Più GPU e computer
1. Introduzione
CNTK supporta attualmente quattro algoritmi SGD paralleli:
Prerequisiti
Per eseguire il training parallelo, assicurarsi che sia installata un'implementazione dell'interfaccia MPI (Message Passing Interface):
In Windows installare la versione 7 (7.0.12437.6) di Microsoft MPI (MS-MPI), un'implementazione Microsoft dello standard Message Passing Interface, da questa pagina di download, contrassegnata semplicemente come "Versione 7" nel titolo della pagina. Fare clic sul pulsante Scarica e quindi selezionare il runtime (
MSMpiSetup.exe).In Linux installare OpenMPI versione 1.10.x. Seguire le istruzioni riportate qui per compilarlo manualmente.
2. Configurazione del training parallelo in CNTK in Python
Per usare l'SGD parallelo dei dati in Python, l'utente deve creare e passare un learner distribuito al formatore:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Per il ciclo di training definito dall'utente (invece di training_session), gli utenti devono passare num_data_partitions e partition_index al MinibatchSource.next_minibatch() metodo in modo che nodi MPI diversi leggano i dati da partizioni di dati diverse (dopo distributed_after la lettura degli esempi).
Si noti che Communicator.finalize() deve essere chiamato solo nel caso in cui il training distribuito sia stato completato correttamente. Nel caso in cui un ruolo di lavoro distribuito non riesca, questo metodo non deve essere chiamato.
Per un esempio completamente funzionale, vedere l'esempio di ConvNet.
3. Configurazione del training parallelo in CNTK in BrainScript
Per abilitare il training parallelo in CNTK BrainScript, è prima necessario attivare il commutatore seguente nel file di configurazione o nella riga di comando:
parallelTrain = true
In secondo luogo, il SGD blocco nel file di configurazione deve contenere un sottoblocdo denominato ParallelTrain con gli argomenti seguenti:
parallelizationMethod: (obbligatorio) i valori legittimi sonoDataParallelSGD,BlockMomentumSGDeModelAveragingSGD.Specifica l'algoritmo parallelo da utilizzare.
distributedMBReading: (facoltativo) accetta il valore booleano:trueofalse; il valore predefinito èfalseÈ consigliabile attivare la lettura del minibatch distribuito per ridurre al minimo il costo di I/O in ogni ruolo di lavoro. Se si usa il lettore di formato di testo CNTK, il lettore di immagini o il lettore di dati compositi, distributedMBReading deve essere impostato su true.
parallelizationStartEpoch: (facoltativo) accetta un valore intero; il valore predefinito è 1.Specifica a partire da quale periodo vengono usati algoritmi di training paralleli; prima che tutti i lavoratori eseseguono lo stesso training, ma solo un lavoratore può salvare il modello. Questa opzione può essere utile se il training parallelo richiede una fase di avvio frequente.
syncPerfStats: (facoltativo) accetta un valore intero; il valore predefinito è 0.Specifica la frequenza con cui verranno stampate le statistiche sulle prestazioni. Tali statistiche includono il tempo dedicato alla comunicazione e/o al calcolo in un periodo di sincronizzazione, che può essere utile per comprendere il collo di bottiglia degli algoritmi di training paralleli.
0 significa che non verranno stampate statistiche. Altri valori specificano la frequenza con cui verranno stampate le statistiche. Ad esempio,
syncPerfStats=5significa che le statistiche verranno stampate dopo ogni 5 sincronizzazioni.Sottoblocdamento che specifica i dettagli di ogni algoritmo di training parallelo. Il nome del sottoblocdo deve essere uguale a
parallelizationMethod. (obbligatorio)
Python offre maggiore flessibilità e utilizzi sono illustrati di seguito per diversi metodi di parallelizzazione.
4. Esecuzione del training parallelo con CNTK
La parallelizzazione in CNTK viene implementata con MPI.
4.1 Esecuzione del training parallelo con BrainScript
Data una delle configurazioni BrainScript di training parallele precedente, è possibile usare i comandi seguenti per avviare un processo MPI parallelo:
Training parallelo nello stesso computer con Linux:
mpiexec --npernode $num_workers $cntk configFile=$configTraining parallelo nello stesso computer con Windows:
mpiexec -n %num_workers% %cntk% configFile=%config%Training parallelo tra più nodi di calcolo con Linux:
Passaggio 1: Creare un file host $hostfile usando l'editor preferito
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Dove name_of_node(n) è semplicemente un nome DNS o un indirizzo IP del nodo di lavoro.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
Training parallelo tra più nodi di calcolo con Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
dove $cntk deve fare riferimento al percorso dell'eseguibile CNTK ($x è il modo della shell Linux di sostituire le variabili di ambiente, l'equivalente di %x% nella shell di Windows).
4.2 Esecuzione del training parallelo con Python
Gli esempi di training distribuito per CNTK v2 con Python sono disponibili qui:
Dato uno script training.py Python CNTK v2, è possibile usare i comandi seguenti per avviare un processo MPI parallelo:
Training parallelo nello stesso computer con Linux:
mpiexec --npernode $num_workers python training.pyTraining parallelo nello stesso computer con Windows:
mpiexec -n %num_workers% python training.pyTraining parallelo tra più nodi di calcolo con Linux:
Passaggio 1: Creare un file host $hostfile usando l'editor preferito
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Dove name_of_node(n) è semplicemente un nome DNS o un indirizzo IP del nodo di lavoro.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
Training parallelo tra più nodi di calcolo con Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
Training di 5 Data-Parallel con SGD a 1 bit
CNTK implementa la tecnica SGD a 1 bit [1]. Questa tecnica consente di distribuire ogni minibatch sui K ruoli di lavoro. Le sfumature parziali risultanti vengono quindi scambiate e aggregate dopo ogni minibatch. "1 bit" si riferisce a una tecnica sviluppata in Microsoft per ridurre la quantità di dati scambiati per ogni valore sfumatura a un singolo bit.
5.1 Algoritmo "SGD a 1 bit"
Lo scambio diretto di sfumature parziali dopo ogni minibatch richiede una larghezza di banda di comunicazione proibitiva. Per risolvere questo problema, SGD a 1 bit quantizza in modo aggressivo ogni valore della sfumatura... a un singolo bit (!) per valore. In pratica, ciò significa che vengono ritagliati valori sfumature di grandi dimensioni, mentre i valori piccoli vengono gonfiati artificialmente. Incredibilmente, questo non danneggia la convergenza se, e solo se, viene usato un trucco .
Il trucco è che per ogni minibatch, l'algoritmo confronta le sfumature quantizzate (scambiate tra i ruoli di lavoro) con i valori di sfumatura originali (che dovrebbero essere scambiati). La differenza tra i due ( errore di quantizzazione) viene calcolata e memorizzata come residua. Questo residuo viene quindi aggiunto al minibatch successivo .
Di conseguenza, nonostante la quantizzazione aggressiva, ogni valore della sfumatura viene infine scambiato con accuratezza completa; solo in un ritardo. Gli esperimenti mostrano che, purché questo modello sia combinato con un warm start (un modello di inizializzazione sottoposto a training su un piccolo subset dei dati di training senza parallelizzazione), questa tecnica ha dimostrato di causare una perdita di accuratezza minima o minima, consentendo una velocità non troppo elevata rispetto a quella lineare (il fattore di limitazione è che le GPU diventano inefficienti durante il calcolo su sotto batch troppo piccoli).
Per una massima efficienza, la tecnica deve essere combinata con il ridimensionamento automatico del minibatch, dove ogni ora e poi, il trainer tenta di aumentare le dimensioni del minibatch. La valutazione su un piccolo sottoinsieme del prossimo periodo di dati, il formatore selezionerà le dimensioni di minibatch più grandi che non danneggiano la convergenza. In questo caso, è utile che CNTK specifica la velocità di apprendimento e gli iperparametri di slancio in modo indipendente dalle dimensioni minibatch.
5.2 Uso di SGD a 1 bit in BrainScript
Sgd a 1 bit non ha alcun parametro diverso dall'abilitazione e dopo il periodo in cui deve iniziare. Inoltre, è necessario abilitare il ridimensionamento automatico dei minibatch. Questi parametri vengono configurati aggiungendo i parametri seguenti al blocco SGD:
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
Si noti che Data-Parallel SGD può essere usato anche senza quantizzazione a 1 bit. Tuttavia, in scenari tipici, in particolare gli scenari in cui ogni parametro del modello viene applicato una sola volta come per una rete neurale DNN di avanzamento, questa operazione non sarà efficiente a causa di esigenze elevate di larghezza di banda di comunicazione.
La sezione 2.2.3 seguente mostra i risultati di SGD a 1 bit in un'attività di riconoscimento vocale, confrontando con il metodo SGD Block-Momentum descritto di seguito. Entrambi i metodi non hanno o quasi nessuna perdita di accuratezza a velocità quasi lineare.
5.3 Uso di SGD a 1 bit in Python
Per usare il SGD parallelo dei dati in Python, facoltativamente con SGD a 1 bit, l'utente deve creare e passare un learner distribuito al formatore:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
La modifica di num_quantization_bits a 32 durante la creazione di distributed_learner lo rende non quantizzato Data-Parallel SGD. In questo caso non è necessario avviare a caldo.
6 Block-Momentum SGD
Block-Momentum SGD è l'implementazione del "blocco di aggiornamento e filtro del modello" o BMUF, algoritmo, short Block Momentum [2].
6.1 Algoritmo SGD Block-Momentum
La figura seguente riepiloga la procedura nell'algoritmo Block-Momentum.

6.2 Configurazione di Block-Momentum SGD in BrainScript
Per usare Block-Momentum SGD, è necessario avere un sotto-blocco denominato BlockMomentumSGD nel SGD blocco con le opzioni seguenti:
syncPeriod. È simile asyncPeriodinModelAveragingSGD, che specifica la frequenza con cui viene eseguita una sincronizzazione del modello. Il valore predefinito perBlockMomentumSGDè 120.000.resetSGDMomentum. Ciò significa che dopo ogni punto di sincronizzazione, la sfumatura smussata usata in SGD locale verrà impostata su 0. Il valore predefinito di questa variabile è true.useNesterovMomentum. Ciò significa che l'aggiornamento dello slancio in stile Nesterov viene applicato a livello di blocco. Per altri dettagli, vedere [2]. Il valore predefinito di questa variabile è true.
Il ritmo di blocco e il tasso di apprendimento a blocchi vengono in genere impostati automaticamente in base al numero di lavoratori utilizzati, ad esempio
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
La nostra esperienza indica che queste impostazioni spesso producono una convergenza simile all'algoritmo SGD standard fino a 64 GPU, che è l'esperimento più grande eseguito. È anche possibile specificare manualmente questi parametri usando le opzioni seguenti:
blockMomentumAsTimeConstantspecifica la costante temporale del filtro a basso passaggio nell'aggiornamento del modello a livello di blocco. Viene calcolato come segue:blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRatespecifica la frequenza di apprendimento a blocchi.
Di seguito è riportato un esempio di Block-Momentum sezione di configurazione SGD:
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3 Uso di Block-Momentum SGD in BrainScript
1. Ottimizzazione dei parametri di apprendimento
Per ottenere una velocità effettiva simile per ogni ruolo di lavoro, è necessario aumentare il numero di campioni in un minibatch proporzionale al numero di ruoli di lavoro. A tale scopo, è possibile regolare
minibatchSizeonbruttsineachrecurrentiter, a seconda che venga usata la modalità casuale in modalità frame.Non è necessario modificare la frequenza di apprendimento (a differenza di Model-Averaging SGD, vedere di seguito).
È consigliabile usare Block-Momentum SGD con un modello ad accesso frequente. Nelle attività di riconoscimento vocale si ottiene una ragionevole convergenza quando si inizia da modelli di inizializzazione sottoposti a training su 24 ore (8,6 milioni di campioni) a 120 ore (43,2 milioni di campioni) dati con SGD standard.
2. Esperimenti ASR
Sono stati usati i Block-Momentum SGD e gli algoritmi SGD (Data-Parallel a 1 bit) per eseguire il training di DNN e LSTM in un'attività di riconoscimento vocale di 2600 ore e confrontare le accuratezze del riconoscimento delle parole rispetto ai fattori di accelerazione. Le tabelle e le figure seguenti illustrano i risultati (*).
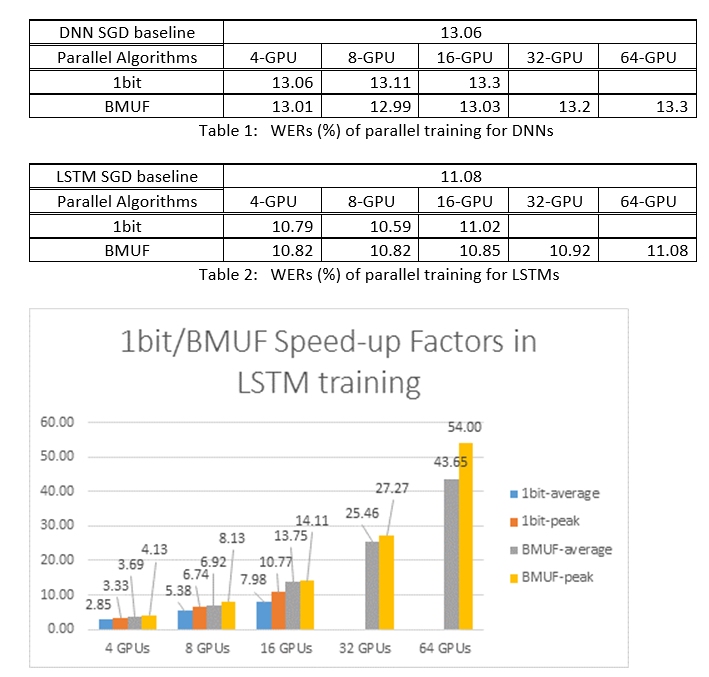
(*): fattore di velocità massima: per SGD a 1 bit, misurato dal fattore di velocità massima (rispetto alla linea di base SGD) ottenuto in un minibatch; per Block Momentum, misurata in base alla velocità massima ottenuta in un blocco; Fattore medio di accelerazione: il tempo trascorso nella baseline SGD diviso per il tempo trascorso osservato. Queste due metriche vengono introdotte a causa della latenza in I/O può influire notevolmente sulla misurazione del fattore di velocità media, soprattutto quando la sincronizzazione viene eseguita a livello di mini batch. Allo stesso tempo, il fattore di velocità massima è relativamente affidabile.
3. Avvertenze
È consigliabile impostare su
resetSGDMomentumtrue; in caso contrario, spesso comporta la divergenza del criterio di training. La reimpostazione dello slancio SGD su 0 dopo ogni sincronizzazione del modello riduce essenzialmente il contributo degli ultimi minibatches. Pertanto, è consigliabile non usare un grande slancio SGD. Ad esempio, per unsyncPeriodvalore di 120.000, si osserva una perdita significativa di accuratezza se lo slancio usato per SGD è 0,99. Riducendo lo slancio SGD a 0,9, 0,5 o persino disabilitandolo, offre accuratezze simili a quella ottenuta dall'algoritmo SGD standard.Block-Momentum SGD ritarda e distribuisce gli aggiornamenti del modello da un blocco a blocchi successivi. Pertanto, è necessario assicurarsi che le sincronizzazioni del modello vengano eseguite abbastanza spesso nel training. Un controllo rapido consiste nell'usare
blockMomentumAsTimeConstant. È consigliabile che il numero di campioni di training univoci,N, soddisfi l'equazione seguente:N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
L'approssimazione deriva dai fatti seguenti: (1) Blocco Momentum è spesso impostato come (1-1/num_of_workers); (2) log(1-1/num_of_workers)~=-num_of_workers.
6.4 Uso di Block-Momentum in Python
Per abilitare Block-Momentum in Python, in modo analogo all'SGD a 1 bit, l'utente deve creare e passare uno strumento di apprendimento distribuito a blocchi al formatore:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Per un esempio completamente funzionale, vedere l'esempio di ConvNet.
7 Model-Averaging SGD
Model-Averaging SGD è un'implementazione dell'algoritmo di media del modello descritto in [3,4] senza l'uso di sfumature naturali. L'idea è consentire a ogni lavoratore di elaborare un subset di dati, ma la media dei parametri del modello da ogni ruolo di lavoro dopo un periodo specificato.
Model-Averaging SGD generalmente converge più lentamente e a un livello ottimale peggiore, rispetto a SGD a 1 bit e Block-Momentum SGD, quindi non è più consigliato.
Per usare Model-Averaging SGD, è necessario avere un sotto-blocco denominato ModelAveragingSGD nel SGD blocco con le opzioni seguenti:
syncPeriodspecifica il numero di campioni che ogni lavoratore deve elaborare prima che venga eseguita una media del modello. Il valore predefinito è 40.000.
7.1 Uso di Model-Averaging SGD in BrainScript
Per rendere Model-Averaging SGD al massimo efficace ed efficiente, gli utenti devono ottimizzare alcuni iper parametri:
minibatchSizeonbruttsineachrecurrentiter. Si supponga cheni ruoli di lavoro partecipino alla configurazione Model-Averaging SGD, l'implementazione di lettura distribuita corrente caricherà1/n-th del minibatch in ogni ruolo di lavoro. Pertanto, per assicurarsi che ogni ruolo di lavoro produa la stessa velocità effettiva del SGD standard, è necessario ingrandire la dimensionendel minibatch -fold. Per i modelli sottoposti a training usando la casualizzazione in modalità frame, è possibile ottenere questo risultato ampliando inminibatchSizenbase alle volte. Per i modelli viene eseguito il training usando la randomizzazione in modalità sequenza, ad esempio le reti APN, alcuni lettori devono aumentare invecenbruttsineachrecurrentiterdin.learningRatesPerSample. La nostra esperienza indica che per ottenere una convergenza simile allo standard SGD, è necessario aumentare ilearningRatesPerSamplentempi. Una spiegazione è disponibile in [2]. Poiché il tasso di apprendimento è aumentato, è necessaria un'assistenza aggiuntiva per assicurarsi che la formazione non diverga, e questo è infatti il principale avvertimento di Model-Averaging SGD. È possibile usare leAutoAdjustimpostazioni per ricaricare il modello migliore precedente se viene osservato un aumento del criterio di training.avvio caldo. Si scopre che Model-Averaging SGD in genere converge meglio se viene avviato da un modello di inizializzazione sottoposto a training dall'algoritmo SGD standard (senza parallelizzazione). Nelle attività di riconoscimento vocale si ottiene una ragionevole convergenza quando si inizia da modelli di inizializzazione sottoposti a training su 24 ore (8,6 milioni di campioni) a 120 ore (43,2 milioni di campioni) dati con SGD standard.
Di seguito è riportato un esempio di sezione di ModelAveragingSGD configurazione:
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 Uso di Model-Averaging SGD in Python
Queste informazioni sono in fase di aggiornamento.
8 Data-Parallel Training con il server dei parametri
Il server dei parametri è un framework ampiamente usato in Machine Learning distribuito [5][6][7]. Il vantaggio più importante che offre è la formazione parallela asincrona con molti ruoli di lavoro. Introduce il server dei parametri come archivio modelli distribuiti. Anziché sfruttare direttamente le primitive AllReduce per sincronizzare gli aggiornamenti dei parametri tra i ruoli di lavoro, il framework del server dei parametri fornisce agli utenti le interfacce come "Aggiungi" e "Get" per consentire ai ruoli di lavoro locali di aggiornare e recuperare i parametri globali dal server dei parametri. In questo modo, i lavoratori locali non devono aspettare l'uno dall'altro durante il processo di training, che consente di risparmiare molto tempo, soprattutto quando il numero di lavoro è elevato.
Inoltre, poiché i server dei parametri sono un framework distribuito che archivia i parametri del modello, i ruoli di lavoro possono recuperare solo i parametri necessari durante il processo di training mini-batch, ciò offre una buona flessibilità nella progettazione del metodo di training distribuito e migliora anche l'efficienza durante l'esecuzione del training con aggiornamenti del modello sparse. In questa versione ci concentreremo innanzitutto sul training parallelo asincrono, più avanti verranno fornite altre informazioni su come sfruttare il framework del server dei parametri per un training efficiente dei modelli con aggiornamenti sparse.
8.1 Uso di Data-Parallel ASGD
- Per usare i server dei parametri per asincrona SGD (abbr. as ASGD), è necessario compilare CNTK con multiverso supportato, Multiverso è un framework server di parametri generale per l'attività di Machine Learning distribuita sviluppata dal team di Microsoft Research Asia.
Clone Code: clonare il codice nella cartella radice di CNTK usando:
git submodule update --init Source/Multiverso
Linux: compilare con--asgd=yesnel processo di configurazione.Windows: aggiungereCNTK_ENABLE_ASGDall'ambiente di sistema e impostare il valore sutrue
- avvio caldo. In alcuni casi, è preferibile che il training del modello asincrono venga avviato da un modello di inizializzazione ,sottoposto a training da un algoritmo SGD standard. In qualche senso, l'asincrona SGD porta più rumore per il training a causa degli aggiornamenti ritardati dall'asincronismo tra i lavoratori. Alcuni modelli sono molto sensibili a tale disturbo all'inizio, il che potrebbe comportare una divergenza del training del modello. In tale circostanza, è necessario un inizio caldo .
8.2 Configurazione di Data-Parallel ASGD in BrainScript
Per usare Data-Parallel ASGD in CNTK, è necessario avere un sub-block DataParallelASGD nel blocco SGD con le opzioni seguenti
-
syncPeriodPerWorkers. Specifica il numero di campioni che ogni ruolo di lavoro deve elaborare prima di comunicare con i server dei parametri. Il valore predefinito è 256. È consigliabile come dimensione del minibatch. È ovvio che la sincronizzazione frequente comporterà un notevole costo di comunicazione. Nel test non è necessario impostare il valore su 1 nella maggior parte dei casi.
-
usePipeline. Specifica se attivare la pipeline di recupero del modello e il calcolo locale. L'attivazione della pipeline aumenterà significativamente la velocità effettiva complessiva del training perché nasconderà alcuni o tutti i costi di comunicazione. Tuttavia, a volte potrebbe rallentare la velocità di convergenza perché verrà introdotto un ritardo maggiore aggiungendo la pipeline. In generale, l'ora dell'orologio verrà salvata nella maggior parte dei casi con la pipeline.
-
AdjustLearningRateAtBeginning. Secondo il documento pubblicato di recente [5], la formazione ASGD è meno stabile ed è necessario usare un tasso di apprendimento molto inferiore per evitare esplosioni occasionali della perdita di training, quindi il processo di apprendimento diventa meno efficiente. Tuttavia, è stato rilevato che l'uso di una frequenza di apprendimento inferiore non è necessario per tutte le attività. E per queste attività sensibili all'inizio, iniziamo la formazione con una velocità di apprendimento ridotta e la ingrandisciamo gradualmente all'inizio del processo di training fino a raggiungere il tasso di apprendimento iniziale usato nella normale SGD. In questo modo, l'accuratezza finale corrisponderà a SGD con la velocità di ASGD. Questa opzione viene quindi fornita agli utenti asgD per sfruttare questo trucco. Si tratta di un sottoblocco in DataParallelASGD con due parametri: adjustCoefficient e adjustNBMiniBatch. La logica è che la frequenza di apprendimento inizia da regolareCoefficient della frequenza di apprendimento iniziale SGD e aumentare regolandoCoefficient della frequenza di apprendimento iniziale SGD ogni regolaNBMiniBatch mini-batch.
Di seguito è riportato un esempio di sezione di DataParallelASGD configurazione:
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 Configurazione di Data-Parallel ASGD in Python
Queste informazioni sono in fase di aggiornamento.
8.4 Esperimenti
Nella figura seguente vengono illustrati gli esperimenti per testare ASGD con set di dati CIFAR-10. Il modello usato in questo esperimento è una resnet a 20 livelli. L'algoritmo asincrono riduce il costo in attesa di tutti i nodi di lavoro. ASGD, in questo caso, è chiaramente più veloce degli algoritmi sincroni, ad esempio MA e SSGD. *Negli esperimenti tutte le modalità parallele sincronizzano i parametri ogni iterazione (aggiornamento mini-batch). E per SSGD, sono stati usati gli aggiornamenti dei parametri a 32 bit. L'algoritmo asincrono ottiene un vantaggio significativo in termini di velocità effettiva di training misurata dalla velocità di elaborazione di esempio, soprattutto quando il numero del nodo di lavoro raggiunge fino a 16.
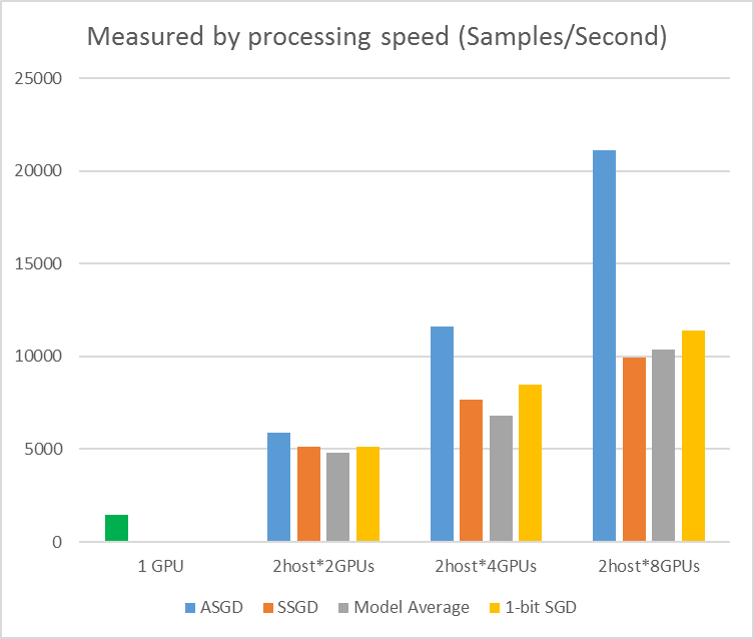 Figura 2.4 velocità per diversi metodi di training
Figura 2.4 velocità per diversi metodi di training
Riferimenti
[1] F. Seide, Hao Fu, Jasha Droppo, Gang Li e Dong Yu, "discesa a 1 bit di sfumatura stochastica e la relativa applicazione al training parallelo di riconoscimento vocale", in Proceedings of Interspeech, 2014.
[2] K. Chen e Q. Huo, "Training scalabile delle macchine di deep learning mediante training incrementale in blocchi con ottimizzazione parallela e filtro dei modelli a blocchi" in Procedura di ICASSP 2016.
[3] M. Zinkevich, M. Weimer, L. Li e A. J. Smola, "Discesa della sfumatura stocastica parallelizzata", in Proceedings of Advances in NIPS, 2010, pp. 2595-2603.
[4] D. Povey, X. Zhang e S. Khudanpur, "Formazione parallela di DNN con sfumatura naturale e media dei parametri", in Atti della Conferenza internazionale sulle rappresentazioni di apprendimento, 2014.
[5] Chen J, Monga R, Bengio S, et al. Revisione di SGD distribuito. ICLR, 2016.
[6] Dean Jeffrey, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Andrew Senior et al. Reti profonde distribuite su larga scala. In Anticipo nei sistemi di elaborazione delle informazioni neurali, pp. 1223-1231. 2012.
[7] Li Mu, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, David G. Andersen e Alexander Smola. "Server di parametri per Machine Learning distribuito". In Big Learning NIPS Workshop, vol. 6, p. 2. 2013.