Creazione di script con PowerShell e cronologia delle prestazioni di Spazi di archiviazione diretta
In Windows Server 2019, Spazi di archiviazione diretta registra e archivia un'ampia cronologia delle prestazioni per macchine virtuali, server, unità, volumi, schede di rete e altro ancora. In PowerShell è facile elaborare ed eseguire query sulla cronologia delle prestazioni in modo da poter passare rapidamente da dati non elaborati a risposte effettive a domande come:
- Ci sono stati picchi di CPU la scorsa settimana?
- Un disco fisico presenta una latenza anomala?
- Quali macchine virtuali utilizzano attualmente la maggior parte delle operazioni di I/O al secondo di archiviazione?
- La larghezza di banda di rete è satura?
- Quando finirà lo spazio libero di questo volume?
- Nell'ultimo mese, quali macchine virtuali hanno usato più memoria?
Il cmdlet Get-ClusterPerf è stato creato per la creazione di script. Accetta input da cmdlet come Get-VM o Get-PhysicalDisk dalla pipeline per gestire l'associazione ed è possibile inviare tramite pipe il relativo output in cmdlet di utilità come Sort-Object, Where-Object e Measure-Object per comporre rapidamente query avanzate.
Questo argomento fornisce e illustra 6 script di esempio che rispondono alle 6 domande precedenti. Presentano criteri che è possibile applicare per trovare picchi, trovare medie, tracciare linee di tendenza, eseguire il rilevamento degli outlier e altro ancora, in un'ampia gamma di dati e intervalli di tempo. Vengono forniti come codice iniziale gratuito da copiare, estendere e riutilizzare.
Nota
Per brevità, gli script di esempio omettono aspetti come la gestione degli errori che ci si potrebbe aspettare da un codice PowerShell di alta qualità. Sono destinati principalmente all'ispirazione e all'istruzione piuttosto che all'uso in produzione.
Esempio 1: CPU, ti vedo!
Questo esempio usa la serie ClusterNode.Cpu.Usage dell'intervallo di tempo LastWeek per mostrare l'utilizzo massimo ("limite massimo"), minimo e medio della CPU per ogni server del cluster. Esegue anche una semplice analisi dei quartili per mostrare per quante ore l'utilizzo della CPU è stato superiore al 25%, 50% e 75% negli ultimi 8 giorni.
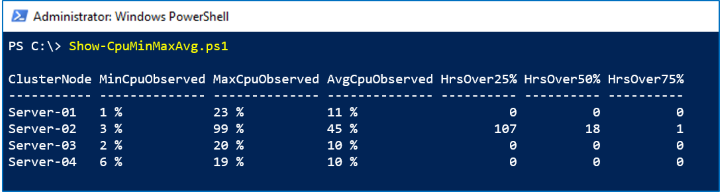
Schermata acquisita
Nello screenshot seguente, si nota che Server-02 ha avuto un picco inspiegabile la scorsa settimana:
Funzionamento
L'output di Get-ClusterPerf viene inviato tramite pipe al cmdlet predefinito Measure-Object; è necessario specificare solo la proprietà Value. Con i flag -Maximum, -Minimum e -Average, Measure-Object fornisce le prime tre colonne quasi gratuitamente. Per eseguire l'analisi dei quartili, è possibile inviare tramite pipe il risultato a Where-Object e contare quanti valori erano -Gt (maggiori di) 25, 50 o 75. L'ultimo passaggio consiste nell'aggiungere le funzioni di supporto Format-Hours e Format-Percent, sicuramente facoltative.
Script
Ecco lo script:
Function Format-Hours {
Param (
$RawValue
)
# Weekly timeframe has frequency 15 minutes = 4 points per hour
[Math]::Round($RawValue/4)
}
Function Format-Percent {
Param (
$RawValue
)
[String][Math]::Round($RawValue) + " " + "%"
}
$Output = Get-ClusterNode | ForEach-Object {
$Data = $_ | Get-ClusterPerf -ClusterNodeSeriesName "ClusterNode.Cpu.Usage" -TimeFrame "LastWeek"
$Measure = $Data | Measure-Object -Property Value -Minimum -Maximum -Average
$Min = $Measure.Minimum
$Max = $Measure.Maximum
$Avg = $Measure.Average
[PsCustomObject]@{
"ClusterNode" = $_.Name
"MinCpuObserved" = Format-Percent $Min
"MaxCpuObserved" = Format-Percent $Max
"AvgCpuObserved" = Format-Percent $Avg
"HrsOver25%" = Format-Hours ($Data | Where-Object Value -Gt 25).Length
"HrsOver50%" = Format-Hours ($Data | Where-Object Value -Gt 50).Length
"HrsOver75%" = Format-Hours ($Data | Where-Object Value -Gt 75).Length
}
}
$Output | Sort-Object ClusterNode | Format-Table
Esempio 2: Pericolo, pericolo, outlier di latenza
Questo esempio usa la serie PhysicalDisk.Latency.Average dell'intervallo di tempo LastHour per cercare gli outlier statistici, definiti come unità con una latenza media oraria superiore a +3σ (tre deviazioni standard) rispetto alla media della popolazione.
Importante
Per brevità, questo script non implementa misure di sicurezza contro la varianza bassa, non gestisce dati parziali mancanti, non distingue per modello o firmware e così via. È consigliabile valutare bene la situazione e non fare affidamento solo su questo script per determinare se sostituire un disco rigido. Questo script viene illustrato qui solo a scopo didattico.
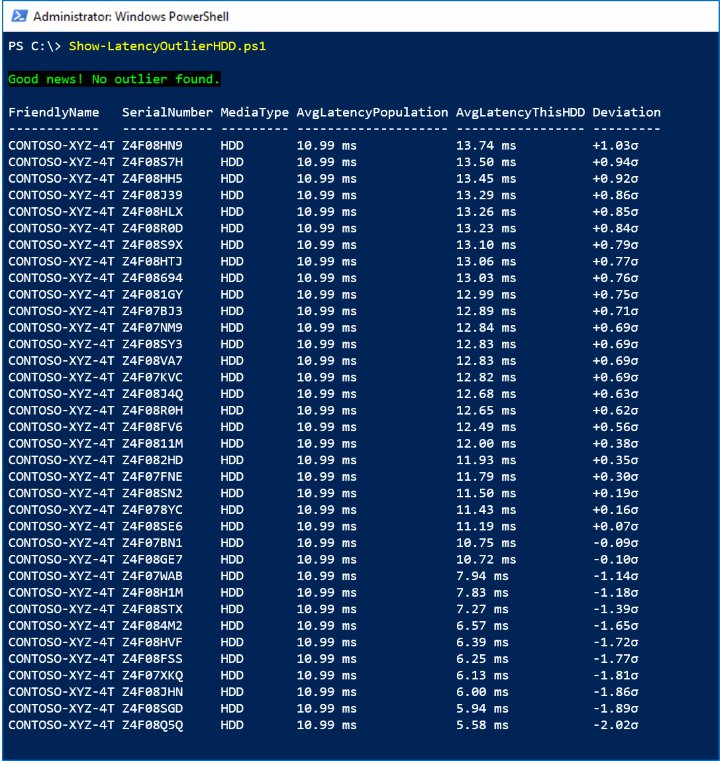
Schermata acquisita
Nello screenshot seguente non sono presenti outlier:
Funzionamento
Prima di tutto, vengono escluse le unità inattive o quasi inattive controllando che PhysicalDisk.Iops.Total sia sempre -Gt 1. Per ogni unità HDD attivo, si invia tramite pipe il relativo intervallo di tempo LastHour, costituito da 360 misurazioni a intervalli di 10 secondi, a Measure-Object -Average per ottenere la latenza media nell'ultima ora. In questo modo si configura una popolazione.
Viene implementata la formula ampiamente nota per trovare la media μ e la deviazione standard σ della popolazione. Per ogni unità HDD attiva, si confronta la latenza media con la media della popolazione e la si divide per la deviazione standard. Si mantengono i valori non elaborati in modo da poter applicare Sort-Object ai risultati e si aggiungono le funzioni di supporto Format-Latency e Format-StandardDeviation, sicuramente facoltative.
Se un'unità è superiore a +3σ, Write-Host viene visualizzato in rosso; in caso contrario, in verde.
Script
Ecco lo script:
Function Format-Latency {
Param (
$RawValue
)
$i = 0 ; $Labels = ("s", "ms", "μs", "ns") # Petabits, just in case!
Do { $RawValue *= 1000 ; $i++ } While ( $RawValue -Lt 1 )
# Return
[String][Math]::Round($RawValue, 2) + " " + $Labels[$i]
}
Function Format-StandardDeviation {
Param (
$RawValue
)
If ($RawValue -Gt 0) {
$Sign = "+"
}
Else {
$Sign = "-"
}
# Return
$Sign + [String][Math]::Round([Math]::Abs($RawValue), 2) + "σ"
}
$HDD = Get-StorageSubSystem Cluster* | Get-PhysicalDisk | Where-Object MediaType -Eq HDD
$Output = $HDD | ForEach-Object {
$Iops = $_ | Get-ClusterPerf -PhysicalDiskSeriesName "PhysicalDisk.Iops.Total" -TimeFrame "LastHour"
$AvgIops = ($Iops | Measure-Object -Property Value -Average).Average
If ($AvgIops -Gt 1) { # Exclude idle or nearly idle drives
$Latency = $_ | Get-ClusterPerf -PhysicalDiskSeriesName "PhysicalDisk.Latency.Average" -TimeFrame "LastHour"
$AvgLatency = ($Latency | Measure-Object -Property Value -Average).Average
[PsCustomObject]@{
"FriendlyName" = $_.FriendlyName
"SerialNumber" = $_.SerialNumber
"MediaType" = $_.MediaType
"AvgLatencyPopulation" = $null # Set below
"AvgLatencyThisHDD" = Format-Latency $AvgLatency
"RawAvgLatencyThisHDD" = $AvgLatency
"Deviation" = $null # Set below
"RawDeviation" = $null # Set below
}
}
}
If ($Output.Length -Ge 3) { # Minimum population requirement
# Find mean μ and standard deviation σ
$μ = ($Output | Measure-Object -Property RawAvgLatencyThisHDD -Average).Average
$d = $Output | ForEach-Object { ($_.RawAvgLatencyThisHDD - $μ) * ($_.RawAvgLatencyThisHDD - $μ) }
$σ = [Math]::Sqrt(($d | Measure-Object -Sum).Sum / $Output.Length)
$FoundOutlier = $False
$Output | ForEach-Object {
$Deviation = ($_.RawAvgLatencyThisHDD - $μ) / $σ
$_.AvgLatencyPopulation = Format-Latency $μ
$_.Deviation = Format-StandardDeviation $Deviation
$_.RawDeviation = $Deviation
# If distribution is Normal, expect >99% within 3σ
If ($Deviation -Gt 3) {
$FoundOutlier = $True
}
}
If ($FoundOutlier) {
Write-Host -BackgroundColor Black -ForegroundColor Red "Oh no! There's an HDD significantly slower than the others."
}
Else {
Write-Host -BackgroundColor Black -ForegroundColor Green "Good news! No outlier found."
}
$Output | Sort-Object RawDeviation -Descending | Format-Table FriendlyName, SerialNumber, MediaType, AvgLatencyPopulation, AvgLatencyThisHDD, Deviation
}
Else {
Write-Warning "There aren't enough active drives to look for outliers right now."
}
Esempio 3: Vicino rumoroso? Questo è scrivere!
La cronologia delle prestazioni può rispondere anche a domande immediate. Le nuove misurazioni sono disponibili in tempo reale, ogni 10 secondi. In questo esempio viene usata la serie VHD.Iops.Total dell'intervallo di tempo MostRecent per identificare le macchine virtuali più usate (qualcuno potrebbe dire "più rumorose") che utilizzano la maggior parte delle operazioni di I/O al secondo di archiviazione in tutti gli host del cluster e viene visualizzata la suddivisione in lettura/scrittura della relativa attività.
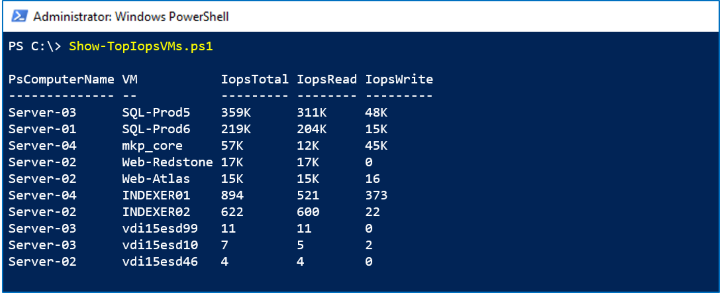
Schermata acquisita
Nello screenshot seguente vengono visualizzate le prime 10 macchine virtuali per attività di archiviazione:
Funzionamento
A differenza di Get-PhysicalDisk, il cmdlet Get-VM non è compatibile con il cluster e restituisce solo le macchine virtuali nel server locale. Per eseguire query da tutti i server in parallelo, si esegue il wrapping della chiamata in Invoke-Command (Get-ClusterNode).Name { ... }. Per ogni macchina virtuale, si ottengono le misurazioni VHD.Iops.Total, VHD.Iops.Read e VHD.Iops.Write. Non specificando il parametro -TimeFrame, si ottiene il singolo punto di dati MostRecent per ogni macchina virtuale.
Suggerimento
Queste serie riflettono la somma dell'attività della macchina virtuale in tutti i relativi file VHD/VHDX. Questo è un esempio in cui la cronologia delle prestazioni viene aggregata automaticamente. Per ottenere la suddivisione per VHD/VHDX, è possibile inviare tramite pipe un singolo Get-VHD in Get-ClusterPerf invece della macchina virtuale.
I risultati di ogni server vengono combinati come $Output, che è possibile Sort-Object e quindi Select-Object -First 10. Si noti che Invoke-Command perfeziona i risultati con una proprietà PsComputerName che indica la provenienza, che possiamo stampare per sapere dove è in esecuzione la macchina virtuale.
Script
Ecco lo script:
$Output = Invoke-Command (Get-ClusterNode).Name {
Function Format-Iops {
Param (
$RawValue
)
$i = 0 ; $Labels = (" ", "K", "M", "B", "T") # Thousands, millions, billions, trillions...
Do { if($RawValue -Gt 1000){$RawValue /= 1000 ; $i++ } } While ( $RawValue -Gt 1000 )
# Return
[String][Math]::Round($RawValue) + " " + $Labels[$i]
}
Get-VM | ForEach-Object {
$IopsTotal = $_ | Get-ClusterPerf -VMSeriesName "VHD.Iops.Total"
$IopsRead = $_ | Get-ClusterPerf -VMSeriesName "VHD.Iops.Read"
$IopsWrite = $_ | Get-ClusterPerf -VMSeriesName "VHD.Iops.Write"
[PsCustomObject]@{
"VM" = $_.Name
"IopsTotal" = Format-Iops $IopsTotal.Value
"IopsRead" = Format-Iops $IopsRead.Value
"IopsWrite" = Format-Iops $IopsWrite.Value
"RawIopsTotal" = $IopsTotal.Value # For sorting...
}
}
}
$Output | Sort-Object RawIopsTotal -Descending | Select-Object -First 10 | Format-Table PsComputerName, VM, IopsTotal, IopsRead, IopsWrite
Esempio 4: Come si dice, "25-gig è il nuovo 10-gig"
Questo esempio usa la serie NetAdapter.Bandwidth.Total dell'intervallo di tempo LastDay per cercare segni di saturazione della rete, definita come >90% della larghezza di banda massima teorica. Per ogni scheda di rete nel cluster, confronta l'utilizzo massimo della larghezza di banda osservato nell'ultimo giorno con la velocità di collegamento dichiarata.
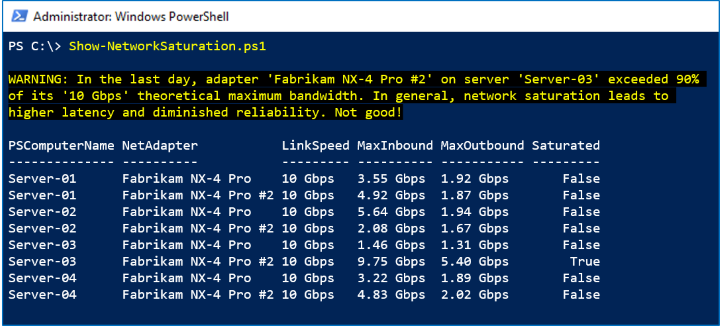
Schermata acquisita
Nello screenshot seguente si può notare che un Fabrikam NX-4 Pro #2 ha raggiunto il picco nell'ultimo giorno:
Funzionamento
Si ripete Invoke-Command illustrato sopra per Get-NetAdapter in ogni server e si invia il risultato tramite pipe a Get-ClusterPerf. Durante la procedura vengono usate due proprietà rilevanti: la stringa LinkSpeed come "10 Gbps" e il relativo intero Speed non elaborato come 10000000000. Si usa Measure-Object per ottenere la media e il picco dall'ultimo giorno (si ricorda che ogni misura nell'intervallo di tempo LastDay rappresenta 5 minuti) e si moltiplica per 8 bit per byte per ottenere un confronto alla pari.
Nota
Alcuni fornitori, come Chelsio, includono l'attività di accesso diretto alla memoria remota (RDMA) nei contatori delle prestazioni della Scheda di rete, quindi è inclusa nella serie NetAdapter.Bandwidth.Total. Altri, come Mellanox, potrebbero non farlo. Se il fornitore non lo fa, è sufficiente aggiungere la serie NetAdapter.Bandwidth.RDMA.Total nella versione di questo script.
Script
Ecco lo script:
$Output = Invoke-Command (Get-ClusterNode).Name {
Function Format-BitsPerSec {
Param (
$RawValue
)
$i = 0 ; $Labels = ("bps", "kbps", "Mbps", "Gbps", "Tbps", "Pbps") # Petabits, just in case!
Do { $RawValue /= 1000 ; $i++ } While ( $RawValue -Gt 1000 )
# Return
[String][Math]::Round($RawValue) + " " + $Labels[$i]
}
Get-NetAdapter | ForEach-Object {
$Inbound = $_ | Get-ClusterPerf -NetAdapterSeriesName "NetAdapter.Bandwidth.Inbound" -TimeFrame "LastDay"
$Outbound = $_ | Get-ClusterPerf -NetAdapterSeriesName "NetAdapter.Bandwidth.Outbound" -TimeFrame "LastDay"
If ($Inbound -Or $Outbound) {
$InterfaceDescription = $_.InterfaceDescription
$LinkSpeed = $_.LinkSpeed
$MeasureInbound = $Inbound | Measure-Object -Property Value -Maximum
$MaxInbound = $MeasureInbound.Maximum * 8 # Multiply to bits/sec
$MeasureOutbound = $Outbound | Measure-Object -Property Value -Maximum
$MaxOutbound = $MeasureOutbound.Maximum * 8 # Multiply to bits/sec
$Saturated = $False
# Speed property is Int, e.g. 10000000000
If (($MaxInbound -Gt (0.90 * $_.Speed)) -Or ($MaxOutbound -Gt (0.90 * $_.Speed))) {
$Saturated = $True
Write-Warning "In the last day, adapter '$InterfaceDescription' on server '$Env:ComputerName' exceeded 90% of its '$LinkSpeed' theoretical maximum bandwidth. In general, network saturation leads to higher latency and diminished reliability. Not good!"
}
[PsCustomObject]@{
"NetAdapter" = $InterfaceDescription
"LinkSpeed" = $LinkSpeed
"MaxInbound" = Format-BitsPerSec $MaxInbound
"MaxOutbound" = Format-BitsPerSec $MaxOutbound
"Saturated" = $Saturated
}
}
}
}
$Output | Sort-Object PsComputerName, InterfaceDescription | Format-Table PsComputerName, NetAdapter, LinkSpeed, MaxInbound, MaxOutbound, Saturated
Esempio 5: Rendi l'archiviazione di nuovo alla moda!
Per esaminare le macrotendenze, la cronologia delle prestazioni viene mantenuta per un massimo di 1 anno. In questo esempio viene usata la serie Volume.Size.Available dell'intervallo di tempo LastYear per determinare la velocità con cui lo spazio di archiviazione si sta riempiendo e stimare quando sarà pieno.
Schermata acquisita
Nello screenshot seguente si nota che il volume Backup aggiunge circa 15 GB al giorno:
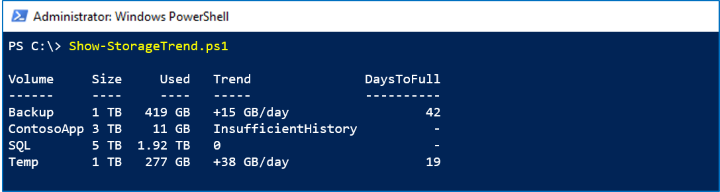
Con questa velocità raggiungerà la propria capacità tra altri 42 giorni.
Funzionamento
L'intervallo di tempo LastYear ha un punto dati al giorno. Sebbene siano strettamente necessari solo due punti per adattarsi a una linea di tendenza, in pratica è meglio richiederne di più, come 14 giorni. Viene usato Select-Object -Last 14 per configurare una matrice di (x, y) punti, per x nell'intervallo [1, 14]. Con questi punti, viene implementato il semplice algoritmo dei minimi quadrati lineari per trovare $A e $B che parametrizzano la retta di migliore adattamento y = ax + b. Bentornati alle scuole superiori.
Dividendo la proprietà SizeRemaining del volume per la tendenza (la pendenza $A) si può stimare approssimativamente quanti giorni mancano al riempimento del volume, alla velocità attuale di aumento dello spazio di archiviazione. È possibile aggiungere le funzioni di supporto Format-Bytes, Format-Trend e Format-Days per migliorare l'output.
Importante
Questa stima è lineare e si basa solo sulle ultime 14 misurazioni giornaliere. Esistono tecniche più sofisticate e precise. È consigliabile valutare bene la situazione e non fare affidamento solo su questo script per determinare se investire nell'espansione dello spazio di archiviazione. Questo script viene illustrato qui solo a scopo didattico.
Script
Ecco lo script:
Function Format-Bytes {
Param (
$RawValue
)
$i = 0 ; $Labels = ("B", "KB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB")
Do { $RawValue /= 1024 ; $i++ } While ( $RawValue -Gt 1024 )
# Return
[String][Math]::Round($RawValue) + " " + $Labels[$i]
}
Function Format-Trend {
Param (
$RawValue
)
If ($RawValue -Eq 0) {
"0"
}
Else {
If ($RawValue -Gt 0) {
$Sign = "+"
}
Else {
$Sign = "-"
}
# Return
$Sign + $(Format-Bytes ([Math]::Abs($RawValue))) + "/day"
}
}
Function Format-Days {
Param (
$RawValue
)
[Math]::Round($RawValue)
}
$CSV = Get-Volume | Where-Object FileSystem -Like "*CSV*"
$Output = $CSV | ForEach-Object {
$N = 14 # Require 14 days of history
$Data = $_ | Get-ClusterPerf -VolumeSeriesName "Volume.Size.Available" -TimeFrame "LastYear" | Sort-Object Time | Select-Object -Last $N
If ($Data.Length -Ge $N) {
# Last N days as (x, y) points
$PointsXY = @()
1..$N | ForEach-Object {
$PointsXY += [PsCustomObject]@{ "X" = $_ ; "Y" = $Data[$_-1].Value }
}
# Linear (y = ax + b) least squares algorithm
$MeanX = ($PointsXY | Measure-Object -Property X -Average).Average
$MeanY = ($PointsXY | Measure-Object -Property Y -Average).Average
$XX = $PointsXY | ForEach-Object { $_.X * $_.X }
$XY = $PointsXY | ForEach-Object { $_.X * $_.Y }
$SSXX = ($XX | Measure-Object -Sum).Sum - $N * $MeanX * $MeanX
$SSXY = ($XY | Measure-Object -Sum).Sum - $N * $MeanX * $MeanY
$A = ($SSXY / $SSXX)
$B = ($MeanY - $A * $MeanX)
$RawTrend = -$A # Flip to get daily increase in Used (vs decrease in Remaining)
$Trend = Format-Trend $RawTrend
If ($RawTrend -Gt 0) {
$DaysToFull = Format-Days ($_.SizeRemaining / $RawTrend)
}
Else {
$DaysToFull = "-"
}
}
Else {
$Trend = "InsufficientHistory"
$DaysToFull = "-"
}
[PsCustomObject]@{
"Volume" = $_.FileSystemLabel
"Size" = Format-Bytes ($_.Size)
"Used" = Format-Bytes ($_.Size - $_.SizeRemaining)
"Trend" = $Trend
"DaysToFull" = $DaysToFull
}
}
$Output | Format-Table
Esempio 6: Divoratore di memoria, si può scappare ma non ci si può nascondere
Poiché la cronologia delle prestazioni viene raccolta e archiviata centralmente per l'intero cluster, non è mai necessario mettere insieme i dati di macchine diverse, indipendentemente dal numero di spostamenti delle macchine virtuali da un host all'altro. Questo esempio usa la serie VM.Memory.Assigned dell'intervallo di tempo LastMonth per identificare le macchine virtuali che hanno utilizzato più memoria negli ultimi 35 giorni.
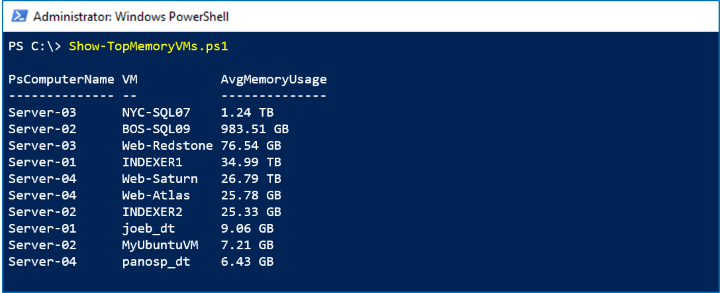
Schermata acquisita
Nello screenshot seguente vengono visualizzate le prime 10 macchine virtuali per utilizzo di memoria nell'ultimo mese:
Funzionamento
Si ripete Invoke-Command, introdotto sopra, per Get-VM in ogni server. Si usa Measure-Object -Average per ottenere la media mensile per ogni macchina virtuale, quindi Sort-Object seguito da Select-Object -First 10 per ottenere la classifica. (O forse è l'elenco dei più ricercati?)
Script
Ecco lo script:
$Output = Invoke-Command (Get-ClusterNode).Name {
Function Format-Bytes {
Param (
$RawValue
)
$i = 0 ; $Labels = ("B", "KB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB")
Do { if( $RawValue -Gt 1024 ){ $RawValue /= 1024 ; $i++ } } While ( $RawValue -Gt 1024 )
# Return
[String][Math]::Round($RawValue) + " " + $Labels[$i]
}
Get-VM | ForEach-Object {
$Data = $_ | Get-ClusterPerf -VMSeriesName "VM.Memory.Assigned" -TimeFrame "LastMonth"
If ($Data) {
$AvgMemoryUsage = ($Data | Measure-Object -Property Value -Average).Average
[PsCustomObject]@{
"VM" = $_.Name
"AvgMemoryUsage" = Format-Bytes $AvgMemoryUsage.Value
"RawAvgMemoryUsage" = $AvgMemoryUsage.Value # For sorting...
}
}
}
}
$Output | Sort-Object RawAvgMemoryUsage -Descending | Select-Object -First 10 | Format-Table PsComputerName, VM, AvgMemoryUsage
Ecco fatto! Speriamo che questi esempi siano utili per iniziare a lavorare. Con la cronologia delle prestazioni di Spazi di archiviazione diretta e il cmdlet Get-ClusterPerf potente e intuitivo per lo creazione di script, è possibile fare domande e rispondere durante la gestione e il monitoraggio dell'infrastruttura di Windows Server 2019.