Introduzione ai cluster Big Data di SQL Server
Si applica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
In SQL Server 2019 (15.x) i cluster Big Data di SQL Server consentono di distribuire cluster scalabili di contenitori SQL Server, Spark e HDFS in esecuzione in Kubernetes. Questi componenti vengono eseguiti in modo affiancato per permettere la lettura, la scrittura e l'elaborazione di Big Data da Transact-SQL o Spark, in modo da combinare e analizzare facilmente i dati relazionali di alto valore con volumi elevati di Big Data.
Operazioni preliminari
- Vedere prima di tutto Introduzione ai cluster Big Data di SQL Server
- Per informazioni sulle nuove funzionalità della versione più recente, vedere le note sulla versione
- Per domande frequenti, vedere Domande frequenti sui cluster Big Data
Architettura dei cluster Big Data
Il diagramma seguente mostra i componenti di un cluster Big Data di SQL Server:

Controller
Il controller fornisce la gestione e la sicurezza per il cluster. Contiene il servizio di controllo, l'archivio di configurazione e altri servizi a livello di cluster, tra cui Kibana, Grafana ed ElasticSearch.
Pool di calcolo
Il pool di calcolo fornisce risorse di calcolo al cluster. Contiene nodi che eseguono SQL Server in pod Linux. I Pod nel pool di calcolo sono divisi in istanze di calcolo SQL per attività di elaborazione specifiche.
Pool di dati
Il pool di dati viene usato per la persistenza dei dati. Il pool di dati è costituito da uno o più pod che eseguono SQL Server in Linux. Viene usato per inserire dati da query SQL o processi Spark.
Pool di archiviazione
Il pool di archiviazione è formato da pod del pool di archiviazione costituiti da SQL Server in Linux, Spark, and HDFS. Tutti i nodi di archiviazione in un cluster Big Data di SQL Server sono membri di un cluster HDFS.
Suggerimento
Per informazioni dettagliate sull'architettura e sull'installazione dei cluster Big Data, vedere Workshop: Microsoft SQL Server Big Data Clusters Architecture (Architettura dei cluster Big Data di Microsoft SQL Server).
Pool di app
La distribuzione di applicazioni consente di distribuire applicazioni in un cluster Big Data di SQL Server fornendo interfacce per la creazione, la gestione e l'esecuzione di applicazioni.
Scenari e funzionalità
I cluster Big Data di SQL Server offrono la flessibilità necessaria per interagire con i Big Data. È possibile eseguire query su origini dati esterne, archiviare Big Data in HDFS gestito da SQL Server o eseguire query sui dati da più origini dati esterne tramite il cluster. È quindi possibile usare i dati per intelligenza artificiale, Machine Learning e altre attività di analisi.
Usare i cluster Big Data di SQL Server per:
- Distribuire cluster scalabili di contenitori SQL Server, Spark e HDFS in esecuzione in Kubernetes.
- Leggere, scrivere ed elaborare Big Data da Transact-SQL o Spark.
- Combinare e analizzare con facilità dati relazionali di alto valore con volumi elevati di Big Data.
- Eseguire query su origini dati esterne.
- Archiviare Big Data in HDFS gestito da SQL Server.
- Eseguire query sui dati da più origini dati esterne tramite il cluster.
- Usare i dati per intelligenza artificiale, Machine Learning e altre attività di analisi.
- Distribuire ed eseguire applicazioni in cluster Big Data.
- Virtualizzare i dati con PolyBase. Eseguire query sui dati da origini dati esterne SQL Server, Oracle, Teradata, MongoDB e ODBC generiche con tabelle esterne.
- Fornire disponibilità elevata per l'istanza master di SQL Server e tutti i database tramite una tecnologia basata su gruppi di disponibilità Always On.
Le sezioni seguenti forniscono altre informazioni su questi scenari.
Virtualizzazione dei dati
Sfruttando PolyBase, i cluster Big Data di SQL Server possono eseguire query su origini dati esterne senza dover spostare o copiare i dati. SQL Server 2019 (15.x) introduce nuovi connettori per le origini dati. Per altre informazioni, vedere Novità di PolyBase 2019.
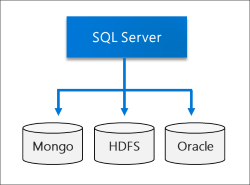
Data lake
Un cluster Big Data di SQL Server include un pool di archiviazione HDFS scalabile. Questo pool può essere usato per archiviare Big Data, potenzialmente inseriti da più origini esterne. Una volta archiviati i Big Data in HDFS nel cluster Big Data, è possibile analizzare ed eseguire query sui dati e combinarli con i dati relazionali.
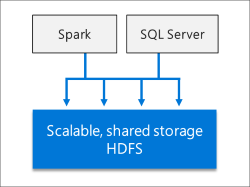
Intelligenza artificiale e Machine Learning integrati
I cluster Big Data di SQL Server permettono l'esecuzione di attività di intelligenza artificiale e Machine Learning sui dati archiviati in pool di archiviazione HDFS e sui pool di dati. È anche possibile usare Spark nonché strumenti di intelligenza artificiale predefiniti in SQL Server, tramite R, Python, Scala o Java.

Gestione e monitoraggio
La gestione e il monitoraggio vengono forniti tramite una combinazione di strumenti da riga di comando, API, portali e viste a gestione dinamica.
È possibile usare Azure Data Studio per eseguire un'ampia gamma di attività sul cluster Big Data:
- Frammenti predefiniti per attività di gestione comuni.
- Possibilità di esplorare HDFS, caricare file, visualizzare file in anteprima e creare directory.
- Possibilità di creare, aprire ed eseguire notebook compatibili con Jupyter.
- Procedura guidata di virtualizzazione dei dati per semplificare la creazione di origini dati esterne (funzionalità abilitata dall'estensione di virtualizzazione dei dati).
Concetti relativi a Kubernetes
Un cluster Big Data di SQL Server è un cluster di contenitori Linux orchestrati da Kubernetes.
Kubernetes è un agente di orchestrazione di contenitori open source, che può ridimensionare le distribuzioni di contenitori in base alle esigenze. La tabella seguente definisce alcuni importanti termini di Kubernetes:
| Termine | Descrizione |
|---|---|
| Cluster | Un cluster Kubernetes è un set di computer, noti come nodi. Un nodo controlla il cluster e viene designato come nodo master, mentre i nodi rimanenti sono nodi di lavoro. Il nodo master Kubernetes è responsabile della distribuzione del lavoro tra i nodi di lavoro e del monitoraggio dell'integrità del cluster. |
| Node | Un nodo esegue applicazioni in contenitori. Può essere un computer fisico o una macchina virtuale. Un cluster Kubernetes può contenere una combinazione di nodi computer fisico e macchina virtuale. |
| Pod | Un pod è l'unità di distribuzione atomica di Kubernetes. Un pod è un gruppo logico di uno o più contenitori, nonché delle risorse associate, necessari per eseguire un'applicazione. Ogni pod viene eseguito in un nodo e un nodo può eseguire uno o più pod. Il nodo master Kubernetes assegna automaticamente pod a nodi nel cluster. |
Nei cluster Big Data di SQL Server, Kubernetes è responsabile dello stato del cluster. Kubernetes crea e configura i nodi del cluster, assegna pod ai nodi ed esegue il monitoraggio dell'integrità del cluster.
Contenuto correlato
- Introduzione alla distribuzione dei cluster Big Data di SQL Server
- Ripristinare un database nell'istanza master di un cluster Big Data di SQL Server
- Inviare processi Spark in cluster Big Data di SQL Server in Azure Data Studio
- Workshop sull'architettura dei cluster Big Data
- Big Data Clusters in a Nutshell