Dati JSON in SQL Server
Si applica a: ![]() SQL Server 2016 (13.x) e versioni
SQL Server 2016 (13.x) e versioni![]() successive database SQL di Azure Istanza gestita di SQL di Azure
successive database SQL di Azure Istanza gestita di SQL di Azure![]()
![]() database SQL di Azure Synapse Analytics
database SQL di Azure Synapse Analytics ![]() in Microsoft Fabric
in Microsoft Fabric
JSON è un popolare formato di dati testuali usato per lo scambio di dati in applicazioni per dispositivi mobili e Web moderne. JSON viene usato anche per archiviare dati non strutturati nei file di log o nei database NoSQL come Microsoft Cosmos DB. Molti servizi Web REST restituiscono risultati formattati come testo JSON oppure accettano dati formattati come JSON. La maggior parte dei servizi di Azure, come Ricerca di Azure, Archiviazione di Azure e Azure Cosmos DB, include ad esempio endpoint REST che restituiscono o usano JSON. JSON è anche il formato principale per lo scambio di dati tra le pagine Web e i server Web tramite le chiamate AJAX.
Le funzioni JSON, introdotte inizialmente in SQL Server 2016 (13.x), consentono di combinare concetti NoSQL e concetti relazionali nello stesso database. È possibile combinare colonne relazionali classiche con colonne che contengono documenti formattati come testo JSON nella stessa tabella, analizzare e importare documenti JSON in strutture relazionali o formattare dati relazionali come testo JSON.
Nota
Il supporto JSON richiede il livello di compatibilità del database 130 o superiore.
Ecco un esempio di testo JSON:
[
{
"name": "John",
"skills": [ "SQL", "C#", "Azure" ]
},
{
"name": "Jane",
"surname": "Doe"
}
]
Usando le funzioni e gli operatori predefiniti di SQL Server, è possibile eseguire le operazioni seguenti con testo JSON:
- Analizzare il testo JSON e leggere o modificare i valori.
- Trasformare matrici di oggetti JSON in formato tabella.
- Eseguire qualsiasi query Transact-SQL sugli oggetti JSON convertiti.
- Formattare i risultati delle query Transact-SQL in formato JSON.
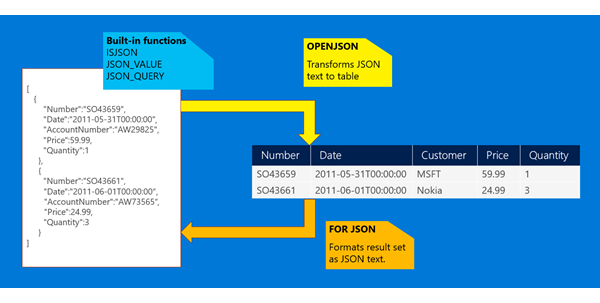
Principali funzionalità JSON di SQL Server e del database SQL
Le sezioni successive illustrano le principali funzionalità offerte da SQL Server tramite il supporto JSON predefinito.
Tipo di dati JSON
Nuovo tipo di dati json che archivia i documenti JSON in un formato binario nativo che offre i seguenti vantaggi rispetto all'archiviazione di dati JSON in varchar/nvarchar:
- Letture più efficienti, in quanto il documento è già analizzato
- Scritture più efficienti, in quanto la query può aggiornare singoli valori senza accedere all'intero documento
- Archiviazione più efficiente, ottimizzata per la compressione
- Nessuna modifica della compatibilità con il codice esistente
Nota
Il tipo di dati JSON è attualmente in anteprima per database SQL di Azure e Istanza gestita di SQL di Azure (configurato con i criteri di aggiornamento sempre aggiornati).
L'uso delle stesse funzioni JSON descritte in questo articolo rimane il modo più efficiente per eseguire query sul tipo di dati json. Per altre informazioni sul tipo di dati json nativo, si veda Tipo di dati JSON.
Estrarre valori dal testo JSON e usarli nelle query
Se un testo JSON viene archiviato in tabelle di database, è possibile leggere o modificare i valori nel testo JSON usando le funzioni predefinite seguenti:
- ISJSON (Transact-SQL) verifica se una stringa include contenuto JSON valido.
- JSON_VALUE (Transact-SQL) estrae un valore scalare da una stringa JSON.
- JSON_QUERY (Transact-SQL) estrae un oggetto o una matrice da una stringa JSON.
- JSON_MODIFY (Transact-SQL) modifica un valore in una stringa JSON.
Esempio
Nell'esempio seguente la query usa sia i dati relazionali sia i dati JSON (archiviati nella colonna ) di una tabella:
SELECT Name,
Surname,
JSON_VALUE(jsonCol, '$.info.address.PostCode') AS PostCode,
JSON_VALUE(jsonCol, '$.info.address."Address Line 1"')
+ ' ' + JSON_VALUE(jsonCol, '$.info.address."Address Line 2"') AS Address,
JSON_QUERY(jsonCol, '$.info.skills') AS Skills
FROM People
WHERE ISJSON(jsonCol) > 0
AND JSON_VALUE(jsonCol, '$.info.address.Town') = 'Belgrade'
AND STATUS = 'Active'
ORDER BY JSON_VALUE(jsonCol, '$.info.address.PostCode');
Strumenti e applicazioni non rilevano alcuna differenza tra i valori ricavati dalle colonne della tabella scalare e i valori ricavati dalla colonna JSON. È possibile usare i valori dal testo JSON in qualsiasi parte della query Transact-SQL (tra cui clausole WHERE, ORDER BY o GROUP BY, aggregazioni finestra e così via). Le funzioni JSON usano una sintassi di tipo JavaScript per fare riferimento ai valori all'interno del testo JSON.
Per altre informazioni, vedere Convalidare, eseguire query e modificare i dati JSON con funzioni predefinite (SQL Server), JSON_VALUE (Transact-SQL)e JSON_QUERY (Transact-SQL).
Modificare valori JSON
Se è necessario modificare parti di testo JSON, è possibile usare la funzione JSON_MODIFY (Transact-SQL) per aggiornare il valore di una proprietà in una stringa JSON e restituire la stringa JSON aggiornata. L'esempio seguente aggiorna il valore di una proprietà in una variabile che include contenuto JSON:
DECLARE @json NVARCHAR(MAX);
SET @json = '{"info": {"address": [{"town": "Belgrade"}, {"town": "Paris"}, {"town":"Madrid"}]}}';
SET @json = JSON_MODIFY(@json, '$.info.address[1].town', 'London');
SELECT modifiedJson = @json;
Il set di risultati è il seguente.
{"info":{"address":[{"town":"Belgrade"},{"town":"London"},{"town":"Madrid"}]}}
Convertire raccolte JSON in un set di righe
Non è necessario un linguaggio di query personalizzato per eseguire query JSON in SQL Server. Per eseguire query sui dati JSON, si può usare il linguaggio T-SQL standard. Se è necessario creare una query o un report sui dati JSON, è possibile convertire facilmente i dati JSON in righe e colonne chiamando la funzione OPENJSON per i set di righe. Per altre informazioni, vedere Analizzare e trasformare dati JSON con OPENJSON.
Nell'esempio seguente viene chiamato OPENJSONche trasforma una matrice di oggetti archiviati nella variabile @json in un set di righe su cui è possibile eseguire una query usando l'istruzione SELECT Transact-SQL standard:
DECLARE @json NVARCHAR(MAX);
SET @json = N'[
{"id": 2, "info": {"name": "John", "surname": "Smith"}, "age": 25},
{"id": 5, "info": {"name": "Jane", "surname": "Smith"}, "dob": "2005-11-04T12:00:00"}
]';
SELECT *
FROM OPENJSON(@json) WITH (
id INT 'strict $.id',
firstName NVARCHAR(50) '$.info.name',
lastName NVARCHAR(50) '$.info.surname',
age INT,
dateOfBirth DATETIME2 '$.dob'
);
Il set di risultati è il seguente.
| ID | firstName | lastName | età | dateOfBirth |
|---|---|---|---|---|
| 2 | John | Smith | 25 | |
| 5 | Jane | Smith | 2005-11-04T12:00:00 |
OPENJSON trasforma la matrice di oggetti JSON in una tabella in cui ogni oggetto è rappresentato come una riga e le coppie chiave-valore vengono restituite come celle. L'output osserva le regole seguenti:
OPENJSONconverte i valori JSON nei tipi specificati nella clausolaWITH.OPENJSONpuò gestire sia coppie chiave-valore flat che gli oggetti annidati organizzati gerarchicamente.- Non è necessario restituire tutti i campi contenuti nel testo JSON.
- Se non esistono valori JSON,
OPENJSONrestituisce valoriNULL. - È possibile specificare un percorso dopo la definizione del tipo per fare riferimento a una proprietà annidata o a una proprietà con un nome diverso.
- Il prefisso
strictfacoltativo nel percorso specifica che i valori per le proprietà specificate devono esistere nel testo JSON.
Per altre informazioni, vedere Analizzare e trasformare i dati con OPENJSON e OPENJSON (Transact-SQL).
È possibile che i documenti JSON abbiano sottoelementi e dati gerarchici che non possano essere mappati direttamente nelle colonne relazionali standard. In questo caso, è possibile rendere flat la gerarchia JSON unendo l'entità padre alle sottomatrici.
Nell'esempio seguente il secondo oggetto della matrice include una sottomatrice in cui sono rappresentate le competenze delle persone. Ogni oggetto secondario può essere analizzato tramite una chiamata di funzione OPENJSON aggiuntiva:
DECLARE @json NVARCHAR(MAX);
SET @json = N'[
{"id": 2, "info": {"name": "John", "surname": "Smith"}, "age": 25},
{"id": 5, "info": {"name": "Jane", "surname": "Smith", "skills": ["SQL", "C#", "Azure"]}, "dob": "2005-11-04T12:00:00"}
]';
SELECT id,
firstName,
lastName,
age,
dateOfBirth,
skill
FROM OPENJSON(@json) WITH (
id INT 'strict $.id',
firstName NVARCHAR(50) '$.info.name',
lastName NVARCHAR(50) '$.info.surname',
age INT,
dateOfBirth DATETIME2 '$.dob',
skills NVARCHAR(MAX) '$.info.skills' AS JSON
)
OUTER APPLY OPENJSON(skills) WITH (skill NVARCHAR(8) '$');
La matrice skills viene restituita nella prima funzione OPENJSON come frammento di testo JSON originale e passata a un'altra funzione OPENJSON tramite l'operatore APPLY. La seconda funzione OPENJSON analizza la matrice JSON e restituisce i valori stringa come singolo set di righe di colonna che viene poi unito al risultato della prima funzione OPENJSON.
Il set di risultati è il seguente.
| ID | firstName | lastName | età | dateOfBirth | skill |
|---|---|---|---|---|---|
| 2 | John | Smith | 25 | ||
| 5 | Jane | Smith | 2005-11-04T12:00:00 | SQL | |
| 5 | Jane | Smith | 2005-11-04T12:00:00 | C# | |
| 5 | Jane | Smith | 2005-11-04T12:00:00 | Azure |
OUTER APPLY OPENJSON unisce l'entità di primo livello alla sottomatrice e restituisce un set di risultati flat. Dato il JOIN, la seconda riga sarà ripetuta per ogni competenza.
Convertire dati di SQL Server in formato JSON o esportare JSON
Nota
La conversione dei dati di Azure Synapse Analytics nel formato JSON o l'esportazione del formato JSON non è supportata.
Formattare i dati SQL Server o i risultati delle query JSON in formato JSON aggiungendo la clausola FOR JSON a un'istruzione SELECT. Usare la clausola FOR JSON per delegare la formattazione dell'output JSON dalle applicazioni client a SQL Server. Per altre informazioni, vedere Formattare i risultati delle query in formato JSON con FOR JSON.
L'esempio seguente usa la modalità PATH con la clausola FOR JSON:
SELECT id,
firstName AS "info.name",
lastName AS "info.surname",
age,
dateOfBirth AS dob
FROM People
FOR JSON PATH;
Ogni clausola FOR JSON formatta i risultati SQL come testo JSON che può essere fornito a qualsiasi app che riconosce JSON. L'opzione PATH usa alias separati da punti nella clausola SELECT per annidare oggetti nei risultati della query.
Il set di risultati è il seguente.
[
{
"id": 2,
"info": {
"name": "John",
"surname": "Smith"
},
"age": 25
},
{
"id": 5,
"info": {
"name": "Jane",
"surname": "Smith"
},
"dob": "2005-11-04T12:00:00"
}
]
Per altre informazioni, vedere Formattare i risultati delle query in formato JSON con FOR JSON e Clausola FOR (Transact-SQL).
Dati JSON da aggregazioni
Nuove funzioni di aggregazione JSON consentono la costruzione di oggetti o matrici JSON in base a un'aggregazione di dati SQL.
- JSON_OBJECTAGG costruisce un oggetto JSON da un'aggregazione di dati o colonne SQL.
- JSON_ARRAYAGG costruisce una matrice JSON da un'aggregazione di dati o colonne SQL.
Nota
Entrambe le funzioni JSON_OBJECTAGG di aggregazione JSON e JSON_ARRAYAGG sono attualmente in anteprima per database SQL di Azure e Istanza gestita di SQL di Azure (configurate con i criteri di aggiornamento sempre aggiornati).
Casi d'uso per dati JSON in SQL Server
Il supporto di JSON in SQL Server e nel database SQL di Azure consente di combinare concetti relazionali e NoSQL. È possibile trasformare facilmente dati relazionali in dati semistrutturati e viceversa. JSON non è tuttavia una sostituzione per i modelli relazionali esistenti. Ecco alcuni casi d'uso specifici che traggono vantaggio dal supporto JSON in SQL Server e nel database SQL.
Semplificare modelli di dati complessi
Valutare la possibilità di denormalizzare il modello di dati con campi JSON al posto di più tabelle figlio.
Archiviare dati di vendita al dettaglio e di e-commerce
Archiviare informazioni sui prodotti con un'ampia gamma di attributi variabili in un modello denormalizzato per una maggiore flessibilità.
Elaborare i dati di log e di telemetria
Caricare, eseguire query e analizzare i dati di log archiviati come file JSON con tutte le potenzialità del linguaggio Transact-SQL.
Archiviare dati IoT semistrutturati
Quando è necessario analizzare dati IoT in tempo reale, caricare i dati in ingresso direttamente nel database anziché in una posizione di archiviazione temporanea.
Semplificare lo sviluppo delle API REST
Trasformare facilmente i dati relazionali dal database nel formato JSON usato dalle API REST che supportano il sito Web.
Combinare dati relazionali e dati JSON
SQL Server fornisce un modello ibrido per l'archiviazione e l'elaborazione dei dati relazionali e JSON usando il linguaggio Transact-SQL standard. È possibile organizzare le raccolte di documenti JSON in tabelle, stabilire relazioni tra di esse, combinare colonne scalari fortemente tipizzate archiviate in tabelle con coppie chiave-valore flessibili archiviate nelle colonne JSON ed eseguire query su valori scalari e JSON in una o più tabelle usando il linguaggio Transact-SQL completo.
Il testo JSON è archiviato in colonne VARCHAR o NVARCHAR e viene indicizzato come testo normale. Qualsiasi funzionalità o componente di SQL Server che supporta testo supporta anche JSON, quindi non esiste quasi nessun vincolo nell'interazione tra JSON e altre funzionalità di SQL Server. È possibile archiviare i dati JSON in tabelle in memoria o temporali, applicare i predicati della sicurezza a livello di riga al testo JSON e così via.
Ecco alcuni casi d'uso che mostrano come usare il supporto JSON integrato in SQL Server.
Archiviare e indicizzare dati JSON in SQL Server
Essendo JSON un formato testuale, i documenti JSON possono essere archiviati in colonne NVARCHAR in un database SQL. Poiché il tipo NVARCHAR è supportato in tutti i sottosistemi di SQL Server, è possibile inserire i documenti JSON in tabelle con indici CLUSTERED COLUMNSTORE, tabelle ottimizzate per la memoria o file esterni che possono essere letti tramite OPENROWSET o PolyBase.
Per altre informazioni sulle opzioni per l'archiviazione, l'indicizzazione e l'ottimizzazione dei dati JSON in SQL Server, vedere gli articoli seguenti:
- Archiviare documenti JSON in SQL Server o nel database SQL
- Indicizzazione dei dati JSON
- Ottimizzare l'elaborazione JSON con OLTP in memoria
Caricare file JSON in SQL Server
È possibile formattare le informazioni archiviate nei file come JSON standard o JSON delimitato da righe. SQL Server può importare il contenuto di file JSON, analizzarlo usando le funzioni OPENJSON e JSON_VALUE e caricarlo nelle tabelle.
Se i documenti JSON vengono archiviati in file locali, unità di rete condivise o posizioni di File di Azure accessibili da SQL Server, è possibile usare l'importazione in blocco per caricare i dati JSON in SQL Server.
Se i file JSON delimitati da righe vengono archiviati nell'archivio BLOB di Azure o nel file system di Hadoop, è possibile usare PolyBase per caricare il testo JSON, analizzarlo nel codice Transact-SQL e caricarlo nelle tabelle.
Importare i dati JSON in tabelle di SQL Server
Se è necessario caricare dati JSON da un servizio esterno in SQL Server, è possibile usare OPENJSON per importare i dati in SQL Server, invece di analizzare i dati nel livello applicativo.
Nelle piattaforme supportate, usare il tipo di dati json nativo anziché nvarchar(max) per migliorare le prestazioni e ottenere un'archiviazione più efficiente.
DECLARE @jsonVariable NVARCHAR(MAX);
SET @jsonVariable = N'[
{
"Order": {
"Number":"SO43659",
"Date":"2011-05-31T00:00:00"
},
"AccountNumber":"AW29825",
"Item": {
"Price":2024.9940,
"Quantity":1
}
},
{
"Order": {
"Number":"SO43661",
"Date":"2011-06-01T00:00:00"
},
"AccountNumber":"AW73565",
"Item": {
"Price":2024.9940,
"Quantity":3
}
}
]';
-- INSERT INTO <sampleTable>
SELECT SalesOrderJsonData.*
FROM OPENJSON(@jsonVariable, N'$') WITH (
Number VARCHAR(200) N'$.Order.Number',
Date DATETIME N'$.Order.Date',
Customer VARCHAR(200) N'$.AccountNumber',
Quantity INT N'$.Item.Quantity'
) AS SalesOrderJsonData;
È possibile fornire il contenuto della variabile JSON tramite un servizio REST esterno, inviarlo come parametro da un framework JavaScript sul lato client o caricarlo da file esterni. È possibile inserire, aggiornare o unire facilmente i risultati dal testo JSON in una tabella di SQL Server.
Analizzare i dati JSON con query SQL
Se è necessario filtrare o aggregare dati JSON per la creazione di report, è possibile usare OPENJSON per trasformare i dati JSON in formato relazionale. È quindi possibile usare le funzioni predefinite e Transact-SQL standard per preparare i report.
SELECT Tab.Id,
SalesOrderJsonData.Customer,
SalesOrderJsonData.Date
FROM SalesOrderRecord AS Tab
CROSS APPLY OPENJSON(Tab.json, N'$.Orders.OrdersArray') WITH (
Number VARCHAR(200) N'$.Order.Number',
Date DATETIME N'$.Order.Date',
Customer VARCHAR(200) N'$.AccountNumber',
Quantity INT N'$.Item.Quantity'
) AS SalesOrderJsonData
WHERE JSON_VALUE(Tab.json, '$.Status') = N'Closed'
ORDER BY JSON_VALUE(Tab.json, '$.Group'),
Tab.DateModified;
È possibile usare sia le colonne sia i valori della tabella standard dal testo JSON nella stessa query. È possibile aggiungere indici nell'espressione JSON_VALUE(Tab.json, '$.Status') per migliorare le prestazioni della query. Per altre informazioni, vedere Indicizzazione dei dati JSON.
Restituire dati da una tabella di SQL Server formattata come JSON
Se si ha un servizio Web che preleva i dati dal livello di database e li restituisce in formato JSON oppure se si hanno framework o librerie JavaScript che accettano dati formattati come JSON, è possibile formattare l'output JSON direttamente in una query SQL. Invece di scrivere codice o includere una libreria per convertire i risultati di una query tabulare e quindi serializzare gli oggetti in formato JSON, è possibile usare FOR JSON per delegare la formattazione JSON a SQL Server.
Ad esempio, può essere necessario generare output JSON che sia conforme alla specifica OData. Il servizio Web prevede una richiesta e una risposta nel formato seguente:
Richiesta:
/Northwind/Northwind.svc/Products(1)?$select=ProductID,ProductNameRisposta:
{"@odata.context": "https://services.odata.org/V4/Northwind/Northwind.svc/$metadata#Products(ProductID,ProductName)/$entity", "ProductID": 1, "ProductName": "Chai"}
Questo URL OData rappresenta una richiesta per le colonne ProductID e ProductName per il prodotto con ID 1. È possibile usare FOR JSON per formattare l'output come previsto in SQL Server.
SELECT 'https://services.odata.org/V4/Northwind/Northwind.svc/$metadata#Products(ProductID,ProductName)/$entity' AS '@odata.context',
ProductID,
Name as ProductName
FROM Production.Product
WHERE ProductID = 1
FOR JSON AUTO;
L'output di questa query è testo JSON completamente conforme alla specifica OData. La formattazione e l'escape vengono gestite da SQL Server. SQL Server può anche formattare i risultati delle query in qualsiasi formato, ad esempio OData JSON o GeoJSON.
Test drive del supporto JSON integrato con il database di esempio AdventureWorks
Per ottenere il database di esempio AdventureWorks è necessario scaricare almeno il file di database e il file di script ed esempi da GitHub.
Dopo aver ripristinato il database di esempio in un'istanza di SQL Server, estrarre il file degli esempi e quindi aprire il file JSON Sample Queries procedures views and indexes.sql dalla cartella JSON. Eseguire gli script in questo file per riformattare alcuni dati esistenti come dati JSON, eseguire test di report e query di esempio sui dati JSON, indicizzare i dati JSON e importare ed esportare JSON.
Di seguito sono elencate le operazioni possibili con gli script inclusi nel file:
Denormalizzare lo schema esistente per creare colonne di dati JSON.
Archiviare informazioni dalle tabelle
SalesReasons,SalesOrderDetails,SalesPerson,Customere da altre tabelle che contengono informazioni relative all'ordine di vendita nelle colonne JSON della tabella.Archiviare informazioni dalle tabelle
EmailAddressesePersonPhonenella tabellaPerson_jsoncome matrici di oggetti JSON.
Creare procedure e viste che eseguono query sui dati JSON.
Indicizzare i dati JSON. Creare indici sulle proprietà JSON e indici full-text.
Importare ed esportare JSON. Creare ed eseguire procedure per esportare il contenuto delle tabelle
PersoneSalesOrdercome risultati JSON, quindi importare e aggiornare le tabellePersoneSalesOrderusando l'input JSON.Eseguire esempi di query. Eseguire alcune query che chiamano le stored procedure e le viste create nei passaggi 2 e 4.
Pulire gli script. Non eseguire questa parte se si vogliono conservare le stored procedure e le viste create nei passaggi 2 e 4.