Rilevamento di oggetti tramite Fast R-CNN
Sommario
- Summary
- Configurazione
- Eseguire l'esempio di toy
- Eseguire il training sui dati VOC Pascal
- Eseguire il training di CNTK Fast R-CNN sui propri dati
- Dettagli tecnici
- Dettagli algoritmo
Riepilogo


Questa esercitazione descrive come usare Fast R-CNN nell'API Python CNTK. R-CNN veloce con BrainScript e cnkt.exe è descritto qui.
Di seguito sono riportate immagini di esempio e annotazioni oggetto per il set di dati di alimentari (a sinistra) e il set di dati VOC Pascal (a destra) usato in questa esercitazione.
Fast R-CNN è un algoritmo di rilevamento degli oggetti proposto da Ross Girshick nel 2015. Il documento viene accettato in ICCV 2015 e archiviato in https://arxiv.org/abs/1504.08083. R-CNN veloce si basa sul lavoro precedente per classificare in modo efficiente le proposte di oggetti usando reti convoluzionali profonde. Rispetto al lavoro precedente, Fast R-CNN usa un'area di schema di pooling di interesse che consente di riutilizzare i calcoli dai livelli convoluzionali.
Eseguire la configurazione
Per eseguire il codice in questo esempio, è necessario un ambiente Python CNTK (vedere qui per informazioni sulla configurazione). Installare i pacchetti aggiuntivi seguenti nell'ambiente Python cntk
pip install opencv-python easydict pyyaml dlib
File binari precompilato per la regressione del rettangolo di selezione e l'eliminazione non massima
La cartella Examples\Image\Detection\utils\cython_modules contiene file binari precompilato necessari per l'esecuzione di Fast R-CNN. Le versioni attualmente contenute nel repository sono Python 3.5 per Windows e Python 3.5, 3.6 per Linux, tutte a 64 bit. Se è necessaria una versione diversa, è possibile compilarla seguendo la procedura descritta in
- Linux: https://github.com/rbgirshick/py-faster-rcnn
- Windows: https://github.com/MrGF/py-faster-rcnn-windows
Copiare i file binari generati cython_bbox e (e/o gpu_nms) da $FRCN_ROOT/lib/utils a $CNTK_ROOT/Examples/Image/Detection/utils/cython_modulescpu_nms .
Dati di esempio e modello di base
Si usa un modello AlexNet con training preliminare come base per il training Fast-R-CNN (per VGG o altri modelli di base, vedere Uso di un modello di base diverso. Sia il set di dati di esempio che il modello AlexNet con training preliminare possono essere scaricati eseguendo il comando Python seguente dalla cartella FastRCNN:
python install_data_and_model.py
- Informazioni su come usare un modello di base diverso
- Informazioni su come eseguire Fast R-CNN sui dati VOC Pascal
- Informazioni su come eseguire Fast R-CNN sui propri dati
Eseguire l'esempio di toy
Per eseguire il training e valutare l'esecuzione fast R-CNN
python run_fast_rcnn.py
I risultati per il training con 2000 ROI su Grocery usando AlexNet come modello di base dovrebbero essere simili ai seguenti:
AP for gerkin = 1.0000
AP for butter = 1.0000
AP for joghurt = 1.0000
AP for eggBox = 1.0000
AP for mustard = 1.0000
AP for champagne = 1.0000
AP for orange = 1.0000
AP for water = 0.5000
AP for avocado = 1.0000
AP for tomato = 1.0000
AP for pepper = 1.0000
AP for tabasco = 1.0000
AP for onion = 1.0000
AP for milk = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
Mean AP = 0.9479
Per visualizzare i rettangoli di selezione stimati e le etichette nelle immagini aperte FastRCNN_config.py dalla FastRCNN cartella e impostare
__C.VISUALIZE_RESULTS = True
Le immagini verranno salvate nella FastRCNN/Output/Grocery/ cartella se si esegue python run_fast_rcnn.py.
Eseguire il training su Pascal VOC
Per scaricare i dati Pascal e creare i file di annotazione per Pascal in formato CNTK, eseguire gli script seguenti:
python Examples/Image/DataSets/Pascal/install_pascalvoc.py
python Examples/Image/DataSets/Pascal/mappings/create_mappings.py
Modificare in dataset_cfg nel get_configuration() metodo di run_fast_rcnn.py in
from utils.configs.Pascal_config import cfg as dataset_cfg
A questo momento è possibile eseguire il training dei dati Pascal VOC 2007 usando python run_fast_rcnn.py. Tenere presente che il training potrebbe richiedere un po' di tempo.
Eseguire il training sui propri dati
Preparare un set di dati personalizzato
Opzione 1: Strumento di assegnazione di tag agli oggetti visivi (scelta consigliata)
Visual Object Tagging Tool (VOTT) è uno strumento di annotazione multipiattaforma per contrassegnare asset video e immagini.

VOTT offre le funzionalità seguenti:
- Assegnazione di tag e rilevamento assistito da computer di oggetti nei video tramite l'algoritmo di rilevamento Camshift.
- Esportazione di tag e asset in formato Fast-RCNN CNTK per il training di un modello di rilevamento oggetti.
- Esecuzione e convalida di un modello di rilevamento oggetti CNTK sottoposto a training in nuovi video per generare modelli più avanzati.
Come annotare con VOTT:
- Scaricare la versione più recente
- Seguire il file Leggimi per eseguire un processo di assegnazione di tag
- Dopo aver tagging Esporta tag nella directory del set di dati
Opzione 2: Uso degli script di annotazione
Per eseguire il training di un modello CNTK Fast R-CNN nel proprio set di dati, vengono forniti due script per annotare le aree rettangolari nelle immagini e assegnare etichette a queste aree.
Gli script archivieranno le annotazioni nel formato corretto come richiesto dal primo passaggio dell'esecuzione di Fast R-CNN (A1_GenerateInputROIs.py).
In primo luogo, archiviare le immagini nella struttura di cartelle seguente
<your_image_folder>/negative- immagini usate per il training che non contengono oggetti<your_image_folder>/positive- immagini usate per il training che contengono oggetti<your_image_folder>/testImages- immagini usate per il test che contengono oggetti
Per le immagini negative non è necessario creare annotazioni. Per le altre due cartelle, usare gli script forniti:
- Eseguire
C1_DrawBboxesOnImages.pyper disegnare rettangoli delimitatori sulle immagini.- Nel set
imgDir = <your_image_folder>di script (/positiveo/testImages) prima dell'esecuzione. - Aggiungere annotazioni usando il cursore del mouse. Dopo che tutti gli oggetti in un'immagine vengono annotati, premendo il tasto 'n' viene scritto il file con estensione bboxes.txt e quindi si passa all'immagine successiva, 'u' annulla (ad esempio rimuove) l'ultimo rettangolo e 'q' chiude lo strumento di annotazione.
- Nel set
- Eseguire
C2_AssignLabelsToBboxes.pyper assegnare etichette ai rettangoli di selezione.- Nel set
imgDir = <your_image_folder>di script (/positiveo/testImages) prima di eseguire... - ... e adattare le classi nello script per riflettere le categorie di oggetti, ad esempio
classes = ("dog", "cat", "octopus"). - Lo script carica questi rettangoli con annotazioni manuali per ogni immagine, li visualizza uno per uno e chiede all'utente di fornire la classe oggetto facendo clic sul rispettivo pulsante a sinistra della finestra. Le annotazioni di verità di base contrassegnate come "nondecidite" o "exclude" sono completamente escluse dall'ulteriore elaborazione.
- Nel set
Eseguire il training su un set di dati personalizzato
Dopo aver archiviato le immagini nella struttura di cartelle descritta e annotandole, eseguire
python Examples/Image/Detection/utils/annotations/annotations_helper.py
dopo aver modificato la cartella in tale script nella cartella dati. Creare infine un MyDataSet_config.py oggetto nella utils\configs cartella seguendo gli esempi esistenti:
__C.CNTK.DATASET == "YourDataSet":
__C.CNTK.MAP_FILE_PATH = "../../DataSets/YourDataSet"
__C.CNTK.CLASS_MAP_FILE = "class_map.txt"
__C.CNTK.TRAIN_MAP_FILE = "train_img_file.txt"
__C.CNTK.TEST_MAP_FILE = "test_img_file.txt"
__C.CNTK.TRAIN_ROI_FILE = "train_roi_file.txt"
__C.CNTK.TEST_ROI_FILE = "test_roi_file.txt"
__C.CNTK.NUM_TRAIN_IMAGES = 500
__C.CNTK.NUM_TEST_IMAGES = 200
__C.CNTK.PROPOSAL_LAYER_SCALES = [8, 16, 32]
Si noti che __C.CNTK.PROPOSAL_LAYER_SCALES non viene usato per Fast R-CNN, solo per Faster R-CNN.
Per eseguire il training e valutare Fast R-CNN sui dati modificare il dataset_cfg nel get_configuration() metodo di run_fast_rcnn.py in
from utils.configs.MyDataSet_config import cfg as dataset_cfg
ed eseguire python run_fast_rcnn.py.
Dettagli tecnici
L'algoritmo Fast R-CNN è illustrato nella sezione Dettagli algoritmo insieme a una panoramica generale del modo in cui viene implementato nell'API Python CNTK. Questa sezione è incentrata sulla configurazione di Fast R-CNN e su come usare modelli di base diversi.
Parametri
I parametri sono raggruppati in tre parti:
- Parametri di rilevamento (vedere
FastRCNN/FastRCNN_config.py) - Parametri del set di dati (vedere ad esempio
utils/configs/Grocery_config.py) - Parametri del modello di base (vedere ad esempio
utils/configs/AlexNet_config.py)
Le tre parti vengono caricate e unite nel get_configuration() metodo in run_fast_rcnn.py. In questa sezione verranno illustrati i parametri del rilevatore. I parametri del set di dati sono descritti qui, i parametri del modello di base qui. Di seguito vengono descritti i parametri più importanti in FastRCNN_config.py. Tutti i parametri vengono anche commentati nel file. La configurazione usa il EasyDict pacchetto che consente di accedere facilmente ai dizionari annidati.
# Number of regions of interest [ROIs] proposals
__C.NUM_ROI_PROPOSALS = 200 # use 2000 or more for good results
# the minimum IoU (overlap) of a proposal to qualify for training regression targets
__C.BBOX_THRESH = 0.5
# Maximum number of ground truth annotations per image
__C.INPUT_ROIS_PER_IMAGE = 50
__C.IMAGE_WIDTH = 850
__C.IMAGE_HEIGHT = 850
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = True
# If set to 'True' conv layers weights from the base model will be trained, too
__C.TRAIN_CONV_LAYERS = True
Le proposte ROI vengono calcolate in tempo reale nel primo periodo usando l'implementazione della ricerca selettiva del dlib pacchetto. Il numero di proposte generate è controllato dal __C.NUM_ROI_PROPOSALS parametro . È consigliabile utilizzare circa 2000 proposte. L'intestazione di regressione viene sottoposta a training solo su quelle roI che hanno una sovrapposizione (IoU) con un box di verità a terra di almeno __C.BBOX_THRESH.
__C.INPUT_ROIS_PER_IMAGE specifica il numero massimo di annotazioni di verità di terra per ogni immagine. CNTK richiede attualmente di impostare un numero massimo. Se sono presenti meno annotazioni, queste verranno riempite internamente. __C.IMAGE_WIDTH e __C.IMAGE_HEIGHT sono le dimensioni usate per ridimensionare e riempire le immagini di input.
__C.TRAIN.USE_FLIPPED = True aumenta i dati di training capovolgendo tutte le immagini ogni altro periodo, ad esempio il primo periodo ha tutte le immagini regolari, la seconda ha tutte le immagini capovolte e così via. __C.TRAIN_CONV_LAYERS determina se i livelli convoluzionali, dall'input alla mappa delle funzionalità convoluzionali, verranno sottoposti a training o fissi. La correzione dei pesi del livello conv significa che i pesi del modello di base vengono acquisiti e non modificati durante il training. È anche possibile specificare il numero di livelli conv di cui si vuole eseguire il training, vedere la sezione Uso di un modello di base diverso.
# NMS threshold used to discard overlapping predicted bounding boxes
__C.RESULTS_NMS_THRESHOLD = 0.5
# If set to True the following two parameters need to point to the corresponding files that contain the proposals:
# __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE
# __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE
__C.USE_PRECOMPUTED_PROPOSALS = False
__C.RESULTS_NMS_THRESHOLD è la soglia di NMS usata per ignorare i rettangoli di delimitazione stimati sovrapposti nella valutazione. Una soglia inferiore produce meno rimozioni e quindi riquadri delimitatori più stimati nell'output finale. Se si imposta __C.USE_PRECOMPUTED_PROPOSALS = True il lettore leggerà le roI pre-calcolate dai file di testo. Questo è ad esempio usato per il training sui dati VOC Pascal. I nomi di __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE file e __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE sono specificati in Examples/Image/Detection/utils/configs/Pascal_config.py.
# The basic segmentation is performed kvals.size() times. The k parameter is set (from, to, step_size)
__C.roi_ss_kvals = (10, 500, 5)
# When doing the basic segmentations prior to any box merging, all
# rectangles that have an area < min_size are discarded. Therefore, all outputs and
# subsequent merged rectangles are built out of rectangles that contain at
# least min_size pixels. Note that setting min_size to a smaller value than
# you might otherwise be interested in using can be useful since it allows a
# larger number of possible merged boxes to be created
__C.roi_ss_min_size = 9
# There are max_merging_iterations rounds of neighboring blob merging.
# Therefore, this parameter has some effect on the number of output rectangles
# you get, with larger values of the parameter giving more output rectangles.
# Hint: set __C.CNTK.DEBUG_OUTPUT=True to see the number of ROIs from selective search
__C.roi_ss_mm_iterations = 30
# image size used for ROI generation
__C.roi_ss_img_size = 200
I parametri precedenti configurano la ricerca selettiva di dlib. Per informazioni dettagliate, vedere la home page di dlib. I parametri aggiuntivi seguenti vengono usati per filtrare le ROIs w.r.t. minimum e maximum side length, area e proporzioni generate.
# minimum relative width/height of an ROI
__C.roi_min_side_rel = 0.01
# maximum relative width/height of an ROI
__C.roi_max_side_rel = 1.0
# minimum relative area of an ROI
__C.roi_min_area_rel = 0.0001
# maximum relative area of an ROI
__C.roi_max_area_rel = 0.9
# maximum aspect ratio of an ROI vertically and horizontally
__C.roi_max_aspect_ratio = 4.0
# aspect ratios of ROIs for uniform grid ROIs
__C.roi_grid_aspect_ratios = [1.0, 2.0, 0.5]
Se la ricerca selettiva restituisce più ROI di quelle richieste, vengono campionate in modo casuale. Se viene restituito un minor numero di ROI aggiuntivi in una griglia regolare usando l'oggetto specificato __C.roi_grid_aspect_ratios.
Uso di un modello di base diverso
Per usare un modello di base diverso, è necessario scegliere una configurazione del modello diversa nel get_configuration() metodo di run_fast_rcnn.py. Due modelli sono supportati immediatamente:
# for VGG16 base model use: from utils.configs.VGG16_config import cfg as network_cfg
# for AlexNet base model use: from utils.configs.AlexNet_config import cfg as network_cfg
Per scaricare il modello VGG16, usare lo script di download in <cntkroot>/PretrainedModels:
python download_model.py VGG16_ImageNet_Caffe
Se si vuole usare un altro modello di base diverso, ad esempio, è necessario copiare il file utils/configs/VGG16_config.py di configurazione e modificarlo in base al modello di base:
# model config
__C.MODEL.BASE_MODEL = "VGG16"
__C.MODEL.BASE_MODEL_FILE = "VGG16_ImageNet_Caffe.model"
__C.MODEL.IMG_PAD_COLOR = [103, 116, 123]
__C.MODEL.FEATURE_NODE_NAME = "data"
__C.MODEL.LAST_CONV_NODE_NAME = "relu5_3"
__C.MODEL.START_TRAIN_CONV_NODE_NAME = "pool2" # __C.MODEL.FEATURE_NODE_NAME
__C.MODEL.POOL_NODE_NAME = "pool5"
__C.MODEL.LAST_HIDDEN_NODE_NAME = "drop7"
__C.MODEL.FEATURE_STRIDE = 16
__C.MODEL.RPN_NUM_CHANNELS = 512
__C.MODEL.ROI_DIM = 7
Per esaminare i nomi dei nodi del modello di base, è possibile usare il plot() metodo da cntk.logging.graph. Si noti che i modelli ResNet non sono attualmente supportati perché il pooling di roi in CNTK non supporta ancora il pooling medio del roi.
Dettagli algoritmo
Fast R-CNN
Le reti R-CNN per il rilevamento degli oggetti sono state presentate per la prima volta nel 2014 da Ross Girshick et al., e sono state presentate per superare le precedenti approcci all'avanguardia su uno dei principali problemi di riconoscimento degli oggetti nel campo: Pascal VOC. Da allora sono stati pubblicati due documenti di follow-up che contengono miglioramenti significativi della velocità: Fast R-CNN e Faster R-CNN.
L'idea di base di R-CNN consiste nell'acquisire una rete neurale profonda che è stata originariamente sottoposta a training per la classificazione delle immagini usando milioni di immagini con annotazioni e modificarla allo scopo del rilevamento degli oggetti. L'idea di base del primo documento R-CNN è illustrata nella figura seguente (tratto dal documento): (1) Dato un'immagine di input, (2) in un primo passaggio, vengono generate numerose proposte di area. (3) Queste proposte di regione, o regioni di interessi (ROI), vengono quindi inviate in modo indipendente attraverso la rete che restituisce un vettore di valori a virgola mobile 4096 per ogni ROI. Infine, (4) viene appreso un classificatore che accetta la rappresentazione del ROI float 4096 come input e restituisce un'etichetta e un'attendibilità per ogni ROI.

Sebbene questo approccio funzioni bene in termini di accuratezza, è molto costoso calcolare poiché la rete neurale deve essere valutata per ogni ROI. R-CNN veloce risolve questo svantaggio valutando solo la maggior parte della rete (per essere specifici: i livelli di convoluzione) una sola volta per ogni immagine. Secondo gli autori, questo porta a una velocità di 213 volte durante il test e una velocità di 9 volte durante il training senza perdita di accuratezza. A tale scopo, si usa un livello di pooling ROI che proietta il ROI sulla mappa delle funzionalità convoluzionale ed esegue il pooling massimo per generare le dimensioni di output desiderate previste dal livello seguente.
Nell'esempio AlexNet usato in questa esercitazione il livello di pooling ROI viene inserito tra l'ultimo livello convoluzionale e il primo livello completamente connesso. Nel codice DELL'API Python CNTK illustrato di seguito viene realizzato clonando due parti della rete, e conv_layers .fc_layers L'immagine di input viene quindi prima normalizzata, sottoposta a push attraverso , conv_layersil roipooling livello e fc_layers infine le teste di stima e regressione vengono aggiunte che stimano rispettivamente l'etichetta di classe e i coefficienti di regressione per roi candidato.
def create_fast_rcnn_model(features, roi_proposals, label_targets, bbox_targets, bbox_inside_weights, cfg):
# Load the pre-trained classification net and clone layers
base_model = load_model(cfg['BASE_MODEL_PATH'])
conv_layers = clone_conv_layers(base_model, cfg)
fc_layers = clone_model(base_model, [cfg["MODEL"].POOL_NODE_NAME], [cfg["MODEL"].LAST_HIDDEN_NODE_NAME], clone_method=CloneMethod.clone)
# Normalization and conv layers
feat_norm = features - Constant([[[v]] for v in cfg["MODEL"].IMG_PAD_COLOR])
conv_out = conv_layers(feat_norm)
# Fast RCNN and losses
cls_score, bbox_pred = create_fast_rcnn_predictor(conv_out, roi_proposals, fc_layers, cfg)
detection_losses = create_detection_losses(...)
pred_error = classification_error(cls_score, label_targets, axis=1)
return detection_losses, pred_error
def create_fast_rcnn_predictor(conv_out, rois, fc_layers, cfg):
# RCNN
roi_out = roipooling(conv_out, rois, cntk.MAX_POOLING, (6, 6), spatial_scale=1/16.0)
fc_out = fc_layers(roi_out)
# prediction head
cls_score = plus(times(fc_out, W_pred), b_pred, name='cls_score')
# regression head
bbox_pred = plus(times(fc_out, W_regr), b_regr, name='bbox_regr')
return cls_score, bbox_pred
L'implementazione originale di Caffe usata nei documenti R-CNN è disponibile in GitHub: RCNN, Fast R-CNN e Faster R-CNN.
Training SVM e NN
Patrick Buehler fornisce istruzioni su come eseguire il training di una SVM sull'output di CNTK Fast R-CNN (usando le funzionalità 4096 dell'ultimo livello completamente connesso) e una discussione sui vantaggi e sui svantaggi qui.
Ricerca selettiva
Ricerca selettiva è un metodo per trovare un ampio set di possibili posizioni degli oggetti in un'immagine, indipendentemente dalla classe dell'oggetto effettivo. Funziona raggruppando i pixel di immagine in segmenti e quindi eseguendo il clustering gerarchico per combinare segmenti dello stesso oggetto in proposte di oggetto.



Per integrare le ROI rilevate da Ricerca selettiva, aggiungiamo roI che coprono l'immagine in scala e proporzioni diverse. L'immagine a sinistra mostra un output di esempio di Ricerca selettiva, in cui ogni possibile posizione dell'oggetto viene visualizzata da un rettangolo verde. I ROI troppo piccoli, troppo grandi e così via, vengono eliminati (al centro) e infine le ROI che coprono in modo uniforme l'immagine vengono aggiunte (a destra). Questi rettangoli vengono quindi usati come aree di interesse (ROI) nella pipeline R-CNN.
L'obiettivo della generazione di ROI è quello di trovare un piccolo set di ROI che, tuttavia, copre il maggior numero possibile di oggetti nell'immagine. Questo calcolo deve essere sufficientemente rapido, mentre allo stesso tempo trovare posizioni degli oggetti su scale e proporzioni diverse. Ricerca selettiva è stata mostrata per eseguire correttamente questa attività, con una buona precisione per velocizzare i compromessi.
NMS (eliminazione non massima)
I metodi di rilevamento oggetti spesso generano più rilevamenti che coprono completamente o parzialmente lo stesso oggetto in un'immagine.
Queste ISTANZE di ISTANZA devono essere unite per poter contare gli oggetti e ottenere le posizioni esatte nell'immagine.
Questa operazione viene eseguita tradizionalmente usando una tecnica denominata Non Maximum Suppression (NMS). La versione di NMS usata (e che è stata usata anche nelle pubblicazioni R-CNN) non unisce le ROI, ma tenta invece di identificare quali ROI meglio coprono le posizioni reali di un oggetto e rimuove tutte le altre ROI. Questa operazione viene implementata selezionando in modo iterativo il ROI con maggiore attendibilità e rimuovendo tutte le altre ROI che si sovrappongono significativamente a questo ROI e vengono classificate come della stessa classe. La soglia per la sovrapposizione può essere impostata in PARAMETERS.py (dettagli).
Risultati del rilevamento prima (a sinistra) e dopo (destra) Eliminazione non massima:


mAP (media precisione media)
Una volta eseguito il training, la qualità del modello può essere misurata usando criteri diversi, ad esempio precisione, richiamo, accuratezza, sotto curva area e così via. Una metrica comune usata per la sfida di riconoscimento degli oggetti VOC Pascal consiste nel misurare la precisione media (AP) per ogni classe. La descrizione seguente della precisione media viene ricavata da Everingham et. La precisione media (mAP) viene calcolata prendendo la media rispetto ai punti di accesso di tutte le classi.
Per un'attività e una classe specifica, la curva di precisione/richiamo viene calcolata dall'output classificato di un metodo. Il richiamo viene definito come percentuale di tutti gli esempi positivi classificati al di sopra di un determinato rango. La precisione è la proporzione di tutti gli esempi sopra elencati che provengono dalla classe positiva. L'API riepiloga la forma della curva di precisione/richiamo ed è definita come precisione media in un set di undici livelli di richiamo equamente spaziati [0,0,1, . . . ,1]:
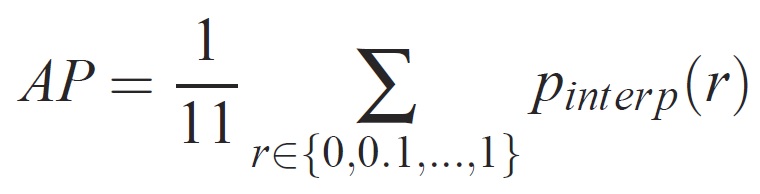
La precisione a ogni livello di richiamo r viene interpolata prendendo la precisione massima misurata per un metodo per il quale il richiamo corrispondente supera r:
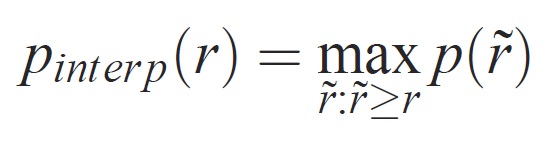
dove p( ̃r) è la precisione misurata al richiamo ̃r. L'intenzione di interpolare la curva di precisione/richiamo in questo modo consiste nel ridurre l'impatto dei "movimenti" nella curva di precisione/richiamo, causati da piccole variazioni nella classificazione degli esempi. Si noti che per ottenere un punteggio elevato, un metodo deve avere precisione a tutti i livelli di richiamo: questo penalizza i metodi che recuperano solo un sottoinsieme di esempi con precisione elevata (ad esempio visualizzazioni laterali delle automobili).