Ulteriori informazioni su tipi di informazioni sensibili basati sulla corrispondenza esatta dei dati
I tipi di informazioni sensibili (SIT) vengono usati per identificare i dati sensibili in modo da evitare che vengano condivisi inavvertitamente o in modo inappropriato. Vengono usati anche per individuare i dati rilevanti in eDiscovery e per applicare azioni di governance a determinati tipi di informazioni. Si definisce un SIT personalizzato in base a:
- criteri
- evidenza di parole chiave come dipendente, numero di previdenza sociale o ID
- vicinanza del carattere all'evidenza in un modello specifico
- livello di probabilità
Ma cosa succede se si desidera un SIT personalizzato che usa valori di dati esatti o quasi esatti, anziché uno che trova corrispondenze basate su modelli generici? Con la classificazione basata su Exact Data Match (EDM), è possibile creare un tipo di informazioni sensibili personalizzato progettato per:
- essere dinamico e facilmente aggiornabile
- risultato di un minor numero di falsi positivi
- usare dati sensibili strutturati
- gestire le informazioni sensibili in modo più sicuro, senza condividerle con nessuno, tra cui Microsoft
- essere usato con più servizi cloud Microsoft
Consiglio
Se non si è un cliente E5, usare la versione di valutazione delle soluzioni Microsoft Purview di 90 giorni per esplorare in che modo funzionalità aggiuntive di Purview possono aiutare l'organizzazione a gestire le esigenze di sicurezza e conformità dei dati. Iniziare ora dall'hub delle versioni di valutazione Portale di conformità di Microsoft Purview. Informazioni dettagliate sull'iscrizione e le condizioni di valutazione.
La classificazione basata su EDM consente di creare SIT personalizzati che fanno riferimento a valori esatti in un database di informazioni riservate. Il database può essere aggiornato ogni giorno e può contenere fino a 100 milioni di righe di dati. Quindi, man mano che dipendenti, pazienti e clienti vanno e vengono e cambiano i record, i tipi di informazioni sensibili personalizzati rimangono aggiornati e applicabili. È inoltre possibile usare la classificazione basata su EDM con criteri, ad esempio criteri di Prevenzione della perdita dei dati Microsoft Purview o criteri di file di Microsoft Cloud App Security.
Il diagramma seguente illustra i funzionamenti fondamentali della classificazione EDM:
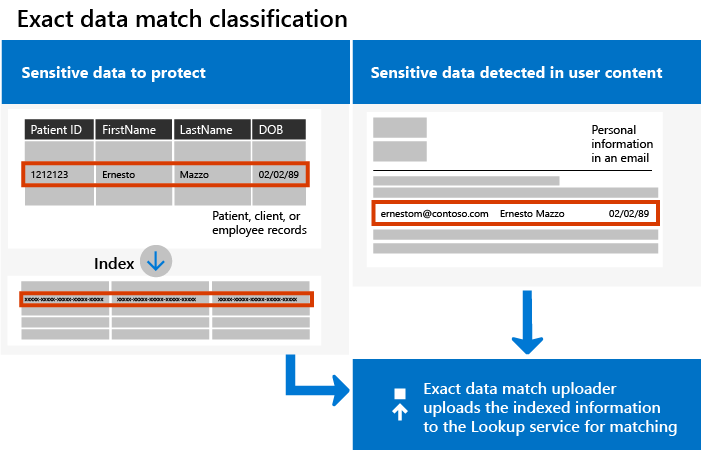
Nota
Microsoft Purview Information Protection supporta le lingue seguenti che usano set di caratteri a byte doppio:
- Cinese (semplificato)
- Cinese (tradizionale)
- Coreano
- Giapponese
Il supporto è disponibile per i tipi di informazioni sensibili. Per altre informazioni, vedere Supporto di Information Protection per set di caratteri a due byte: Note sulla versione (anteprima).
Cosa c'è di diverso in un SIT EDM
Quando si usano i SIT EDM, è utile comprendere alcuni concetti specifici.
Schema
Uno schema è un file XML. Microsoft Purview usa lo schema per determinare se i dati contengono o meno stringhe che corrispondono a quelle che i tipi di informazioni sensibili sono progettati per rilevare.
Il file XML dello schema definisce:
- Nome dello schema, in seguito denominato DataStore.
- Nomi di campo contenuti nella tabella di origine delle informazioni riservate. Esiste un mapping 1:1 dei nomi dei campi dello schema ai nomi di colonna nella tabella di origine delle informazioni riservate.
- Quali campi di prova corroborativi richiedono la modalità di corrispondenza multi-token.
- Quali campi dati sono ricercabili.
- Indica se le corrispondenze configurabili sono supportate per ogni campo. Una corrispondenza configurabile è una corrispondenza con parametri che modificano una ricerca, ad esempio ignorando i delimitatori e la distinzione tra maiuscole e minuscole nei valori ricercati.
Tabella dell'origine delle informazioni riservate
La tabella di origine delle informazioni riservate contiene i valori cercati da EDM SIT. La tabella è costituita da colonne e righe. Le intestazioni di colonna sono i nomi dei campi, le righe sono istanze di elementi e ogni cella di una riga contiene i valori per l'istanza dell'elemento per tale campo.
Di seguito è riportato un semplice esempio di tabella di origine delle informazioni riservate.
| Nome | Cognome | Date of Birth |
|---|---|---|
| Isaia | Langer | 05-05-1960 |
| Ana | Bowman | 11-24-1971 |
| Oscar | Ward | 02-12-1998 |
Pacchetto di regole
Ogni tipo di informazioni riservate ha un pacchetto di regole. Usare il pacchetto di regole in un SIT EDM per definire i vari componenti di EDM SIT. Nella tabella seguente viene fornita una descrizione di ogni componente.
| Componente | Descrizione |
|---|---|
| Corrisponde | Specifica l'elemento primario (campo dati) da utilizzare nella ricerca esatta. Può essere un'espressione regolare con o senza convalida del checksum, un elenco di parole chiave, un dizionario di parole chiave o una funzione. |
| Classificazione | Specifica la corrispondenza del tipo di informazioni riservate che attiva una ricerca EDM. |
| Elementi di supporto | Elementi che, se trovati, forniscono prove che consentono di aumentare la confidenza della corrispondenza. Ad esempio, l'occorrenza di un cognome in prossimità di un numero effettivo di previdenza sociale. Un elemento di supporto può essere un'espressione regolare con o senza una convalida checksum, un elenco di parole chiave, un dizionario di parole chiave o una corrispondenza di stringa a token singolo o multi token. |
| Livello di probabilità (Alto, Medio, Basso) |
Indicazione della quantità di prove di supporto rilevate oltre all'elemento primario. Maggiore è l'evidenza di supporto che contiene un elemento, maggiore è la probabilità che un elemento corrispondente contenga le informazioni sensibili che stai cercando. Per altre informazioni sui livelli di attendibilità, vedere Parti fondamentali di un tipo di informazioni riservate. |
| Prossimità | Numero di caratteri tra l'elemento primario e l'elemento di supporto. |
Si forniscono uno schema e dati personalizzati
Microsoft Purview include molti SIT predefiniti . Questi SIT sono dotati di schemi, modelli REGEX, parole chiave e livelli di attendibilità. Tuttavia, con i SIT EDM, è necessario definire lo schema, nonché i campi primario e secondario che identificano gli elementi sensibili. Poiché lo schema e i valori dei dati primari e secondari sono tutti altamente sensibili, è possibile crittografarli tramite una funzione hash che include un valore salt generato in modo casuale o fornito automaticamente. Solo i valori hash vengono caricati nel servizio, quindi i dati sensibili non sono mai aperti.
Elementi di supporto primario e secondario
Quando si crea un sit EDM, si definisce un campo elemento primario nel pacchetto di regole. EDM cerca quindi l'elemento primario in tutto il contenuto. In modo che EDM possa rilevarli, gli elementi primari devono essere individuabili tramite un SIT esistente.
Nota
Per un elenco completo dei SIT disponibili, vedere Definizioni di entità del tipo di informazioni riservate
È necessario trovare un SIT predefinito che rilevi le informazioni sensibili che si desidera vengano rilevate da EDM SIT. Ad esempio, se lo schema SIT EDM ha il numero di previdenza sociale degli Stati Uniti come elemento primario, quando si crea lo schema EDM, lo si è associato al SIT del numero di previdenza sociale (SSN) degli Stati Uniti . Per essere rilevati, gli elementi primari devono seguire un modello definito.
Quando l'elemento primario viene trovato in un elemento analizzato, EDM cerca quindi gli elementi secondari (detti anche elementi di supporto ). A differenza degli elementi primari, gli elementi secondari hanno la possibilità di seguire un modello. Se gli elementi secondari contengono più token, questi elementi devono essere associati a un sit in grado di rilevare il contenuto o che possono essere configurati per la corrispondenza multi-token. In tutti i casi, gli elementi secondari devono trovarsi all'interno di una certa prossimità all'elemento primario affinché venga rilevata una corrispondenza.
Funzionamento della corrispondenza
EDM funziona confrontando le stringhe nei documenti e nei messaggi di posta elettronica con i valori nella tabella di origine delle informazioni riservate. Usa questo confronto per determinare se i valori nel contenuto analizzato sono presenti nella tabella. La determinazione viene eseguita confrontando gli hash crittografici unidirezionali.
Consiglio
È possibile usare sia i SIT EDM che i SIT predefiniti su cui si basano, insieme nelle regole DLP per migliorare il rilevamento dei dati sensibili. Usare IL SIT EDM con livelli di confidenza più elevati e il sit predefinito con livelli di confidenza inferiori. Ad esempio, usare un SIT EDM che cerca il numero di previdenza sociale e altri dati di supporto con requisiti rigorosi con alta attendibilità. Se configurato per corrispondenze con attendibilità elevata, EDM genera una corrispondenza DLP quando vengono rilevate solo alcune istanze. Per attivare una corrispondenza DLP quando viene rilevato un numero maggiore di occorrenze, usare un SIT predefinito, ad esempio il numero di previdenza sociale degli Stati Uniti.
Funzionamento degli elementi di supporto con EDM
Come illustrato in What's different in an EDM SIT, gli elementi di supporto sono elementi che, se trovati, forniscono prove che consentono di aumentare la confidenza della corrispondenza.
Con il supporto per i SIT EDM, è possibile cercare e rilevare gli elementi di supporto composti da più campi. Le corrispondenze degli elementi di supporto possono essere costituite da elenchi di parole chiave, dizionari di parole chiave, stringhe alfanumeriche singole o stringhe multi-token.
Verrà ora esaminato un esempio. Si supponga di voler rilevare i numeri di previdenza sociale degli Stati Uniti. Per aumentare la probabilità di corrispondenza, gli elementi di supporto includono first name, last namee date of birth (DoB). Pertanto, la tabella di origine ha un aspetto simile al seguente:
| SSN | FirstName | LastName | Dob |
|---|---|---|---|
| 987-65-4320 | Isaia | Langer | 05-05-1960 |
| 078-05-1120 | Ana | Bowman | 11-24-1971 |
| 219-09-9999 | Oscar | Ward | 02-12-1998 |
Quando si cercano elementi di supporto corrispondenti in un file protetto, il sit EDM controlla ogni elemento di supporto (sia singolarmente che in combinazione) una volta rilevato l'elemento primario.
Si supporvi, ad esempio, che venga rilevato il primo numero di previdenza sociale. La funzionalità corrispondenza dati esatta cerca quindi combinazioni di elementi di supporto in tutte le colonne della tabella di origine:
- Isaia
- Langer
- 05-05-1960
- Isaiah Langer
- Isaia 05-05-1960
- Langer 05-05-1960
- Isaiah Langer 05-05-1960
Corrispondenza multi-token
La corrispondenza multi-token è progettata per essere usata quando il campo di prova corroborativo contiene valori multi-token, ma la corrispondenza di tali valori con un SIT non è facilmente realizzabile. Ad esempio, quando si dispone di un Address campo contenente valori come 1 Microsoft Way, Redmond, WA o 123 Main Street, New York, NY.
Questa funzionalità consente a EDM di confrontare gli hash delle parole consecutive nel contenuto con gli hash dei campi multi-token nell'origine dati. Se sono identici, EDM produce una corrispondenza. In questo modo, EDM può rilevare campi multi-token, ad esempio nomi, indirizzi, condizioni mediche o qualsiasi altro campo di evidenza corroborante che potrebbe contenere più di una parola, purché siano contrassegnati come multi-token nello schema EDM.
Ad esempio, se si seleziona la corrispondenza multi-token come opzione di corrispondenza, si ottengono due vantaggi aggiuntivi:
- I criteri rileveranno il contenuto corrispondente a più campi nelle colonne della tabella di origine.
- La tabella di origine può includere campi con valori stringa costituiti da un numero preconfigurato di parole. La tabella seguente mostra una tabella di origine di esempio:
| SSN | Nome | Via e numero civico |
|---|---|---|
| 987-65-4320 | Isaiah Langer | 1432 Lincoln Road |
| 078-05-1120 | Ana Bowman | 8250 First Street |
| 219-09-9999 | Oscar Ward | 424 205th Avenue |
Con la corrispondenza multi-token, i campi Name e Street Address vengono confrontati sia come stringhe di elementi di supporto indipendenti che in combinazione come singoli campi. Di conseguenza, quando vengono confrontate come stringhe multi-token come elementi di supporto per il numero di previdenza sociale 987-65-4320, le corrispondenze sono:
- Isaiah Langer
- 1432 Lincoln Road
Se abbinata in combinazione, la corrispondenza è simile alla seguente:
- Isaiah Langer + 1432 Lincoln Road
La corrispondenza multi-token è supportata anche per i set di caratteri a byte doppio, che in genere non usano spazi per separare le parole.
Servizi supportati da EDM
| Servizio | Posizioni |
|---|---|
| Prevenzione della perdita dei dati di Microsoft Purview | - SharePoint - OneDrive - Chat di Teams - Exchange Online - Dispositivi |
| Microsoft Defender for Cloud Apps | - SharePoint - OneDrive |
| Etichettatura automatica (lato servizio) | - SharePoint - OneDrive - Exchange Online |
| Etichettatura automatica (lato client) | - Word - Excel - PowerPoint - Client desktop di Exchange |
| Chiave gestita dal cliente | - SharePoint - OneDrive - Teams Chat - Exchange Online - Word - Excel - PowerPoint - Client desktop di Exchange - Dispositivi |
| eDiscovery | - SharePoint - OneDrive - Teams Chat - Exchange Online - Word - Excel - PowerPoint - Client desktop di Exchange |
| Gestione dei rischi Insider | - SharePoint - OneDrive - Teams Chat - Exchange Online - Word - Excel - PowerPoint - Client desktop di Exchange |