Eseguire analisi con Machine Learning Studio (versione classica) usando un database di SQL Server
SI APPLICA A:  Machine Learning Studio (versione classica)
Machine Learning Studio (versione classica)  di Azure Machine Learning
di Azure Machine Learning
Importante
Il supporto dello studio di Azure Machine Learning (versione classica) terminerà il 31 agosto 2024. È consigliabile passare ad Azure Machine Learning entro tale data.
A partire dal 1° dicembre 2021 non sarà possibile creare nuove risorse dello studio di Azure Machine Learning (versione classica). Fino al 31 agosto 2024 sarà possibile continuare a usare le risorse dello studio di Azure Machine Learning (versione classica).
- Vedere le informazioni sullo spostamento di progetti di apprendimento automatico da ML Studio (versione classica) ad Azure Machine Learning.
- Scoprire di più su Azure Machine Learning
La documentazione relativa allo studio di Machine Learning (versione classica) è in fase di ritiro e potrebbe non essere aggiornata in futuro.
In molti casi, le aziende che si avvalgono di dati locali vogliono sfruttare la scalabilità e l'agilità del cloud per i propri carichi di lavoro di Machine Learning. Non intendono tuttavia abbandonare i carichi di lavoro e i processi aziendali correnti spostando nel cloud tutti i propri dati locali. Machine Learning Studio (versione classica) supporta ora la lettura dei dati da un database di SQL Server e quindi il training e l'assegnazione di punteggi a un modello con questi dati. Non è più necessario copiare e sincronizzare manualmente i dati tra il cloud e il server locale. Al contrario, il modulo Import Data in Machine Learning Studio (versione classica) può ora leggere direttamente dal database di SQL Server per i processi di training e assegnazione dei punteggi.
Questo articolo offre una panoramica di come inserire i dati di SQL Server in Machine Learning Studio (versione classica). Si presuppone che si abbia familiarità con i concetti di Studio (versione classica) come aree di lavoro, moduli, set di dati, esperimenti e così via.
Nota
Questa funzionalità non è disponibile per le aree di lavoro gratuite. Per altre informazioni sui piani tariffari e sui piani tariffari di Machine Learning, vedere Prezzi di Machine Learning Studio (versione classica).
Installare il runtime di integrazione self-hosted di Data Factory
Per accedere a un database di SQL Server in Machine Learning Studio (versione classica), è necessario scaricare e installare il runtime di integrazione self-hosted di Data Factory, noto in precedenza come gateway Gestione dati. Quando si configura la connessione in Machine Learning Studio (versione classica), è possibile scaricare e installare Integration Runtime (IR) usando la finestra di dialogo Scarica e registra gateway dati descritta di seguito.
È anche possibile installare il runtime di integrazione in anticipo scaricando ed eseguendo il pacchetto di installazione MSI dal Microsoft Download Center. Il file MSI è anche utilizzabile per eseguire l'aggiornamento di un runtime di integrazione esistente alla versione più recente conservando tutte le impostazioni.
Il runtime di integrazione self-hosted di Data Factory prevede i prerequisiti seguenti:
- L'integrazione self-hosted di Data Factory richiede un sistema operativo a 64 bit con .NET Framework 4.6.1 o versioni successive.
- Sono supportati i sistemi operativi Windows 10, Windows 2012, Windows Server 2012, Windows Server 2012 R2, Windows Server 2016.
- La configurazione consigliata per la machine IR è di almeno 2 GHz, CPU 4 core, 8 GB di RAM e un disco da 80 GB.
- Se il computer host si iberna, il runtime di integrazione non risponde alle richieste di dati. Pertanto, configurare una combinazione per il risparmio di energia appropriata nel computer prima di installare il runtime di integrazione. L'installazione del runtime di integrazione visualizza un messaggio se il computer è configurato per l'ibernazione.
- Poiché le attività di copia seguono una frequenza specifica, l'utilizzo delle risorse nel computer (CPU e memoria) segue lo stesso ciclo costituito da periodi di massimo utilizzo alternati a periodi di inattività. L'utilizzo delle risorse dipende molto anche dalla quantità di dati da spostare. Quando sono in corso più processi di copia, l'utilizzo delle risorse aumenta durante i periodi di picco. Sebbene la configurazione minima sopra elencata sia tecnicamente sufficiente, a seconda del carico previsto per lo spostamento dei dati è possibile adottare una configurazione con più risorse rispetto alla configurazione minima.
Tenere presente quanto segue durante l'installazione e l'uso di un runtime di integrazione self-hosted di Data Factory:
In un computer può essere installata una sola istanza di IR.
È possibile usare un singolo runtime di integrazione per più origini dati locali.
Alla stessa origine dati locale è possibile collegare più runtime di integrazione su computer diversi.
È possibile configurare un IR per una sola area di lavoro alla volta. Attualmente, non è possibile condividere gli IR tra le aree di lavoro.
È possibile configurare più runtime di integrazione per una singola area di lavoro. Ad esempio, è possibile usare un runtime di integrazione connesso alle origini dati di test durante lo sviluppo e un runtime di integrazione di produzione quando si è pronti per l'operazionalizzazione.
Il runtime di integrazione non deve trovarsi sullo stesso computer dell'origine dati. Tuttavia, se i gateway sono posizionati in prossimità dell'origine dati, il tempo necessario alla connessione del gateway all'origine dati si riduce. Si consiglia di installare il runtime di integrazione in un computer diverso da quello che ospita l'origine dati locale in modo che il gateway non si contenda le risorse con l'origine dati.
Se nel computer è già installato un runtime di integrazione che gestisce scenari di Power BI o Azure Data Factory, installare un runtime di integrazione separato per Machine Learning Studio (versione classica) in un altro computer.
Nota
Non è possibile eseguire runtime di integrazione self-hosted di Data Factory e Power BI Gateway nello stesso computer.
È necessario usare il runtime di integrazione self-hosted di Data Factory per Machine Learning Studio (versione classica) anche se si usa Azure ExpressRoute per altri dati. Considerare l'origine dati come origine dati locale, ovvero protetta da firewall, anche quando si usa ExpressRoute. Usare il runtime di integrazione self-hosted Data Factory per stabilire la connettività tra Machine Learning e l'origine dati.
Informazioni dettagliate sui prerequisiti di installazione e sulla procedura di installazione, oltre a suggerimenti sulla risoluzione dei problemi, sono disponibili nell'articolo Runtime di integrazione in Data Factory.
Dati in ingresso dal database di SQL Server in Machine Learning
In questa procedura dettagliata si configurerà un runtime di integrazione di Azure Data Factory in un'area di lavoro di Azure Machine Learning, lo si configurerà e quindi si leggeranno i dati da un database di SQL Server.
Suggerimento
Prima di iniziare, disabilitare il blocco popup del browser per studio.azureml.net. Se si usa il browser Google Chrome, scaricare e installare uno dei diversi plug-in disponibili nella sezione dell' estensione per app ClickOncein Google Chrome WebStore.
Nota
Il runtime di integrazione self-hosted Data Factory di Azure era conosciuto in precedenza come Gateway di gestione dati. L'esercitazione dettagliata continuerà a indicarlo come gateaway.
Passaggio 1: Creare un gateway
Il primo passaggio consiste nel creare e configurare il gateway per accedere al database SQL.
Accedere a Machine Learning Studio (versione classica) e selezionare l'area di lavoro in cui si vuole lavorare.
Fare clic sul pannello SETTINGS (IMPOSTAZIONI) a sinistra e quindi sulla scheda DATA GATEWAYS (GATEWAY DATI) in alto.
Fare clic su NEW DATA GATEWAY (NUOVO GATEWAY DATI) nella parte inferiore della schermata.
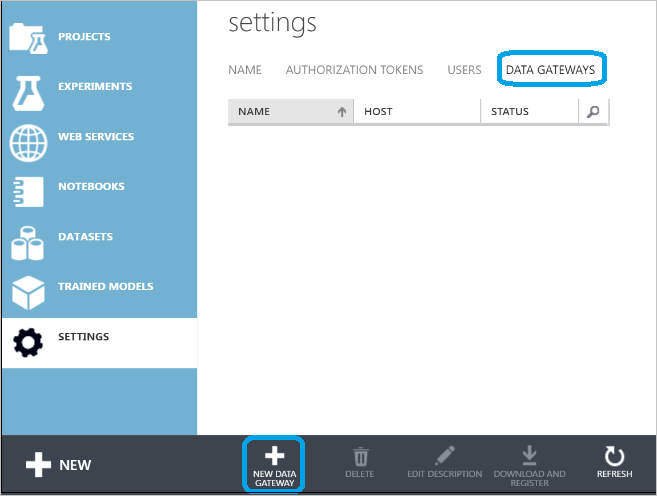
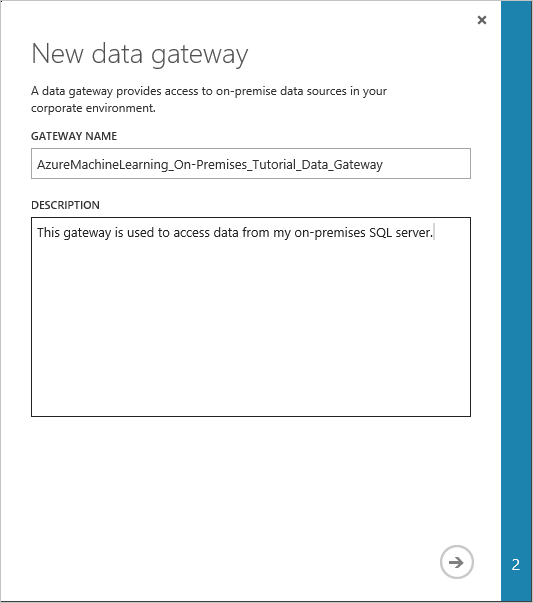
Nella finestra di dialogo New data gateway (Nuovo gateway dati) compilare il campo Gateway Name (Nome gateway) e, facoltativamente, il campo Description (Descrizione). Fare clic sulla freccia nell'angolo inferiore destro per passare al passaggio successivo della configurazione.
Nella finestra di dialogo Download and register data gateway (Scarica e registra il gateway dati) copiare negli Appunti il valore del campo GATEWAY REGISTRATION KEY (CHIAVE REGISTRAZIONE GATEWAY).
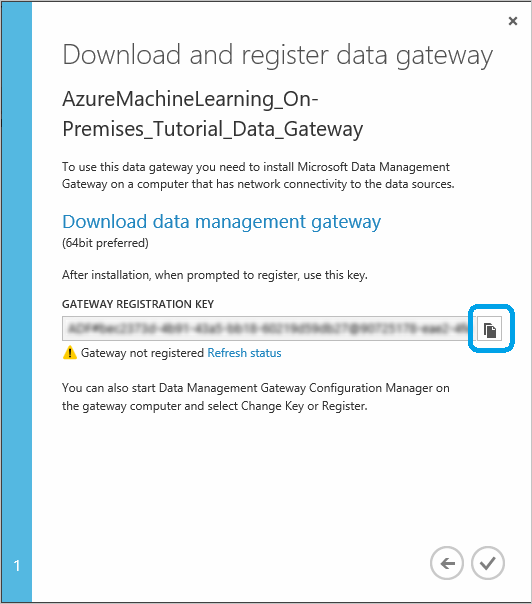
Se Gateway di gestione dati di Microsoft non è ancora stato scaricato e installato, fare clic su Download data management gateway(Scarica Gateway di gestione dati). Si verrà reindirizzati all'Area download Microsoft in cui sarà possibile selezionare la versione del gateway necessaria, in modo da poterla scaricare e installare. Informazioni dettagliate sui prerequisiti di installazione e sulla procedura di installazione, oltre a suggerimenti sulla risoluzione dei problemi, sono disponibili nelle sezioni iniziali dell'articolo Spostare dati tra origini locali e il cloud con Gateway di gestione dati.
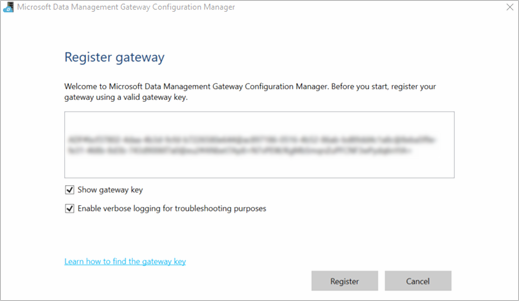
Dopo aver installato il gateway, verrà aperto Gestione configurazione di Gateway di gestione dati e verrà visualizzata la finestra di dialogo Registra gateway . Incollare la chiave di registrazione del gateway copiata negli Appunti e fare clic su Registra.
Se si dispone già di un gateway installato, eseguire Gestione configurazione di Gateway di gestione dati. Fare clic su Cambia chiave, incollare la chiave di registrazione del gateway copiata negli Appunti nel passaggio precedente e fare clic su OK.
Al termine dell'installazione verrà visualizzata la finestra di dialogo Registra gateway di Gestione configurazione di Gateway di gestione dati. Incollare la CHIAVE DI REGISTRAZIONE DEL GATEWAY copiata negli Appunti e fare clic su Registra.
La configurazione del gateway è completa quando nella scheda Home di Gestione configurazione di Gateway di gestione dati i valori seguenti sono impostati secondo quanto descritto di seguito:
Nome gateway e Nome istanza sono impostati sul nome del gateway.
Registrazione è impostato su Registrato.
Stato è impostato su Avviato.
La barra di stato in fondo visualizza Connesso al servizio cloud Gateway di gestione dati insieme a un segno di spunta verde.
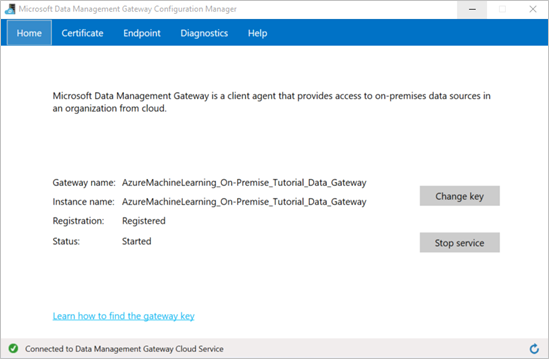
Machine Learning Studio (versione classica) viene aggiornato anche quando la registrazione ha esito positivo.
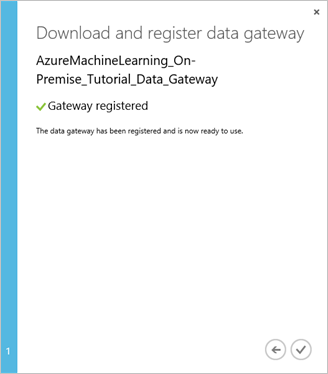
Nella finestra di dialogo Download and register data gateway (Scarica e registra gateway dati) fare clic sul segno di spunta per completare l'installazione. Nella pagina Settings (Impostazioni) lo stato del gateway risulta impostato su "Online". Nel riquadro di destra sono disponibili informazioni sullo stato e altre informazioni utili.
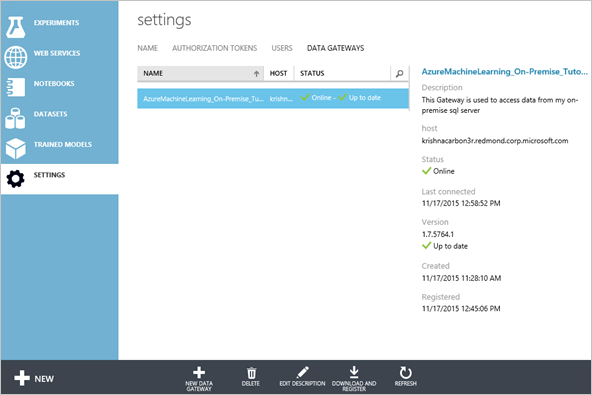
In Microsoft Gestione dati Gateway Configuration Manager passare alla scheda Certificato. Il certificato specificato in questa scheda viene usato per crittografare/decrittografare le credenziali per l'archivio dati locale specificato nel portale. Questo certificato è quello predefinito. Si consiglia di sostituirlo con il certificato personale di cui è stato eseguito il backup nel sistema di gestione dei certificati. Fare clic su Modifica per usare il proprio certificato.
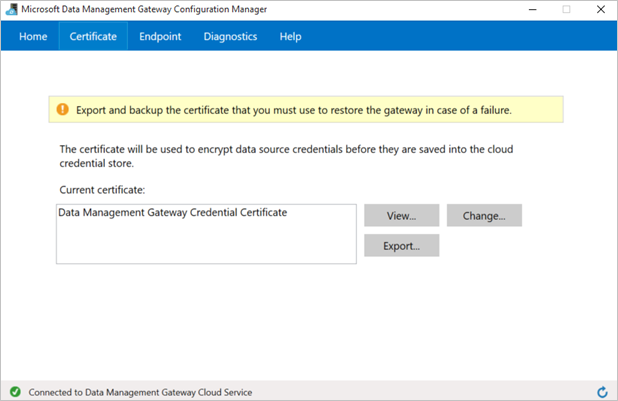
(Facoltativo) Se si vuole abilitare la registrazione dettagliata per la risoluzione dei problemi del gateway, in Gestione configurazione di Gateway di gestione dati passare alla scheda Diagnostica e selezionare l'opzione Abilita la registrazione dettagliata per la risoluzione dei problemi. Le informazioni di registrazione sono disponibili in Windows Visualizzatore eventi nel nodo Registri applicazioni e servizi ->Gestione dati Gateway. È possibile usare la scheda Diagnostica anche per testare la connessione a un'origine dati locale usando il gateway.

In questo modo viene completato il processo di configurazione del gateway in Machine Learning Studio (versione classica). ed è quindi possibile iniziare a usare i dati locali.
È possibile creare e configurare più gateway in Studio (versione classica) per ogni area di lavoro. Può essere utile, ad esempio, creare un gateway da connettere alle origini dati di test in fase di sviluppo e un gateway per le origini dati di produzione. Machine Learning Studio (versione classica) offre la flessibilità necessaria per configurare più gateway a seconda dell'ambiente aziendale. Attualmente non è possibile condividere un gateway tra aree di lavoro e un solo gateway può essere installato in un singolo computer. Per altre informazioni, vedere Spostare dati tra origini locali e il cloud con Gateway di gestione dati.
Passaggio 2: Usare il gateway per leggere dati da un'origine dati locale
Dopo aver configurato il gateway, è possibile aggiungere un modulo Import Data a un esperimento che inserisce i dati dal database di SQL Server.
In Machine Learning Studio (versione classica) selezionare la scheda ESPERIMENTI , fare clic su +NUOVO nell'angolo in basso a sinistra e selezionare Esperimento vuoto (o selezionare uno dei diversi esperimenti di esempio disponibili).
Trovare il modulo Import data (Importa dati) e trascinarlo nell'area di disegno dell'esperimento.
Fare clic su Save as (Salva con nome) sotto l'area di disegno. Immettere "Machine Learning Studio (versione classica) Esercitazione su SQL Server locale" per il nome dell'esperimento, selezionare l'area di lavoro e fare clic sul segno di spunta OK .

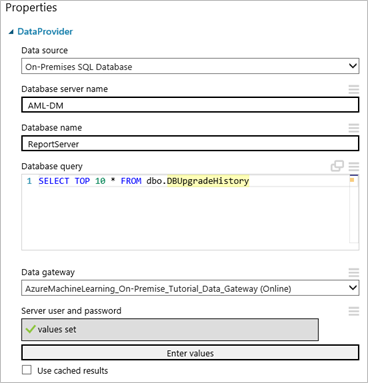
Fare clic sul modulo Import Data (Importazione dati) per selezionarlo, quindi sul pannello Properties (Proprietà) a destra dell'area di disegno e selezionare "On-Premises SQL Database" (Database SQL locale) dall'elenco a discesa Data source (Origine dati).
Selezionare il gateway dati precedentemente installato e registrato. È possibile configurare un altro gateway selezionando l'opzione che consente di aggiungere un nuovo gateway dati.

Compilare i campi Database server name (Nome server database) e Database name (Nome database) insieme a Database query (Query database) e specificare la query di database SQL che si vuole eseguire.
Fare clic su Enter values (Immetti valori) in User name and password (Nome utente e password) e specificare le credenziali del database. È possibile usare l'autenticazione integrata di Windows o l'autenticazione di SQL Server a seconda della configurazione di SQL Server.

Il messaggio "values required" (valori richiesti) verrà modificato in "values set" (valori impostati) con un segno di spunta verde. Se la password o le informazioni del database non vengono modificate, è sufficiente immettere le credenziali una sola volta. Machine Learning Studio (versione classica) usa il certificato fornito quando è stato installato il gateway per crittografare le credenziali nel cloud. Azure non archivia mai credenziali locali senza crittografia.
Fare clic su RUN (ESEGUI) per eseguire l'esperimento.
Al termine dell'esecuzione dell'esperimento è possibile visualizzare i dati importati dal database facendo clic sulla porta di output del modulo Import Data (Importa dati) e selezionando Visualize (Visualizza).
Dopo aver completato lo sviluppo dell'esperimento, è possibile distribuire il modello e renderlo operativo. Usando il servizio di esecuzione batch, i dati del database di SQL Server configurato nel modulo Import Data (Importa dati ) verranno letti e usati per l'assegnazione dei punteggi. Sebbene per l'assegnazione dei punteggi ai dati locali sia possibile usare il servizio di richiesta/risposta, Microsoft consiglia l'uso del componente aggiuntivo di Excel . Attualmente, la scrittura in un database di SQL Server tramite Esporta dati non è supportata né negli esperimenti né nei servizi Web pubblicati.