CREATE EXTERNAL TABLE (Transact-SQL)
Crea una tabella esterna.
Questo articolo fornisce la sintassi, gli argomenti, la sezione Osservazioni, le autorizzazioni ed esempi per qualsiasi prodotto SQL scelto.
Per altre informazioni sulle convenzioni della sintassi, vedere Convenzioni della sintassi Transact-SQL.
Selezionare un prodotto
Nella riga seguente selezionare il nome del prodotto a cui si è interessati. Verranno visualizzate solo le informazioni per tale prodotto.
* SQL Server *
Panoramica: SQL Server
Questo comando crea una tabella esterna per PolyBase per accedere ai dati archiviati in un cluster Hadoop o Archiviazione BLOB di Azure tabella esterna PolyBase che fa riferimento ai dati archiviati in un cluster Hadoop o Archiviazione BLOB di Azure.
Si applica a: SQL Server 2016 (o versione successiva)
Usa una tabella esterna con un'origine dati esterna per le query PolyBase. Le origini dati esterne vengono usate per stabilire la connettività e supportano questi casi d'uso principali:
- Virtualizzazione dati e caricamento dati con PolyBase
- Operazioni di caricamento bulk con SQL Server o database SQL con
BULK INSERToOPENROWSET
Vedere anche CREATE EXTERNAL DATA SOURCE e DROP EXTERNAL TABLE.
Sintassi
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'folder_or_filepath',
DATA_SOURCE = external_data_source_name,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ ,...n ] ]
)
[;]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argomenti
{ nome_database.nome_schema.nome_tabella | nome_schema.nome_tabella | nome_tabella }
Nome della tabella da creare, composto da una, due o tre parti. Per una tabella esterna, SQL archivia solo i metadati della tabella insieme alle statistiche di base relative al file o alla cartella a cui viene fatto riferimento in Hadoop o Archiviazione BLOB di Azure. Nessun dato effettivo viene spostato o archiviato in SQL Server.
Importante
Per ottenere prestazioni ottimali, se il driver dell'origine dati esterna supporta un nome in tre parti, è consigliabile specificare il nome in tre parti.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE supporta la possibilità di configurare il nome di colonna, il tipo di dati, il supporto dei valori Null e le regole di confronto. Non è possibile usare DEFAULT CONSTRAINT nelle tabelle esterne.
Le definizioni di colonna, inclusi i tipi di dati e il numero di colonne, devono corrispondere ai dati nei file esterni. In casa di mancata corrispondenza, le righe del file verranno rifiutate quando si esegue la query sui dati effettivi.
LOCATION = 'folder_or_filepath'
Specifica la cartella o il percorso e il nome del file per i dati effettivi in Hadoop o in Archiviazione BLOB di Azure. Inoltre, l'archiviazione di oggetti compatibile con S3 è supportata a partire da SQL Server 2022 (16.x)). Il percorso inizia dalla cartella radice. La cartella radice è la posizione dei dati specificata nell'origine dati esterna.
In SQL Server l'istruzione CREATE EXTERNAL TABLE crea il percorso e la cartella, se non esiste già. Quindi è possibile usare INSERT INTO per esportare i dati da una tabella di SQL Server locale a un'origine dati esterna. Per altre informazioni, vedere l'articolo relativo alle query di PolyBase.
Se si specifica che LOCATION deve essere una cartella, una query PolyBase che effettua selezioni dalla tabella esterna recupererà i file dalla cartella e da tutte le relative sottocartelle. Proprio come Hadoop, PolyBase non restituisce le cartelle nascoste. Inoltre, non restituisce i file il cui nome file inizia con un carattere di sottolineatura (_) o un punto (.).
Nell'esempio di immagine seguente, se LOCATION='/webdata/', una query PolyBase restituirà righe da mydata.txt e mydata2.txt. Non verrà restituito mydata3.txt perché si tratta di un file in una sottocartella nascosta. Non restituirà _hidden.txt perché è un file nascosto.
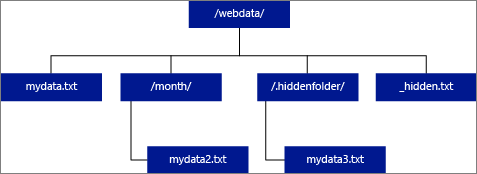
Per modificare l'impostazione predefinita e leggere solo dalla directory radice, impostare l'attributo <polybase.recursive.traversal> su 'false' nel file di configurazione core-site.xml. Questo file si trova nella <SqlBinRoot>\PolyBase\Hadoop\Confbin radice di SQL Server. Ad esempio: C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn.
DATA_SOURCE = external_data_source_name
Specifica il nome dell'origine dati esterna che contiene il percorso dei dati esterni. Questo percorso è un file system Hadoop (HDFS), un contenitore Archiviazione BLOB di Azure o Azure Data Lake Store. Per creare un'origine dati esterna, usare CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Specifica il nome dell'oggetto formato file esterno in cui sono archiviati il tipo di file e il metodo di compressione per i dati esterni. Per creare un formato di file esterno, usare CREATE EXTERNAL FILE FORMAT.
I formati di file esterni possono essere riutilizzati da più file esterni simili.
Opzioni di rifiuto
Questa opzione può essere usata solo con origini dati esterne in cui TYPE = HADOOP.
È possibile specificare i parametri di rifiuto che determinano in che modo PolyBase gestirà i record dirty che recupera dall'origine dati esterna. Un record di dati è considerato "dirty" se i tipi di dati effettivi o il numero di colonne non corrispondono alle definizioni di colonna della tabella esterna.
Se non si specificano o si modificano i valori di rifiuto, PolyBase usa i valori predefiniti. Queste informazioni sui parametri di rifiuto vengono archiviate come metadati aggiuntivi quando si crea una tabella esterna con l'istruzione CREATE EXTERNAL TABLE. Quando un'istruzione SELECT o SELECT INTO SELECT futura seleziona i dati dalla tabella esterna, PolyBase usa le opzioni di rifiuto per determinare il numero o la percentuale di righe che possono essere rifiutate prima che la query effettiva abbia esito negativo. La query restituirà risultati (parziali) finché non viene superata la soglia di rifiuto, quindi ha esito negativo con il messaggio di errore appropriato.
REJECT_TYPE = value | percentage
Chiarisce se l'opzione REJECT_VALUE è specificata come valore letterale o percentuale.
value
REJECT_VALUE è un valore letterale, non una percentuale. La query avrà esito negativo quando il numero di righe rifiutate supera reject_value.
Ad esempio, se REJECT_VALUE = 5 e REJECT_TYPE = value, la query SELECT avrà esito negativo dopo il rifiuto di cinque righe.
percentuale
REJECT_VALUE è una percentuale, non un valore letterale. Una query avrà esito negativo quando la percentuale di righe non riuscite supera reject_value. La percentuale di righe con esito negativo viene calcolata a intervalli.
REJECT_VALUE = reject_value
Specifica il valore o la percentuale di righe che possono essere rifiutate prima che la query abbia esito negativo.
Per REJECT_TYPE = value, reject_value deve essere un numero intero compreso tra 0 e 2.147.483.647.
Per REJECT_TYPE = percentage, reject_value deve essere un valore float compreso tra 0 e 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Questo attributo è obbligatorio quando si specifica REJECT_TYPE = percentage. Determina il numero di righe che si deve tentare di recuperare prima che PolyBase ricalcoli la percentuale di righe rifiutate.
Il parametro reject_sample_value deve essere un numero intero compreso tra 0 e 2.147.483.647.
Ad esempio, se REJECT_SAMPLE_VALUE = 1000, PolyBase calcola la percentuale di righe con esito negativo dopo che ha tentato di importare 1000 righe dal file di dati esterno. Se la percentuale di righe non riuscite è minore di reject_value, PolyBase tenta di recuperare altre 1.000 righe. Continua a ricalcolare la percentuale di righe non riuscite dopo aver tentato di importare ogni 1.000 righe aggiuntive.
Nota
Poiché PolyBase calcola la percentuale di righe con esito negativo a intervalli, la percentuale effettiva di tali righe può superare reject_value.
Esempio:
Questo esempio illustra come le tre opzioni REJECT interagiscono tra loro. Ad esempio, se REJECT_TYPE = percentage, REJECT_VALUE = 30 e REJECT_SAMPLE_VALUE = 100, potrebbe verificarsi il seguente scenario:
- PolyBase tenta di recuperare le prime 100 righe di cui 25 avranno esito negativo e 75 esito positivo.
- La percentuale di righe con esito negativo viene calcolata come 25%, che è minore del valore di rifiuto pari al 30%. Di conseguenza, PolyBase continua a recuperare i dati dall'origine dati esterna.
- PolyBase tenta di caricare le 100 righe successive: questa volta 25 righe hanno esito positivo e 75 righe hanno esito negativo.
- Percentuale di righe con esito negativo viene ricalcolata come 50%. La percentuale di righe con esito negativo ha superato il valore di rifiuto del 30%.
- La query PolyBase ha esito negativo con il 50% di righe rifiutate dopo aver tentato di restituire le prime 200 righe. Si noti che le righe corrispondenti vengono restituite prima che la query PolyBase rilevi che è stata superata la soglia di rifiuto.
REJECTED_ROW_LOCATION = posizione della directory
Si applica a: SQL Server 2019 CU6 e versioni successive, Azure Synapse Analytics.
Specifica la directory all'interno dell'origine dati esterna in cui vengono scritte le righe rifiutate e il file di errori corrispondente.
Se il percorso specificato non esiste, PolyBase ne crea uno per conto dell'utente. Viene creata una directory figlio con il nome _rejectedrows. Il _ carattere garantisce che la directory venga preceduta da un carattere di escape per altre elaborazioni dati, a meno che non venga specificato in modo esplicito nel parametro location. All'interno di questa directory è presente una cartella creata in base all'ora di caricamento dell'invio nel formato YearMonthDay -HourMinuteSecond (ad esempio 20230330-173205). In questa cartella vengono scritte due tipi di file, i file _reason (file del motivo) e i file di dati. Questa opzione può essere usata solo con origini dati esterne in cui TYPE = HADOOP e per le tabelle esterne usando DELIMITEDTEXTFORMAT_TYPE. Per altre informazioni, vedere CREATE EXTERNAL DATA SOURCE e CREATE EXTERNAL FILE FORMAT.
I file motivo e i file di dati hanno entrambi il queryID associato all'istruzione CTAS. Poiché i dati e il motivo si trovano in file distinti, i file corrispondenti hanno un suffisso corrispondente.
Autorizzazioni
Richiede queste autorizzazioni utente:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT (si applica solo a Hadoop e Archiviazione di Azure origini dati esterne)
- CONTROL DATABASE (si applica solo a Hadoop e Archiviazione di Azure origini dati esterne)
Si noti che l'account di accesso remoto specificato in DATABASE SCOPED CREDENTIAL usato nel comando
Per Archiviazione BLOB di Azure, quando si configurano le chiavi di accesso e la firma di accesso condiviso nella portale di Azure, gli account di archiviazione Archiviazione BLOB di Azure o ADLS Gen2 configurano le autorizzazioni consentite per concedere almeno le autorizzazioni lettura e scrittura. L'autorizzazione elenco potrebbe essere necessaria anche durante la ricerca tra le cartelle. È anche necessario selezionare sia Container che Object come tipi di risorse consentiti.
Importante
L'autorizzazione ALTER ANY EXTERNAL DATA SOURCE concede a qualsiasi entità di sicurezza la possibilità di creare e modificare qualsiasi oggetto origine dati esterna e, di conseguenza, la possibilità di accedere a tutte le credenziali con ambito database nel database. Questa autorizzazione deve essere considerata con privilegi elevati e quindi essere concessa solo a entità attendibili nel sistema.
Gestione degli errori
Durante l'esecuzione dell'istruzione CREATE EXTERNAL TABLE, PolyBase tenta di connettersi all'origine dati esterna. Se il tentativo di connessione non riesce, l'istruzione ha esito negativo e la tabella esterna non viene creata. La conferma dell'esito negativo del comando può richiedere almeno un minuto perché PolyBase ritenta la connessione prima di stabilire che la query non riesce.
Osservazioni:
Negli scenari di query ad hoc, ad esempio SELECT FROM EXTERNAL TABLE, PolyBase archivia le righe recuperate dall'origine dati esterna in una tabella temporanea. Dopo il completamento della query, PolyBase rimuove ed elimina la tabella temporanea. Nessun dato permanente viene archiviato nelle tabelle SQL.
Al contrario, nello scenario di importazione, ad esempio SELECT INTO FROM EXTERNAL TABLE, PolyBase archivia le righe recuperate dall'origine dati esterna come dati permanenti nella tabella SQL. La nuova tabella viene creata durante l'esecuzione della query quando PolyBase recupera i dati esterni.
PolyBase può eseguire il push di parte del calcolo della query in Hadoop per migliorare le prestazioni della query. Questa operazione è chiamata distribuzione del predicato. Per abilitarla, specificare l'opzione del percorso della gestione risorse di Hadoop in CREATE EXTERNAL DATA SOURCE.
È possibile creare numerose tabelle esterne che fanno riferimento alle stesse o ad altre origini dati esterne.
Limitazioni e restrizioni
Non essendo sotto il controllo di gestione diretto di SQL Server, i dati per una tabella possono essere modificati o rimossi in qualsiasi momento da un processo esterno. Per questo motivo, non si garantisce che i risultati delle query in una tabella esterna siano deterministici. La stessa query può restituire risultati diversi ogni volta che viene eseguita su una tabella esterna. Analogamente, una query può non riuscire se i dati esterni vengono spostati o rimossi.
È possibile creare più tabelle esterne che fanno tutte riferimento a origini dati esterne differenti. Se si eseguono contemporaneamente query in diverse origini dati Hadoop, ogni origine Hadoop deve usare la stessa impostazione di configurazione del server di "connettività Hadoop". Ad esempio, non è possibile eseguire contemporaneamente una query su un cluster Cloudera Hadoop e un cluster Hortonworks Hadoop poiché usano impostazioni di configurazione diverse. Per le impostazioni di configurazione e le combinazioni supportate, vedere Configurazione della connettività di PolyBase.
Quando la tabella esterna usa DELIMITEDTEXT, CSV, PARQUETo DELTA come tipi di dati, le tabelle esterne supportano solo le statistiche per una colonna per CREATE STATISTICS comando.
Solo queste istruzioni Data Definition Language (DDL) sono consentite per le tabelle esterne:
- CREATE TABLE e DROP TABLE
- CREATE STATISTICS e DROP STATISTICS
- CREATE VIEW e DROP VIEW
Costrutti e operazioni non supportati:
- Il vincolo DEFAULT per le colonne di tabelle esterne
- Operazioni di eliminazione, inserimento e aggiornamento di Data Manipulation Language (DML)
Limitazioni delle query
PolyBase può utilizzare al massimo 33.000 file per cartella durante l'esecuzione di 32 query PolyBase simultanee. Questo numero massimo include i file e le sottocartelle presenti in ogni cartella HDFS. Se il livello di concorrenza è inferiore a 32, un utente può eseguire le query PolyBase sulle cartelle in HDFS che contengono più di 33.000 file. È consigliabile usare percorsi brevi per i file esterni e non più di 30.000 file per ogni cartella HDFS. Quando si fa riferimento a troppi file, potrebbe verificarsi un'eccezione di memoria insufficiente in Java Virtual Machine (JVM).
Limitazioni della larghezza della tabella
PolyBase in SQL Server 2016 ha un limite di larghezza di riga di 32 KB, in base alla dimensione massima di una singola riga valida secondo la definizione della tabella. Se la somma dello schema di colonne è maggiore di 32 KB, PolyBase non sarà in grado di eseguire query sui dati.
Limitazioni dei tipi di dati
I tipi di dati seguenti non possono essere usati in tabelle esterne di PolyBase:
- geografiche
- geometry
- hierarchyid
- 'immagine
- testo
- ntext
- xml
- Qualsiasi tipo definito dall'utente
Limitazioni specifiche dell'origine dati
Oracle
I sinonimi di Oracle non possono essere usati con PolyBase.
Tabelle esterne per raccolte MongoDB che contengono matrici
Per creare tabelle esterne nelle raccolte MongoDB contenenti matrici, è necessario usare l'estensione di virtualizzazione dei dati per Azure Data Studio per produrre un'istruzione CREATE EXTERNAL TABLE basata sullo schema rilevato dal driver ODBC PolyBase per MongoDB. Le azioni di appiattimento vengono eseguite automaticamente dal driver. In alternativa, è possibile usare sp_data_source_objects (Transact-SQL) per rilevare lo schema della raccolta (colonne) e creare manualmente la tabella esterna. La stored procedure sp_data_source_table_columns esegue inoltre l'appiattimento automatico tramite il driver ODBC di PolyBase per il driver MongoDB. L'estensione di virtualizzazione dei dati per Azure Data Studio e sp_data_source_table_columns usano le stesse stored procedure interne per eseguire query sullo schema esterno.
Blocco
Blocco condiviso per l'oggetto SCHEMARESOLUTION.
Sicurezza
I file di dati per una tabella esterna vengono archiviati in Hadoop o Archiviazione BLOB di Azure. Questi file di dati vengono creati e gestiti dai processi dell'utente, che sarà responsabile della gestione della sicurezza dei dati esterni.
Esempi
R. Creare una tabella esterna con dati in formato di testo delimitato
Questo esempio illustra tutti i passaggi necessari per creare una tabella esterna i cui dati sono formattati in file di testo delimitato. Definisce un'origine dati esterna mydatasource e un formato di file esterno myfileformat. Questi oggetti a livello di database vengono quindi a cui viene fatto riferimento nell'istruzione CREATE EXTERNAL TABLE. Per altre informazioni, vedere CREATE EXTERNAL DATA SOURCE e CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|')
);
CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
B. Creare una tabella esterna con dati in formato RCFILE
Questo esempio illustra tutti i passaggi necessari per creare una tabella esterna i cui dati sono formattati come RCFILE. Definisce un'origine dati esterna mydatasource_rc e un formato di file esterno myfileformat_rc. Questi oggetti a livello di database vengono quindi a cui viene fatto riferimento nell'istruzione CREATE EXTERNAL TABLE. Per altre informazioni, vedere CREATE EXTERNAL DATA SOURCE e CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
CREATE EXTERNAL TABLE ClickStream_rc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/employee_rc.tbl',
DATA_SOURCE = mydatasource_rc,
FILE_FORMAT = myfileformat_rc
)
;
C. Creare una tabella esterna con dati in formato ORC
Questo esempio illustra tutti i passaggi necessari per creare una tabella esterna i cui dati sono formattati come file ORC. Definisce un'origine dati esterna mydatasource_orc e un formato di file esterno myfileformat_orc. Questi oggetti a livello di database vengono quindi a cui viene fatto riferimento nell'istruzione CREATE EXTERNAL TABLE. Per altre informazioni, vedere CREATE EXTERNAL DATA SOURCE e CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;
CREATE EXTERNAL TABLE ClickStream_orc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
)
;
D. Eseguire query sui dati hadoop
ClickStream è una tabella esterna che si connette al file di testo delimitato employee.tbl in un cluster Hadoop. La query seguente è simile a una query eseguita su una tabella standard. Tuttavia, questa query recupera i dati da Hadoop e quindi calcola i risultati.
SELECT TOP 10 (url) FROM ClickStream WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. Unire i dati Hadoop con i dati SQL
Questa query è simile a un JOIN standard in due tabelle SQL. La differenza è che PolyBase recupera i dati clickstream da Hadoop e quindi lo aggiunge alla UrlDescription tabella. Una tabella è una tabella esterna e l'altra è una tabella SQL standard.
SELECT url.description
FROM ClickStream cs
JOIN UrlDescription url ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. Importare dati da Hadoop in una tabella SQL
In questo esempio viene creata una nuova tabella SQL ms_user che archivia in modo permanente il risultato di un join tra la tabella SQL standard user e la tabella esterna ClickStream.
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. Creare una tabella esterna per SQL Server
Prima di creare credenziali con ambito database, il database utente deve avere una chiave master per proteggerle. Per altre informazioni, vedere CREATE MASTER KEY e CREATE DATABASE SCOPED CREDENTIAL.
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH IDENTITY = 'username', Secret = 'password';
GO
Creare una nuova origine dati esterna denominata SQLServerInstance e una tabella esterna denominata sqlserver.customer:
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
GO
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer(
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
I. Creare una tabella esterna per Oracle
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name)
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. Note this may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_ORDERPRIORITY] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL(38) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='DB1.mySchema.customer',
DATA_SOURCE= external_data_source_name
);
J. Creare una tabella esterna per Teradata
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
K. Creare una tabella esterna per MongoDB
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
.L Eseguire query sull'archiviazione di oggetti compatibile con S3 tramite una tabella esterna
Si applica a: SQL Server 2022 (16.x) e versioni successive
Nell'esempio seguente viene illustrato l'uso di T-SQL per eseguire query su un file Parquet archiviato nell'archivio di oggetti compatibile con S3 tramite query su tabella esterna. L'esempio usa un percorso relativo all'interno dell'origine dati esterna.
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/'
, CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
GO
CREATE EXTERNAL TABLE Region(
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152) )
WITH (LOCATION = '/region/', DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat);
GO
Passaggi successivi
Altre informazioni sui concetti correlati sono disponibili negli articoli seguenti:
* Database SQL di Azure *
Panoramica: database SQL di Azure
Nel database SQL di Azure crea una tabella esterna per query elastiche (in anteprima).
Vedere anche CREATE EXTERNAL DATA SOURCE.
Sintassi
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH ( <sharded_external_table_options> )
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name,
SCHEMA_NAME = N'nonescaped_schema_name',
OBJECT_NAME = N'nonescaped_object_name',
[DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN]]
)
[;]
Argomenti
{ nome_database.nome_schema.nome_tabella | nome_schema.nome_tabella | nome_tabella }
Nome della tabella da creare, composto da una, due o tre parti. Per una tabella esterna, solo i metadati della tabella vengono archiviati in SQL insieme alle statistiche di base relative al file o alla cartella a cui viene fatto riferimento nel database SQL di Azure. I dati effettivi non vengono spostati o archiviati nel database SQL di Azure.
Importante
Per ottenere prestazioni ottimali, se il driver dell'origine dati esterna supporta un nome in tre parti, è consigliabile specificare il nome in tre parti.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE supporta la possibilità di configurare il nome di colonna, il tipo di dati, il supporto dei valori Null e le regole di confronto. Non è possibile usare DEFAULT CONSTRAINT nelle tabelle esterne.
Nota
Il testo , ntext, xmle tipi di dati json non sono supportati per le colonne nelle tabelle esterne per il database SQL di Azure.
Le definizioni di colonna, inclusi i tipi di dati e il numero di colonne, devono corrispondere ai dati nei file esterni. In casa di mancata corrispondenza, le righe del file verranno rifiutate quando si esegue la query sui dati effettivi.
Opzioni per la tabella esterna partizionata
Specifica l'origine dati esterna (un'origine dati non SQL Server) e un metodo di distribuzione per la query elastica.
DATA_SOURCE
La clausola DATA_SOURCE definisce l'origine dati esterna (una mappa di partizioni) usata per la tabella esterna. Per un esempio, vedere Creare tabelle esterne.
Importante
Database SQL di Azure supporta la creazione di tabelle esterne nei tipi ORIGINE DATI ESTERNA RDMS e SHARD_MAP_MANAGER. database SQL di Azure non supporta la creazione di tabelle esterne per Archiviazione BLOB di Azure.
SCHEMA_NAME e OBJECT_NAME
Le clausole SCHEMA_NAME e OBJECT_NAME eseguono il mapping della definizione della tabella esterna a una tabella in uno schema diverso. Se queste clausole vengono omesse, si presuppone che lo schema dell'oggetto remoto sia "dbo" e che il relativo nome sia identico al nome della tabella esterna in fase di definizione. Questo è utile se il nome della tabella remota è già in uso nel database in cui si vuole creare la tabella esterna. Ad esempio, si vuole definire una tabella esterna per ottenere una visualizzazione aggregata delle viste del catalogo o delle viste a gestione dinamica (DMV) nel livello dati con scalabilità orizzontale. Poiché le viste del catalogo e le DMV esistono già localmente, non sarà possibile usare i rispettivi nomi per la definizione della tabella esterna. Usare invece un nome diverso e usare il nome della vista del catalogo o della vista DMV nelle clausole SCHEMA_NAME e/o OBJECT_NAME. Per un esempio, vedere Creare tabelle esterne.
DISTRIBUTION
Facoltativo. Questo argomento è obbligatorio solo per i database di tipo SHARD_MAP_MANAGER. Questo argomento verifica se una tabella viene trattata come una tabella partizionata o una tabella replicata. Con le tabelle SHARDED (nome colonna), i dati provenienti da tabelle diverse non si sovrappongono. REPLICATED specifica che le tabelle devono avere gli stessi dati in ogni partizione. ROUND_ROBIN indica che viene usato un metodo specifico di un'applicazione per distribuire i dati.
La clausola DISTRIBUTION specifica la distribuzione dei dati usata per questa tabella. Query Processor utilizza le informazioni fornite nella clausola DISTRIBUTION per generare i piani di query più efficienti.
- SHARDED indica che i dati sono partizionati orizzontalmente tra i database. La chiave di partizionamento per la distribuzione dei dati è il parametro
sharding_column_name. - REPLICATED indica che in ogni database sono presenti copie identiche della tabella. Sarà quindi necessario assicurarsi che le repliche siano identiche in tutti i database.
- ROUND_ROBIN indica che la tabella è partizionata orizzontalmente con un metodo di distribuzione dipendente dall'applicazione.
Autorizzazioni
Gli utenti con accesso alla tabella esterna ottengono automaticamente l'accesso alle tabelle remote sottostanti con le credenziali specificate nella definizione dell'origine dati esterna. Evitare l'elevazione dei privilegi indesiderata mediante le credenziali dell'origine dati esterna. Usare GRANT o REVOKE per la tabella esterna, come se fosse una tabella comune. Dopo aver definito l'origine dati esterna e le tabelle esterne, è ora possibile usare la sintassi T-SQL completa sulle tabelle esterne.
Gestione degli errori
Durante l'esecuzione dell'istruzione CREATE EXTERNAL TABLE, se il tentativo di connessione non riesce, l'istruzione avrà esito negativo e la tabella esterna non verrà creata. La conferma dell'esito negativo del comando può richiedere almeno un minuto perché il database SQL ritenta la connessione prima di determinare l'esito negativo della query.
Osservazioni:
Negli scenari di query ad hoc, ad esempio SELECT FROM EXTERNAL TABLE, database SQL archivia le righe recuperate dall'origine dati esterna in una tabella temporanea. Dopo il completamento della query, il database SQL rimuove ed elimina la tabella temporanea. Nessun dato permanente viene archiviato nelle tabelle SQL.
Al contrario, nello scenario di importazione, ad esempio SELECT INTO FROM EXTERNAL TABLE, il database SQL archivia le righe recuperate dall'origine dati esterna come dati permanenti nella tabella SQL. La nuova tabella viene creata durante l'esecuzione della query quando il database SQL recupera i dati esterni.
È possibile creare numerose tabelle esterne che fanno riferimento alle stesse o ad altre origini dati esterne.
È possibile creare più tabelle esterne che fanno tutte riferimento a origini dati esterne differenti.
Limitazioni
semantica di isolamento: l'accesso ai dati tramite una tabella esterna non rispetta la semantica di isolamento all'interno di SQL Server. Ciò significa che l'esecuzione di query su una tabella esterna non impone alcun blocco o isolamento dello snapshot. Pertanto, i dati restituiti possono cambiare se i dati nell'origine dati esterna cambiano. La stessa query può restituire risultati diversi ogni volta che viene eseguita su una tabella esterna. Analogamente, una query può non riuscire se i dati esterni vengono spostati o rimossi.
Costrutti e operazioni non supportati:
- Vincolo DEFAULT per le colonne di tabelle esterne.
- Operazioni di eliminazione, inserimento e aggiornamento di Data Manipulation Language (DML).
- Dynamic Data Masking nelle colonne delle tabelle esterne.
- I cursori non sono supportati per le tabelle esterne nel database SQL di Azure.
Solo predicati letterali: solo i predicati letterali definiti in una query possono essere inseriti nell'origine dati esterna. A differenza dei server collegati e dell'accesso ai predicati determinati durante l'esecuzione della query, vale a dire quando vengono usati con un ciclo annidato in un piano di query. Questo comporta spesso la copia dell'intera tabella esterna in locale e quindi unita in join.
Nell'esempio seguente, se
External.Ordersè una tabella esterna eCustomerè una tabella locale, la query copia l'intera tabella esterna in locale perché il predicato necessario non è noto in fase di compilazione.SELECT Orders.OrderId, Orders.OrderTotal FROM External.Orders WHERE CustomerId IN ( SELECT TOP 1 CustomerId FROM Customer WHERE CustomerName = 'MyCompany' );Nessun parallelismo: l'uso di tabelle esterne impedisce l'uso del parallelismo nel piano di query.
Eseguita come query remota: le tabelle esterne vengono implementate come query remote, pertanto il numero stimato di righe restituite è in genere 1000. Esistono altre regole basate sul tipo di predicato usato per filtrare la tabella esterna. Si tratta di stime basate su regole anziché di stime basate sui dati effettivi della tabella esterna. Lo strumento di ottimizzazione non accede all'origine dati remota per ottenere una stima più accurata.
Non supportato per l'endpoint privato: le query di tabella esterne non sono supportate quando la connessione alla tabella remota è un endpoint privato.
Limitazioni dei tipi di dati
I tipi di dati seguenti non possono essere usati in tabelle esterne di PolyBase:
- geografiche
- geometry
- hierarchyid
- 'immagine
- testo
- ntext
- xml
- Qualsiasi tipo definito dall'utente
Blocco
Blocco condiviso per l'oggetto SCHEMARESOLUTION.
Esempi
R. Creare una tabella esterna per il database SQL di Azure
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
( [CustomerID] [int] NOT NULL,
[CustomerName] [varchar](50) NOT NULL,
[Company] [varchar](50) NOT NULL)
WITH
( DATA_SOURCE = MyElasticDBQueryDataSrc)
B. Creare una tabella esterna per un'origine dati partizionata
In questo esempio viene rieseguito il mapping di una DMV remota a una tabella esterna usando le clausole SCHEMA_NAME e OBJECT_NAME.
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]([session_id] smallint NOT NULL,
[request_id] int NOT NULL,
[start_time] datetime NOT NULL,
[status] nvarchar(30) NOT NULL,
[command] nvarchar(32) NOT NULL,
[sql_handle] varbinary(64),
[statement_start_offset] int,
[statement_end_offset] int,
[cpu_time] int NOT NULL)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION=ROUND_ROBIN
);
Passaggi successivi
Per altre informazioni sulle tabelle esterne nel database SQL di Azure, vedere gli articoli seguenti:
* Azure Synapse
Analytics *
Panoramica: Azure Synapse Analytics
Usare una tabella esterna per:
- I pool SQL dedicati possono eseguire query, importare e archiviare dati da Hadoop, Archiviazione BLOB di Azure e Azure Data Lake Storage Gen1 e Gen2.
- I pool SQL serverless possono eseguire query, importare e archiviare dati da Archiviazione BLOB di Azure, Azure Data Lake Storage Gen1 e Gen2. Serverless non supporta
TYPE=Hadoop.
Vedere anche CREATE EXTERNAL DATA SOURCE e DROP EXTERNAL TABLE.
Per altre indicazioni ed esempi sull'uso di tabelle esterne con Azure Synapse, vedere Usare tabelle esterne con Synapse SQL.
Sintassi
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
Argomenti
{ nome_database.nome_schema.nome_tabella | nome_schema.nome_tabella | nome_tabella }
Nome della tabella da creare, composto da una, due o tre parti. Per una tabella esterna, solo i metadati della tabella insieme alle statistiche di base relative al file o alla cartella a cui si fa riferimento in Azure Data Lake, Hadoop o Archiviazione BLOB di Azure. Quando vengono create tabelle esterne, i dati effettivi non vengono spostati né archiviati.
Importante
Per ottenere prestazioni ottimali, se il driver dell'origine dati esterna supporta un nome in tre parti, è consigliabile specificare il nome in tre parti.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE supporta la possibilità di configurare il nome di colonna, il tipo di dati, il supporto dei valori Null e le regole di confronto. Non è possibile usare DEFAULT CONSTRAINT nelle tabelle esterne.
Nota
I tipi di dati testo, ntexte xml non sono supportati tipi di dati per le colonne nelle tabelle esterne per Synapse Analytics.
- Durante la lettura di file delimitati, le definizioni di colonna, inclusi i tipi di dati e il numero di colonne, devono corrispondere ai dati nei file esterni. In casa di mancata corrispondenza, le righe del file verranno rifiutate quando si esegue la query sui dati effettivi.
- Per la lettura da file Parquet, è possibile specificare solo le colonne da leggere e ignorare il resto.
LOCATION = 'folder_or_filepath'
Specifica la cartella o il percorso e il nome del file per i dati effettivi in Azure Data Lake, Hadoop o Archiviazione BLOB di Azure. Il percorso inizia dalla cartella radice. La cartella radice è la posizione dei dati specificata nell'origine dati esterna. L'istruzione CREATE EXTERNAL TABLE AS SELECT crea il percorso e la cartella, se non esistono.
CREATE EXTERNAL TABLE non crea il percorso e la cartella.
Se si specifica che LOCATION deve essere una cartella, una query PolyBase che effettua selezioni dalla tabella esterna recupererà i file dalla cartella e da tutte le relative sottocartelle. Proprio come Hadoop, PolyBase non restituisce le cartelle nascoste. Inoltre, non restituisce i file il cui nome file inizia con un carattere di sottolineatura (_) o un punto (.).
Nell'esempio di immagine seguente, se LOCATION='/webdata/', una query PolyBase restituirà righe da mydata.txt e mydata2.txt. Non verrà restituito mydata3.txt perché si trova in una sottocartella di una cartella nascosta. Non restituirà _hidden.txt perché è un file nascosto.
A differenza delle tabelle esterne hadoop, le tabelle esterne native non restituiscono sottocartelle a meno che non si specifichi /** alla fine del percorso. In questo esempio, se LOCATION='/webdata/', una query del pool SQL serverless restituirà righe da mydata.txt. Non restituirà mydata2.txt e mydata3.txt perché si trovano in una sottocartella. Le tabelle Hadoop restituiranno tutti i file all'interno di qualsiasi sottocartella.
Sia hadoop che tabelle esterne native ignorano i file con i nomi che iniziano con una sottolineatura (_) o un punto (.).
DATA_SOURCE = external_data_source_name
Specifica il nome dell'origine dati esterna che contiene il percorso dei dati esterni. Questo percorso è in Azure Data Lake. Per creare un'origine dati esterna, usare CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Specifica il nome dell'oggetto formato file esterno in cui sono archiviati il tipo di file e il metodo di compressione per i dati esterni. Per creare un formato di file esterno, usare CREATE EXTERNAL FILE FORMAT.
TABLE_OPTIONS
Specifica il set di opzioni che descrivono come leggere i file sottostanti. Attualmente, l'unica opzione disponibile è {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]} che indica alla tabella esterna di ignorare gli aggiornamenti eseguiti sui file sottostanti, anche se ciò potrebbe causare l'incoerenza di alcune operazioni di lettura. Usare questa opzione solo in casi speciali ovvero quando sono stati aggiunti spesso file. Questa opzione è disponibile nel pool SQL serverless per il formato CSV.
Opzioni REJECT
Le opzioni di rifiuto sono disponibili in anteprima per i pool SQL serverless in Azure Synapse Analytics.
Questa opzione può essere usata solo con origini dati esterne in cui TYPE = HADOOP.
È possibile specificare i parametri di rifiuto che determinano in che modo PolyBase gestirà i record dirty che recupera dall'origine dati esterna. Un record di dati è considerato "dirty" se i tipi di dati effettivi o il numero di colonne non corrispondono alle definizioni di colonna della tabella esterna.
Se non si specificano o si modificano i valori di rifiuto, PolyBase usa i valori predefiniti. Queste informazioni sui parametri di rifiuto vengono archiviate come metadati aggiuntivi quando si crea una tabella esterna con l'istruzione CREATE EXTERNAL TABLE. Quando un'istruzione SELECT o SELECT INTO SELECT futura seleziona i dati dalla tabella esterna, PolyBase usa le opzioni di rifiuto per determinare il numero o la percentuale di righe che possono essere rifiutate prima che la query effettiva abbia esito negativo. La query restituirà risultati (parziali) finché non viene superata la soglia di rifiuto, quindi ha esito negativo con il messaggio di errore appropriato.
L'opzione di formato PARSER_VERSION è supportata solo nei pool SQL serverless.
REJECT_TYPE = value | percentage
Chiarisce se l'opzione REJECT_VALUE è specificata come valore letterale o percentuale.
value
REJECT_VALUE è un valore letterale, non una percentuale. La query PolyBase avrà esito negativo se il numero di righe rifiutate supera reject_value.
Ad esempio, se REJECT_VALUE = 5 e REJECT_TYPE = value, la query SELECT di PolyBase avrà esito negativo dopo che sono state rifiutate cinque righe.
percentuale
REJECT_VALUE è una percentuale, non un valore letterale. La query PolyBase avrà esito negativo se la percentuale di righe non eseguite supera il valore reject_value. La percentuale di righe con esito negativo viene calcolata a intervalli.
REJECT_VALUE = reject_value
Specifica il valore o la percentuale di righe che possono essere rifiutate prima che la query abbia esito negativo.
- Per REJECT_TYPE = value, reject_value deve essere un numero intero compreso tra 0 e 2.147.483.647.
- Per REJECT_TYPE = percentage, reject_value deve essere un valore float compreso tra 0 e 100. La percentuale è valida solo per i pool SQL dedicati in cui
TYPE=HADOOP.
La query avrà esito negativo quando il numero di righe rifiutate supera reject_value. Ad esempio, se REJECT_VALUE = 5 e REJECT_TYPE = valore, la query SELECT avrà esito negativo dopo il rifiuto di cinque righe.
REJECT_SAMPLE_VALUE = reject_sample_value
Questo attributo è obbligatorio quando si specifica REJECT_TYPE = percentage. Determina il numero di righe che si deve tentare di recuperare prima che PolyBase ricalcoli la percentuale di righe rifiutate.
Il parametro reject_sample_value deve essere un numero intero compreso tra 0 e 2.147.483.647.
Ad esempio, se REJECT_SAMPLE_VALUE = 1000, PolyBase calcola la percentuale di righe con esito negativo dopo che ha tentato di importare 1000 righe dal file di dati esterno. Se la percentuale di righe non riuscite è minore di reject_value, PolyBase tenta di recuperare altre 1.000 righe. Continua a ricalcolare la percentuale di righe non riuscite dopo aver tentato di importare ogni 1.000 righe aggiuntive.
Nota
Poiché PolyBase calcola la percentuale di righe con esito negativo a intervalli, la percentuale effettiva di tali righe può superare reject_value.
Esempio:
Questo esempio illustra come le tre opzioni REJECT interagiscono tra loro. Ad esempio, se REJECT_TYPE = percentage, REJECT_VALUE = 30 e REJECT_SAMPLE_VALUE = 100, potrebbe verificarsi il seguente scenario:
- PolyBase tenta di recuperare le prime 100 righe di cui 25 avranno esito negativo e 75 esito positivo.
- La percentuale di righe con esito negativo viene calcolata come 25%, che è minore del valore di rifiuto pari al 30%. Di conseguenza, PolyBase continua a recuperare i dati dall'origine dati esterna.
- PolyBase tenta di caricare le 100 righe successive: questa volta 25 righe hanno esito positivo e 75 righe hanno esito negativo.
- Percentuale di righe con esito negativo viene ricalcolata come 50%. La percentuale di righe con esito negativo ha superato il valore di rifiuto del 30%.
- La query PolyBase ha esito negativo con il 50% di righe rifiutate dopo aver tentato di restituire le prime 200 righe. Si noti che le righe corrispondenti vengono restituite prima che la query PolyBase rilevi che è stata superata la soglia di rifiuto.
REJECTED_ROW_LOCATION = posizione della directory
Specifica la directory all'interno dell'origine dati esterna in cui vengono scritte le righe rifiutate e il file di errori corrispondente.
Se il percorso specificato non esiste, verrà creato. Viene creata una directory figlio con il nome _rejectedrows. Il _ carattere garantisce che la directory venga preceduta da un carattere di escape per altre elaborazioni dati, a meno che non venga specificato in modo esplicito nel parametro location.
- Nei pool SQL serverless il percorso è
YearMonthDay_HourMinuteSecond_StatementID. È possibile usarestatementIDper correlare la cartella con la query che l'ha generata. - Nei pool SQL dedicati il percorso creato si basa sul tempo di invio del carico nel formato
YearMonthDay -HourMinuteSecond, ad esempio20180330-173205.
In questa cartella vengono scritti due tipi di file, il _reason file e il file di dati.
Per altre informazioni, vedere CREATE EXTERNAL DATA SOURCE.
Sia i file del motivo che i file di dati hanno il queryID associato all'istruzione CTAS. Poiché i dati e il motivo si trovano in file distinti, i file corrispondenti hanno un suffisso corrispondente.
Nei pool SQL serverless il error.json file contiene una matrice JSON con errori rilevati relativi alle righe rifiutate. Ogni elemento che rappresenta un errore contiene gli attributi seguenti:
| Attributo | Descrizione |
|---|---|
| Error | Motivo per cui la riga viene rifiutata. |
| Riga | Numero ordinale della riga rifiutata nel file. |
| Istogramma | Numero ordinale della colonna rifiutata. |
| Valore | Valore della colonna rifiutata. Se il valore è maggiore di 100 caratteri, vengono visualizzati solo i primi 100 caratteri. |
| file | Percorso del file a cui appartiene la riga. |
Autorizzazioni
Richiede queste autorizzazioni utente:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Nota
Le autorizzazioni CONTROL DATABASE sono necessarie per creare solo MASTER KEY, DATABASE SCOPED CREDENTIAL ed EXTERNAL DATA SOURCE
Si noti che l'account di accesso che crea l'origine dati esterna deve avere l'autorizzazione per leggere e scrivere nell'origine dati esterna, che si trova in Hadoop o Archiviazione BLOB di Azure.
Importante
L'autorizzazione ALTER ANY EXTERNAL DATA SOURCE concede a qualsiasi entità di sicurezza la possibilità di creare e modificare qualsiasi oggetto origine dati esterna e, di conseguenza, la possibilità di accedere a tutte le credenziali con ambito database nel database. Questa autorizzazione deve essere considerata con privilegi elevati e quindi essere concessa solo a entità attendibili nel sistema.
Gestione degli errori
Durante l'esecuzione dell'istruzione CREATE EXTERNAL TABLE, PolyBase tenta di connettersi all'origine dati esterna. Se il tentativo di connessione non riesce, l'istruzione non riesce e la tabella esterna non verrà creata. La conferma dell'esito negativo del comando può richiedere almeno un minuto perché PolyBase ritenta la connessione prima di stabilire che la query non riesce.
Osservazioni:
Negli scenari di query ad hoc, ad esempio SELECT FROM EXTERNAL TABLE, PolyBase archivia le righe recuperate dall'origine dati esterna in una tabella temporanea. Dopo il completamento della query, PolyBase rimuove ed elimina la tabella temporanea. Nessun dato permanente viene archiviato nelle tabelle SQL.
Al contrario, nello scenario di importazione, ad esempio SELECT INTO FROM EXTERNAL TABLE, PolyBase archivia le righe recuperate dall'origine dati esterna come dati permanenti nella tabella SQL. La nuova tabella viene creata durante l'esecuzione della query quando PolyBase recupera i dati esterni.
PolyBase può eseguire il push di parte del calcolo della query in Hadoop per migliorare le prestazioni della query. Questa operazione è chiamata distribuzione del predicato. Per abilitarla, specificare l'opzione del percorso della gestione risorse di Hadoop in CREATE EXTERNAL DATA SOURCE.
È possibile creare numerose tabelle esterne che fanno riferimento alle stesse o ad altre origini dati esterne.
Prestare attenzione ai dati di origine usando le regole di confronto UTF-8. Per i dati di origine che usano le regole di confronto UTF-8, è necessario specificare manualmente regole di confronto non UTF-8 ogni colonna UTF-8 nell'istruzione CREATE EXTERNAL TABLE. Il motivo è che il supporto UTF-8 non si estende alle tabelle esterne. Quando si tenta di creare una tabella esterna con regole di confronto UTF-8, verrà visualizzato un Unsupported collation messaggio di errore. Se le regole di confronto del database della tabella esterna sono regole di confronto UTF-8, la creazione di tabelle esterne avrà esito negativo a meno che non si forniscano regole di confronto esplicite non UTF-8, [UTF8_column] varchar(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL,ad esempio .
I pool SQL serverless e dedicati in Azure Synapse Analytics usano codebase diversi per la virtualizzazione dei dati. I pool SQL serverless supportano una tecnologia di virtualizzazione dei dati nativa. I pool SQL dedicati supportano la virtualizzazione dei dati nativa e PolyBase. La virtualizzazione dei dati PolyBase viene usata quando si crea EXTERNAL DATA SOURCE con TYPE=HADOOP.
Limitazioni e restrizioni
Poiché non si trovano sotto il controllo di gestione diretto di Azure Synapse, i dati per una tabella possono essere modificati o rimossi in qualsiasi momento da un processo esterno. Per questo motivo, non si garantisce che i risultati delle query in una tabella esterna siano deterministici. La stessa query può restituire risultati diversi ogni volta che viene eseguita su una tabella esterna. Analogamente, una query può non riuscire se i dati esterni vengono spostati o rimossi.
È possibile creare più tabelle esterne che fanno tutte riferimento a origini dati esterne differenti.
Solo queste istruzioni Data Definition Language (DDL) sono consentite per le tabelle esterne:
- CREATE TABLE e DROP TABLE
- CREATE STATISTICS e DROP STATISTICS
- CREATE VIEW e DROP VIEW
Costrutti e operazioni non supportati:
- Il vincolo DEFAULT per le colonne di tabelle esterne
- Operazioni di eliminazione, inserimento e aggiornamento di Data Manipulation Language (DML)
- Dynamic Data Masking nelle colonne delle tabelle esterne
Limitazioni delle query
Si consiglia di non fare riferimento a più di 30.000 file per cartella. Quando si fa riferimento a un numero eccessivo di file, potrebbe verificarsi un'eccezione di memoria insufficiente (JVM) Java Virtual Machine o ridurre le prestazioni.
Limitazioni della larghezza della tabella
PolyBase in Azure Data Warehouse ha un limite di larghezza di riga di 1 MB, in base alla dimensione massima di una singola riga valida secondo la definizione della tabella. Se la somma dello schema di colonne è maggiore di 1 MB, PolyBase non sarà in grado di eseguire query sui dati.
Limitazioni dei tipi di dati
I tipi di dati seguenti non possono essere usati in tabelle esterne di PolyBase:
- geografiche
- geometry
- hierarchyid
- 'immagine
- testo
- ntext
- xml
- Qualsiasi tipo definito dall'utente
Blocco
Blocco condiviso per l'oggetto SCHEMARESOLUTION.
Esempi
R. Importare dati da ADLS Gen 2 in Azure Synapse Analytics
Per esempi per Azure Data Lake Storage Gen 1, vedere Creare un'origine dati esterna.
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>' ;
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT
, FORMAT_OPTIONS ( FIELD_TERMINATOR = '|'
, STRING_DELIMITER = ''
, DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff'
, USE_TYPE_DEFAULT = FALSE
)
);
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
( [ProductKey] [int] NOT NULL,
[ProductLabel] nvarchar NULL,
[ProductName] nvarchar NULL )
WITH
(
LOCATION='/DimProduct/' ,
DATA_SOURCE = AzureDataLakeStore ,
FILE_FORMAT = TextFileFormat ,
REJECT_TYPE = VALUE ,
REJECT_VALUE = 0
);
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey] ) )
AS SELECT * FROM
[dbo].[DimProduct_external] ;
B. Importare dati da Parquet in Azure Synapse Analytics
L'esempio seguente crea una tabella esterna. Restituisce quindi la prima riga:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 * FROM census_external_table;
Passaggi successivi
Per altre informazioni sulle tabelle esterne e sui concetti correlati, vedere gli articoli seguenti:
* Piattaforma di strumenti
analitici (PDW) *
Panoramica: Sistema della piattaforma di analisi
Usare una tabella esterna per:
- Eseguire query sui dati di Hadoop o di Archiviazione BLOB di Azure con istruzioni Transact-SQL.
- Importare e archiviare dati da Hadoop o Archiviazione BLOB di Azure nel sistema della piattaforma di analisi.
Vedere anche CREATE EXTERNAL DATA SOURCE e DROP EXTERNAL TABLE.
Sintassi
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
}
Argomenti
{ nome_database.nome_schema.nome_tabella | nome_schema.nome_tabella | nome_tabella }
Nome della tabella da creare, composto da una, due o tre parti. Per una tabella esterna, Analytics Platform System archivia solo i metadati della tabella insieme alle statistiche di base relative al file o alla cartella a cui si fa riferimento in Hadoop o Archiviazione BLOB di Azure. I dati effettivi non vengono spostati o archiviati nella piattaforma di strumenti analitici.
Importante
Per ottenere prestazioni ottimali, se il driver dell'origine dati esterna supporta un nome in tre parti, è consigliabile specificare il nome in tre parti.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE supporta la possibilità di configurare il nome di colonna, il tipo di dati, il supporto dei valori Null e le regole di confronto. Non è possibile usare DEFAULT CONSTRAINT nelle tabelle esterne.
Le definizioni di colonna, inclusi i tipi di dati e il numero di colonne, devono corrispondere ai dati nei file esterni. In casa di mancata corrispondenza, le righe del file verranno rifiutate quando si esegue la query sui dati effettivi.
LOCATION = 'folder_or_filepath'
Specifica la cartella o il percorso e il nome del file per i dati effettivi in Hadoop o in Archiviazione BLOB di Azure. Il percorso inizia dalla cartella radice. La cartella radice è la posizione dei dati specificata nell'origine dati esterna.
Nella piattaforma di strumenti analitici l'istruzione CREATE EXTERNAL TABLE AS SELECT crea il percorso e la cartella, se non esistono.
CREATE EXTERNAL TABLE non crea il percorso e la cartella.
Se si specifica che LOCATION deve essere una cartella, una query PolyBase che effettua selezioni dalla tabella esterna recupererà i file dalla cartella e da tutte le relative sottocartelle. Proprio come Hadoop, PolyBase non restituisce le cartelle nascoste. Inoltre, non restituisce i file il cui nome file inizia con un carattere di sottolineatura (_) o un punto (.).
Nell'esempio di immagine seguente, se LOCATION='/webdata/', una query PolyBase restituirà righe da mydata.txt e mydata2.txt. Non verrà restituito mydata3.txt perché si trova in una sottocartella di una cartella nascosta. Non restituirà _hidden.txt perché è un file nascosto.
Per modificare il valore predefinito e leggere solo dalla cartella radice, impostare l'attributo <polybase.recursive.traversal> su 'false' nel core-site.xml file di configurazione. Questo file si trova nella <SqlBinRoot>\PolyBase\Hadoop\Conf\bin radice di SQL Server. Ad esempio: C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\.
DATA_SOURCE = external_data_source_name
Specifica il nome dell'origine dati esterna che contiene il percorso dei dati esterni. Questo percorso è hadoop o Archiviazione BLOB di Azure. Per creare un'origine dati esterna, usare CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Specifica il nome dell'oggetto formato file esterno in cui sono archiviati il tipo di file e il metodo di compressione per i dati esterni. Per creare un formato di file esterno, usare CREATE EXTERNAL FILE FORMAT.
Opzioni di rifiuto
Questa opzione può essere usata solo con origini dati esterne in cui TYPE = HADOOP.
È possibile specificare i parametri di rifiuto che determinano in che modo PolyBase gestirà i record dirty che recupera dall'origine dati esterna. Un record di dati è considerato "dirty" se i tipi di dati effettivi o il numero di colonne non corrispondono alle definizioni di colonna della tabella esterna.
Se non si specificano o si modificano i valori di rifiuto, PolyBase usa i valori predefiniti. Queste informazioni sui parametri di rifiuto vengono archiviate come metadati aggiuntivi quando si crea una tabella esterna con l'istruzione CREATE EXTERNAL TABLE. Quando un'istruzione SELECT o SELECT INTO SELECT futura seleziona i dati dalla tabella esterna, PolyBase usa le opzioni di rifiuto per determinare il numero o la percentuale di righe che possono essere rifiutate prima che la query effettiva abbia esito negativo. La query restituirà risultati (parziali) finché non viene superata la soglia di rifiuto, quindi ha esito negativo con il messaggio di errore appropriato.
REJECT_TYPE = value | percentage
Chiarisce se l'opzione REJECT_VALUE è specificata come valore letterale o percentuale.
value
REJECT_VALUE è un valore letterale, non una percentuale. La query PolyBase avrà esito negativo se il numero di righe rifiutate supera reject_value.
Ad esempio, se REJECT_VALUE = 5 e REJECT_TYPE = value, la query SELECT di PolyBase avrà esito negativo dopo che sono state rifiutate cinque righe.
percentuale
REJECT_VALUE è una percentuale, non un valore letterale. La query PolyBase avrà esito negativo se la percentuale di righe non eseguite supera il valore reject_value. La percentuale di righe con esito negativo viene calcolata a intervalli.
REJECT_VALUE = reject_value
Specifica il valore o la percentuale di righe che possono essere rifiutate prima che la query abbia esito negativo.
Per REJECT_TYPE = value, reject_value deve essere un numero intero compreso tra 0 e 2.147.483.647.
Per REJECT_TYPE = percentage, reject_value deve essere un valore float compreso tra 0 e 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Questo attributo è obbligatorio quando si specifica REJECT_TYPE = percentage. Determina il numero di righe che si deve tentare di recuperare prima che PolyBase ricalcoli la percentuale di righe rifiutate.
Il parametro reject_sample_value deve essere un numero intero compreso tra 0 e 2.147.483.647.
Ad esempio, se REJECT_SAMPLE_VALUE = 1000, PolyBase calcola la percentuale di righe con esito negativo dopo che ha tentato di importare 1000 righe dal file di dati esterno. Se la percentuale di righe non riuscite è minore di reject_value, PolyBase tenta di recuperare altre 1.000 righe. Continua a ricalcolare la percentuale di righe non riuscite dopo aver tentato di importare ogni 1.000 righe aggiuntive.
Nota
Poiché PolyBase calcola la percentuale di righe con esito negativo a intervalli, la percentuale effettiva di tali righe può superare reject_value.
Esempio:
Questo esempio illustra come le tre opzioni REJECT interagiscono tra loro. Ad esempio, se REJECT_TYPE = percentage, REJECT_VALUE = 30 e REJECT_SAMPLE_VALUE = 100, potrebbe verificarsi il seguente scenario:
- PolyBase tenta di recuperare le prime 100 righe di cui 25 avranno esito negativo e 75 esito positivo.
- La percentuale di righe con esito negativo viene calcolata come 25%, che è minore del valore di rifiuto pari al 30%. Di conseguenza, PolyBase continuerà a recuperare i dati dall'origine dati esterna.
- PolyBase tenta di caricare le 100 righe successive: questa volta 25 righe hanno esito positivo e 75 righe hanno esito negativo.
- Percentuale di righe con esito negativo viene ricalcolata come 50%. La percentuale di righe con esito negativo ha superato il valore di rifiuto del 30%.
- La query PolyBase ha esito negativo con il 50% di righe rifiutate dopo aver tentato di restituire le prime 200 righe. Si noti che le righe corrispondenti vengono restituite prima che la query PolyBase rilevi che è stata superata la soglia di rifiuto.
Autorizzazioni
Richiede queste autorizzazioni utente:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
- CONTROL DATABASE
Si noti che l'account di accesso che crea l'origine dati esterna deve avere l'autorizzazione per leggere e scrivere nell'origine dati esterna, che si trova in Hadoop o Archiviazione BLOB di Azure.
Importante
L'autorizzazione ALTER ANY EXTERNAL DATA SOURCE concede a qualsiasi entità di sicurezza la possibilità di creare e modificare qualsiasi oggetto origine dati esterna e, di conseguenza, la possibilità di accedere a tutte le credenziali con ambito database nel database. Questa autorizzazione deve essere considerata con privilegi elevati e quindi essere concessa solo a entità attendibili nel sistema.
Gestione degli errori
Durante l'esecuzione dell'istruzione CREATE EXTERNAL TABLE, PolyBase tenta di connettersi all'origine dati esterna. Se il tentativo di connessione non riesce, l'istruzione ha esito negativo e la tabella esterna non viene creata. La conferma dell'esito negativo del comando può richiedere almeno un minuto perché PolyBase ritenta la connessione prima di stabilire che la query non riesce.
Osservazioni:
Negli scenari di query ad hoc, ad esempio SELECT FROM EXTERNAL TABLE, PolyBase archivia le righe recuperate dall'origine dati esterna in una tabella temporanea. Dopo il completamento della query, PolyBase rimuove ed elimina la tabella temporanea. Nessun dato permanente viene archiviato nelle tabelle SQL.
Al contrario, nello scenario di importazione, ad esempio SELECT INTO FROM EXTERNAL TABLE, PolyBase archivia le righe recuperate dall'origine dati esterna come dati permanenti nella tabella SQL. La nuova tabella viene creata durante l'esecuzione della query quando PolyBase recupera i dati esterni.
PolyBase può eseguire il push di parte del calcolo della query in Hadoop per migliorare le prestazioni della query. Questa operazione è chiamata distribuzione del predicato. Per abilitarla, specificare l'opzione del percorso della gestione risorse di Hadoop in CREATE EXTERNAL DATA SOURCE.
È possibile creare numerose tabelle esterne che fanno riferimento alle stesse o ad altre origini dati esterne.
Limitazioni e restrizioni
Poiché non si trovano sotto il controllo di gestione diretto dell'appliance, i dati per una tabella possono essere modificati o rimossi in qualsiasi momento da un processo esterno. Per questo motivo, non si garantisce che i risultati delle query in una tabella esterna siano deterministici. La stessa query può restituire risultati diversi ogni volta che viene eseguita su una tabella esterna. Analogamente, una query può non riuscire se i dati esterni vengono spostati o rimossi.
È possibile creare più tabelle esterne che fanno tutte riferimento a origini dati esterne differenti. Se si eseguono contemporaneamente query in diverse origini dati Hadoop, ogni origine Hadoop deve usare la stessa impostazione di configurazione del server di "connettività Hadoop". Ad esempio, non è possibile eseguire contemporaneamente una query su un cluster Cloudera Hadoop e un cluster Hortonworks Hadoop poiché usano impostazioni di configurazione diverse. Per le impostazioni di configurazione e le combinazioni supportate, vedere Configurazione della connettività di PolyBase.
Solo queste istruzioni Data Definition Language (DDL) sono consentite per le tabelle esterne:
- CREATE TABLE e DROP TABLE
- CREATE STATISTICS e DROP STATISTICS
- CREATE VIEW e DROP VIEW
Costrutti e operazioni non supportati:
- Il vincolo DEFAULT per le colonne di tabelle esterne
- Operazioni di eliminazione, inserimento e aggiornamento di Data Manipulation Language (DML)
- Dynamic Data Masking nelle colonne delle tabelle esterne
Limitazioni delle query
PolyBase può utilizzare al massimo 33.000 file per cartella durante l'esecuzione di 32 query PolyBase simultanee. Questo numero massimo include i file e le sottocartelle presenti in ogni cartella HDFS. Se il livello di concorrenza è inferiore a 32, un utente può eseguire le query PolyBase sulle cartelle in HDFS che contengono più di 33.000 file. È consigliabile usare percorsi brevi per i file esterni e non più di 30.000 file per ogni cartella HDFS. Quando si fa riferimento a troppi file, potrebbe verificarsi un'eccezione di memoria insufficiente in Java Virtual Machine (JVM).
Limitazioni della larghezza della tabella
PolyBase in SQL Server 2016 ha un limite di larghezza di riga di 32 KB, in base alla dimensione massima di una singola riga valida secondo la definizione della tabella. Se la somma dello schema di colonne è maggiore di 32 KB, PolyBase non sarà in grado di eseguire query sui dati.
In Azure Synapse Analytics questa limitazione è stata aumentata a 1 MB.
Limitazioni dei tipi di dati
I tipi di dati seguenti non possono essere usati in tabelle esterne di PolyBase:
- geografiche
- geometry
- hierarchyid
- 'immagine
- testo
- ntext
- xml
- Qualsiasi tipo definito dall'utente
Blocco
Blocco condiviso per l'oggetto SCHEMARESOLUTION.
Sicurezza
I file di dati per una tabella esterna vengono archiviati in Hadoop o Archiviazione BLOB di Azure. Questi file di dati vengono creati e gestiti dai processi dell'utente, che sarà responsabile della gestione della sicurezza dei dati esterni.
Esempi
R. Unire i dati HDFS ai dati della piattaforma di strumenti analitici
SELECT cs.user_ip FROM ClickStream cs
JOIN [User] u ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. Importare i dati delle righe da HDFS in una tabella della piattaforma di strumenti analitici distribuita
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = HASH (url) )
AS SELECT url, event_date, user_ip FROM ClickStream;
C. Importare i dati delle righe da HDFS in una tabella della piattaforma di strumenti analitici replicata
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = REPLICATE )
AS SELECT url, event_date, user_ip
FROM ClickStream;
Passaggi successivi
Altre informazioni sulle tabelle esterne nella piattaforma di strumenti analitici sono disponibili negli articoli seguenti:
* Istanza gestita di SQL di Azure *
Panoramica: Istanza gestita di SQL di Azure
Crea una tabella dati esterna in Istanza gestita di SQL di Azure. Per informazioni complete, vedere Virtualizzazione dei dati con Istanza gestita di SQL di Azure.
La virtualizzazione dei dati in Istanza gestita di SQL di Azure consente l'accesso a dati esterni in un'ampia gamma di formati di file in Azure Data Lake Storage Gen2 o Archiviazione BLOB di Azure e per eseguire query con istruzioni T-SQL, anche combinare dati con dati relazionali archiviati in locale usando join.
Vedere anche CREATE EXTERNAL DATA SOURCE e DROP EXTERNAL TABLE.
Sintassi
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argomenti
{ nome_database.nome_schema.nome_tabella | nome_schema.nome_tabella | nome_tabella }
Nome della tabella da creare, composto da una, due o tre parti. Per una tabella esterna, solo i metadati della tabella insieme alle statistiche di base relative al file o alla cartella a cui si fa riferimento in Azure Data Lake o Archiviazione BLOB di Azure. Quando vengono create tabelle esterne, i dati effettivi non vengono spostati né archiviati.
Importante
Per ottenere prestazioni ottimali, se il driver dell'origine dati esterna supporta un nome in tre parti, è consigliabile specificare il nome in tre parti.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE supporta la possibilità di configurare il nome di colonna, il tipo di dati, il supporto dei valori Null e le regole di confronto. Non è possibile usare DEFAULT CONSTRAINT nelle tabelle esterne.
Le definizioni di colonna, inclusi i tipi di dati e il numero di colonne, devono corrispondere ai dati nei file esterni. In caso di mancata corrispondenza, le righe del file vengono rifiutate quando si eseguono query sui dati effettivi.
LOCATION = 'folder_or_filepath'
Specifica la cartella o il percorso del file e il nome del file per i dati effettivi in Azure Data Lake o Archiviazione BLOB di Azure. Il percorso inizia dalla cartella radice. La cartella radice è la posizione dei dati specificata nell'origine dati esterna.
CREATE EXTERNAL TABLE non crea il percorso e la cartella.
Se si specifica LOCATION come cartella, la query da Istanza gestita di SQL di Azure selezionata dalla tabella esterna recupererà i file dalla cartella ma non da tutte le relative sottocartelle.
Istanza gestita di SQL di Azure non è possibile trovare file in sottocartelle o cartelle nascoste. Inoltre, non restituisce i file il cui nome file inizia con un carattere di sottolineatura (_) o un punto (.).
Nell'esempio di immagine seguente, se LOCATION='/webdata/', una query restituirà righe da mydata.txt. Non verrà restituito mydata2.txt perché si trova in una sottocartella, non verrà restituito mydata3.txt perché si trova in una cartella nascosta e non verrà restituito _hidden.txt perché si tratta di un file nascosto.
DATA_SOURCE = external_data_source_name
Specifica il nome dell'origine dati esterna che contiene il percorso dei dati esterni. Questo percorso è in Azure Data Lake. Per creare un'origine dati esterna, usare CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Specifica il nome dell'oggetto formato file esterno in cui sono archiviati il tipo di file e il metodo di compressione per i dati esterni. Per creare un formato di file esterno, usare CREATE EXTERNAL FILE FORMAT.
Autorizzazioni
Richiede queste autorizzazioni utente:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Nota
Le autorizzazioni CONTROL DATABASE sono necessarie per creare solo MASTER KEY, DATABASE SCOPED CREDENTIAL ed EXTERNAL DATA SOURCE
Si noti che l'account di accesso che crea l'origine dati esterna deve avere l'autorizzazione per leggere e scrivere nell'origine dati esterna, che si trova in Hadoop o Archiviazione BLOB di Azure.
Importante
L'autorizzazione ALTER ANY EXTERNAL DATA SOURCE concede a qualsiasi entità di sicurezza la possibilità di creare e modificare qualsiasi oggetto origine dati esterna e, di conseguenza, la possibilità di accedere a tutte le credenziali con ambito database nel database. Questa autorizzazione deve essere considerata con privilegi elevati e quindi essere concessa solo a entità attendibili nel sistema.
Osservazioni:
Negli scenari di query ad hoc, ad esempio SELECT FROM EXTERNAL TABLE, le righe recuperate dall'origine dati esterna vengono archiviate in una tabella temporanea. Al termine della query, le righe vengono rimosse e la tabella temporanea viene eliminata. Nessun dato permanente viene archiviato nelle tabelle SQL.
Al contrario, nello scenario di importazione, ad esempio SELECT INTO FROM EXTERNAL TABLE, le righe recuperate dall'origine dati esterna vengono archiviate come dati permanenti nella tabella SQL. La nuova tabella viene creata durante l'esecuzione della query quando vengono recuperati i dati esterni.
Attualmente, la virtualizzazione dei dati con Istanza gestita di SQL di Azure è di sola lettura.
È possibile creare numerose tabelle esterne che fanno riferimento alle stesse o ad altre origini dati esterne.
Limitazioni e restrizioni
Poiché i dati per una tabella esterna non sono sotto il controllo diretto della gestione di Istanza gestita di SQL di Azure, possono essere modificati o rimossi in qualsiasi momento da un processo esterno. Per questo motivo, non si garantisce che i risultati delle query in una tabella esterna siano deterministici. La stessa query può restituire risultati diversi ogni volta che viene eseguita su una tabella esterna. Analogamente, una query può non riuscire se i dati esterni vengono spostati o rimossi.
È possibile creare più tabelle esterne che fanno tutte riferimento a origini dati esterne differenti.
Solo queste istruzioni Data Definition Language (DDL) sono consentite per le tabelle esterne:
- CREATE TABLE e DROP TABLE
- CREATE STATISTICS e DROP STATISTICS
- CREATE VIEW e DROP VIEW
Costrutti e operazioni non supportati:
- Il vincolo DEFAULT per le colonne di tabelle esterne
- Operazioni di eliminazione, inserimento e aggiornamento di Data Manipulation Language (DML)
Limitazioni della larghezza della tabella
Il limite di larghezza delle righe di 1 MB si basa sulle dimensioni massime di una singola riga valida per definizione di tabella. Se la somma dello schema di colonna è maggiore di 1 MB, le query di virtualizzazione dei dati avranno esito negativo.
Limitazioni dei tipi di dati
I tipi di dati seguenti non possono essere usati in tabelle esterne in Istanza gestita di SQL di Azure:
- geografiche
- geometry
- hierarchyid
- 'immagine
- testo
- ntext
- xml
- json
- Qualsiasi tipo definito dall'utente
Blocco
Blocco condiviso per l'oggetto SCHEMARESOLUTION.
Esempi
R. Eseguire query sui dati esterni da Istanza gestita di SQL di Azure con una tabella esterna
Per altri esempi, vedere Creare un'origine dati esterna o vedere Virtualizzazione dei dati con Istanza gestita di SQL di Azure.
Creare la chiave master del database, se non esiste.
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Strong Password>' GOCreare le credenziali con ambito database usando un token di firma di accesso condiviso. È anche possibile usare un'identità gestita.
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>' ; --Removing leading '?' GOCreare l'origine dati esterna usando le credenziali.
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] ) GOCreare un EXTERNAL FILE FORMAT e un EXTERNAL TABLE per eseguire query sui dati come se fosse una tabella locale.
-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE=PARQUET ) GO --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides( vendorID VARCHAR(100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR(8000), doLocationId VARCHAR(8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR(8000), paymentType VARCHAR(8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR(8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( LOCATION = 'yellow/puYear=*/puMonth=*/*.parquet', DATA_SOURCE = NYCTaxiExternalDataSource, FILE_FORMAT = MyFileFormat ); GO --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides; GO
Passaggi successivi
Per altre informazioni sulle tabelle esterne e sui concetti correlati, vedere gli articoli seguenti: