Usare il seeding automatico per inizializzare una replica secondaria per un gruppo di disponibilità Always On
Si applica a: ![]() SQL Server
SQL Server
In SQL Server 2012 e 2014, l'unico modo per inizializzare una replica secondaria in un gruppo di disponibilità AlwaysOn di SQL Server consiste nell'usare le operazioni di backup, copia e ripristino. SQL Server 2016 introduce una nuova funzionalità per l'inizializzazione di una replica secondaria: il seeding automatico. Il seeding automatico usa il trasporto del flusso di log per trasmettere il backup mediante un'infrastruttura VDI nella replica secondaria per ogni database del gruppo di disponibilità tramite endpoint configurati. Questa nuova funzionalità può essere usata durante la creazione iniziale di un gruppo di disponibilità o quando viene aggiunto un database a un gruppo di disponibilità. Il seeding automatico si trova in tutte le edizioni di SQL Server che supportano i gruppi di disponibilità Always On e può essere usato sia con i gruppi di disponibilità tradizionali che con i gruppi di disponibilità distribuiti.
Sicurezza
Le autorizzazioni di sicurezza variano a seconda del tipo di replica da inizializzare:
- Per un gruppo di disponibilità tradizionale, le autorizzazioni devono essere concesse al gruppo di disponibilità nella replica secondaria quando viene aggiunta al gruppo di disponibilità. In Transact-SQL, usare i comando
ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE. - Per un gruppo di disponibilità distribuito in cui i database della replica che verranno creati si trovano nella replica primaria del secondo gruppo di disponibilità non sono necessarie autorizzazioni aggiuntive perché è già un gruppo di disponibilità primario. Tuttavia, se è presente una sola replica nel secondo gruppo di disponibilità, concedere l'autorizzazione
CREATE ANY DATABASEal nome del gruppo di disponibilità secondario o il seeding automatico potrebbe non riuscire. - Per una replica secondaria nel secondo gruppo di disponibilità di un gruppo di disponibilità distribuito, è necessario usare il comando
ALTER AVAILABILITY GROUP [<2ndAGName>] GRANT CREATE ANY DATABASE. Viene eseguito il seeding di questa replica secondaria dal gruppo di disponibilità primario del secondo gruppo di disponibilità.
Impatto del log delle prestazioni e delle transazioni sulla replica primaria
Il seeding automatico potrebbe essere pratico o meno per inizializzare una replica secondaria, a seconda delle dimensioni del database, della velocità della rete e della distanza tra le repliche primaria e secondaria. Si consideri ad esempio di avere una situazione simile alla seguente:
- Dimensioni del database di 5 TB
- Velocità della rete di 1 GB/sec
- Distanza tra i due siti di 1.000 miglia
Se è disponibile la larghezza di banda completa, una rete con 1GB/sec può fornire velocità effettiva prolungata pari a 125 MB/sec. In questo esempio, il seeding automatico richiederebbe poco più di 11 ore. In pratica, il processo di seeding automatico è più lento, perché i segnali della rete peggiorano per le distanze più lunghe e il collegamento viene condiviso con altre risorse nella rete. Durante il seeding, il log delle transazioni per il database nella replica primaria continua ad aumentare e non può essere troncato finché il seeding automatico di tale database non viene completato. È quindi possibile troncare il log delle transazioni con un backup del log delle transazioni.
Il seeding automatico è un processo a thread singolo in grado di gestire fino a cinque database. L'uso di un processo a thread singolo influisce sulle prestazioni, soprattutto se il gruppo di disponibilità ha più di un database.
Per il seeding automatico è possibile usare la compressione, ma è disabilitata per impostazione predefinita. Attivando la compressione si riduce la larghezza di banda di rete e si accelera possibilmente il processo, ma si ottiene in cambio un sovraccarico aggiuntivo del processore. Per usare la compressione durante il seeding automatico, abilitare il flag di traccia 9567. Vedere Ottimizzare la compressione per un gruppo di disponibilità.
Layout dei dischi
In SQL Server 2016 e versioni precedenti la cartella in cui viene creato il database per il seeding automatico deve già esistere e deve essere uguale a quella del percorso per la replica primaria.
In SQL Server 2017 Microsoft consiglia di usare lo stesso percorso per i dati e per il file di log in tutte le repliche che partecipano a un gruppo di disponibilità, ma è possibile usare percorsi diversi se necessario. Ad esempio, in un gruppo di disponibilità multipiattaforma un'istanza di SQL Server si trova su Windows e un'altra istanza di SQL Server si trova su Linux. Le diverse piattaforme hanno percorsi predefiniti diversi. SQL Server 2017 supporta repliche dei gruppi di disponibilità su istanze di SQL Server con percorsi predefiniti diversi.
La tabella seguente presenta esempi di layout dei dischi di dati supportati che possono supportare il seeding automatico:
| Percorso dati predefinito dell'istanza primaria |
Percorso dati predefinito dell'istanza secondaria |
Percorso del file di origine dell'istanza primaria |
Percorso del file di destinazione dell'istanza secondaria |
|---|---|---|---|
| c:\data\ | /var/opt/mssql/data/ | c:\data\ | /var/opt/mssql/data/ |
| c:\data\ | /var/opt/mssql/data/ | c:\data\group1\ | /var/opt/mssql/data/group1/ |
| c:\data\ | d:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | d:\data\group1\ |
Gli scenari in cui i percorsi dei database di replica primari e secondari non corrispondono ai percorsi predefiniti dell'istanza non sono interessati da questa modifica. I requisiti relativi alla corrispondenza dei percorsi file di replica secondaria e dei percorsi file di replica primaria rimangono invariati.
| Percorso dati predefinito dell'istanza primaria |
Percorso dati predefinito dell'istanza secondaria |
Percorso file dell'istanza primaria |
Percorso file dell'istanza secondaria |
|---|---|---|---|
| c:\data\ | c:\data\ | d:\group1\ | d:\group1\ |
| c:\data\ | c:\data\ | d:\data\ | d:\data\ |
| c:\data\ | c:\data\ | d:\data\group1\ | d:\data\group1\ |
Se si combinano percorsi predefiniti e non predefiniti nelle repliche primarie e secondarie, SQL Server 2017 si comporta in modo diverso rispetto alle versioni precedenti. La tabella seguente illustra questo comportamento di SQL Server 2017.
| Percorso dati predefinito dell'istanza primaria |
Percorso dati predefinito dell'istanza secondaria |
Percorso file dell'istanza primaria |
SQL Server 2016 Percorso file dell'istanza secondaria |
SQL Server 2017 Percorso file dell'istanza secondaria |
|---|---|---|---|---|
| c:\data\ | d:\data\ | c:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | c:\data\group1\ | d:\data\group1\ |
Per ripristinare il comportamento di SQL Server 2016 e versioni precedenti, abilitare il flag di traccia 9571. Per informazioni su come abilitare i flag di traccia, vedere DBCC TRACEON (Transact-SQL).
Creare un gruppo di disponibilità con seeding automatico
È possibile creare un gruppo di disponibilità con il seeding automatico con Transact-SQL o SQL Server Management Studio (SSMS versione 17 o successiva). Per usare la creazione guidata Gruppo di disponibilità in SSMS, attenersi a queste istruzioni. Quando si arriva al passaggio 9, come prima opzione predefinita viene visualizzato il seeding automatico.
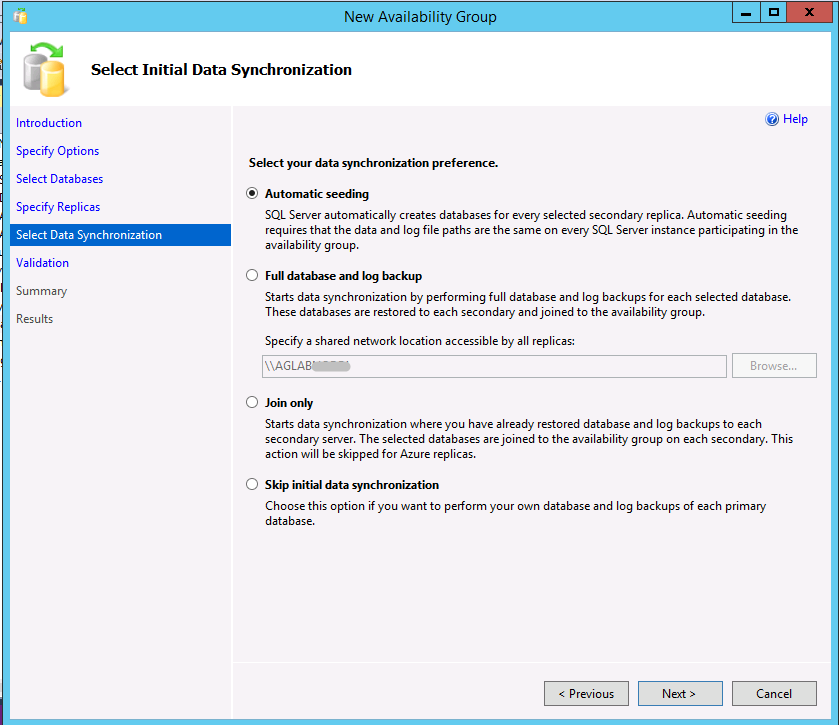
L'esempio seguente crea un gruppo di disponibilità con seeding automatico mediante Transact-SQL. Vedere anche l'argomento Creare un gruppo di disponibilità (Transact-SQL). Il seeding viene abilitato in una replica secondaria impostando l'opzione SEEDING_MODE su AUTOMATIC. Il comportamento predefinito è MANUAL, che è il comportamento delle versioni precedenti a SQL Server 2016 che richiede il backup del database da eseguire nella replica primaria, la copia del file di backup nella replica secondaria e il ripristino del backup con l'opzione WITH NORECOVERY.
CREATE AVAILABILITY GROUP [<AGName>]
FOR DATABASE db1
REPLICA ON N'Primary_Replica'
WITH (
ENDPOINT_URL = N'TCP://Primary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT
),
N'Secondary_Replica' WITH (
ENDPOINT_URL = N'TCP://Secondary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
SEEDING_MODE = AUTOMATIC);
GO
L'impostazione di SEEDING_MODE in una replica primaria durante l'istruzione CREATE AVAILABILITY GROUP non ha alcun effetto perché la replica primaria contiene già la copia principale di lettura/scrittura del database. SEEDING_MODE verrà applicato solo quando un'altra replica diventa la replica primaria e viene aggiunto un database. La modalità di seeding può essere modificata successivamente. Vedere Modificare la modalità di seeding di una replica.
In un'istanza che diventa una replica secondaria, dopo l'aggiunta dell'istanza al log di SQL Server viene aggiunto il messaggio seguente:
Alla replica di disponibilità locale per il gruppo di disponibilità 'AGName' non è stata concessa l'autorizzazione per creare i database sebbene
SEEDING_MODEsia impostato suAUTOMATIC. UsareALTER AVAILABILITY GROUP ... GRANT CREATE ANY DATABASEper consentire la creazione di database di cui è stato effettuato il seeding dalla replica di disponibilità primaria.
Concedere le autorizzazioni di creazione di database sulla replica secondaria al gruppo di disponibilità
Dopo l'aggiunta, concedere al gruppo di disponibilità l'autorizzazione per la creazione di database nell'istanza di replica secondaria di SQL Server. Per consentire il funzionamento del seeding automatico, il gruppo di disponibilità necessita dell'autorizzazione per la creazione di un database.
Suggerimento
Quando il gruppo di disponibilità crea un database in una replica secondaria imposta "sa", più precisamente l'account con sid 0x01, come proprietario del database.
Per modificare il proprietario del database dopo la creazione automatica di un database da parte di una replica secondaria, usare ALTER AUTHORIZATION. Vedere ALTER AUTHORIZATION (Transact-SQL).
L'esempio seguente concede tale autorizzazione a un gruppo di disponibilità denominato AGName.
ALTER AVAILABILITY GROUP [<AGName>]
GRANT CREATE ANY DATABASE
GO
Se necessario, configurare il proprietario del database nella replica secondaria.
Verificare il seeding automatico
Se l'operazione ha esito positivo, i database vengono creati automaticamente nella replica secondaria con uno dei due stati seguenti:
- SYNCHRONIZED se la replica secondaria è configurata per essere sincrona e i dati vengono sincronizzati.
- SYNCHRONIZING se la replica secondaria è configurata con lo spostamento dei dati asincrono o quando è configurata con dati sincroni, ma non ancora sincronizzati con la replica primaria.
Oltre alle DMV (viste a gestione dinamica) descritte di seguito, l'inizio e il completamento del seeding automatico possono essere visualizzati nel log di SQL Server:

Combinare operazioni di backup e ripristino con il seeding automatico
Con il seeding automatico è possibile combinare le operazioni tradizionali di backup, copia e ripristino. In questo caso, ripristinare prima il database in una replica secondaria, inclusi tutti i log delle transazioni disponibili. Successivamente, abilitare il seeding automatico quando si crea il gruppo di disponibilità per "aggiornare" il database della replica secondaria, come se venisse ripristinato un backup della parte finale del log (vedere Backup della parte finale del log (SQL Server)).
Aggiungere un database a un gruppo di disponibilità con seeding automatico
È possibile aggiungere un database a un gruppo di disponibilità con il seeding automatico con Transact-SQL o SQL Server Management Studio (SSMS versione 17 o successiva).
Se per la replica secondaria è stato usato il seeding automatico quando è stata aggiunta al gruppo di disponibilità, non è necessario eseguire alcuna operazione. Se la replica secondaria ha eseguito le operazioni di backup, copia e ripristino, modificare prima di tutto la modalità di seeding (vedere la sezione successiva) e quindi durante l'aggiunta del database usare l'istruzione GRANT. Vedere Aggiungere un database a un gruppo di disponibilità.
Modificare la modalità di seeding di una replica
La modalità di seeding di una replica può essere modificata dopo la creazione del gruppo di disponibilità, pertanto il seeding automatico può essere abilitato o disabilitato. Abilitando il seeding automatico dopo la creazione consente a un database di essere aggiunto al gruppo di disponibilità con il seeding automatico, se è stato creato con le operazioni di backup, copia e ripristino. Ad esempio:
ALTER AVAILABILITY GROUP [AGName]
MODIFY REPLICA ON 'Replica_Name'
WITH (SEEDING_MODE = AUTOMATIC)
Per disabilitare il seeding automatico, usare il valore MANUAL.
Impedire il seeding automatico dopo la creazione di un gruppo di disponibilità
Se non si vuole disabilitare completamente il seeding automatico per una replica secondaria, ma si vuole impedire temporaneamente alla replica secondaria di creare automaticamente i database, è possibile negare l'autorizzazione CREATE al gruppo di disponibilità. Ciò avviene quando un nuovo database viene aggiunto al gruppo di disponibilità, ma il gruppo di disponibilità non deve poter creare il database in una replica secondaria.
ALTER AVAILABILITY GROUP [AGName]
DENY CREATE ANY DATABASE
GO
Monitorare il seeding automatico
Sono disponibili quattro modi per monitorare e risolvere i problemi del seeding automatico:
- Log di SQL Server come già descritto
- DMV
- Tabelle di cronologia di backup
- Eventi estesi
DMV
Sono disponibili due viste a gestione dinamica (DMV) per il monitoraggio del seeding: sys.dm_hadr_automatic_seeding e sys.dm_hadr_physical_seeding_stats.
sys.dm_hadr_automatic_seedingcontiene lo stato generale del seeding automatico e mantiene la cronologia di ogni esecuzione, indipendentemente dall'esito positivo o meno. La colonnacurrent_stateconterrà il valore COMPLETED o FAILED. Se il valore è FAILED, usare il valore infailure_state_descper la diagnosi del problema. Potrebbe essere necessario usare sia questo valore che quello riportato nel Log di SQL Server per stabilire la causa dell'errore. Questa DMV viene popolata nella replica primaria e in tutte le repliche secondarie.sys.dm_hadr_physical_seeding_statsmostra lo stato dell'operazione di seeding automatico quando è in esecuzione. Analogamente asys.dm_hadr_automatic_seeding, restituisce valori per le repliche primarie e secondarie, ma la cronologia non viene archiviata. I valori sono per solo l'esecuzione corrente e non vengono conservati. Le colonne interessate includonostart_time_utc,end_time_utc,estimate_time_complete_utc,total_disk_io_wait_time_ms,total_network_wait_time_ms, e failure_message, in caso di esito negativo dell'operazione di seeding.
Tabelle di cronologia di backup
Il seeding automatico inserisce inoltre le voci nelle tabelle msdb in cui viene archiviata la cronologia di backup e ripristini. Nella replica secondaria che riceve il seeding automatico, la colonna physical_device_name della tabella backupmediafamily contiene un GUID per il relativo valore e la voce corrispondente in backupset contiene il nome della replica primaria per server_name e machine_name.
Eventi estesi
Il seeding automatico aggiunge nuovi eventi estesi per tenere traccia delle modifiche allo stato, degli errori e delle statistiche sulle prestazioni durante l'inizializzazione. Ad esempio, lo script seguente crea una sessione di eventi estesi che acquisisce gli eventi correlati al seeding automatico.
CREATE EVENT SESSION [AlwaysOn_autoseed] ON SERVER
ADD EVENT sqlserver.hadr_automatic_seeding_state_transition,
ADD EVENT sqlserver.hadr_automatic_seeding_timeout,
ADD EVENT sqlserver.hadr_db_manager_seeding_request_msg,
ADD EVENT sqlserver.hadr_physical_seeding_backup_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_failure,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_target_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_progress,
ADD EVENT sqlserver.hadr_physical_seeding_restore_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_submit_callback
ADD TARGET package0.event_file(
SET filename=N'autoseed.xel',
max_file_size=(5),
max_rollover_files=(4)
)
WITH (
MAX_MEMORY=4096 KB,
EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY=30 SECONDS,
MAX_EVENT_SIZE=0 KB,
MEMORY_PARTITION_MODE=NONE,
TRACK_CAUSALITY=OFF,
STARTUP_STATE=ON
)
GO
ALTER EVENT SESSION AlwaysOn_autoseed ON SERVER STATE=START
GO
La tabella seguente elenca gli eventi estesi correlati al seeding automatico.
| Nome | Descrizione |
|---|---|
| hadr_db_manager_seeding_request_msg | Messaggio di richiesta di seeding. |
| hadr_physical_seeding_backup_state_change | Modifica dello stato lato backup del seed fisico. |
| hadr_physical_seeding_restore_state_change | Modifica dello stato lato ripristino del seed fisico. |
| hadr_physical_seeding_forwarder_state_change | Modifica dello stato lato server di inoltro del seed fisico. |
| hadr_physical_seeding_forwarder_target_state_change | Modifica dello stato lato destinazione del server di inoltro del seed fisico. |
| hadr_physical_seeding_submit_callback | Evento di callback invio del seed fisico. |
| hadr_physical_seeding_failure | Evento di errore del seed fisico. |
| hadr_physical_seeding_progress | Evento di stato del seed fisico. |
| hadr_physical_seeding_schedule_long_task_failure | Evento di errore per attività di lunga durata della pianificazione per il seed fisico. |
| hadr_automatic_seeding_start | Si verifica quando viene inviata un'operazione di seeding automatico. |
| hadr_automatic_seeding_state_transition | Si verifica quando cambia lo stato di un'operazione di seeding automatico. |
| hadr_automatic_seeding_success | Si verifica quando un'operazione di seeding automatico riesce. |
| hadr_automatic_seeding_failure | Si verifica quando un'operazione di seeding automatico non riesce. |
| hadr_automatic_seeding_timeout | Si verifica in caso di timeout di un'operazione di seeding automatico. |
Vedi anche
ALTER AVAILABILITY GROUP (Transact-SQL)
CREATE AVAILABILITY GROUP (Transact-SQL)
Guida alla risoluzione dei problemi e al monitoraggio dei gruppi di disponibilità Always On