Distribuire il nodo NameNode di HDFS e i servizi Spark condivisi in una configurazione a disponibilità elevata
Si applica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
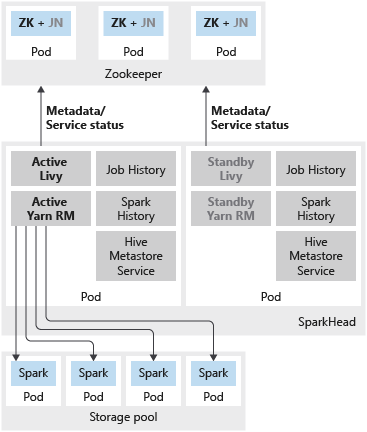
Oltre a distribuire l'istanza master di SQL Server in una configurazione a disponibilità elevata tramite gruppi di disponibilità, è possibile distribuire altri servizi cruciali nel cluster Big Data per garantire un livello di affidabilità maggiore. È possibile configurare HDFS name node e i servizi Spark condivisi raggruppati in sparkhead con una replica aggiuntiva. In questo caso, viene distribuito anche Zookeeper dal cluster Big Data al server come coordinatore del cluster e archivio di metadati per i servizi seguenti:
- Nodo NameNode di HDFS
- Livy e Yarn Resource Manager.
La cronologia di Spark, la cronologia dei processi e il servizio metadati Hive sono servizi senza stato. Zookeeper non è necessario per garantire l'integrità del servizio per questi componenti.
La distribuzione di più repliche per questi servizi restituisce livelli migliori di scalabilità, affidabilità e bilanciamento del carico dei carichi di lavoro tra le repliche disponibili.
Nota
I servizi seguenti vengono distribuiti come contenitori nel pod sparkhead:
- Livy
- Yarn Resource Manager
- Cronologia di Spark
- Storico processi
- Servizio metadati Hive
La figura seguente mostra una distribuzione a disponibilità elevata di Spark in un cluster Big Data di SQL Server:
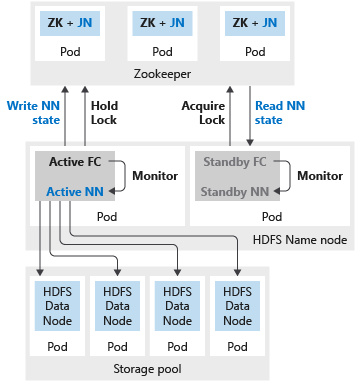
La figura seguente mostra una distribuzione a disponibilità elevata di HDFS in un cluster Big Data di SQL Server:
Distribuzione
Se il nodo NameNode o SparkHead è configurato con due repliche, è necessario configurare anche la risorsa Zookeeper con tre repliche. In una configurazione a disponibilità elevata per il nodo NameNode di HDFS due pod ospitano due repliche. I pod sono nmnode-0 e nmnode-1. Questa configurazione è attiva-passiva. È attivo un solo nodo per volta. L'altro è in standby e diventa attivo solo come conseguenza di un evento di failover.
Per iniziare a personalizzare la distribuzione del cluster Big Data, è possibile usare il profilo di configurazione predefinito aks-dev-test-ha o kubeadm-prod. Questi profili includono le impostazioni necessarie per le risorse per cui è possibile configurare la disponibilità elevata aggiuntiva. Ad esempio, di seguito è riportata una sezione del file di configurazione bdc.json pertinente per la distribuzione delle risorse condivise del nodo NameNode di HDFS, di Zookeeper e di Spark (sparkhead) con disponibilità elevata.
{
...
"nmnode-0": {
"spec": {
"replicas": 2
}
},
"sparkhead": {
"spec": {
"replicas": 2
}
},
"zookeeper": {
"spec": {
"replicas": 3
}
},
...
}
Come procedura consigliata, in una distribuzione di produzione è necessario impostare anche la replica del blocco HDFS su 3. Questa impostazione è già specificata nei profili aks-dev-test-ha e kubeadm-prod. Vedere la sezione seguente del file di configurazione bdc.json:
{
...
"hdfs": {
"resources": [
"nmnode-0",
"zookeeper",
"storage-0",
"sparkhead"
],
"settings": {
"hdfs-site.dfs.replication": "3"
}
},
...
}
Limitazioni note
Le limitazioni e i problemi noti relativi alla configurazione della disponibilità elevata per i servizi Hadoop nei cluster Big Data di SQL Server includono i seguenti:
- Tutte le configurazioni devono essere specificate al momento della distribuzione del cluster Big Data. Con la versione SQL Server 2019 CU1 non è possibile abilitare la configurazione a disponibilità elevata dopo la distribuzione.
Passaggi successivi
- Per altre informazioni sull'uso di file di configurazione in distribuzioni di cluster Big Data, vedere Come distribuire cluster Big Data di SQL Server in Kubernetes.
- Per altre informazioni sulle opzioni di disponibilità elevata per l'istanza master di SQL Server nei cluster Big Data, vedere Distribuire l'istanza master di SQL Server con disponibilità elevata.