The Parallelism Operator (aka Exchange)
As I noted in my Introduction to Parallel Query Execution post, the parallelism (or exchange) iterator actually implements parallelism in query execution. The optimizer places exchanges at the boundaries between threads; the exchange moves the rows between the threads.
The iterator that’s really two iterators
The exchange iterator is unique in that it is really two iterators: a producer and a consumer. We place the producer at the root of a query sub-tree (often called a branch). The producer reads input rows from its sub-tree, assembles the rows into packets, and routes these packets the appropriate consumers. We place the consumer at the leaf of the next query sub-tree. The consumer receives packets from its producer(s), removes the rows from these packets, and returns the rows to its parent iterator. For example, a repartition exchange running at degree of parallelism (DOP) two, consists of two producers and two consumers:
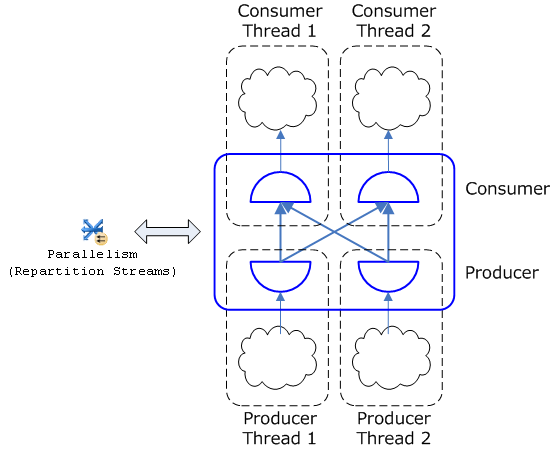
Note that while the data flow between most iterators is pull based (an iterator calls GetRow on its child when it is ready for another row), the data flow in between an exchange producer and consumer is push based. That is, the producer fills a packet with rows and “pushes” it to the consumer. This model allows the producer and consumer threads to execute independently. (We do have flow control to prevent a fast producer from flooding a slow consumer with excessive packets.)
How many different types of exchanges are there?
Exchanges can be classified in three different ways.
First, we can classify exchanges based on the number of producer and/or consumer threads:
| Type | # producer threads | # consumer threads |
|---|---|---|
| Gather Streams | DOP | 1 |
| Repartition Streams | DOP | DOP |
| Distribute Streams | 1 | DOP |
A gather streams exchange is often called a “start parallelism” exchange since the operators above it run serially while the operators below it run in parallel. The root exchange in any parallel plan is always a gather exchange since the results of any query plan must ultimately be funneled back to the single connection thread to be returned to the client. A distribute streams exchange is often called a “stop parallelism” exchange. It is the opposite of a gather streams exchange: the operators above a distribute steams exchange run in parallel while the operators below it run serially.
Second, we can classify exchanges based on how they route rows from the producer to the consumer. We refer to this property as the “partitioning type” of the exchange. Partitioning type only makes sense for a repartition or a distribute streams exchange since there is only one way to route rows in a gather exchange: to the single consumer thread. SQL Server supports the following partitioning types:
| Partitioning Type | Description |
|---|---|
| Broadcast | Send all rows to all consumer threads. |
| Round Robin | Send each packet of rows to the next consumer thread in sequence. |
| Hash | Determine where to send each row by evaluating a hash function on one or more columns in the row. |
| Range | Determine where to send each row by evaluating a range function on one column in the row. (A range function splits the total possible set of values into a set of continguous ranges. This partition type is rare and is used only by certain parallel index build plans.) |
| Demand | Send the next row to the next consumer that asks. This partition type is the only type of exchange that uses a pull rather a push model for data flow and is used only in query plans with partitioned tables. |
Third, we can classify exchanges as merging (or order preserving) and non-merging (or non-order preserving). The consumer in a merging exchange ensures that rows from multiple producers are returned in a sorted order. (The rows must already be in this sorted order at the producer; the merging exchange does not actually sort.) A merging exchange only make sense for a gather or a repartition streams exchange; with a distribute streams exchange, there is only one producer and, thus, only one stream of rows and nothing to merge at each consumer.
Showplan
SQL Server includes all of the above properties in showplan (graphical, text, and XML).
Speaking of showplan, in graphical showplan you can also tell at a glance which operators are running in parallel (i.e., which operators are between a start exchange and a stop exchange) by looking for a little parallelism symbol on the operator icons:

In my next post about parallelism, I’ll begin to explore some parallel query plans and demonstrate the different types of exchanges in action.
Comments
Anonymous
January 18, 2008
In some of my past posts, I've discussed how SQL Server implements aggregation including the stream aggregateAnonymous
February 06, 2008
Great blog Craig. I have couple of questions around the Parallelism Exchanges.Every physical operator in my plan is done in parallel (arrows) does it mean that i should have Exchanges in my plan (probably between every two operators, obviously NO. Need a little bit explanation) ?For example what's the meaning of this plan ? select<-Top<-Parallelism(Gather)<-Strem Aggregate<-Parallelism(Repartition)<-Compute Scalar<-Sort<-TableScanHow is it different from this ?select<-Top<-Parallelism(Gather)<-Strem Aggregate<-Sort<-Parallelism(Repartition)<-TableScanAnonymous
February 07, 2008
Yes, if a plan includes operators with the parallel or arrows icon, there must be exchanges in the plan. The arrows icon on an operator indicates that there are multiple threads running the operator. This can only occur if the operator is below a gather or repartition streams exchange and is NOT below a distribute streams exchange. However, the operator need not be immediately below an exchange and there need not be an exchange between every pair of operators. There can be multiple operators below a single exchange that all run in parallel and in the same set of threads. The two plans are very similar. In the first plan the repartition exchange must merge the results of the sort while in the second plan it need not merge. Both plans are valid and the choice of where to place the exchanges in this case is most likely cost based.