Risolvere i problemi relativi a una query che mostra una differenza significativa di prestazioni tra due server
Si applica a: SQL Server
Questo articolo illustra i passaggi per la risoluzione dei problemi di prestazioni in cui una query viene eseguita più lentamente in un server rispetto a un altro server.
Sintomi
Si supponga che siano installati due server con SQL Server. Una delle istanze di SQL Server contiene una copia di un database nell'altra istanza di SQL Server. Quando si esegue una query sui database in entrambi i server, la query viene eseguita più lentamente in un server rispetto all'altro.
La procedura seguente consente di risolvere questo problema.
Passaggio 1: Determinare se si tratta di un problema comune con più query
Usare uno dei due metodi seguenti per confrontare le prestazioni per due o più query nei due server:
Testare manualmente le query in entrambi i server:
- Scegliere diverse query per il test con priorità posizionate sulle query che sono:
- Notevolmente più veloce in un server rispetto all'altro.
- Importante per l'utente/applicazione.
- Esecuzione frequente o progettata per riprodurre il problema su richiesta.
- Sufficientemente lungo per acquisire dati su di esso (ad esempio, anziché una query di 5 millisecondi, scegliere una query di 10 secondi).
- Eseguire le query sui due server.
- Confrontare il tempo trascorso (durata) su due server per ogni query.
- Scegliere diverse query per il test con priorità posizionate sulle query che sono:
Analizzare i dati sulle prestazioni con SQL Nexus.
- Raccogliere i dati PSSDiag/SQLdiag o SQL LogScout per le query sui due server.
- Importare i file di dati raccolti con SQL Nexus e confrontare le query dai due server. Per altre informazioni, vedere Confronto delle prestazioni tra due raccolte di log (ad esempio Lento e Veloce).
Scenario 1: solo una singola query viene eseguita in modo diverso nei due server
Se una sola query viene eseguita in modo diverso, è più probabile che il problema sia specifico della singola query anziché dell'ambiente. In questo caso, passare al passaggio 2: Raccogliere dati e determinare il tipo di problema di prestazioni.
Scenario 2: più query vengono eseguite in modo diverso nei due server
Se più query vengono eseguite più lentamente in un server rispetto all'altro, la causa più probabile è la differenza tra server o ambiente dati. Passare a Diagnosticare le differenze di ambiente e verificare se il confronto tra i due server è valido.
Passaggio 2: Raccogliere dati e determinare il tipo di problema di prestazioni
Raccogliere tempo trascorso, tempo CPU e letture logiche
Per raccogliere tempo trascorso e tempo cpu della query su entrambi i server, usare uno dei metodi seguenti che meglio si adattano alla situazione:
Per le istruzioni attualmente in esecuzione, controllare total_elapsed_time e cpu_time colonne in sys.dm_exec_requests. Eseguire la query seguente per ottenere i dati:
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;Per le esecuzioni precedenti della query, controllare last_elapsed_time e last_worker_time colonne in sys.dm_exec_query_stats. Eseguire la query seguente per ottenere i dati:
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCNota
Se
avg_wait_timemostra un valore negativo, si tratta di una query parallela.Se è possibile eseguire la query su richiesta in SQL Server Management Studio (SSMS) o Azure Data Studio, eseguirla con SET STATISTICS TIME
ONe SET STATISTICS IOON.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFFQuindi, dai messaggi verranno visualizzati il tempo cpu, il tempo trascorso e le letture logiche simili alle seguenti:
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.Se è possibile raccogliere un piano di query, controllare i dati dalle proprietà del piano di esecuzione.
Eseguire la query con Includi piano di esecuzione effettivo.
Selezionare l'operatore più a sinistra dal piano di esecuzione.
In Proprietà espandere la proprietà QueryTimeStats.
Controllare ElapsedTime e CpuTime.
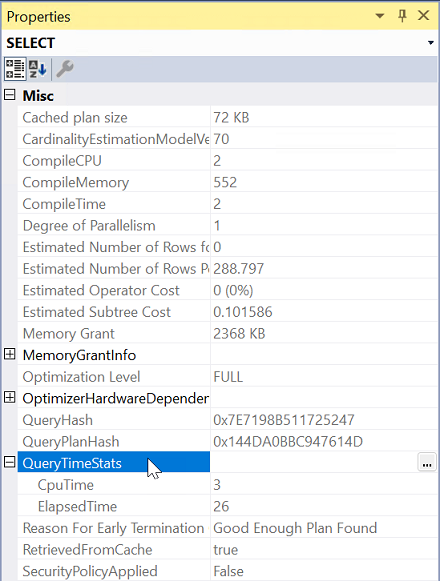
Confrontare il tempo trascorso e il tempo di CPU della query per determinare il tipo di problema per entrambi i server.
Tipo 1: associato alla CPU (runner)
Se il tempo della CPU è vicino, uguale o superiore al tempo trascorso, è possibile considerarlo come una query associata alla CPU. Ad esempio, se il tempo trascorso è di 3000 millisecondi (ms) e il tempo della CPU è 2900 ms, significa che la maggior parte del tempo trascorso viene impiegato sulla CPU. È quindi possibile dire che si tratta di una query associata alla CPU.
Esempi di query con associazione alla CPU:
| Tempo trascorso (ms) | Tempo di CPU (ms) | Letture (logiche) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1000 | 20 |
Letture logiche: lettura di pagine di dati/indici nella cache, sono spesso i driver di utilizzo della CPU in SQL Server. Potrebbero esserci scenari in cui l'uso della CPU proviene da altre origini: un ciclo while (in T-SQL o in altro codice come XProcs o oggetti CRL SQL). Il secondo esempio nella tabella illustra uno scenario di questo tipo, in cui la maggior parte della CPU non proviene dalle letture.
Nota
Se il tempo della CPU è maggiore della durata, indica che viene eseguita una query parallela; più thread usano la CPU contemporaneamente. Per altre informazioni, vedere Query parallele - runner o waiter.
Tipo 2: in attesa di un collo di bottiglia (cameriere)
Una query è in attesa di un collo di bottiglia se il tempo trascorso è significativamente maggiore del tempo della CPU. Il tempo trascorso include il tempo di esecuzione della query sulla CPU (tempo CPU) e il tempo di attesa del rilascio di una risorsa (tempo di attesa). Ad esempio, se il tempo trascorso è 2000 ms e il tempo di CPU è 300 ms, il tempo di attesa è 1700 ms (2000 - 300 = 1700). Per altre informazioni, vedere Tipi di attese.
Esempi di query in attesa:
| Tempo trascorso (ms) | Tempo di CPU (ms) | Letture (logiche) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
Query parallele - Runner o waiter
Le query parallele possono usare più tempo della CPU rispetto alla durata complessiva. L'obiettivo del parallelismo è consentire a più thread di eseguire contemporaneamente parti di una query. In un secondo di tempo, una query può usare otto secondi di tempo della CPU eseguendo otto thread paralleli. Di conseguenza, diventa difficile determinare un limite di CPU o una query in attesa in base al tempo trascorso e alla differenza di tempo della CPU. Tuttavia, come regola generale, seguire i principi elencati nelle due sezioni precedenti. Il riepilogo è:
- Se il tempo trascorso è molto maggiore del tempo della CPU, considerarlo un cameriere.
- Se il tempo della CPU è molto maggiore del tempo trascorso, considerarlo uno strumento di esecuzione.
Esempi di query parallele:
| Tempo trascorso (ms) | Tempo di CPU (ms) | Letture (logiche) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1500000 |
Passaggio 3: Confrontare i dati di entrambi i server, individuare lo scenario e risolvere il problema
Si supponga che siano presenti due computer denominati Server1 e Server2. La query viene eseguita più lentamente su Server1 rispetto a Server2. Confrontare i tempi da entrambi i server e quindi seguire le azioni dello scenario più adatto alle proprie dalle sezioni seguenti.
Scenario 1: la query su Server1 usa più tempo cpu e le letture logiche sono superiori a Server1 rispetto a Server2
Se il tempo della CPU in Server1 è molto maggiore di quello di Server2 e il tempo trascorso corrisponde al tempo di CPU in modo stretto su entrambi i server, non ci sono attese o colli di bottiglia principali. L'aumento del tempo di CPU in Server1 è probabilmente causato da un aumento delle letture logiche. Una modifica significativa nelle letture logiche indica in genere una differenza nei piani di query. Ad esempio:
| Server | Tempo trascorso (ms) | Tempo di CPU (ms) | Letture (logiche) |
|---|---|---|---|
| Server1 | 3100 | 3000 | 300000 |
| Server2 | 1100 | 1000 | 90200 |
Azione: controllare i piani di esecuzione e gli ambienti
- Confrontare i piani di esecuzione della query in entrambi i server. A tale scopo, usare uno dei due metodi seguenti:
- Confrontare visivamente i piani di esecuzione. Per altre informazioni, vedere Visualizzazione di un piano di esecuzione effettivo.
- Salvare i piani di esecuzione e confrontarli usando la funzionalità Confronto piani di SQL Server Management Studio.
- Confrontare gli ambienti. Diversi ambienti possono causare differenze di piano di query o differenze dirette nell'utilizzo della CPU. Gli ambienti includono le versioni del server, le impostazioni di configurazione del database o del server, i flag di traccia, il numero di CPU o la velocità del clock e la macchina virtuale rispetto alla macchina fisica. Per informazioni dettagliate, vedere Diagnosticare le differenze del piano di query.
Scenario 2: La query è un cameriere in Server1 ma non in Server2
Se i tempi di CPU per la query su entrambi i server sono simili, ma il tempo trascorso su Server1 è molto maggiore rispetto a Server2, la query su Server1 impiega molto più tempo in attesa in un collo di bottiglia. Ad esempio:
| Server | Tempo trascorso (ms) | Tempo di CPU (ms) | Letture (logiche) |
|---|---|---|---|
| Server1 | 4500 | 1000 | 90200 |
| Server2 | 1100 | 1000 | 90200 |
- Tempo di attesa su Server1: 4500 - 1000 = 3500 ms
- Tempo di attesa su Server2: 1100 - 1000 = 100 ms
Azione: controllare i tipi di attesa in Server1
Identificare ed eliminare il collo di bottiglia in Server1. Esempi di attese sono blocchi (attese di blocco), attese di latch, attese di I/O del disco, attese di rete e attese di memoria. Per risolvere i problemi comuni relativi ai colli di bottiglia, procedere a Diagnosticare attese o colli di bottiglia.
Scenario 3: le query su entrambi i server sono camerieri, ma i tipi di attesa o i tempi sono diversi
Ad esempio:
| Server | Tempo trascorso (ms) | Tempo di CPU (ms) | Letture (logiche) |
|---|---|---|---|
| Server1 | 8000 | 1000 | 90200 |
| Server2 | 3000 | 1000 | 90200 |
- Tempo di attesa su Server1: 8000 - 1000 = 7000 ms
- Tempo di attesa su Server2: 3000 - 1000 = 2000 ms
In questo caso, i tempi di CPU sono simili in entrambi i server, che indica che i piani di query sono probabilmente uguali. Le query vengono eseguite ugualmente su entrambi i server se non attendono i colli di bottiglia. Quindi le differenze di durata provengono dalle diverse quantità di tempo di attesa. Ad esempio, la query attende i blocchi in Server1 per 7000 ms mentre è in attesa di I/O in Server2 per 2000 ms.
Azione: controllare i tipi di attesa in entrambi i server
Risolvere ogni collo di bottiglia attendere singolarmente in ogni server e velocizzare le esecuzioni in entrambi i server. La risoluzione di questo problema è impegnativa perché è necessario eliminare i colli di bottiglia in entrambi i server e rendere le prestazioni paragonabili. Per risolvere i problemi comuni relativi ai colli di bottiglia, procedere a Diagnosticare attese o colli di bottiglia.
Scenario 4: la query su Server1 usa più tempo cpu rispetto a Server2, ma le letture logiche sono vicine
Ad esempio:
| Server | Tempo trascorso (ms) | Tempo di CPU (ms) | Letture (logiche) |
|---|---|---|---|
| Server1 | 3000 | 3000 | 90200 |
| Server2 | 1000 | 1000 | 90200 |
Se i dati corrispondono alle condizioni seguenti:
- Il tempo della CPU in Server1 è molto maggiore di quello di Server2.
- Il tempo trascorso corrisponde al tempo di CPU strettamente in ogni server, che indica che non è prevista alcuna attesa.
- Le letture logiche, in genere il driver più elevato del tempo cpu, sono simili in entrambi i server.
Il tempo aggiuntivo della CPU deriva quindi da altre attività associate alla CPU. Questo scenario è il più raro di tutti gli scenari.
Cause: traccia, funzioni definite dall'utente e integrazione con CLR
Questo problema può essere causato da:
- Traccia XEvents/SQL Server, in particolare con il filtro sulle colonne di testo (nome del database, nome account di accesso, testo di query e così via). Se la traccia è abilitata in un server ma non in un'altra, questo potrebbe essere il motivo della differenza.
- Funzioni definite dall'utente (UDF) o altro codice T-SQL che esegue operazioni associate alla CPU. Questo potrebbe essere in genere la causa quando altre condizioni sono diverse in Server1 e Server2, ad esempio dimensioni dei dati, velocità dell'orologio della CPU o Risparmio energia.
- Integrazione CLR di SQL Server o stored procedure estese (XP) che possono guidare la CPU, ma non eseguire letture logiche. Le differenze nelle DLL possono causare tempi di CPU diversi.
- Differenza nella funzionalità di SQL Server associata alla CPU (ad esempio, codice di manipolazione delle stringhe).
Azione: controllare tracce e query
Controllare le tracce in entrambi i server per quanto segue:
- Se è presente una traccia abilitata in Server1 ma non in Server2.
- Se una traccia è abilitata, disabilitare la traccia ed eseguire di nuovo la query in Server1.
- Se la query viene eseguita più velocemente questa volta, abilitare la traccia indietro ma rimuovere i filtri di testo da esso, se presenti.
Controllare se la query usa funzioni definite dall'utente che eseguono modifiche alle stringhe o eseguono un'elaborazione estesa sulle colonne di dati nell'elenco
SELECT.Controllare se la query contiene cicli, ricorsioni di funzione o annidazioni.
Diagnosticare le differenze di ambiente
Controllare le domande seguenti e determinare se il confronto tra i due server è valido.
Le due istanze di SQL Server sono la stessa versione o build?
In caso contrario, potrebbero esserci alcune correzioni che hanno causato le differenze. Eseguire la query seguente per ottenere informazioni sulla versione in entrambi i server:
SELECT @@VERSIONLa quantità di memoria fisica è simile in entrambi i server?
Se un server ha 64 GB di memoria mentre l'altro ha 256 GB di memoria, questa sarebbe una differenza significativa. Con più memoria disponibile per memorizzare nella cache le pagine di dati/indici e i piani di query, la query potrebbe essere ottimizzata in modo diverso in base alla disponibilità delle risorse hardware.
Le configurazioni hardware correlate alla CPU sono simili in entrambi i server? Ad esempio:
Il numero di CPU varia tra computer (24 CPU in un computer rispetto a 96 CPU nell'altro).
Combinazioni per il risparmio di energia, bilanciate e prestazioni elevate.
Macchina virtuale (VM) e computer fisico (bare metal).
Hyper-V e VMware: differenza nella configurazione.
Differenza di velocità dell'orologio (velocità di clock inferiore rispetto alla velocità di clock più elevata). Ad esempio, 2 GHz rispetto a 3,5 GHz possono fare la differenza. Per ottenere la velocità dell'orologio in un server, eseguire il comando di PowerShell seguente:
Get-CimInstance Win32_Processor | Select-Object -Expand MaxClockSpeed
Usare uno dei due modi seguenti per testare la velocità della CPU dei server. Se non producono risultati confrontabili, il problema è esterno a SQL Server. Potrebbe trattarsi di una differenza di risparmio energia, meno CPU, problemi software delle macchine virtuali o differenza di velocità del clock.
Eseguire lo script di PowerShell seguente in entrambi i server e confrontare gli output.
$bf = [System.DateTime]::Now for ($i = 0; $i -le 20000000; $i++) {} $af = [System.DateTime]::Now Write-Host ($af - $bf).Milliseconds " milliseconds" Write-Host ($af - $bf).Seconds " Seconds"Eseguire il codice Transact-SQL seguente in entrambi i server e confrontare gli output.
SET NOCOUNT ON DECLARE @spins INT = 0 DECLARE @start_time DATETIME = GETDATE(), @time_millisecond INT WHILE (@spins < 20000000) BEGIN SET @spins = @spins +1 END SELECT @time_millisecond = DATEDIFF(millisecond, @start_time, getdate()) SELECT @spins Spins, @time_millisecond Time_ms, @spins / @time_millisecond Spins_Per_ms
Diagnosticare attese o colli di bottiglia
Per ottimizzare una query in attesa di colli di bottiglia, identificare il tempo di attesa e il collo di bottiglia (il tipo di attesa). Una volta confermato il tipo di attesa, ridurre il tempo di attesa o eliminare completamente l'attesa.
Per calcolare il tempo di attesa approssimativo, sottrarre il tempo cpu (tempo di lavoro) dal tempo trascorso di una query. In genere, il tempo di CPU è il tempo di esecuzione effettivo e la parte rimanente della durata della query è in attesa.
Esempi di come calcolare la durata approssimativa dell'attesa:
| Tempo trascorso (ms) | Tempo di CPU (ms) | Tempo di attesa (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
Identificare il collo di bottiglia o l'attesa
Per identificare le query cronologiche in attesa prolungata (ad esempio, >il 20% del tempo di attesa complessivo è il tempo di attesa), eseguire la query seguente. Questa query usa le statistiche sulle prestazioni per i piani di query memorizzati nella cache dall'inizio di SQL Server.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCPer identificare le query attualmente in esecuzione con attese superiori a 500 ms, eseguire la query seguente:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Se è possibile raccogliere un piano di query, controllare WaitStats dalle proprietà del piano di esecuzione in SSMS:
- Eseguire la query con Includi piano di esecuzione effettivo.
- Fare clic con il pulsante destro del mouse sull'operatore più a sinistra nella scheda Piano di esecuzione
- Selezionare Proprietà e quindi proprietà WaitStats .
- Controllare WaitTimeMs e WaitType.
Se si ha familiarità con gli scenari PSSDiag/SQLdiag o SQL LogScout LightPerf/GeneralPerf, è consigliabile usarli per raccogliere statistiche sulle prestazioni e identificare le query in attesa nell'istanza di SQL Server. È possibile importare i file di dati raccolti e analizzare i dati sulle prestazioni con SQL Nexus.
Riferimenti per eliminare o ridurre le attese
Le cause e le risoluzioni per ogni tipo di attesa variano. Non esiste un metodo generale per risolvere tutti i tipi di attesa. Ecco alcuni articoli per risolvere i problemi comuni relativi al tipo di attesa:
- Comprendere e risolvere i problemi di blocco (LCK_M_*)
- Comprendere e risolvere i problemi di blocco di Database SQL di Azure
- Risolvere i problemi di rallentamento delle prestazioni di SQL Server causati da problemi di I/O (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- Risolvere i conflitti di inserimento dell'ultima pagina PAGELATCH_EX in SQL Server
- Spiegazioni e soluzioni delle concessioni di memoria (RESOURCE_SEMAPHORE)
- Risolvere i problemi relativi alle query lente risultanti da ASYNC_NETWORK_IO tipo di attesa
- Risoluzione dei problemi relativi al tipo di attesa HADR_SYNC_COMMIT elevato con i gruppi di disponibilità AlwaysOn
- Funzionamento: CMEMTHREAD e debug
- Rendere possibile l'attesa del parallelismo (CXPACKET e CXCONSUMER)
- Attesa THREADPOOL
Per le descrizioni di molti tipi di attesa e di ciò che indicano, vedere la tabella in Tipi di attese.
Diagnosticare le differenze del piano di query
Ecco alcune cause comuni per le differenze nei piani di query:
Differenze tra le dimensioni dei dati o i valori dei dati
Lo stesso database viene usato in entrambi i server, usando lo stesso backup del database? I dati sono stati modificati in un server rispetto all'altro? Le differenze tra i dati possono causare piani di query diversi. Ad esempio, il join della tabella T1 (1000 righe) con la tabella T2 (2.000.000 righe) è diverso dal join della tabella T1 (100 righe) con la tabella T2 (2.000.000 righe). Il tipo e la velocità dell'operazione
JOINpossono essere notevolmente diversi.Differenze tra statistiche
Le statistiche sono state aggiornate su un database e non su un altro? Le statistiche sono state aggiornate con una frequenza di campionamento diversa (ad esempio, il 30% rispetto all'analisi completa del 100%)? Assicurarsi di aggiornare le statistiche su entrambi i lati con la stessa frequenza di campionamento.
Differenze del livello di compatibilità del database
Controllare se i livelli di compatibilità dei database sono diversi tra i due server. Per ottenere il livello di compatibilità del database, eseguire la query seguente:
SELECT name, compatibility_level FROM sys.databases WHERE name = '<YourDatabase>'Differenze di versione/compilazione del server
Le versioni o le build di SQL Server sono diverse tra i due server? Ad esempio, è un server SQL Server versione 2014 e l'altra di SQL Server versione 2016? Potrebbero essere presenti modifiche al prodotto che possono causare modifiche alla modalità di selezione di un piano di query. Assicurarsi di confrontare la stessa versione e la stessa build di SQL Server.
SELECT ServerProperty('ProductVersion')Differenze di versione di Cardinalità Estimator (CE)
Controllare se lo strumento di stima della cardinalità legacy è attivato a livello di database. Per altre informazioni su CE, vedere Stima della cardinalità (SQL Server).
SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'LEGACY_CARDINALITY_ESTIMATION'Hotfix di Optimizer abilitati/disabilitati
Se gli hotfix di Query Optimizer sono abilitati in un server ma disabilitati nell'altro, è possibile generare piani di query diversi. Per altre informazioni, vedere Sql Server Query Optimizer hotfix trace flag 4199 servicing model .For more information, see SQL Server Query Optimizer hotfix trace flag 4199 servicing model.
Per ottenere lo stato degli hotfix di Query Optimizer, eseguire la query seguente:
-- Check at server level for TF 4199 DBCC TRACESTATUS (-1) -- Check at database level USE <YourDatabase> SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'QUERY_OPTIMIZER_HOTFIXES'Differenze tra flag di traccia
Alcuni flag di traccia influiscono sulla selezione del piano di query. Controllare se sono presenti flag di traccia abilitati in un server che non sono abilitati nell'altro. Eseguire la query seguente su entrambi i server e confrontare i risultati:
-- Check at server level for trace flags DBCC TRACESTATUS (-1)Differenze hardware (numero di CPU, dimensioni della memoria)
Per ottenere le informazioni sull'hardware, eseguire la query seguente:
SELECT cpu_count, physical_memory_kb/1024/1024 PhysicalMemory_GB FROM sys.dm_os_sys_infoDifferenze hardware in base a Query Optimizer
Controllare l'oggetto
OptimizerHardwareDependentPropertiesdi un piano di query e verificare se le differenze hardware sono considerate significative per piani diversi.WITH xmlnamespaces(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan') SELECT txt.text, t.OptHardw.value('@EstimatedAvailableMemoryGrant', 'INT') AS EstimatedAvailableMemoryGrant , t.OptHardw.value('@EstimatedPagesCached', 'INT') AS EstimatedPagesCached, t.OptHardw.value('@EstimatedAvailableDegreeOfParallelism', 'INT') AS EstimatedAvailDegreeOfParallelism, t.OptHardw.value('@MaxCompileMemory', 'INT') AS MaxCompileMemory FROM sys.dm_exec_cached_plans AS cp CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp CROSS APPLY qp.query_plan.nodes('//OptimizerHardwareDependentProperties') AS t(OptHardw) CROSS APPLY sys.dm_exec_sql_text (CP.plan_handle) txt WHERE text Like '%<Part of Your Query>%'Timeout di Optimizer
Si è verificato un problema di timeout dell'utilità di ottimizzazione? Query Optimizer può interrompere la valutazione delle opzioni di piano se la query eseguita è troppo complessa. Quando si arresta, seleziona il piano con il costo più basso disponibile al momento. Questo può portare a ciò che sembra una scelta arbitraria di piano in un server rispetto a un altro.
Opzioni SET
Alcune opzioni SET influiscono sul piano, ad esempio SET ARITHABORT. Per altre informazioni, vedere Opzioni SET.
Differenze tra hint per le query
Una query usa hint per la query e l'altra no? Controllare manualmente il testo della query per stabilire la presenza di hint per la query.
Piani sensibili ai parametri (problema di analisi dei parametri)
Si esegue il test della query con gli stessi valori dei parametri? In caso contrario, è possibile iniziare lì. Il piano è stato compilato in precedenza in un server in base a un valore di parametro diverso? Testare le due query usando l'hint per la query RECOMPILE per assicurarsi che non venga eseguito alcun riutilizzo del piano. Per altre informazioni, vedere Analizzare e risolvere i problemi relativi ai parametri.
Opzioni di database diverse/impostazioni di configurazione con ambito
Le stesse opzioni di database o le stesse impostazioni di configurazione con ambito vengono usate in entrambi i server? Alcune opzioni di database possono influire sulle scelte di piano. Ad esempio, compatibilità del database, ce legacy rispetto all'analisi dei parametri predefinita e analisi dei parametri. Eseguire la query seguente da un server per confrontare le opzioni di database usate nei due server:
-- On Server1 add a linked server to Server2 EXEC master.dbo.sp_addlinkedserver @server = N'Server2', @srvproduct=N'SQL Server' -- Run a join between the two servers to compare settings side by side SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value_in_use AS srv1_value_in_use, s2.value_in_use AS srv2_value_in_use, Variance = CASE WHEN ISNULL(s1.value_in_use, '##') != ISNULL(s2.value_in_use,'##') THEN 'Different' ELSE '' END FROM sys.configurations s1 FULL OUTER JOIN [server2].master.sys.configurations s2 ON s1.name = s2.name SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value srv1_value_in_use, s2.value srv2_value_in_use, s1.is_value_default, s2.is_value_default, Variance = CASE WHEN ISNULL(s1.value, '##') != ISNULL(s2.value, '##') THEN 'Different' ELSE '' END FROM sys.database_scoped_configurations s1 FULL OUTER JOIN [server2].master.sys.database_scoped_configurations s2 ON s1.name = s2.nameGuide di piano
Le guide di piano vengono usate per le query in un server ma non nell'altro? Eseguire la query seguente per stabilire le differenze:
SELECT * FROM sys.plan_guides