Guida all'architettura e gestione del log delle transazioni di SQL Server
Si applica a: ![]() SQL Server
SQL Server ![]() Database SQL di Azure
Database SQL di Azure ![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure ![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Piattaforma di strumenti analitici (PDW)
Piattaforma di strumenti analitici (PDW)
Ogni database SQL Server include un log delle transazioni in cui vengono archiviate tutte le transazioni e le modifiche apportate dalle transazioni stesse al database. Il log delle transazioni è un componente fondamentale del database e, in caso di errore di sistema, può essere necessario per ripristinare la coerenza del database. In questa guida vengono fornite informazioni sull'architettura fisica e logica del log delle transazioni. Le informazioni sull'architettura consentono di gestire più efficacemente i log delle transazioni.
Architettura logica del log delle transazioni
Il log delle transazioni di SQL Server funziona in modo logico come se il log delle transazione sia una stringa di record di log. Ogni record di log è identificato da un numero di sequenza del file di log (LSN). Ogni nuovo record di log viene scritto nell'estremità finale logica del log con un LSN maggiore di quello del record precedente. I record di log vengono archiviati in una sequenza seriale quando vengono creati, in modo tale che se LSN2 è maggiore di LSN1, la modifica descritta dal record di log cui fa riferimento LSN2 si verifica dopo la modifica descritta dal record di log cui fa riferimento LSN1. Ogni record di log contiene l'ID della transazione a cui appartiene. Tutti i record di log associati a ogni transazione sono collegati singolarmente in una catena tramite puntatori ai record precedenti che consentono di eseguire più rapidamente il rollback della transazione.
La struttura di base di un LSN è [VLF ID:Log Block ID:Log Record ID]. Per altre informazioni, vedere le sezioni relative a VLF e al blocco dei log.
Di seguito è riportato un esempio di LSN: 00000031:00000da0:0001, dove 0x31 è l'ID del file VLF, 0xda0 è l'ID del blocco dei log e 0x1 è il primo record di log in tale blocco di log. Per esempi di LSN, tenere conto dell'output di DMV sys.dm_db_log_info ed esaminare la colonna vlf_create_lsn.
Nei record di log relativi alle modifiche dei dati vengono registrate le operazioni logiche eseguite oppure immagini dei dati precedenti e successive alla modifica. Un'immagine precedente la modifica è una copia dei dati eseguita prima dell'operazione, mentre un'immagine successiva alla modifica è una copia dei dati eseguita dopo l'operazione.
La procedura necessaria per recuperare un'operazione varia a seconda del tipo di record di log:
Operazione logica registrata
- Per eseguire il roll forward dell'operazione logica, questa viene eseguita nuovamente.
- Per eseguire il rollback dell'operazione logica, questa viene eseguita al contrario.
Immagine precedente e successiva (alla modifica dei dati) registrata
- Per eseguire il roll forward dell'operazione, viene applicata l'immagine successiva.
- Per eseguire il rollback dell'operazione, viene applicata l'immagine precedente.
Nel log delle transazioni vengono registrati molti tipi di operazioni, tra cui:
L'inizio e la fine di ogni transazione.
Tutte le modifiche apportate ai dati, ovvero inserimento, aggiornamento o eliminazione, comprese le modifiche apportate da stored procedure di sistema o istruzioni DDL (Data Definition Language) a qualsiasi tabella, incluse le tabelle di sistema.
Tutte le allocazioni o deallocazioni di pagina e di extent.
Operazioni di creazione o eliminazione di una tabella o di un indice.
Nel log vengono registrate anche le operazioni di rollback. Ogni transazione riserva una determinata quantità di spazio nel log delle transazioni per garantire che nel log sia disponibile spazio sufficiente per supportare un rollback generato da un'istruzione di rollback esplicita o dal verificarsi di un errore. La quantità di spazio riservata varia in base alle operazioni eseguite nella transazione, ma in genere equivale alla quantità di spazio utilizzata per registrare nel log ogni operazione. Lo spazio riservato viene liberato al completamento della transazione.
La sezione del file di log dal primo record di log che deve essere presente per la corretta esecuzione del rollback a livello di database all'ultimo record di log scritto è definita parte attiva del log, log attivo o parte finale del log. Questa sezione del log è necessaria per il recupero completo del database. Non è possibile troncare nessuna parte del log attivo. Il numero di sequenza del file di log (LSN) di questo primo record di log è noto come LSN minimo del recupero (MinLSN). Per altre informazioni sulle operazioni supportate dal log delle transazioni, vedere Log delle transazioni.
Backup dei log e differenziali spostano il database ripristinato a un momento successivo, corrispondente a un LSN maggiore.
Architettura fisica del log delle transazioni
Del log delle transazioni di un database viene eseguito il mapping su uno o più file fisici. Concettualmente, il file di log è una stringa di record di log. Fisicamente, la sequenza di record di log viene archiviata in modo efficiente nel set di file fisici che implementano il log delle transazioni. È necessario che sia disponibile almeno un file di log per ogni database.
File di log virtuali (VLFs)
Nel motore di database di SQL Server ogni file di log fisico viene diviso internamente in diversi file di log virtuali. I file di log virtuali non hanno dimensioni fisse e non è previsto un numero fisso di file di log virtuali per un file di log fisico. Il motore di database definisce dinamicamente le dimensioni dei file di log virtuali durante la creazione o l'estensione dei file di log. Il motore di database tenta di tenere alcuni file virtuali. Le dimensioni dei file virtuali dopo l'estensione di un file di log corrispondono alla somma delle dimensioni del log esistente e del nuovo incremento del file. Le dimensioni o il numero di file di log virtuali non possono essere configurati o impostati dagli amministratori.
Creazione di file di log virtuali
La creazione di file di log virtuali (VLF) avviene nel modo seguente:
- In SQL Server 2014 (12.x) e versioni successive se il valore growth successivo è inferiore a 1/8 del valore di dimensione del log fisico attuale, creare 1 file di log virtuale che copra l'aumento delle dimensioni.
- Se l'aumento successivo è superiore a 1/8 della dimensione corrente del log, usare il metodo pre-2014:
- Se il valore growth è inferiore a 64 MB, creare 4 file di log virtuali che coprano l'aumento delle dimensioni (ad esempio per growth di 1 MB creare quattro file virtuali di log da 256 KB).
- Nel database SQL di Azure e a partire da SQL Server 2022 (16.x - tutte le edizioni), la logica è leggermente diversa. Se il valore growth è minore o uguale a 64 MB, il motore di database crea un solo file virtuale di log per coprire le dimensioni di growth.
- Se il valore growth è compreso tra 64 MB e 1 GB, creare 8 file di log virtuali che coprano l'aumento delle dimensioni (ad esempio per growth di 512 MB creare otto file virtuali di log da 64 MB).
- Se il valore growth è superiore a 1 GB, creare 16 file di log virtuali che coprano l'aumento delle dimensioni (ad esempio per growth di 8 GB creare sedici file virtuali di log da 512 MB).
- Se il valore growth è inferiore a 64 MB, creare 4 file di log virtuali che coprano l'aumento delle dimensioni (ad esempio per growth di 1 MB creare quattro file virtuali di log da 256 KB).
Se le dimensioni dei file di log aumentano in modo considerevole a piccoli ma numerosi incrementi, il numero di file di log virtuali sarà elevato. Ciò può rallentare l'avvio del database, le operazioni di backup e ripristino dei log e generare la replica transazionale/CDC e la latenza di rollforward sempre attiva. Se invece i file di log sono impostati su dimensioni elevate con uno o pochi incrementi, il numero di file di log virtuali molto grandi sarà ridotto. Per altre informazioni su una stima corretta per impostare le dimensioni richieste e l'aumento di dimensioni automatico di un log delle transazioni, vedere la sezione Articoli consigliati di Gestire le dimensioni del file registro transazioni.
È consigliabile disporre di e un valore growth_increment relativamente alto e creare file di log con una dimensione prossima alle dimensioni finali necessarie usando gli incrementi necessari per ottenere una distribuzione ottimale dei file di log virtuali.
Vedere i suggerimenti seguenti per determinare la distribuzione ottimale dei file di log virtuali per le dimensioni correnti del log delle transazioni:
- Il valore size, impostato dall'argomento
SIZEdiALTER DATABASE, corrisponde alle dimensioni iniziali del file di log. - Il valore growth_increment, vale a dire il valore di aumento automatico, impostato dall'argomento
FILEGROWTHdei setALTER DATABASE, è la quantità di spazio che viene aggiunta al file ogni volta che è richiesto spazio nuovo.
Per altre informazioni sugli argomenti FILEGROWTH e SIZE di ALTER DATABASE, vedere Opzioni per file e filegroup ALTER DATABASE (Transact-SQL)..
Suggerimento
Per determinare la distribuzione ottimale dei file di log virtuali per le dimensioni correnti del log delle transazioni di tutti i database in un'istanza specifica e gli incrementi della crescita necessari per ottenere le dimensioni richieste, vedere questo Script per correggere i file di log virtuali su GitHub.
Cosa succede quando sono presenti troppi file di log virtuali?
Durante le fasi iniziali di un processo di ripristino del database, SQL Server individua tutti i file di log virtuali nei file registro transazioni e compila un elenco di questi file di log virtuali. Questo processo può richiedere molto tempo a seconda del numero di file di log virtuali presenti nel database specifico. Maggiore è il numero di file di log virtuali, più lungo è il processo. Un database può terminare con un numero elevato di file di log virtuali se si verifica un aumento automatico frequente del log delle transazioni o una crescita manuale a piccoli incrementi. Quando il numero di file di log virtuali raggiunge l'intervallo di diverse centinaia di migliaia, si possono riscontrare alcuni o la maggior parte dei seguenti sintomi:
- Il completamento del ripristino durante l'avvio di SQL Server richiede molto tempo per uno o più database.
- Il completamento del ripristino di un database richiede molto tempo.
- Il completamento dei tentativi di collegamento di un database richiede molto tempo.
- Quando si tenta di configurare il mirroring del database, vengono visualizzati messaggi di errore 1413, 1443 e 1479, che indicano un timeout.
- Quando si tenta di ripristinare un database, si verificano errori correlati alla memoria, ad esempio 701.
- La replica transazionale o Change Data Capture potrebbe riscontrare una latenza significativa.
Quando si esamina il log degli errori di SQL Server, è possibile notare che una quantità significativa di tempo viene impiegata prima della fase di analisi del processo di ripristino del database. Ad esempio:
2022-05-08 14:42:38.65 spid22s Starting up database 'lot_of_vlfs'.
2022-05-08 14:46:04.76 spid22s Analysis of database 'lot_of_vlfs' (16) is 0% complete (approximately 0 seconds remain). Phase 1 of 3. This is an informational message only. No user action is required.
Inoltre, quando si ripristina un database con un numero elevato di file di log virtuali, SQL Server potrebbe registrare un errore MSSQLSERVER_9017:
Database %ls has more than %d virtual log files which is excessive. Too many virtual log files can cause long startup and backup times. Consider shrinking the log and using a different growth increment to reduce the number of virtual log files.
Per altre informazioni, vedere MSSQLSERVER_9017.
Correggere i database con un numero elevato di file di log virtuali
Per mantenere il numero totale di file di log virtuali a un importo ragionevole, ad esempio a un massimo di diverse migliaia, è possibile reimpostare il file registro transazioni in modo che contenga un numero minore di file di log virtuali eseguendo la procedura seguente:
Compattare manualmente i file registro transazioni.
Aumentare manualmente e in un passaggio le dimensioni dei file a quelle necessarie usando il seguente script T-SQL:
ALTER DATABASE <database name> MODIFY FILE (NAME='Logical file name of transaction log', SIZE = <required size>);Nota
È possibile eseguire questo passaggio anche in SQL Server Management Studio usando la pagina delle proprietà del database.
Dopo aver impostato il nuovo layout di file registro transazioni a numero inferiore di file di log virtuali, controllare e apportare le modifiche necessarie alle impostazioni di aumento automatico del log delle transazioni. Questa convalida delle impostazioni garantisce che il file di log eviti di riscontrare lo stesso problema in futuro.
Prima di eseguire una di queste operazioni, assicurarsi di disporre di un backup ripristinabile valido se in un secondo momento dovessero sopraggiungere problemi.
Per determinare la distribuzione ottimale dei file di log virtuali per le dimensioni correnti del log delle transazioni di tutti i database in un'istanza specifica e gli incrementi della crescita necessari per ottenere le dimensioni richieste, è possibile usare il seguente script di GitHub per correggere i file di log virtuali.
Blocchi di log
Ogni file di log virtuale contiene uno o più blocchi di log. Ogni blocco di log è costituito dai record di log (allineati a un limite di 4 byte). Un blocco di log è variabile in dimensioni ed è sempre un numero intero multiplo di 512 byte (la dimensione minima del settore supportata da SQL Server) con una dimensione massima di 60 KB. Un blocco di log è l'unità di base di I/O per il log delle transazioni.
In sintesi, un blocco di log è un contenitore di record di log usato come unità di base per il log delle transazioni durante la scrittura di record di log su disco.
Ogni blocco di log all'interno di un file di log virtuali viene indirizzato in modo univoco dall'offset del blocco. Il primo blocco ha sempre un offset di blocco che punta al di là dei primi 8 KB nel file di log virtuale.
In generale, un file di log virtuali viene sempre riempito con blocchi di log. È possibile che l'ultimo blocco di log in un file di log virtuali sia vuoto, ad esempio che non contenga record di log. Ciò si verifica quando un record di log da scrivere non rientra nel blocco di log corrente e anche quando lo spazio lasciato sul file di log virtuali non è sufficiente a contenere questo record di log. In questo caso viene creato un blocco di log vuoto che riempie il file di log virtuali. Il record di log viene inserito nel primo blocco del file di log virtuali successivo.
Natura circolare del log delle transazioni
Il log delle transazioni è un file circolare. Si consideri ad esempio un database con un file di log fisico diviso in quattro file di log virtuali. Quando viene creato il database, il file di log logico comincia all'inizio del file di log fisico. Vengono aggiunti nuovi record di log alla fine del log logico, che si espandono verso la fine del log fisico. Il troncamento del log libera tutti i log virtuali i cui record vengono visualizzati tutti davanti al numero minimo di sequenza del file di log (MinLSN, Minimum Log Sequence Number) per il recupero. MinLSN è il numero di sequenza del file di log del record di log meno recente necessario per un corretto rollback a livello di database. Il log delle transazioni del database di esempio sarebbe simile a quello illustrato nel diagramma seguente.
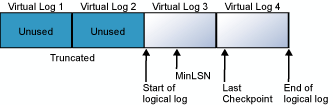
Quando la fine del log logico raggiunge la fine del file di log fisico, i nuovi record di log vengono nuovamente inseriti a partire dall'inizio del file di log fisico.
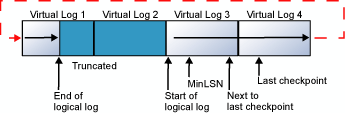
Questo ciclo viene ripetuto all'infinito, a condizione che la fine del log logico non raggiunga mai l'inizio del log stesso. Se i vecchi record di log vengono troncati abbastanza frequentemente in modo da lasciare sempre spazio sufficiente per i nuovi record di log creati fino al checkpoint successivo, il log non viene mai riempito completamente. Se, tuttavia, la fine del log logico raggiunge l'inizio del log stesso, può verificarsi uno dei due eventi indicati di seguito:
Se è abilitata l'impostazione
FILEGROWTHper il log e sul disco vi è spazio disponibile, il file viene esteso in base al valore specificato nel parametro growth_increment e i nuovi record del log vengono aggiunti all'estensione. Per altre informazioni sull'impostazioneFILEGROWTH, vedere Opzioni per file e filegroup ALTER DATABASE (Transact-SQL).Se l'impostazione
FILEGROWTHnon è abilitata oppure se lo spazio disponibile sul disco in cui risiede il file di log è inferiore a quello specificato in growth_increment, viene generato un errore 9002. Per altre informazioni, vedere Risolvere i problemi relativi a un log delle transazioni pieno (Errore di SQL Server 9002).
Se il log include più file di log fisici, il log logico utilizza tutti i file di log fisici prima di eseguire il wrapping all'avvio del primo file di log fisico.
Importante
Per altre informazioni sulla gestione delle dimensioni del log delle transazioni, vedere Gestione delle dimensioni del file di log delle transazioni.
Troncamento del log
Il troncamento del log è essenziale per evitare il riempimento del log. Il troncamento del log comporta l'eliminazione dei file di log virtuali inattivi dal log delle transazioni logico di un database di SQL Server, liberando spazio nel log logico per il riutilizzo da parte del log delle transazioni fisico. Se un log delle transazioni non viene mai troncato, le sue dimensioni aumenteranno fino a occupare tutto lo spazio su disco allocato ai relativi file di log fisici. Tuttavia, prima che sia possibile troncare il log, è necessario eseguire un'operazione su checkpoint. Tramite un checkpoint vengono scritte le pagine correnti modificate in memoria, note come pagine dirty, e le informazioni relative al log delle transazioni dalla memoria sul disco. Quando viene eseguito il checkpoint, la parte inattiva del log delle transazioni viene contrassegnata come riutilizzabile. Successivamente, la parte inattiva può essere liberata mediante il troncamento del log. Per altre informazioni sui checkpoint, vedere Checkpoint di database (SQL Server).
Nei diagrammi seguenti viene illustrato un log delle transazioni prima e dopo il troncamento. Nel primo diagramma viene illustrato un log delle transazioni che non è mai stato troncato. Attualmente, il log logico utilizza quattro file di log virtuali. Il log logico inizia prima del primo file di log virtuale e termina al log virtuale 4. Il record MinLSN si trova nel log virtuale 3. I log virtuali 1 e 2 contengono solo record di log inattivi. Questi record possono essere troncati. Il log virtuale 5 è ancora inutilizzato e non fa parte del log logico corrente.
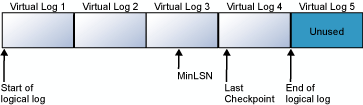
Nel secondo diagramma viene illustrata la struttura del log dopo il troncamento. I log virtuali 1 e 2 sono stati liberati per il riutilizzo. Il log logico ora inizia all'inizio del log virtuale 3. Il log virtuale 5 è ancora inutilizzato e non fa parte del log logico corrente.
A meno che non venga posticipato per qualche motivo, il troncamento del log viene effettuato automaticamente dopo gli eventi seguenti:
- Nel modello di recupero con registrazione minima, dopo un checkpoint.
- Nel modello di recupero con registrazione completa o modello di recupero con registrazione minima delle operazioni bulk, dopo un backup del log se dal backup precedente si è verificato un checkpoint.
Il troncamento del log può essere posticipato da diversi fattori. Se si verifica un ritardo elevato nel troncamento del log, lo spazio del log delle transazioni può esaurirsi. Per informazioni, vedere Fattori che possono posticipare il troncamento del log e Risolvere i problemi relativi a un log delle transazioni completo (Errore 9002 di SQL Server).
Log delle transazioni write-ahead
In questa sezione viene descritto il ruolo del log delle transazioni write-ahead nella registrazione delle modifiche dei dati sul disco. SQL Server usa un algoritmo di log write-ahead (WAL) che garantisce che le modifiche apportate ai dati non vengano scritte nel disco prima del record di log corrispondente. In questo modo, è possibile mantenere le proprietà ACID per una transazione.
Per altre informazioni su WAL, vedere i concetti fondamentali di input/output per SQL Server.
Per comprendere il funzionamento dei log write-ahead in relazione al log delle transazioni, è importante conoscere la modalità con cui i dati modificati vengono scritti sul disco. SQL Server mantiene una cache del buffer (anche nota come pool di buffer) in cui vengono lette le pagine di dati quando questi ultimi devono essere recuperati. Quando una pagina viene modificata nella cache del buffer, non viene immediatamente riscritta nel disco, ma viene contrassegnata come dirty. A una pagina di dati possono essere associate più scritture logiche prima di essere scritta fisicamente sul disco. Per ogni scrittura logica, viene inserito un record del log delle transazioni nella cache del log, per registrare la modifica. I record di log devono essere scritti sul disco prima che la pagina dirty associata venga rimossa dalla cache buffer e scritta sul disco. Tramite il processo di gestione dei checkpoint viene eseguita periodicamente l'analisi della cache buffer alla ricerca di buffer con pagine di un database specifico e tutte le pagine dirty vengono scritte nel disco. I checkpoint consentono di risparmiare tempo durante un successivo recupero, grazie alla creazione di un punto in cui è certo che tutte le pagine dirty siano state scritte sul disco.
La scrittura di una pagina di dati modificata dalla cache buffer al disco viene definita scaricamento della pagina. SQL Server dispone della logica tramite cui viene impedito lo scaricamento di una pagina dirty prima della scrittura del record di log associato. I record di log vengono scritti su disco quando i buffer di log vengono scaricati. Ciò si verifica ogni volta che viene eseguito il commit di una transazione o che i buffer di log sono pieni.
Backup del log delle transazioni
In questa sezione vengono introdotti concetti relativi al backup e al ripristino, vale a dire all'applicazione, di log delle transazioni. In base ai modelli di recupero con registrazione completa e con registrazione minima delle operazioni bulk, per poter recuperare i dati è necessario eseguire backup di routine dei log delle transazioni (backup del log). È possibile eseguire il backup del log mentre è in esecuzione un qualsiasi backup completo. Per altre informazioni sui modelli di recupero, vedere Backup e ripristino di database SQL Server.
Prima di creare il primo backup del log, è necessario creare un backup completo, ad esempio un backup del database oppure il primo di un set di backup di file. Il ripristino di un database solo tramite backup di file può essere un'operazione complessa. Quando possibile, è pertanto consigliabile iniziare con un backup completo del database. Eseguire quindi regolarmente il backup del log delle transazioni. In questo modo, è possibile non solo limitare al minimo il rischio di perdita dei dati, ma anche abilitare il troncamento del log delle transazioni. In genere, il troncamento del log delle transazioni viene eseguito dopo ogni backup del log convenzionale,
Importante
È consigliabile eseguire backup del log sufficientemente frequenti da soddisfare i requisiti aziendali e in particolare il requisito relativo alla tolleranza per eventuali perdite di dati, che potrebbero ad esempio verificarsi in seguito al danneggiamento della risorsa di archiviazione dei log.
La frequenza appropriata per l'esecuzione dei backup del log viene determinata in base al raggiungimento di un compromesso tra la tolleranza per il rischio di perdita dei dati e la quantità di backup del log che è possibile archiviare, gestire e potenzialmente ripristinare. Considerare l'obiettivo del tempo di ripristino (RTO) e l'obiettivo del punto di ripristino (RPO) necessari quando si implementa la strategia di ripristino, in particolare la frequenza di backup del log. Potrebbe essere sufficiente eseguire un backup del log ogni 15 - 30 minuti. Se nella propria azienda è necessario limitare al minimo il rischio di perdita dei dati, valutare se eseguire i backup del log con una maggiore frequenza. L'esecuzione di backup del log più frequenti offre il vantaggio aggiuntivo di un aumento della frequenza del troncamento del log, con una conseguente riduzione delle dimensioni dei file di log.
Per limitare il numero di backup dei log che è necessario ripristinare, è fondamentale eseguire regolarmente il backup dei dati. Ad esempio, è possibile pianificare un backup completo del database una volta la settima e backup differenziali del database una volta al giorno.
Considerare gli obiettivi RTO e RPO richiesti quando si implementa la strategia di ripristino, in particolare la frequenza del backup completo e differenziale del database.
Per altre informazioni sui backup del log delle transazioni, vedere Backup di log delle transazioni (SQL Server).
La catena di log
Una sequenza continua di backup del log è denominata catena di log. Una catena di log ha inizio con un backup completo del database. In genere, una nuova catena di log viene creata solo quando si esegue il backup del database per la prima volta oppure dopo il passaggio dal modello di recupero con registrazione minima al modello di recupero con registrazione completa o con registrazione minimadelle operazioni bulk. Se si sceglie di non sovrascrivere i set di backup esistenti durante la creazione di un backup completo del database, la catena di log esistente rimane intatta. Con la catena di log intatta, è possibile ripristinare il database da qualsiasi backup completo del database nel set di supporti, seguito da tutti i backup del log successivi tramite il punto di recupero specifico. Il punto di recupero può essere la fine dell'ultimo backup del log o un punto di recupero specifico in uno dei backup del log. Per altre informazioni, vedere Backup di log delle transazioni (SQL Server).
Per ripristinare un database al punto in cui si è verificato l'errore, è necessario che la catena di log sia intatta. In altre parole, è necessario che una sequenza non interrotta di backup del log delle transazioni si estenda fino al punto di errore. Il punto in cui la sequenza del log deve iniziare dipende dal tipo di backup dei dati che si sta ripristinando, ovvero un backup del database, parziale o di file. Nel caso di un backup del database o parziale, la sequenza di backup del log si deve estendere dalla fine di un backup del database o parziale. Nel caso di un set di backup di file, la sequenza di backup del log si deve estendere dall'inizio di un intero set di backup di file. Per altre informazioni, vedere Applicazione dei backup di log delle transazioni (SQL Server).
Ripristinare i backup di log
Il ripristino di un backup del log esegue il roll forward delle modifiche registrate nel log delle transazioni in modo da ricreare l'esatto stato del database esistente all'inizio dell'operazione di backup del log. Quando si ripristina un database, è necessario ripristinare i backup del log creati dopo il backup completo del database ripristinato oppure dall'inizio del primo backup di file ripristinato. In genere, dopo il ripristino del backup dei dati o del backup differenziale più recente, è necessario ripristinare una serie di backup del log fino al punto di recupero desiderato. Recuperare quindi il database. Verrà eseguito il rollback di tutte le transazioni incomplete nel momento in cui è iniziato il recupero e verrà attivata la modalità online per il database. Dopo il ripristino del database, non è possibile ripristinare altri backup. Per altre informazioni, vedere Applicazione dei backup di log delle transazioni (SQL Server).
Checkpoint e la parte attiva del log
I checkpoint scaricano le pagine di dati dirty dalla cache buffer del database corrente al disco riducendo al minimo la parte attiva del log da elaborare durante un recupero con registrazione completa del database, durante il quale vengono eseguiti i tipi seguenti di azioni:
- Rollforward dei record di log relativi alle modifiche non scaricate su disco prima dell'arresto del sistema.
- Viene eseguito il rollback di tutte le modifiche associate a transazioni incomplete, ad esempio transazioni per cui non esiste un record di log COMMIT o ROLLBACK.
Funzionamento dei checkpoint
Un checkpoint esegue i processi seguenti nel database:
Scrive nel file di log un record che indica l'inizio del checkpoint.
Archivia le informazioni registrate per il checkpoint in una catena di record di log relativi al checkpoint.
Una delle informazioni registrate nel checkpoint è il numero di sequenza del file di log (LSN) del primo record che deve essere presente per poter eseguire correttamente il rollback a livello di database. Questo numero LSN è denominato LSN minimo del recupero (MinLSN). Il numero MinLSN è il valore minimo tra:
- Numero LSN dell'inizio del checkpoint.
- Numero LSN dell'inizio della transazione attiva meno recente.
- Numero LSN dell'inizio della transazione di replica meno recente non ancora recapitata al database di distribuzione.
I record del checkpoint contengono inoltre un elenco di tutte le transazioni attive che hanno modificato il database.
Se il database utilizza il modello di recupero con registrazione minima, contrassegna per il riutilizzo lo spazio che precede il numero MinLSN.
Scrive sul disco tutte le pagine di log e di dati dirty.
Scrive nel file di log un record che indica la fine del checkpoint.
Scrive il numero LSN corrispondente all'inizio della catena nella pagina di avvio del database.
Attività che causano un checkpoint
I checkpoint vengono eseguiti nelle situazioni seguenti:
- Viene eseguita esplicitamente un'istruzione CHECKPOINT. Viene eseguito un checkpoint nel database corrente per la connessione.
- Nel database viene eseguita un'operazione con registrazione minima, ad esempio viene eseguita un'operazione di copia bulk in un database che utilizza il modello di recupero con registrazione minima delle operazioni bulk.
- Vengono aggiunti o rimossi file di database utilizzando l'istruzione ALTER DATABASE.
- Un'istanza di SQL Server viene arrestata da un'istruzione SHUTDOWN o dall'arresto del servizio SQL Server (MSSQLSERVER). Entrambe le azioni causano un checkpoint in ogni database dell'istanza di SQL Server.
- Un'istanza di SQL Server genera periodicamente checkpoint automatici in ogni database per ridurre il tempo necessario all'istanza per il recupero del database.
- Viene eseguito un backup del database.
- Viene eseguita un'attività che richiede la chiusura di un database. Ciò può verificarsi quando l'opzione AUTO_CLOSE è impostata su ON e viene chiusa l'ultima connessione utente al database. Un altro esempio è quando viene apportata una modifica dell'opzione di database che richiede un riavvio del database.
Checkpoint automatici
Il motore di database di SQL Server genera checkpoint automatici. L'intervallo fra i checkpoint automatici dipende dalla quantità di spazio di log utilizzata e dal tempo trascorso dall'ultimo checkpoint. Questo intervallo di tempo è estremamente variabile e se al database vengono apportate poche modifiche può essere molto lungo. I checkpoint automatici possono anche essere eseguiti di frequente, se si modificano grandi quantità di dati.
Usare l'opzione di configurazione del server dell' intervallo di recupero per calcolare l'intervallo tra i checkpoint automatici per tutti i database in un'istanza del server. Questa opzione specifica il periodo di tempo massimo che può essere usato dal motore di database per recuperare un database durante un riavvio del sistema. Il motore di database stima il numero di record di log che è possibile elaborare nell' intervallo di recupero durante un'operazione di recupero.
L'intervallo fra i checkpoint automatici dipende anche dal modello di recupero:
Se il database usa il modello di recupero con registrazione completa o con registrazione minima delle operazioni bulk, viene generato un checkpoint automatico ogni volta che il numero di record di log raggiunge il valore che il motore di database stima sia possibile elaborare nel periodo di tempo specificato dall'opzione dell'intervallo di recupero.
Se il database utilizza il modello di recupero con registrazione minima, viene generato un checkpoint automatico ogni volta che il numero di record di log raggiunge il minore tra i valori seguenti:
- Il log viene riempito al 70%.
- Il numero di record di log raggiunge il valore che il motore di database stima sia possibile elaborare nel periodo di tempo specificato dall'opzione dell'intervallo di recupero.
Per altre informazioni sull'impostazione dell'intervallo di recupero, vedere Configurare l'intervallo di recupero (min) (opzione di configurazione del server).
Suggerimento
L'opzione di impostazione avanzata -k di SQL Server consente all'amministratore del database di limitare il comportamento di I/O del checkpoint in base alla velocità effettiva del sottosistema di I/O per alcuni tipi di checkpoint. L'opzione di impostazione -k si applica ai checkpoint automatici e ai checkpoint senza limitazione.
I checkpoint automatici troncano la parte non utilizzata del log delle transazioni se il database utilizza il modello di recupero con registrazione minima, ma non se il database utilizza il modello di recupero con registrazione completa o con registrazione minima delle operazioni bulk. Per altre informazioni, vedere Log delle transazioni.
L'istruzione CHECKPOINT offre ora l'argomento facoltativo checkpoint_duration che specifica il tempo necessario in secondi per il completamento dei checkpoint. Per altre informazioni, vedere CHECKPOINT (Transact-SQL).
Log attivo
La parte del file di log compresa tra il numero MinLSN e l'ultimo record di log scritto viene definita parte attiva del log o log attivo. ed è necessaria per eseguire il recupero con registrazione completa del database. Non è possibile troncare nessuna parte del log attivo. Tutti i record del log devono essere troncati dalle parti del log che precedono il numero MinLSN.
Nel diagramma seguente viene illustrata una versione semplificata della parte finale di un log delle transazioni con due transazioni attive. I record di checkpoint sono stati compattati in un unico record.

LSN 148 è l'ultimo record del log delle transazioni. Quando è stato elaborato il checkpoint registrato in corrispondenza del numero LSN 147, era stato eseguito il commit di Tran 1 e Tran 2 era l'unica transazione attiva. Pertanto, il primo record di log di Tran 2 è il meno recente di una transazione attiva al momento dell'ultimo checkpoint e, di conseguenza, il numero MinLSN corrisponde a LSN 142, ovvero al record di inizio della transazione Tran 2.
Transazioni con esecuzione prolungata
Il log attivo deve includere tutte le parti di tutte le transazioni di cui non è stato eseguito il commit. Se un'applicazione avvia una transazione e non ne esegue il commit o il rollback, il motore di database non fa aumentare il numero MinLSN. Questa situazione può dare luogo a due tipi di problemi:
- Se il sistema viene arrestato dopo che la transazione ha eseguito numerose modifiche di cui non è stato eseguito il commit, la fase di recupero del riavvio successivo può richiedere tempi notevolmente più lunghi rispetto al valore specificato dall'opzione dell' intervallo di recupero .
- È possibile che il log raggiunga dimensioni considerevoli in quanto non può essere troncato dopo il numero MinLSN. Ciò si verifica anche se il database utilizza il modello di recupero con registrazione minima, in base al quale il log delle transazioni viene troncato in corrispondenza di ogni checkpoint automatico.
È possibile evitare il ripristino di transazioni a esecuzione prolungata e i problemi descritti in questo articolo usando il ripristino accelerato del database, una funzionalità disponibile a partire da SQL Server 2019 (15.x) e nel database SQL di Azure.
Transazioni di replica
L'agente di lettura log esegue il monitoraggio del log delle transazioni di tutti i database configurati per la replica transazionale e copia le transazioni contrassegnate per la replica dal log delle transazioni al database di distribuzione. Il log attivo deve contenere tutte le transazioni contrassegnate per la replica, ma non ancora recapitate al database di distribuzione. Tali transazioni potrebbero impedire il troncamento del log, se non vengono replicate tempestivamente. Per altre informazioni, vedere Replica transazionale.
Contenuto correlato
- Log delle transazioni
- Gestione delle dimensioni del file di log delle transazioni
- Backup del log delle transazioni (SQL Server)
- Checkpoint di database (SQL Server)
- Configurare l'intervallo di recupero (min) (opzione di configurazione del server)
- Ripristino accelerato del database
- sys.dm_db_log_info (Transact-SQL)
- sys.dm_db_log_space_usage (Transact-SQL)
- Informazioni sulla registrazione e il recupero in SQL Server di Paul Randall
- Gestione del log delle transazioni di SQL Server di Tony Davis e Gail Shaw