Azure Storage プロバイダー (Azure Functions)
このドキュメントでは、パフォーマンスとスケーラビリティの側面に重点を置いて、Durable Functions Azure Storage プロバイダーの特性について説明します。 Azure Storage プロバイダーは既定のプロバイダーです。 インスタンスの状態とキューは、Azure Storage (クラシック) アカウントに格納されます。
注意
Durable Functions でサポートされるストレージ プロバイダーとそれらの比較の詳細については、Durable Functions ストレージ プロバイダーに関するドキュメントを参照してください。
Azure Storage プロバイダーでは、すべての関数実行は Azure Storage キューによって行われます。 オーケストレーションとエンティティの状態と履歴は、Azure テーブルに格納されます。 Azure Blob と BLOB リースを使用して、複数のアプリ インスタンス ("ワーカー" または単に VM とも呼ばれます) の間でオーケストレーション インスタンスとエンティティが分配されます。 このセクションでは、さまざまな Azure Storage 成果物と、それらがパフォーマンスとスケーラビリティに与える影響について詳しく説明します。
ストレージ表現
タスク ハブ は、すべてのインスタンス状態とすべてのメッセージを永続的に保持します。 これらを使用してオーケストレーションの進行状況を追跡する方法の簡単な概要については、 タスク ハブの実行例を参照してください。
Azure Storage プロバイダーは、次のコンポーネントを使用してストレージ内のタスク ハブを表します。
- 2 ~ 3 つの Azure テーブル間。 履歴とインスタンスの状態を表すために、2 つのテーブルが使用されます。 テーブル パーティション マネージャーが有効になっている場合は、パーティション情報を保存するために 3 つ目のテーブルが導入されます。
- 1 つの Azure キューにアクティビティ メッセージが格納されます。
- 1 つ以上の Azure キューにインスタンス メッセージが格納されます。 これらのいわゆる "コントロール キュー" はそれぞれ、インスタンス ID のハッシュに基づいて、すべてのインスタンス メッセージのサブセットが割り当てられるパーティションを表します。
- BLOB やサイズの大きいメッセージのリースに使用される追加の BLOB コンテナーがいくつかあります。
たとえば、PartitionCount = 4 を持つ xyz という名前が付いたタスク ハブには、次のキューとテーブルが含まれています。

次に、これらのコンポーネントとそれらが果たす役割について詳しく説明します。
履歴テーブル
履歴テーブルは、タスク ハブ内のすべてのオーケストレーション インスタンスの履歴イベントを含む Azure Storage テーブルです。 このテーブルの名前は、TaskHubNameHistory の形式になります。 インスタンスが実行されると、新しい行がこのテーブルに追加されます。 このテーブルのパーティション キーは、オーケストレーションのインスタンス ID から派生します。 既定では、インスタンス ID はランダムであり、Azure Storage の内部パーティションが最適に分配されるようになっています。 このテーブルの行キーは、履歴イベントの順序付けに使用されるシーケンス番号です。
オーケストレーション インスタンスを実行する必要がある場合、1 つのテーブル パーティション内の範囲クエリを使用して、履歴テーブルの対応する行がメモリに読み込まれます。 その後、これらの "履歴イベント" がオーケストレーター関数コードに再生され、以前にチェックポイントされた状態に戻されます。 このように実行履歴を使用した状態の再構築は、イベント ソーシング パターンの影響を受けます。
ヒント
履歴テーブルに格納されているオーケストレーション データには、アクティビティおよびサブオーケストレーター関数からの出力ペイロードが含まれます。 外部イベントからのペイロードも履歴テーブルに格納されます。 オーケストレーターの実行が必要になるたびに履歴全体がメモリに読み込まれるので、履歴が大規模であると、特定の VM で深刻なメモリ不足が発生するおそれがあります。 オーケストレーション履歴の長さとサイズを削減するには、大規模なオーケストレーションを複数のサブオーケストレーションに分割するか、呼び出されるアクティビティおよびサブオーケストレーター関数によって返される出力のサイズを小さくします。 または、VM ごとのコンカレンシー スロットルを下げて、メモリに同時に読み込まれるオーケストレーションの数を制限することでも、メモリ使用量を削減できます。
インスタンス テーブル
インスタンス テーブルは、タスク ハブ内のすべてのオーケストレーションおよびエンティティのインスタンスの状態を含みます。 インスタンスが作成されると、このテーブルに新しい行が追加されます。 このテーブルのパーティション キーはオーケストレーション インスタンス ID またはエンティティ キーであり、行キーは空の文字列です。 オーケストレーションまたはエンティティ インスタンスごとに 1 行があります。
このテーブルは、status query HTTP API 呼び出しおよびコードからのインスタンス クエリ要求を満たすために使用されます。 最終的には、前述の履歴テーブルの内容との整合性が維持されます。 このように別の Azure Storage テーブルを使用したインスタンス クエリ操作への効率的な対応は、コマンド クエリ責務分離 (CQRS) パターンの影響を受けます。
ヒント
"インスタンス" テーブルをパーティションに分割することにより、実行時のパフォーマンスやスケールに大きな影響を与えることなく、何百万ものオーケストレーション インスタンスを格納できます。 ただし、インスタンスの数は、マルチインスタンス クエリのパフォーマンスに大きな影響を与えるおそれがあります。 これらのテーブルに格納されているデータの量を制御するには、定期的に古いインスタンス データを削除することを検討してください。
パーティション テーブル
Note
このテーブルは、Table Partition Manager が有効になっている場合にのみタスク ハブに表示されます。 これを適用するには、アプリの useTablePartitionManagementhost.json で 設定を構成します。
パーティション テーブルには、Durable Functions アプリのパーティションの状態が保存され、アプリのワーカー間でパーティションを分散するために使用されます。 パーティションごとに 1 行あります。
キュー
オーケストレーター、エンティティ、アクティビティの関数はすべて、関数アプリのタスク ハブ内の内部キューによってトリガーされます。 このようにキューを使用することによって、信頼性のある "少なくとも 1 回" のメッセージ配信保証が実現されます。 Durable Functions には、コントロール キューと作業項目キューという 2 種類のキューがあります。
作業項目キュー
Durable Functions では、タスク ハブあたり 1 つの作業項目のキューがあります。 これは基本的なキューであり、Azure Functions の他の queueTrigger キューと同様に動作します。 このキューは、一度に 1 つのメッセージをデキューして、ステートレスな "アクティビティ関数" をトリガーするために使用されます。 これらの各メッセージには、アクティビティ関数の入力と追加のメタデータ (実行する関数など) が含まれています。 Durable Functions アプリケーションが複数の VM にスケールアウトされた場合、作業項目キューのタスクを取得するためにこれらの VM がすべて競合します。
コントロール キュー
Durable Functions では、タスク ハブごとに複数の "コントロール キュー" があります。 "コントロール キュー" は、単純な作業項目キューよりも高度なキューです。 コントロール キューは、ステートフルなオーケストレーターおよびエンティティ関数をトリガーするために使用されます。 オーケストレーターおよびエンティティ関数のインスタンスはステートフル シングルトンであるため、各オーケストレーションまたはエンティティが一度に 1 つのワーカーだけで処理されることが重要です。 この制約を満たすために、各オーケストレーション インスタンスまたはエンティティは単一のコントロール キューに割り当てられます。 これらのコントロール キューは、各キューが一度に 1 つのワーカーだけで処理されるよう、ワーカー間で負荷分散されています。 この動作の詳細については、以降のセクションをご覧ください。
コントロール キューには、さまざまな種類のオーケストレーション ライフサイクル メッセージが含まれます。 たとえば、オーケストレーター コントロール メッセージ、アクティビティ関数の "応答" メッセージ、タイマー メッセージがあります。 1 回のポーリングで 32 個のメッセージがコントロール キューからデキューされます。 これらのメッセージには、ペイロード データと、対象となるオーケストレーション インスタンスなどのメタデータが含まれています。 デキューされた複数のメッセージが同じオーケストレーション インスタンスを対象としている場合、それらはバッチとして処理されます。
コントロール キュー メッセージは、バックグラウンド スレッドを使用して持続的にポーリングされます。 各キュー ポーリングのバッチ サイズは host.json の controlQueueBatchSize 設定によって制御され、既定値は 32 (Azure キューでサポートされる最大値) です。 メモリにバッファーされているプリフェッチされたコントロール キュー メッセージの最大数は、host.json の controlQueueBufferThreshold 設定によって制御されます。 controlQueueBufferThreshold の既定値は、ホスティング プランの種類など、さまざまな要因によって異なります。 これらの設定の詳細については、host.json スキーマに関するドキュメントを参照してください。
ヒント
controlQueueBufferThreshold の値を大きくすると、1 つのオーケストレーションまたはエンティティでイベントをより迅速に処理できます。 ただし、この値を増やすと、メモリ使用量も増加するおそれがあります。 メモリ使用量が増加する原因として、キューからプルするメッセージが多くなることや、メモリにフェッチされるオーケストレーション履歴が増えることが挙げられます。 したがって、controlQueueBufferThreshold の値を減らすことは、メモリ使用量を減らす効果的な方法になります。
キューのポーリング
Durable Task 拡張機能は、アイドル状態のキューのポーリングがストレージ トランザクション コストに与える影響を軽減するために、ランダムな指数バックオフ アルゴリズムを実装します。 メッセージが見つかると、ランタイムは直ちに別のメッセージを確認します。 メッセージが見つからない場合は、一定時間待機してから再試行します。 その後の試行でもキュー メッセージを取得できなかった場合は、最大待ち時間 (既定で 30 秒間) に達するまで待ち時間は増加し続けます。
最大ポーリング遅延は、host.json ファイル内の maxQueuePollingInterval プロパティを使用して構成できます。 このプロパティを高い値に設定するほど、メッセージ処理の待機時間が長くなる可能性があります。 長い処理時間が予期されるのは、非アクティブ期間の後のみになります。 このプロパティを低い値に設定すると、ストレージ トランザクションの増加により、ストレージ コストが上昇する場合があります。
Note
Azure Functions Consumption プランおよび Premium プランで実行しているとき、Azure Functions Scale Controller は、それぞれのコントロールと作業項目キューを 10 秒に 1 回ポーリングします。 この追加のポーリングは、関数アプリをアクティブにしてスケーリングの決定を行うタイミングを判別するために必要です。 この記事の執筆時点では、この 10 秒の間隔は定数であり、構成することはできません。
オーケストレーション開始の遅延
オーケストレーションのインスタンスを開始するには、タスク ハブのコントロール キューのいずれかに ExecutionStarted メッセージを追加します。 特定の状況では、オーケストレーションの実行がスケジュールされている時刻から、実際に実行が開始されるまでの間に、複数秒の遅延が発生する場合があります。 この時間の間、オーケストレーションのインスタンスは Pending 状態のままになります。 この遅延には、次の 2 つの原因が考えられます。
コントロール キューのバックログ: このインスタンスのコントロール キューに多数のメッセージが含まれている場合は、
ExecutionStartedメッセージがランタイムによって受信および処理されるまでに時間がかかることがあります。 メッセージのバックログは、オーケストレーションで多数のイベントが同時に処理されている場合に発生する可能性があります。 コントロール キューに送られるイベントには、オーケストレーション開始イベント、アクティビティ完了、永続タイマー、終了、外部イベントなどがあります。 通常の状況でこの遅延が発生する場合は、より多くのパーティションを持つ新しいタスク ハブを作成することを検討してください。 より多くのパーティションを構成すると、ランタイムによって負荷分散のためにより多くのコントロール キューが作成されます。 各パーティションはコントロール キューに 1:1 で対応しており、最大で 16 個のパーティションがあります。バックオフ ポーリングの遅延: オーケストレーションが遅延するもう 1 つの一般的な原因は、前に説明したコントロール キューに対するバックオフ ポーリング動作です。 ただし、この遅延は、アプリが 2 つ以上のインスタンスにスケールアウトされている場合にのみ予想されます。 アプリ インスタンスが 1 つしかない場合、またはオーケストレーションを開始するアプリ インスタンスがターゲット コントロール キューをポーリングしているインスタンスでもある場合は、キューのポーリング遅延は発生しません。 前に説明したように、host.json の設定を更新することで、バックオフ ポーリング遅延を減らすことができます。
BLOB
ほとんどの場合、Durable Functions ではデータを永続化するために Azure Storage Blob を使用しません。 ただし、キューとテーブルには、Durable Functions で必要なすべてのデータがストレージ行またはキュー メッセージに永続化されないようにすることができるサイズ制限があります。 たとえば、シリアル化するときに、キューに永続化する必要があるデータが 45 KB を超える場合、Durable Functions では代わりにデータが圧縮されて BLOB に格納されます。 この方法で BLOB ストレージにデータを永続化する場合、Durable Function では、その BLOB への参照がテーブル行またはキュー メッセージに格納されます。 Durable Functions でデータを取得する必要がある場合は、BLOB から自動的に取り込まれます。 これらの BLOB は BLOB コンテナー <taskhub>-largemessages に格納されます。
パフォーマンスに関する考慮事項
大きいメッセージに対する追加の圧縮と BLOB 操作の手順は、CPU および I/O 待機時間のコスト面でコストが高くなる可能性があります。 さらに、Durable Functions では、永続化されたデータをメモリに読み込む必要があり、多くの異なる関数を同時に実行する場合にこれを行うこともあります。 その結果、大きなデータ ペイロードを永続化すると、メモリの使用率も高くなる可能性があります。 メモリのオーバーヘッドを最小限に抑えるには、大きなデータ ペイロードを手動で (たとえば、BLOB ストレージに) 永続化し、代わりにそのデータへの参照を受け渡すことを検討してください。 これにより、コードで必要なときにのみデータを読み込んで、オーケストレーター関数の再生中の冗長な読み込みを回避することができます。 ただし、ペイロードをローカル ディスクに格納することはお勧め しません。これは、関数がその有効期間を通じて異なる VM で実行される可能性があるため、ディスク上の状態が利用可能であることが保証されないためです。
ストレージ アカウントの選択
Durable Functions で使用されるキュー、テーブル、BLOB は、構成済みの Azure Storage アカウントに作成されます。 使用するアカウントは、host.json ファイルの durableTask/storageProvider/connectionStringName 設定 (または Durable Functions 1.x の durableTask/azureStorageConnectionStringName 設定) を使用して指定できます。
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"connectionStringName": "MyStorageAccountAppSetting"
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"azureStorageConnectionStringName": "MyStorageAccountAppSetting"
}
}
}
アカウントが指定されていない場合、既定の AzureWebJobsStorage ストレージ アカウントが使用されます。 ただし、パフォーマンスが重視されるワークロードの場合、既定以外のストレージ アカウントを構成することをお勧めします。 Durable Functions では Azure Storage を頻繁に使用するので、専用のストレージ アカウントを使用することで、Durable Functions によるストレージの使用を、Azure Functions ホストによる内部的な使用から分離します。
Note
Azure Storage プロバイダーを使用する場合、標準の汎用 Azure Storage アカウントが必要です。 他のストレージ アカウントの種類はどれもサポートされていません。 Durable Functions には、従来の v1 汎用ストレージ アカウントを使用することを強くお勧めします。 新しい v2 ストレージ アカウントでは、Durable Functions ワークロードのコストが大幅に高まるおそれがあります。 Azure Storage アカウントの種類について詳しくは、「ストレージ アカウントの概要」ドキュメントを参照してください。
オーケストレーターのスケールアウト
より多くの VM を弾力的に追加することでアクティビティ関数を無限にスケールアウトできますが、個々のオーケストレーター インスタンスとエンティティは単一のパーティションに存在するよう制約され、パーティションの最大数は host.json の partitionCount 設定によって制限されます。
Note
一般に、オーケストレーター関数は軽量であることを目的としているので、多くの処理能力を必要としません。 そのため、オーケストレーションのスループットを向上させるためにコントロール キューの多数のパーティションを作成する必要はありません。 高負荷の処理の大半をステートレスなアクティビティ関数で実行することで、無限にスケールアウトできます。
コントロール キューの数は、host.json ファイルで定義されています。 次の例の host.json スニペットを使うと、durableTask/storageProvider/partitionCount プロパティ (または Durable Functions 1.x の durableTask/partitionCount) は 3 に設定されます。 パーティション数と同じだけのコントロール キューがあることに注意してください。
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
タスク ハブは、1 ~ 16 個のパーティションで構成できます。 パーティション数が指定されていない場合、既定値は 4 です。
トラフィックの少ないシナリオでは、アプリケーションがスケールインされるため、パーティションが少数のワーカーによって管理されます。 例として、下の図を考えてみましょう。
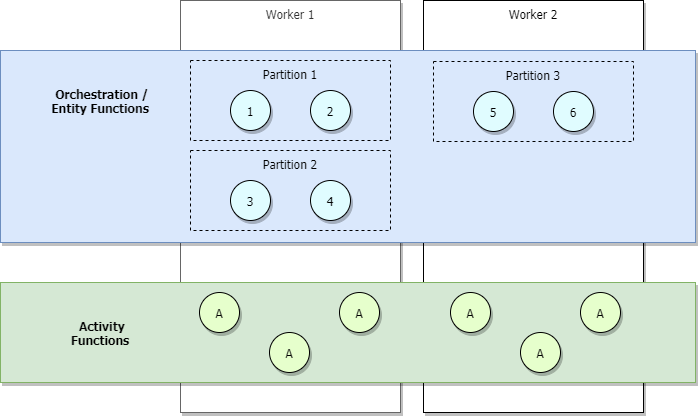
前の図では、オーケストレーター 1 から 6 の負荷が複数のパーティションに分散されていることがわかります。 同様に、パーティションはアクティビティのようにワーカー間で負荷分散されています。 パーティションは、開始するオーケストレーターの数に関係なく、ワーカー間で負荷分散されます。
Azure Functions 従量課金またはエラスティック Premium プランで実行している場合、または負荷ベースの自動スケーリングを構成している場合、トラフィックの増加に応じてより多くのワーカーが割り当てられ、パーティションは最終的にすべてのワーカーに対して負荷分散されます。 スケールアウトを続けると、最終的に各パーティションが 1 つのワーカーによって管理されます。 一方、アクティビティは引き続きすべてのワーカー間で負荷分散されます。 これを下の図で示します。
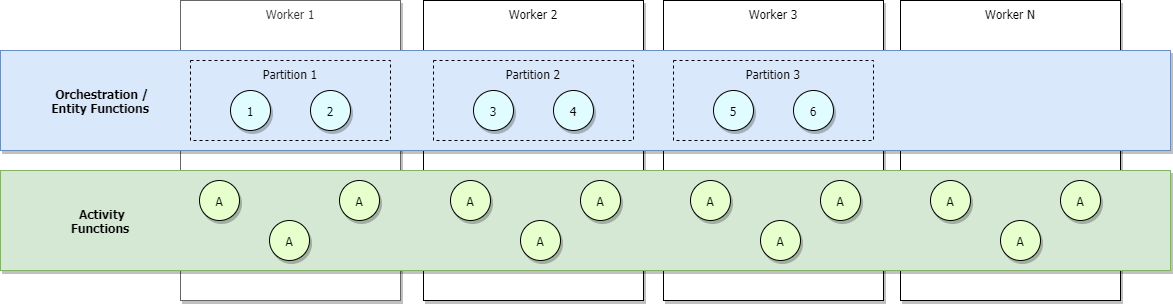
任意の時点で同時にアクティブなオーケストレーションの最大数の上限は、アプリケーションに割り当てられたワーカーの数に maxConcurrentOrchestratorFunctions を "掛けた" 値に等しくなります。 この上限は、パーティションがワーカー間で完全にスケールアウトされている場合に、より正確に設定できます。 完全にスケールアウトされている場合、各ワーカーの Functions ホスト インスタンスは 1 つだけになるため、"アクティブ" な同時オーケストレーター インスタンスの最大数は、パーティション数に maxConcurrentOrchestratorFunctions を "掛けた" 値に等しくなります。
Note
このコンテキストでは、"アクティブ" とは、オーケストレーションまたはエンティティがメモリに読み込まれ、"新しいイベント" が処理されることを意味します。 オーケストレーションまたはエンティティは、アクティビティ関数の戻り値など、追加のイベントを待機している場合は、メモリからアンロードされ、"アクティブ" と見なされなくなります。 オーケストレーションとエンティティはその後、処理する新しいイベントが存在する場合にのみメモリに再読み込みされます。 1 つの VM で実行できるオーケストレーションまたはエンティティは、すべてが "実行中" 状態であっても、その "合計" の実際の最大数はありません。 唯一の制限は、"同時にアクティブになっている" オーケストレーションまたはエンティティのインスタンスの数です。
下の図で示している完全にスケールアウトされたシナリオでは、さらにオーケストレーターが追加されていますが、いくつかが非アクティブで、グレーで示されています。
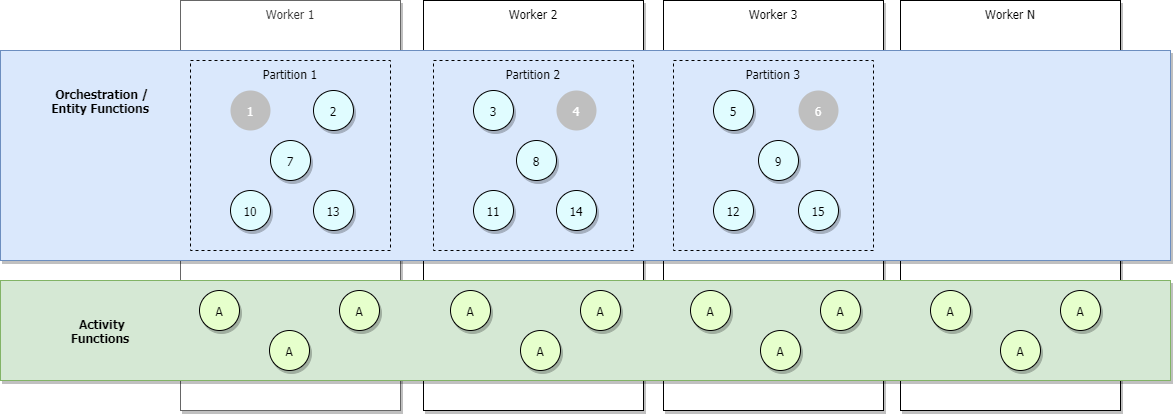
スケールアウト中に、コントロール キュー リースが Functions ホスト インスタンス間で再配分されて、パーティションが均等に分配されます。 これらのリースは Azure Blob Storage リースとして内部実装され、個別のオーケストレーション インスタンスまたはエンティティが一度に 1 つのホスト インスタンスだけで実行されるようにします。 タスク ハブを 3 つのパーティションで構成している (したがって、コントロール キューが 3 つの) 場合、オーケストレーション インスタンスとエンティティは 3 つのリース保持ホスト インスタンスすべての間で負荷分散できます。 VM を追加することで、アクティビティ関数を実行するための容量を増やすことができます。
次の図は、Azure Functions ホストがスケールアウトされた環境で ストレージ エンティティと対話する方法を示しています。
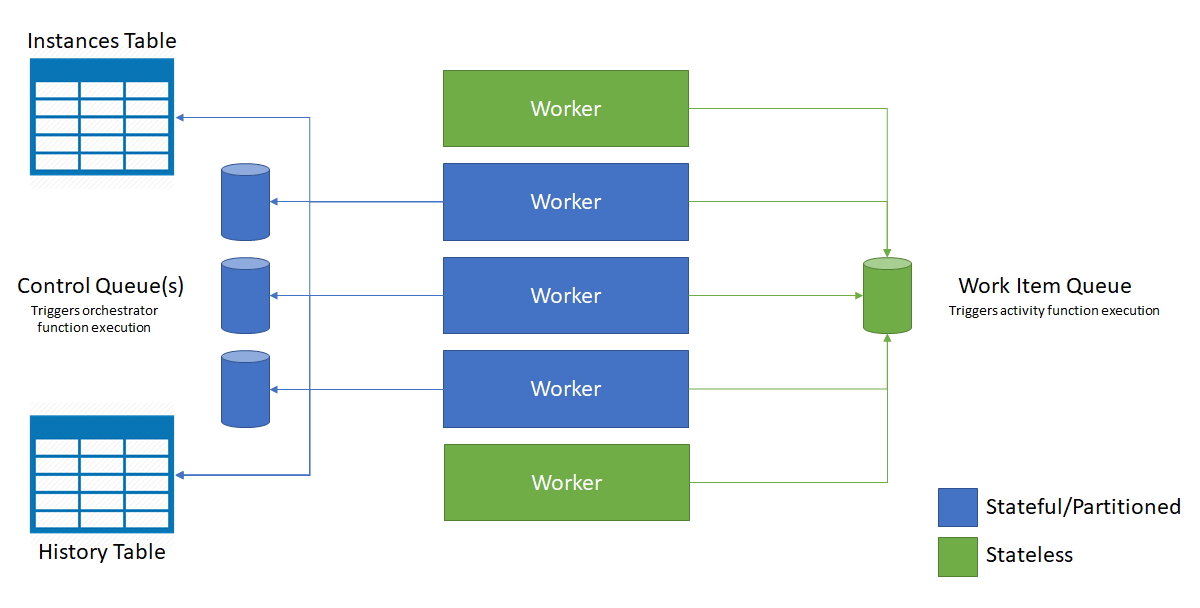
前の図に示すように、作業項目キューのメッセージを取得するためにすべての VM が競合します。 ただし、コントロール キューからメッセージを取得できるのは 3 台の VM のみであり、各 VM が 1 つのコントロール キューをロックします。
オーケストレーション インスタンスおよびエンティティは、すべてのコントロール キュー インスタンスに分散されます。 分散は、オーケストレーションのインスタンス ID またはエンティティ名とキーのペアをハッシュすることによって行われます。 オーケストレーション インスタンス ID は既定ではランダムな GUID であり、インスタンスはすべてのコントロール キューに均等に配分されます。
一般に、オーケストレーター関数は軽量であることを目的としているので、多くの処理能力を必要としません。 そのため、オーケストレーションのスループットを向上させるためにコントロール キューの多数のパーティションを作成する必要はありません。 高負荷の処理の大半をステートレスなアクティビティ関数で実行することで、無限にスケールアウトできます。
延長セッション
延長セッションは、メッセージの処理が完了した後でも、オーケストレーションとエンティティをメモリ内に保持する キャッシュ メカニズム です。 一般に、延長セッションを有効にすると、基礎となっている永続的ストアに対する I/O が減少し、全体的なスループットが向上します。
延長セッションを有効にするには、host.json ファイルで durableTask/extendedSessionsEnabled を true に設定します。 durableTask/extendedSessionIdleTimeoutInSeconds 設定は、アイドル セッションがメモリに保持される期間を制御するために使用できます。
Functions 2.0
{
"extensions": {
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
}
Functions 1.0
{
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
この設定には、次の 2 つの欠点があることに注意してください。
- アイドル状態のインスタンスはメモリからすぐにアンロードされないので、関数アプリのメモリ使用量が全体的に増加します。
- 短期間で同時に実行される個別のオーケストレーターまたはエンティティ関数が多数ある場合、スループットが全体的に低下するおそれがあります。
たとえば、durableTask/extendedSessionIdleTimeoutInSeconds を 30 秒に設定した場合、実行時間の短いオーケストレーターまたはエンティティ関数の 1 回の実行時間が 1 秒未満であっても、30 秒間メモリが占有されることになります。 また、前述の durableTask/maxConcurrentOrchestratorFunctions クォータにもカウントされるので、他のオーケストレーターまたはエンティティ関数の実行を妨げる可能性があります。
オーケストレーターおよびエンティティ関数に対する延長セッションの具体的な効果については、次のセクションで説明します。
Note
延長セッションは現在、C# や F# など、.NET 言語でのみサポートされています。 その他のプラットフォームで extendedSessionsEnabled を true に設定すると、ランタイム問題が発生することがあります。たとえば、警告なく、アクティビティやオーケストレーションでトリガーされる関数の実行に失敗します。
オーケストレーター関数の再生
前述のように、オーケストレーター関数は履歴テーブルの内容を使用して再生されます。 既定では、メッセージのバッチがコントロール キューからデキューされるたびに、オーケストレーター関数コードが再生されます。 ファンアウト、ファンイン パターンを使用していて、すべてのタスクが完了するまで待機している場合 (たとえば、.NET で Task.WhenAll()、JavaScript で context.df.Task.all()、またはPython で context.task_all() を使用している場合) でも、タスク応答のバッチが時間の経過と共に処理されるため、再生が発生します。 延長セッションを有効にすると、オーケストレーター関数インスタンスがメモリに保持される期間が長くなり、履歴全体を再生することなく新しいメッセージを処理できます。
延長セッションのパフォーマンス向上は、次のような場合によく見られます。
- 同時に実行されるオーケストレーション インスタンスの数が制限されている場合。
- オーケストレーションに、すぐに完了するシーケンシャル アクション (たとえば、数百個のアクティビティ関数呼び出し) がある場合。
- ほぼ同時に完了する多数のアクションがオーケストレーションによってファンアウトおよびファンインされる場合。
- オーケストレーター関数でサイズの大きなメッセージが処理される場合、または CPU を集中的に使用するデータ処理を行う必要がある場合。
他のどのような状況でも、通常、オーケストレーター関数のパフォーマンスの向上は見られません。
Note
これらの設定は、オーケストレーター関数が十分に開発され、テストされた後にのみ使用してください。 既定のアグレッシブな再生動作は、開発時にオーケストレーター関数コードの制約違反を検出する場合に役立ちます。そのため、既定では無効です。
パフォーマンスの目標
次の表は、 パフォーマンスとスケール に関する記事の「 パフォーマンス ターゲット 」セクションで説明されているシナリオで予想される 最大 スループット数を示しています。
"インスタンス" は、Azure App Service の単一のサイズの小さい (A1) VM で実行されるオーケストレーター関数の単一のインスタンスを指します。 どの場合も、延長セッションが有効になっていることを前提としています。 実際の結果は、関数コードで実行される CPU または I/O の処理によって異なる可能性があります。
| シナリオ | 最大スループット |
|---|---|
| アクティビティの順次実行 | インスタンスあたり、5 アクティビティ/秒 |
| アクティビティの並列実行 (ファンアウト) | インスタンスあたり、100 アクティビティ/秒 |
| 並列応答処理 (ファンイン) | インスタンスあたり、150 応答/秒 |
| 外部イベント処理 | インスタンスあたり、50 イベント/秒 |
| エンティティ操作の処理 | 1 秒あたり 64 回の操作 |
予想されるスループットの数値が得られず、CPU 使用率とメモリ使用量が正常と思われる場合は、原因がストレージ アカウントの正常性に関係していないかどうかを確認してください。 Durable Functions 拡張機能は Azure ストレージ アカウントに大きな負荷をかける可能性があり、負荷が非常に高くなると、ストレージ アカウントのスロットルが発生する場合があります。
ヒント
場合によっては、host.json の controlQueueBufferThreshold 設定の値を増やすことで、外部イベント、アクティビティのファンイン、エンティティ操作のスループットを大幅に向上できます。 この値を既定値より大きくすると、Durable Task Framework ストレージ プロバイダーでは、よく多くのメモリを使用して積極的にこれらのイベントをプリフェッチし、Azure Storage コントロール キューからのメッセージのデキューに関連する遅延が減少します。 詳細については、host.json のリファレンス ドキュメントを参照してください。
高スループット処理
Azure Storage バックエンドのアーキテクチャにより、Durable Functions の理論上の最大パフォーマンスとスケーラビリティに一定の制限が加えられます。 テストで Azure Storage の Durable Functions がスループット要件を満たしていないことが示された場合は、代わりに、Durable Functions に Netherite ストレージ プロバイダーを使用することを検討してください。
さまざまな基本的なシナリオで達成可能なスループットを比較するには、Netherite ストレージ プロバイダー ドキュメントの「 基本シナリオ 」セクションを参照してください。
Netherite ストレージ バックエンドは、Microsoft Research によって設計および開発されました。 これは、Azure ページ BLOB 上で Azure Event Hubs と FASTER データベース テクノロジを使用します。 Netherite の設計により、他のプロバイダーと比較して、オーケストレーションとエンティティのスループット処理を大幅に向上できます。 一部のベンチマーク シナリオでは、既定の Azure Storage プロバイダーと比較して、桁違いのスループット向上が記録されました。
Durable Functions でサポートされるストレージ プロバイダーとそれらの比較の詳細については、Durable Functions ストレージ プロバイダーに関するドキュメントを参照してください。