RyuJIT CTP3: How to use SIMD
SIMD details will be forthcoming from the .NET blog, but Soma's already showed some sample code, and everything's available, so until those details are available here are directions about how to kick the SIMD tires:
- Go get RyuJIT CTP3 and install it (requires x64 Windows 8.1 or Window Server 2012R2, same as before)
- Set the "use RyuJIT" environment variable: set COMPLUS_AltJit=*
- Update: make sure you un-set this when you are done testing RyuJIT! See here for more details.
- Now pay attention, because things diverge here a bit:
- Set a new (and temporary) “enable SIMD stuff” environment variable: set COMPLUS_FeatureSIMD=1
- Add the Microsoft.Bcl.Simd NuGet package to your project (you must select “include Prerelease” or use the –Pre option)
- Tricky thing necessary until RyuJIT is final: Add a reference to Microsoft.Numerics.Vectors.Vector<T> to a class constructor that will be invoked BEFORE your methods that use the new Vector types. I’d suggest just putting it in your program’s entry class’s constructor. It must occur in the class constructor, not the instance constructor.
- Make sure your application is actually running on x64. If you don't see protojit.dll loaded in your process (tasklist /M protojit.dll) then you've missed something here.
You can take a gander at some sample code sitting over here. It's pretty well commented, at least the VectorFloat.cs file is in the Mandelbrot demo. I spent almost as much time making sure comments were good as writing those 24 slightly different implementations of the Mandelbrot calculation. Take a look at the Microsoft.Numerics.Vectors namespace: there some stuff in Vector<T>, some stuff in VectorMath, and some stuff in plain Vector. And there are also "concrete types" for 2, 3, and 4 element floats.
One quick detail, for those of you that are trying this stuff out immediately: our plan (and we've already prototyped this) is to have Vector<T> automatically use AVX SIMD types on hardware where the performance of AVX code should be better than SSE2. Doing that properly, however, requires some changes to the .NET runtime. We're only able to support SSE2 for the CTP release because of that restriction (and time wasn't really on our side, either).
I’ll try to answer questions down below. I know this doesn’t have much detail. We’ve been really busy trying to get CTP3 out the door (it was published about 45 seconds before Jay’s slide went up). Many more details are coming. One final piece of info: SIMD isn’t the only thing we’ve been doing over the past few weeks. We also improved our benchmarks a little bit:
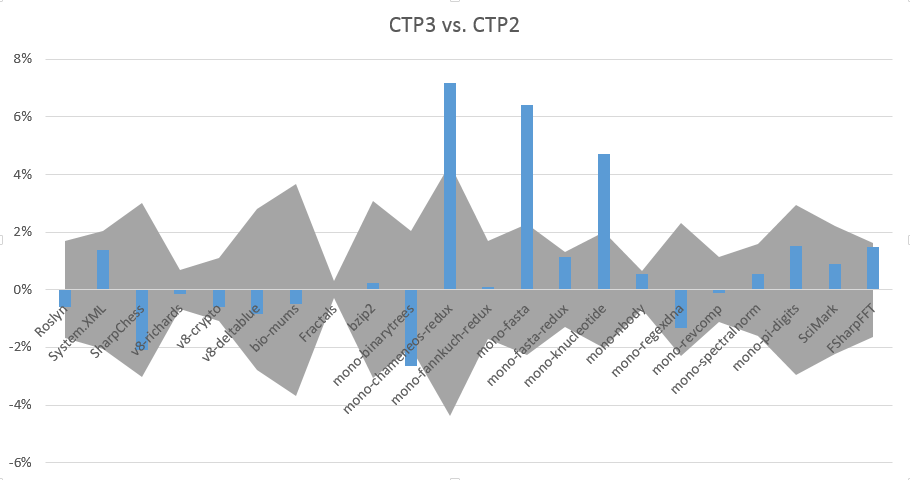
The gray bars are standard deviation, so my (really horrible) understanding of statistics means that delta's that are within the gray bars are pretty much meaningless. I'm not sure if we really did regress mono-binarytrees or not, but I'm guessing probably not. I do know that we improved a couple things that should help mono-fasta and mono-knucleotide, but the mono-chameneos-redux delta was unexpected.
Anyway, I hope this helps a little. I'm headed home for the evening, as my adrenaline buzz from trying to get everything done in time for Jay's talk is fading fast, and I want to watch Habib from the comfort of my couch, rather than be in traffic. Okay, I'm exaggerating: my commute is generally about 10 minutes, but I'm tired, and whiny, and there are wolves after me.
-Kev
Comments
Anonymous
April 03, 2014
The SIMD stuff is very exciting. If I can find some time I'll try adding some experimental support for it in MonoGame.Anonymous
April 03, 2014
@Tom Spilman: I'd love to see this stuff supported in Mono!Anonymous
April 03, 2014
The comment has been removedAnonymous
April 03, 2014
Great news! Very exiting times!Anonymous
April 04, 2014
@Nicholas: I know that RyuJIT with SIMD is exciting. Please just breathe deeply, and perhaps lie down. I don't want any of RyuJIT's rabid fans injuring themselves :)Anonymous
April 04, 2014
Wicked! Thank you!Anonymous
April 04, 2014
It is not SIMD support itself what excites me the most but the fact MS started paying attention to the quality of the machine code CLR generates.Anonymous
April 04, 2014
Kevin, is it possible for JIT to treat readonly fields as JIT constants? For example, when non-inlined methods (not ctors) are jited. That would let not to jit the whole branches and allow other types of optimizations.If it is not possible right now some mechanism (an attribute?) could be introduced that new code could use.Anonymous
April 06, 2014
What am I missing. I install that package and none of the namespaces start with Microsoft. They all start with System e.g System.Numerics.Vector<T>. 1.0.1-Beta is the right version, isn't it?Anonymous
April 06, 2014
@OmariO: const fields are generally the only things that will benefit from that sort of work. If it can be const, it should be const. readonly could allow us to do some type-specific optimizations & potentially better inlining (of methods off the readonly field) but not much else. It still a reasonable idea, though...@Keith, yes that's the right one. Once you've installed that, you still need to set the environment variables & use the type in your class constructor. Check out the sample for more details: code.msdn.microsoft.com/SIMD-Sample-f2c8c35aAnonymous
April 07, 2014
tirania.org/.../Nov-03.htmlAnonymous
April 07, 2014
Awesome! I'm very happy to see SIMD in .Net. I'm super-excited that MS is making an effort to improve the code that JIT'r produces.Here's a test for you....write a function and mark it as unsafe. Make sure to not use anything that requires garbage collection. Have it do something that is computationally expensive and time consuming. Like a function that takes an matrix and computes the Levenshtein distance between all of the rows. Write exactly the same thing in C++. Compare them. Compare their speed. Compare the emitted assembly. In most cases .Net is slower and does more. There's often no reason it couldn't have produced exactly the same, fast, code.One suggestion on the blog: While it's cool to see the difference between CTP2 and CTP3, what really matters is how RyuJIT compares to JIT64 so we can see how much better it is from it's predecessor.Anonymous
April 07, 2014
I see 2 useful cases when readonly fields as JIT constants could beneficial:class SomeClass{ static readonly bool etwLoggingEnabled = Congiguration.GetEtwLoggingAnabled(); public void SomeMethod() { // begin region if (etwLoggingEnabled) { logger.SomeMethodcalled(); } // end ... }}JIT could potentially completely skip jitting that region.2.class Buffer{ readonly int[] buffer; readonly int max; // must be <= buffer.Length when methods below are jited uint pointer = 0; public void WriteNext(int value) { ... buffer[pointer % max] = value; // or buffer[pointer % buffer.Length] = value; pointer++; } public void Loop(int value) { for (uint i =...; ... ; i++ ) { buffer[i % max] = value; // or buffer[i % buffer.Length] = value; } }}If the reference to the array is a jit time constant then buffer.Length is a jit constant too. This would let eliminate array bounds check and even replace % with & if at jit time max (or buffer.Length) is a power of two.Anonymous
April 08, 2014
@Laci: yup, we were very well aware of that work. We actually talked to the Xamarin folks about the design (as well as MVPs) before we finalized it. Our design is significantly less linked at the hip with x86 than Mono's design.@David: You probably won't believe me, but there's a fair bit of code that looks better coming out of RyuJIT that is better than what the C++ compiler is emitting. It's not a 50-50 thing (admittedly, we are slightly worse off than the C++ compiler, but it's not a slam dunk like it once was), but having more language constraints results in some scenarios where things work better.@Omario_O: Ah: write-once (readonly really means write-once) turned into compile time constants: kind of cool. We can definitely take a look at it from that angle!Anonymous
April 10, 2014
This has been around for a decade in C++. Plus, true cross-platform portability (C++ again). Did I mention the ability to do many useful things you cannot do in C# and you can in C++???Anonymous
April 10, 2014
@Amity Games: By "this" are you referring to the new Vector<T> type that is sized according to the width of you machine's CPU? Because if so, then you are wrong: C++ doesn't have this ability. If you're referring to a bunch of other stuff, then I'll agree with you. C++ can do many useful things you cannot do in C#, just like C# can do many useful things that you cannot do in C++. I'm a big fan of choosing the right tool for the job. I think choosing the right tool for the job is far more important that trolling. But that's just me :-PAnonymous
April 12, 2014
Just tested RyuJIT and the SIMD Samples, ok. Now I've already a BIG Math Library with lots of functions (plus almost all Vertex/PixelShader syntax reproduced) and almost all my struct are SequentialLayout like the "internal Register" , How to let RyuJIT generate SIMD on my struct/class/Methods instead of the one in BCL.Simd ? Is that possible or I need to extend Vector<T> ? And with extension methods can RyuJit generate SIMD ?Anonymous
April 15, 2014
I'm experimenting with vectorization of operations on large arrays and I'm find the performance of Vector<T>.CopyTo() isn't very good at all. Here's a snippet of my sample code to do vectorization: var scaledData1 = new float[rawData.Length]; var scaledData2 = new float[rawData.Length]; var stopwatch = Stopwatch.StartNew(); for (int i = 0; i < rawData.Length; i++) { scaledData1[i] = rawData[i] * Scale + Offset; } stopwatch.Stop(); Console.WriteLine("Regular scaling takes " + stopwatch.ElapsedMilliseconds); var vecScaleFactor = new Vector<float>(Scale); var vecOffset = new Vector<float>(Offset); stopwatch.Reset(); stopwatch.Start(); for (int i = 0; i < rawData.Length; i += 4) { var simdVector = new Vector<float>(rawData, i); var result = (simdVector * vecScaleFactor) + vecOffset; //scaledData2[i] = result[0]; //scaledData2[i + 1] = result[1]; //scaledData2[i + 2] = result[2]; //scaledData2[i + 3] = result[3]; result.CopyTo(scaledData2, i); } Console.WriteLine("Vector scaling takes " + stopwatch.ElapsedMilliseconds);This approach takes longer than just processing the array using regular (non-SIMD) scaling. However if I comment out the CopyTo() and uncomment the copy of the individuals registers then the performance is better than using non-SIMD approach - usually taking about 2/3 to 1/2 the time. Another concerning issue is that I seem to get different results when SIMD is not enabled and I'm running a Release config. One would hope that the code behaves the same whether SIMD is enabled or not. Of course, the performance of using Vector<T> when SIMD is not enabled is so much worse that you should use VectorMath.IsHardwareAccelerated to pick the right code path. All of this plumbing work begs for having auto-vectorization built into the C# compiler. :-)Anonymous
April 15, 2014
@MrReset: We've had a number of requests for automatically detecting (or allowing attributes) user types and promoting them to vector types. The primary problem with this is the amount of JIT-time validation we'd need to do: we'd need to make sure that element layout is compatible, validate which methods correspond to which hardware operations, etc... It's an interesting problem that lands somewhere between full auto-vectorization, and what we have today. The approach that is likely to be most achievable in the short term is for RyuJIT to do a great job of optimizing the case where you have struct that contains a Vector4f (or other Vector type), and you can just modify the internal representation to forward to the contained Vector type. Does that make sense?Anonymous
April 16, 2014
@Keith:Most likely the results differ because Intel's 32-bit float SIMD implementations perform their computations at 32-bits precision, whereas the default behavior of their scalar unit is to take a 32-bit float, convert internally to 80-bit extended precision, perform the calculation at the 80-bit precision level, and then either truncate or round the result and return as a 32-bit value.Anonymous
April 16, 2014
"I'm find the performance of Vector<T>.CopyTo() isn't very good at all"CopyTo isn't an intrinsic in the released version. I find it hard to believe that it will stay like this, it's more likely that they didn't have time to finish it. Vector<T>'s constructor is an intrinsic so this kind of stuff is certainly doable.Anonymous
April 16, 2014
Yes, Vector<T>.CopyTo() isn't an intrinsic yet in CTP due to lack of time. It will definitely be made into an intrinsic.Anonymous
April 18, 2014
What exactly is meant by "instrinsic"? Does this mean there is canned code that doesn't need to be jitted?Anonymous
April 19, 2014
The comment has been removedAnonymous
April 23, 2014
The comment has been removedAnonymous
April 23, 2014
BTW, if I change the code to be truly length independent like so: Vector<float> vector; int vectorLength = Vector<float>.Length; float[] temp = new float[vectorLength]; for (int i = 0; i < rawData.Length; i += Vector<float>.Length) { int numElements = rawData.Length - i; if (numElements < vectorLength) { float[] rawValues = new float[numElements]; for (int j = 0; j < numElements; j++) { temp[j] = rawData[i + j]; } vector = new Vector<float>(temp); } else { numElements = vectorLength; vector = new Vector<float>(rawData, i); } var result = (vector * vecScaleFactor) + vecOffset; for (int j = 0; j < numElements; j++) { scaledData2[i + j] = result[j]; } }My performance is often worse than the non-vectorized loop. So unless the Vector<T> ctor and CopyTo() methods are updated to handle lengths less than current number of registers, the only performant approach I can see is to ensure my arrays are always a multiple of vector length and to ignore any padding at the end of the array. This sort of vectorization has to be very common, right? Surely there is some canonical implementation documented somewhere? Another thought. Ideally I'd like Vector to just handle this for me. It might very handy to have method like: static void Vectorize(T[] srcArray, T[] dstArray, int index, Func<Vector<T>,Vector<T>> operation)Then my loop becomes: for (int i = 0; i < rawData.Length; i += Vector<float>.Length) { Vector<float>.Vectorize(rawData, scaledData, i, vec => vec * vecScaleFactor + vecOffset): }Even more ideally, Vector<T> could handle type conversions. For instance, AD converter data is stored as integer values or varying widths. To convert the digital quantization value to its analog equivalent you multiply the integer value by a floating point scale factor and then add a floating point offset to compute the final value which is a floating point number. Often the quantization value bit width of the ADC is small - say 8 to 16 bits. If you have digitized lots of data (GBs) it is more efficient to store the data in a byte or short array than in a double array. Hence the desire to do Vector<byte> * Vector<double> + Vector<double> gives Vector<double>.Anonymous
April 23, 2014
"My performance is often worse than the non-vectorized loop."There's really no point in talking about the performance of this kind of code until CopyTo becomes an intrinsic. Extracting the elements of a vector to store them into the float array has a significant performance penalty."This sort of vectorization has to be very common, right? Surely there is some canonical implementation documented somewhere?"The usual approach is to have a second scalar loop that deals with the remaining array elements. A native C/C++ compiler (VC++ for example) generates something like the following code:int i = 0;for (; i <= rawData.Length - Vector<float>.Length; i += Vector<float>.Length) { var v = new Vector<float>(rawData, i); v = v * scale + offset; v.CopyTo(rawData, i);}for (; i < rawData.Length; i++) { rawData[i] = rawData[i] * scale[0] + offset[0];}"It might very handy to have method like:..."Probably not, at least in the case of " * scale + offset". The delegate call would cost you an arm and a leg in such cases. This would work properly only if they ever decide to inline delegate calls.Using vectors for the scalar loop like you are trying to do is not ideal because packing scalars into a vector is not exactly efficient the same way that extracting values from a vector is not efficient."Even more ideally, Vector<T> could handle type conversions."That would be cool but it's quite tricky. For example a Vector<int> could be converted to a Vector<float> but what about a Vector<short> to Vector<float>? A Vector<short> could have 8 elements and a Vector<float> could have only 4.Anonymous
April 23, 2014
@MikeDanes - thanks for the reply! All good points for me to consider.Anonymous
May 05, 2014
Kevin, when you say add a reference in the class constructor, are you talking about a static method constructor or the parameterless constructor?Anonymous
May 07, 2014
@Keith & Mike:We're prepping an update that includes an intrinsified (that's clearly not a real word) version of .CopyTo. The edge-of-the-array cases are still being discussed. I really like the Vector<T>.Vectorize usability, but it would require a tremendous amount of work to get it all to actually work properly. I like to think most of it could be done at compile time, not JIT/Runtime, but we're just really getting started here...Anonymous
May 07, 2014
The comment has been removedAnonymous
May 07, 2015
Is it possible to do shuffle operations with this? I was looking to port a series of fast Y'CbCr (Y'UV) packed/planar and colorspace conversion functions I wrote with SSE2/AVX2 intrinsics in C++. They can convert a 1080p 24bpp framebuffer nearly as fast as it can be copied (sans conversion) with memcpy. Without shuffles, it'd be many times slower.I've written a research video codec in C# that I'd like to actually be able to use one day. Yea, I'm a glutton for punishment, apparently. ;PAnonymous
May 28, 2015
jclary - I would love to see support for shuffles in our vector types. I think that for the fixed-size types (e.g. Vector4), the API design could be fairly straight forward (e.g. Vector4.WZYX() might reverse the elements). However it would be more challenging to design a general purpose API for shuffling Vector<T>. There is an issue on the corefx github repo: github.com/.../1168 that you could add comments to - and I would especially appreciate hearing your specific requirements.Anonymous
August 07, 2015
Hello speed geeks. Is there a roadmap for incorporating the SIMD support into the .Net runtimes and native support in Visual Studio? Cheers, Rob