Clustering K-means
Importante
Il supporto dello studio di Azure Machine Learning (versione classica) terminerà il 31 agosto 2024. È consigliabile passare ad Azure Machine Learning entro tale data.
A partire dal 1° dicembre 2021 non sarà possibile creare nuove risorse dello studio di Azure Machine Learning (versione classica). Fino al 31 agosto 2024 sarà possibile continuare a usare le risorse dello studio di Azure Machine Learning (versione classica).
- Vedere leinformazioni sullo spostamento di progetti di Machine Learning da ML Studio (versione classica) ad Azure Machine Learning.
- Informazioni su Azure Machine Learning.
La documentazione relativa allo studio di Machine Learning (versione classica) è in fase di ritiro e potrebbe non essere aggiornata in futuro.
Configura e inizializza un modello di clustering K-means
Categoria: Machine Learning/Initialize Model/Clustering
Nota
Si applica a: Solo Machine Learning Studio (versione classica)
I moduli di trascinamento della selezione simili sono disponibili nella finestra di progettazione di Azure Machine Learning.
Panoramica del modulo
Questo articolo descrive come usare il modulo K-Means Clustering in Machine Learning Studio (versione classica) per creare un modello di clustering K-means non sottoposto a training.
K-means è uno degli algoritmi di apprendimento non supervisionati più semplici e più noti e può essere usato per un'ampia gamma di attività di Machine Learning, ad esempio il rilevamento di dati anomali, il clustering di documenti di testo e l'analisi di un set di dati prima di usare altri metodi di classificazione o regressione. Per creare un modello di clustering, aggiungere questo modulo all'esperimento, connettere un set di dati e impostare parametri, ad esempio il numero di cluster previsti, la metrica di distanza da usare per la creazione dei cluster e così via.
Dopo aver configurato gli iperparametri del modulo, connettere il modello non sottoposto a training al modello di training del clustering o ai moduli Sweep Clustering per eseguire il training del modello sui dati di input forniti. Poiché l'algoritmo K-means è un metodo di apprendimento non supervisionato, una colonna etichetta è facoltativa.
- Se i dati includono un'etichetta, è possibile usare i valori delle etichette per guidare la selezione dei cluster e ottimizzare il modello.
- Se i dati non hanno etichette, l'algoritmo crea cluster che rappresentano le categorie possibili, in base esclusivamente ai dati.
Suggerimento
Se i dati di training hanno etichette, è consigliabile usare uno dei metodi di classificazione con supervisione forniti in Machine Learning. Ad esempio, è possibile confrontare i risultati del clustering con i risultati quando si usa uno degli algoritmi dell'albero delle decisioni multiclasse.
Informazioni sul clustering k-means
In generale, il clustering usa tecniche iterative per raggruppare i casi di un set di dati in cluster con caratteristiche simili. Questi raggruppamenti sono utili per esplorare i dati, identificare le anomalie nei dati e infine per eseguire stime. I modelli di clustering consentono anche di identificare le relazioni in un set di dati che potrebbe non derivare logicamente esplorando o osservando con semplicità. Per questi motivi, il clustering viene spesso usato nelle fasi iniziali delle attività di Machine Learning, per esplorare i dati e individuare correlazioni impreviste.
Quando si configura un modello di clustering usando il metodo k-means, è necessario specificare un numero di destinazione k che indica il numero di centroidi desiderati nel modello. Il centroide è un punto rappresentativo di ogni cluster. L'algoritmo K-means assegna ogni punto dati in ingresso a uno dei cluster riducendo al minimo la somma all'interno del cluster di quadrati.
Quando si elaborano i dati di training, l'algoritmo K-means inizia con un set iniziale di centroidi scelti casualmente, che fungono da punti di partenza per ogni cluster e applica l'algoritmo di Lloyd per perfezionare in modo iterativo le posizioni dei centroidi. L'algoritmo K-means interrompe la compilazione e l'affinamento dei cluster quando soddisfa una o più di queste condizioni:
I centroidi si stabilizzano, ovvero le assegnazioni di cluster per i singoli punti non cambiano più e l'algoritmo è convergente su una soluzione.
L'algoritmo ha completato l'esecuzione del numero specificato di iterazioni.
Dopo aver completato la fase di training, usare il modulo Assegna dati ai cluster per assegnare nuovi case a uno dei cluster trovati dall'algoritmo k-means. L'assegnazione del cluster viene eseguita calcolando la distanza tra il nuovo case e il centroid di ogni cluster. Ogni nuovo caso viene assegnato al cluster con il centroide più vicino.
Come configurare il clustering K-Means
Aggiungere il modulo K-Means Clustering all'esperimento.
Specificare la modalità di training del modello impostando l'opzione Crea modalità di training .
Singolo parametro: se si conoscono i parametri esatti da usare nel modello di clustering, è possibile specificare un set specifico di valori come argomenti.
Intervallo di parametri: se non si è certi dei parametri migliori, è possibile trovare i parametri ottimali specificando più valori e usando il modulo Sweep Clustering per trovare la configurazione ottimale.
Il formatore esegue l'iterazione su più combinazioni delle impostazioni fornite e determina la combinazione di valori che produce i risultati ottimali del clustering.
In Number of Centroids (Numero di centroidi) digitare il numero di cluster con cui iniziare l'algoritmo.
Non è garantito che il modello producano esattamente questo numero di cluster. L'algorithn inizia con questo numero di punti dati e esegue l'iterazione per trovare la configurazione ottimale, come descritto nella sezione Note tecniche .
Se si esegue uno sweep di parametri, il nome della proprietà viene modificato in Range per Number of Centroids. È possibile usare Range Builder per specificare un intervallo oppure digitare una serie di numeri che rappresentano diversi numeri di cluster da creare durante l'inizializzazione di ogni modello.
Le proprietà Inizializzazione o Inizializzazione per sweep vengono utilizzate per specificare l'algoritmo utilizzato per definire la configurazione iniziale del cluster.
Primo N: il numero iniziale di punti dati viene scelto dal set di dati e usato come mezzo iniziale.
Chiamato anche il metodo Forgy.
Casuale: l'algoritmo inserisce in modo casuale un punto dati in un cluster e quindi calcola la media iniziale come centroide dei punti assegnati casualmente del cluster.
Chiamato anche metodo di partizione casuale .
K-Means++: metodo predefinito per l'inizializzazione dei cluster.
L'algoritmo K-means ++ è stato proposto nel 2007 da David Arthur e Sergei Vassilvitskii per evitare un clustering scadente dall'algoritmo k-means standard. K-means ++ migliora il K-means standard usando un metodo diverso per la scelta dei centri cluster iniziali.
K-Means++Fast: variante dell'algoritmo K-means ++ ottimizzato per un clustering più veloce.
Uniformemente: i centroidi si trovano equidistenti l'uno dall'altro nello spazio d-Dimensionale di n punti dati.
Usare la colonna etichetta: i valori nella colonna etichetta vengono usati per guidare la selezione dei centroidi.
Per Valore di inizializzazione numero casuale, digitare facoltativamente un valore da usare come valore di inizializzazione per l'inizializzazione del cluster. Questo valore può avere un effetto significativo sulla selezione del cluster.
Se si utilizza uno sweep di parametri, è possibile specificare che vengono creati più semi iniziali per cercare il valore di inizializzazione migliore. Per Numero di semi da eseguire lo sweep, digitare il numero totale di valori di inizializzazione casuali da utilizzare come punti iniziali.
Per Metrica scegliere la funzione da usare per misurare la distanza tra i vettori del cluster o tra i nuovi punti dati e il centroide scelto in modo casuale. Machine Learning supporta le metriche di distanza del cluster seguenti:
Euclideo: la distanza euclidea viene comunemente usata come misura della dispersione del cluster per il clustering K-means. Questa metrica è preferibile perché riduce al minimo la distanza media tra i punti e i centroidi.
Coseno: la funzione coseno viene usata per misurare la somiglianza del cluster. La somiglianza coseno è utile nei casi in cui non ti interessa la lunghezza di un vettore, solo il suo angolo.
Per le iterazioni, digitare il numero di volte in cui l'algoritmo deve scorrere i dati di training prima di finalizzare la selezione dei centroidi.
È possibile modificare questo parametro per bilanciare l'accuratezza rispetto al tempo di training.
Per Modalità assegnazione etichetta scegliere un'opzione che specifica come deve essere gestita una colonna etichetta, se presente nel set di dati.
Poiché il clustering K-means è un metodo di Machine Learning non supervisionato, le etichette sono facoltative. Tuttavia, se il set di dati include già una colonna etichetta, è possibile usare tali valori per guidare la selezione dei cluster oppure specificare che i valori devono essere ignorati.
Ignora colonna etichetta: i valori nella colonna etichetta vengono ignorati e non vengono usati per la compilazione del modello.
Riempimento dei valori mancanti: i valori delle colonne dell'etichetta vengono usati come funzionalità per creare i cluster. Se manca un'etichetta, il valore viene imputato usando altre funzionalità.
Sovrascrivi dal centro più vicino al centro: i valori delle colonne dell'etichetta vengono sostituiti con valori di etichetta stimati, usando l'etichetta del punto più vicino al centroide corrente.
Eseguire il training del modello.
Se si imposta La modalità di training crea su Parametro singolo, aggiungere un set di dati con tag ed eseguire il training del modello usando il modulo Train Clustering Model (Training del modello di clustering ).
Se si imposta Crea modalità di training su Intervallo di parametri, aggiungere un set di dati con tag ed eseguire il training del modello usando Sweep Clustering. È possibile usare il modello di cui è stato eseguito il training usando questi parametri oppure annotare le impostazioni dei parametri da usare quando si configura uno strumento di apprendimento.
Risultati
Dopo aver completato la configurazione e il training del modello, è disponibile un modello che è possibile usare per generare i punteggi. Esistono tuttavia diversi modi per eseguire il training del modello e più modi per visualizzare e usare i risultati:
Acquisire uno snapshot del modello nell'area di lavoro
Se è stato usato il modulo Train Clustering Model
- Fare clic con il pulsante destro del mouse sul modulo Train Clustering Model (Esegui training del modello di clustering ).
- Selezionare Trained model (Modello sottoposto a training) e quindi fare clic su Save as Trained Model (Salva come modello sottoposto a training).
Se è stato usato il modulo Sweep Clustering per eseguire il training del modello
- Fare clic con il pulsante destro del mouse sul modulo Sweep Clustering .
- Selezionare Best Trained model (Modello con training ottimale ) e quindi fare clic su Save as Trained Model (Salva come modello sottoposto a training).
Il modello salvato rappresenterà i dati di training al momento del salvataggio del modello. Se in seguito si aggiornano i dati di training usati nell'esperimento, il modello salvato non verrà aggiornato.
Visualizzare una rappresentazione visiva dei cluster nel modello
Se è stato usato il modulo Training Clustering Model
- Fare clic con il pulsante destro del mouse sul modulo e scegliere Set di dati Risultati.
- Selezionare Visualize (Visualizza).
Se è stato usato il modulo Sweep Clustering
Aggiungere un'istanza del modulo Assegna dati ai cluster e generare punteggi usando il modello Best Traininged.
Fare clic con il pulsante destro del mouse sul modulo Assegna dati ai cluster , selezionare Set di dati Risultati e selezionare Visualizza.
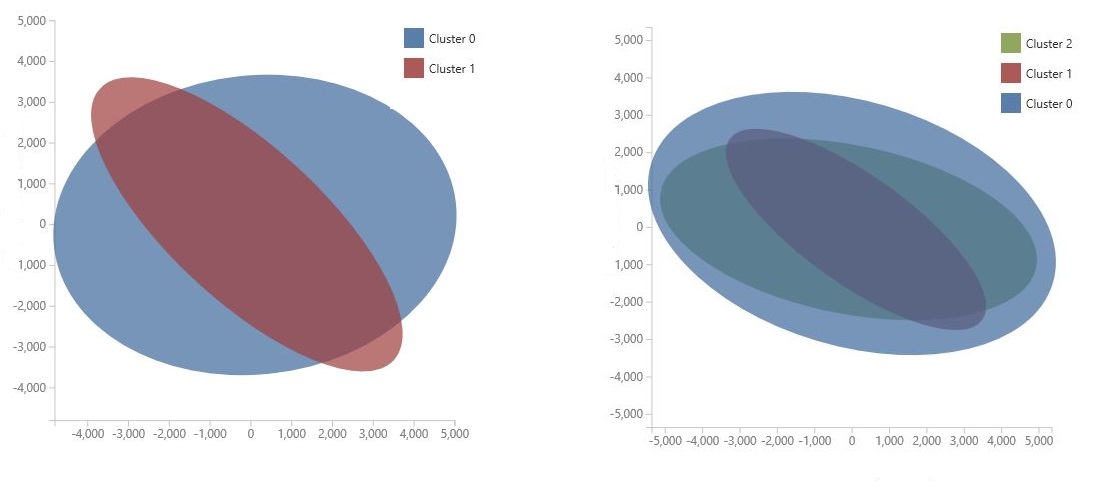
Il grafico viene generato usando l'analisi dei componenti principale, una tecnica in data science per comprimere lo spazio delle funzionalità di un modello. Il grafico mostra alcuni set di funzionalità, compressi in due dimensioni, che meglio caratterizzano la differenza tra i cluster. Esaminando visivamente le dimensioni generali dello spazio delle funzionalità per ogni cluster e la quantità di sovrapposizione dei cluster, è possibile ottenere un'idea della modalità di esecuzione del modello.
Ad esempio, i grafici PCA seguenti rappresentano i risultati di due modelli sottoposti a training usando gli stessi dati: il primo è stato configurato per l'output di due cluster e il secondo è stato configurato per l'output di tre cluster. Da questi grafici è possibile notare che l'aumento del numero di cluster non ha necessariamente migliorato la separazione delle classi.
Suggerimento
Usare il modulo Sweep Clustering per scegliere il set ottimale di iperparametri, tra cui il seed casuale e il numero di centroidi iniziali.
Vedere l'elenco dei punti dati e i cluster a cui appartengono
Sono disponibili due opzioni per visualizzare il set di dati con risultati, a seconda della modalità di training del modello:
Se è stato usato il modulo Sweep Clustering per eseguire il training del modello
- Usare la casella di controllo nel modulo Sweep Clustering per specificare se si desidera visualizzare i dati di input insieme ai risultati o visualizzare solo i risultati.
- Al termine del training, fare clic con il pulsante destro del mouse sul modulo e selezionare Set di dati Risultati (numero di output 2)
- Fare clic su Visualizza.
Se è stato usato il modulo Training Clustering Model
- Aggiungere il modulo Assegna dati ai cluster e connettere il modello sottoposto a training all'input a sinistra. Connettere un set di dati all'input destro.
- Aggiungere il modulo Convert to Dataset all'esperimento e connetterlo all'output di Assegna dati ai cluster.
- Usare la casella di controllo nel modulo Assegna dati ai cluster per specificare se si desidera visualizzare i dati di input insieme ai risultati o vedere solo i risultati.
- Eseguire l'esperimento o eseguire solo il modulo Converti in set di dati .
- Fare clic con il pulsante destro del mouse su Converti nel set di dati, selezionare Set di dati Risultati e fare clic su Visualizza.
L'output contiene prima le colonne di dati di input, se incluse e le colonne seguenti per ogni riga di dati di input:
Assegnazione: l'assegnazione è un valore compreso tra 1 e n, dove n è il numero totale di cluster nel modello. Ogni riga di dati può essere assegnata a un solo cluster.
DistancesToClusterCenter no.n: questo valore misura la distanza dal punto dati corrente al centroid per il cluster. Colonna separata in output per ogni cluster nel modello sottoposto a training.
I valori per la distanza del cluster si basano sulla metrica di distanza selezionata nell'opzione Metrica per misurare il risultato del cluster. Anche se si esegue uno sweep di parametri nel modello di clustering, è possibile applicare una sola metrica durante lo sweep. Se si modifica la metrica, è possibile ottenere valori di distanza diversi.
Visualizzare le distanze tra cluster
Nel set di dati dei risultati della sezione precedente fare clic sulla colonna delle distanze per ogni cluster. Studio (versione classica) visualizza un istogramma che visualizza la distribuzione delle distanze per i punti all'interno del cluster.
Ad esempio, gli istogrammi seguenti mostrano la distribuzione delle distanze del cluster dallo stesso esperimento, usando quattro metriche diverse. Tutte le altre impostazioni per lo sweep dei parametri erano uguali. La modifica della metrica ha generato un numero diverso di cluster in un modello.
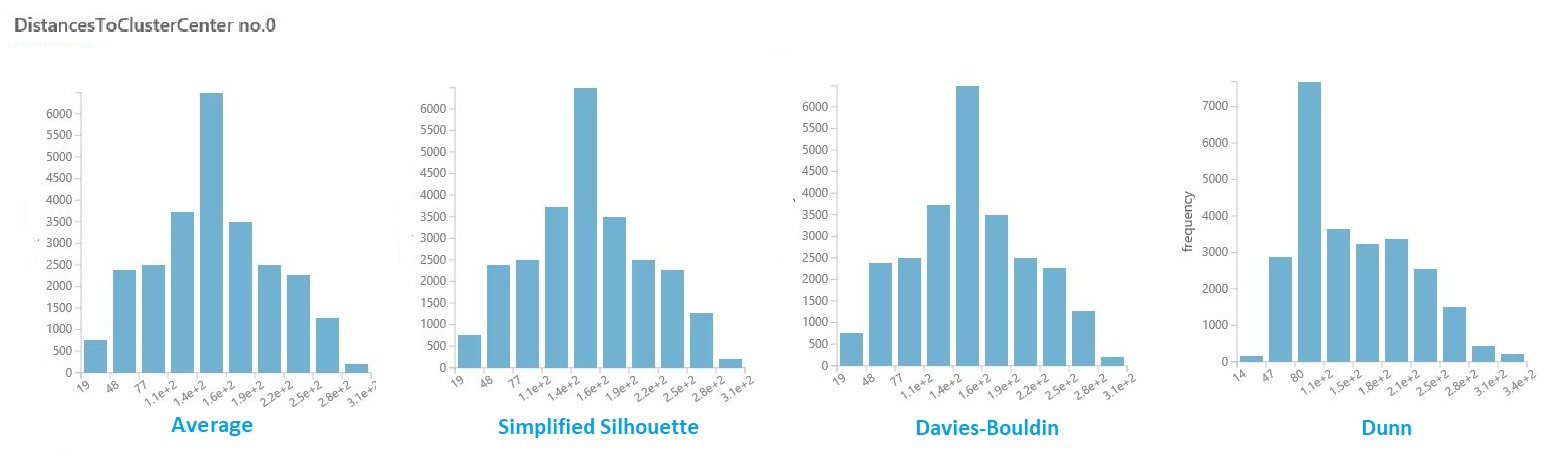
In generale, è consigliabile scegliere una metrica che ottimizza la distanza tra punti dati in classi diverse e riduce al minimo le distanze all'interno di una classe. È possibile usare i mezzi precompilate e altri valori nel riquadro Statistiche per guidarvi in questa decisione.
Suggerimento
È possibile estrarre mezzi e altri valori usati nelle visualizzazioni usando il modulo PowerShell per Machine Learning.
In alternativa, usare il modulo Esegui script R per calcolare una matrice di distanza personalizzata.
Suggerimenti per la generazione del modello di clustering migliore
È noto che il processo di seeding usato durante il clustering può influire significativamente sul modello. Il seeding significa il posizionamento iniziale di punti in centroidi potenti.
Ad esempio, se il set di dati contiene molti outlier e un outlier viene scelto per inizializzare i cluster, nessun altro punto dati sarebbe adatto a tale cluster e il cluster potrebbe essere un singleton: ovvero un cluster con un solo punto.
Esistono vari modi per evitare questo problema:
Usare uno sweep di parametri per modificare il numero di centroidi e provare più valori di inizializzazione.
Creare più modelli, variando la metrica o iterando di più.
Usare un metodo come PCA per trovare le variabili che hanno un effetto dannoso sul clustering. Vedere l'esempio Trova aziende simili per una dimostrazione di questa tecnica.
In generale, con i modelli di clustering, è possibile che qualsiasi configurazione specificata comporterà un set di cluster ottimizzato in locale. In altre parole, il set di cluster restituiti dal modello si adatta solo ai punti dati correnti e non è generalizzabile ad altri dati. Se è stata usata una configurazione iniziale diversa, il metodo K-Means potrebbe trovare una configurazione diversa, addirittura superiore.
Importante
È consigliabile sperimentare sempre i parametri, creare più modelli e confrontare i modelli risultanti.
Esempio
Per esempi del modo in cui viene usato il clustering K-means in Machine Learning, vedere questi esperimenti nella raccolta di intelligenza artificiale di Azure:
Dati dell'iris del gruppo: confronta i risultati del clustering K-Means e la regressione logistica multiclasse per un'attività di classificazione.
Esempio di quantizzazione dei colori: compila più modelli K-means con parametri diversi per trovare la compressione ottimale dell'immagine.
Clustering: aziende simili: varia il numero di centroid per trovare gruppi di aziende simili nel&P500.
Note tecniche
Dato un numero di cluster specifico (K) per trovare un set di punti dati con dimensione D con N punti dati, l'algoritmo K-Means crea i cluster come indicato di seguito:
Il modulo inizializza una matrice K-by-D con i centroidi finali che definiscono i cluster K trovati.
Per impostazione predefinita, il modulo assegna i primi punti dati K per i cluster K .
Partendo da un set iniziale di K centroidi, il metodo usa l'algoritmo di Lloyd per perfezionare in modo iterativo le posizioni dei centroidi.
L'algoritmo termina quando i centroidi si stabilizzano o quando viene completato un determinato numero di iterazioni.
Viene usata una metrica di similitudine (per impostazione predefinita, la distanza euclidea) per assegnare ciascun punto dati al cluster con il centroide più vicino.
Avviso
- Se si passa un intervallo di parametri a Training Clustering Model, usa solo il primo valore nell'elenco di intervalli di parametri.
- Se si passa un singolo set di valori di parametro al modulo Sweep Clustering , quando si prevede un intervallo di impostazioni per ogni parametro, ignora i valori e usa i valori predefiniti per il learner.
- Se si seleziona l'opzione Intervallo di parametri e si immette un singolo valore per qualsiasi parametro, tale singolo valore specificato viene usato durante lo sweep, anche se altri parametri cambiano in un intervallo di valori.
Parametri del modulo
| Nome | Intervallo | Type | Predefinito | Descrizione |
|---|---|---|---|---|
| Numero di centroidi | >=2 | Integer | 2 | Numero di centroidi |
| Metrica | Elenco (subset) | Metrica | Euclidean | Metrica selezionata |
| Inizializzazione | Elenco | Metodo di inizializzazione del centroide | K-Means++ | Algoritmo di inizializzazione |
| Iterazioni | >=1 | Integer | 100 | Number of iterations |
Output
| Nome | Tipo | Descrizione |
|---|---|---|
| Untrained model | ICluster interface | Modello di clustering K-Means senza training |
Eccezioni
Per un elenco di tutte le eccezioni, vedere Codici di errore del modulo di Machine Learning.
| Eccezione | Descrizione |
|---|---|
| Errore 0003 | L'eccezione si verifica se uno o più input sono null o vuoti. |
Vedi anche
Clustering
Assign Data to Clusters (Assegna dati ai cluster)
Train Clustering Model (Training del modello di clustering)
Clustering a scorrimento