Ridimensionamento con KEDA
KEDA (Kubernetes Event-driven Autoscaling)
La scalabilità automatica basata su eventi (KEDA) di Kubernetes è un componente semplice e leggero che semplifica la scalabilità automatica delle applicazioni. È possibile aggiungere KEDA a qualsiasi cluster Kubernetes e usarla insieme a componenti Kubernetes standard, ad esempio Horizontal Pod Autoscaler (HPA) o Cluster Autoscaler, per estendere le funzionalità. Con KEDA, è possibile scegliere come destinazione app specifiche in modo che sfruttino il ridimensionamento basato sugli eventi e consentire ad altre app di usare metodi di ridimensionamento diversi. KEDA è una scelta flessibile e sicura da eseguire insieme a qualsiasi framework o applicazione Kubernetes.
Funzionalità principali
- Creare applicazioni sostenibili e convenienti con funzionalità scalabili a zero
- Ridimensionare i carichi di lavoro dell'applicazione per soddisfare la domanda usando le utilità di scalabilità automatica KEDA
- Ridimensionare automaticamente le applicazioni con
ScaledObjects - Ridimensionare automaticamente i processi con
ScaledJobs - Usare la sicurezza di livello di produzione separando la scalabilità automatica e l'autenticazione dai carichi di lavoro
- Usare la propria utilità di scalabilità automatica esterna per usare configurazioni di scalabilità automatica personalizzate
Architettura
KEDA offre due componenti principali:
- Operatore KEDA: Consente agli utenti finali di ridurre o aumentare i carichi di lavoro da zero a N istanze con supporto per distribuzioni Kubernetes, processi, StatefulSet o qualsiasi risorsa del cliente che definisce una sottorisorsa
/scale. - Server metriche: Espone metriche esterne all'utilità HPA, ad esempio messaggi in un argomento di Kafka o eventi in Hub eventi di Azure, per eseguire azioni di scalabilità automatica. A causa delle limitazioni upstream, il server delle metriche KEDA deve essere l'unico adattatore delle metriche installato nel cluster.
Il diagramma seguente illustra l'integrazione di KEDA con Kubernetes HPA, le origini eventi esterne e il server API di Kubernetes per offrire la funzionalità di ridimensionamento automatico:
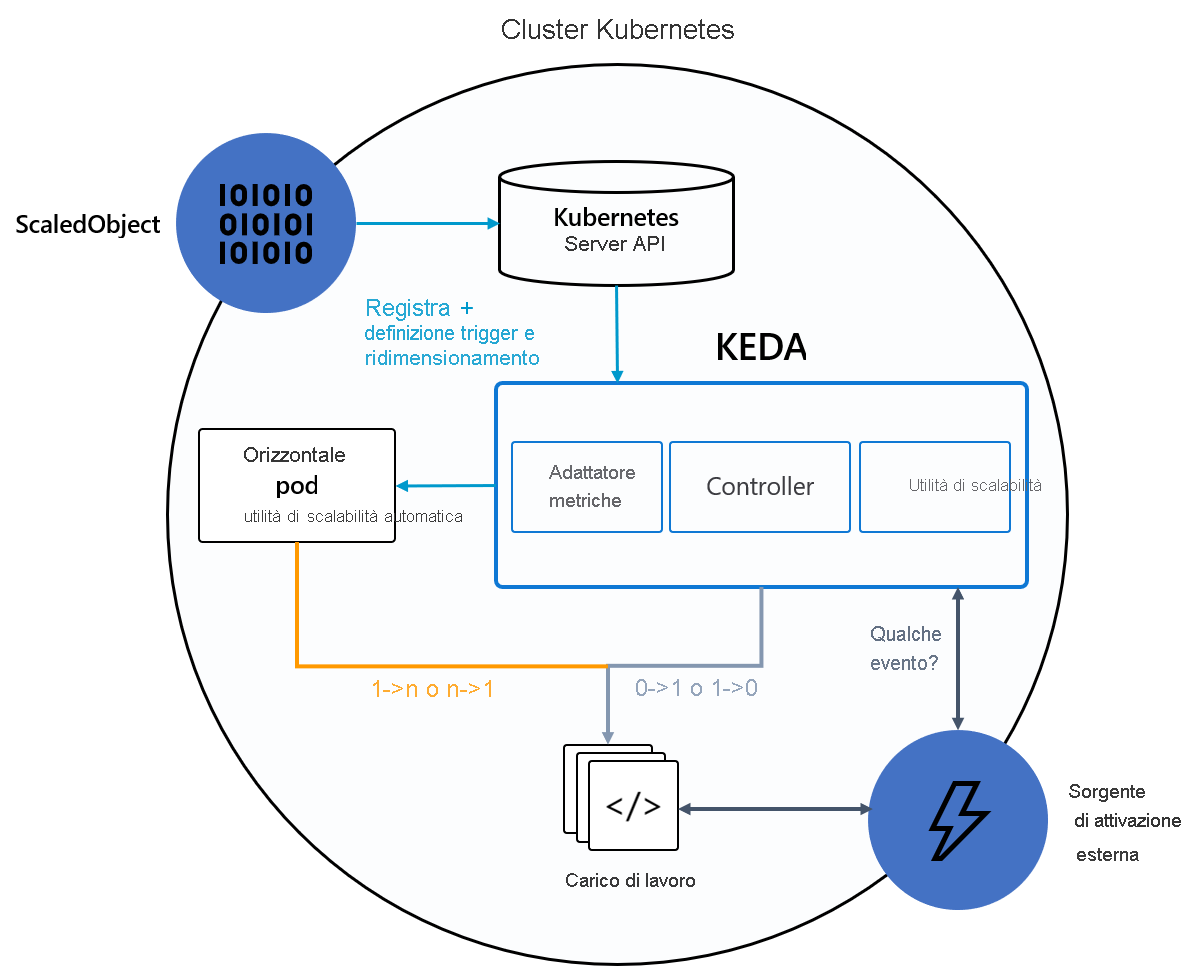
Suggerimento
Per altre informazioni, vedere la documentazione ufficiale di KEDA.
Origini eventi e oggetti scaler
Le utilità di scalabilità automatica KEDA possono rilevare se una distribuzione deve essere attivata o disattivata e fornire metriche personalizzate per un'origine evento specifica. Distribuzioni e set con stato sono il modo più comune per ridimensionare i carichi di lavoro con KEDA. È anche possibile ridimensionare le risorse personalizzate che implementano la sottorisorsa /scale. È possibile definire il set con stato o la distribuzione Kubernetes da ridimensionare in base a un trigger di ridimensionamento. KEDA monitora tali servizi e li ridimensiona automaticamente in base agli eventi che si verificano.
In background, KEDA monitora l'origine eventi e invia i dati a Kubernetes e HPA per favorire il ridimensionamento rapido delle risorse. Ogni replica di una risorsa estrae attivamente elementi dall'origine evento. Con KEDA e Deployments/StatefulSets è possibile eseguire il ridimensionamento in base agli eventi mantenendo al tempo stesso una semantica completa di connessione ed elaborazione con l'origine evento, ad esempio, elaborazione in ordine, tentativi, messaggi non recapitabili o checkpoint.
Specifica dell'oggetto dimensionato
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
Specifica del processo ridimensionato
In alternativa al ridimensionamento del codice basato su eventi come distribuzioni, è possibile eseguire e ridimensionare il codice come processi di Kubernetes. Il motivo principale per prendere in considerazione questa opzione è l'eventuale necessità di elaborare esecuzioni prolungate. Anziché elaborare più eventi all'interno di una distribuzione, ogni evento rilevato pianifica il proprio processo di Kubernetes. Questo approccio consente di elaborare ogni evento in isolamento e ridimensionare il numero di esecuzioni simultanee in base al numero di eventi nella coda.
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}