Основы построения In-Memory СУБД SQL Server 2014. Hash индексы.
Мы продолжаем наш рассказ о новой, оптимизированной для исполнения в оперативной памяти, СУБД SQL 2014 (In-Memory Database).
В предыдущем блоге мы рассказали об основах физического размещения данных на диске и в оперативной памяти (https://blogs.technet.com/b/sqlruteam/archive/2014/03/28/sql2014_5f00_memory_5f00_optimized_5f00_rdbms_5f00_overview_5f00_physical_5f00_structure.aspx).
Текущий блог будет посвящен Hash-индексам, лежащим в основе хранения и доступа к данным в этой СУБД.
Основы хеширования.
В начале обратимся к Википедии, для того, что бы понять, что такое хеширование. (https://ru.wikipedia.org/wiki/%D0%A5%D0%B5%D1%88%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5).
"Хеширование (иногда «хэширование» , англ. hashing) — преобразование по детерминированному алгоритму входного массива данных произвольной длины в выходную битовую строку фиксированной длины. Такие преобразования также называются хеш-функциями или функциями свёртки , а их результаты называют хешем , хеш-кодом или сводкой сообщения (англ. message digest).
В общем случае однозначного соответствия между исходными данными и хеш-кодом нет в силу того, что количество значений хеш-функций меньше, чем вариантов входного массива; существует множество массивов с разным содержимым, но дающих одинаковые хеш-коды, эта ситуация называется хеш-коллизией. Вероятность возникновения коллизий играет немаловажную роль в оценке качества хеш-функций."
Хорошая хеш-функция должна удовлетворять двум свойствам:
-
- Быстро вычисляться;
- Минимизировать количество коллизий
Существует большое количество алгоритмов хеширования, как интернациональных, так и принятых только в одной стране. Например интернациональные алгоритмы пришедшие в Россию вместе с продуктами Microsoft: MD5, SHA1, SHA256, SHA384. Алгоритмы принятые в России ГОСТ Р 34.11-94, ГОСТ Р 34.11-2012.
Hash-индексы
В отличии от стандартной СУБД (Disk based) где страницы, принадлежащие одной таблице, должны быть связаны при помощи IAM, строки в таблицах In-Memory database обязательно должны быть связаны при помощи Hash-индексов. Таким образом In-Memory optimized таблицы должны иметь хотя бы один Hash-индекс.
Hash-индексы используют детерминистическую функцию для построения hash-значения. Т.е. эта функция при подаче на вход одинаковых значений гарантировано сгенерирует один и тот же hash.
Ниже показан пример hash-индекса, который строится на основе количества символов в строке. (Данный пример показан для простоты и не используется в реальных системах.) Hash-индекс построен на основе Имени (поле Name). Если строки, на основе которых строится индекс уникальны, то каждый hash-индекс будет ссылаться только на одну строку, если строки не уникальны, или размер hash-таблицы мал для отображения всех строк (размер таблицы меньше чем кардинальность набора данных), то один hash-индекс указывает на цепочку строк.
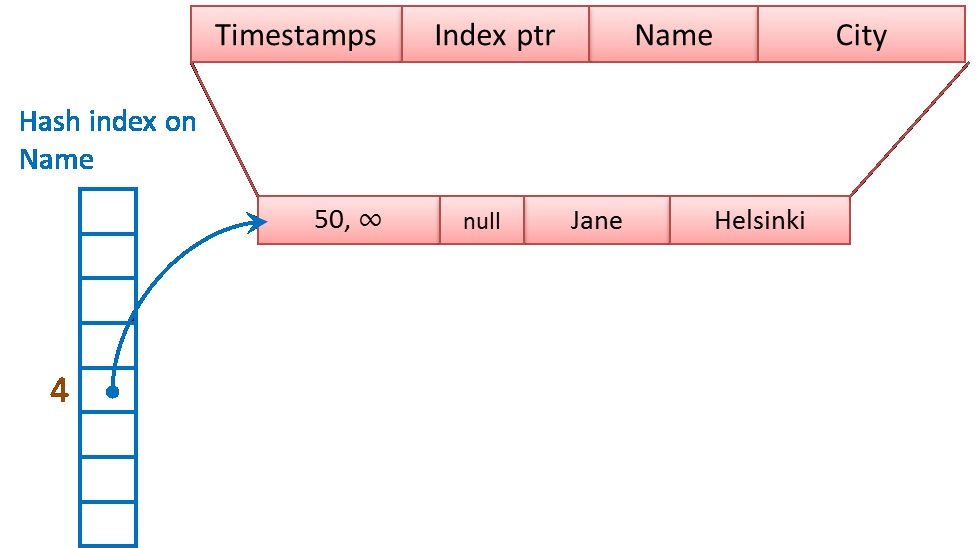
При добавлении строки, порождающей тот же hash она будет связана в цепочку, как показано на рисунке ниже.
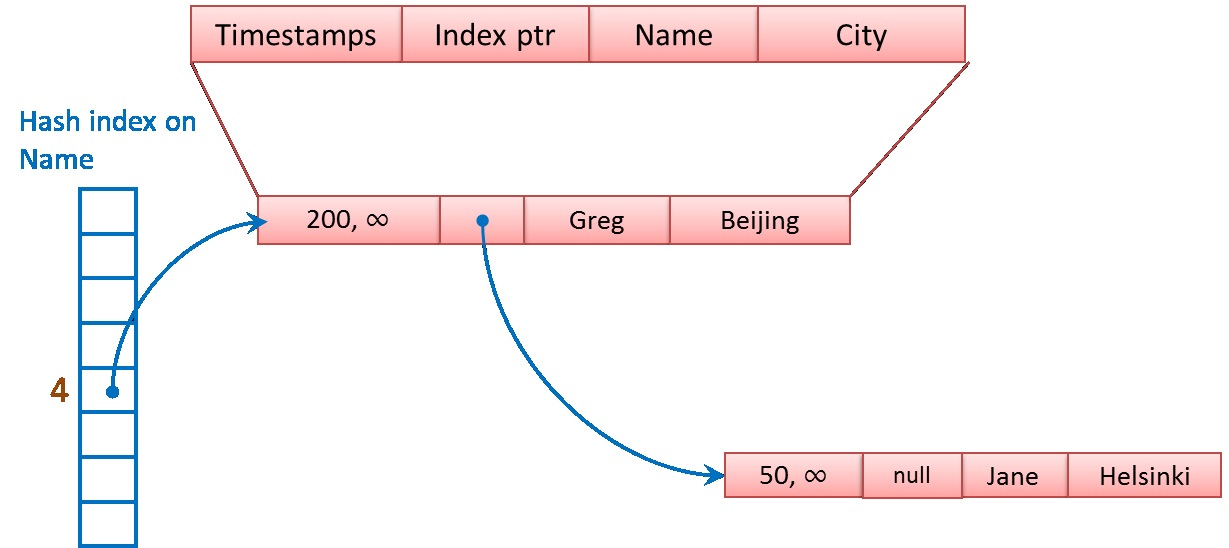
Размер hash-таблицы указывается при создании таблицы. Он указывается в количестве значений hash-ключей. Указав чрезмерный размер hash-таблицы (значительно больше чем планируемое количество уникальных значений в таблице) вы резервируете оперативную память, которая не может быть использована и будет потеряна для системы. Однако, указав недостаточный размер hash-таблицы, вы получите ситуацию показанную на рисунке выше, при которой сервер будет вынужден двигаться по цепочке ссылок, ища нужную запись.
Что произойдет, если мы будем вставлять строку с именем содержащем 3.5 буквы (хотя это невозможно, но для примера представьте себе). При вставке такой строки SQL Server должен размещать ее либо в цепочке строк соответствующий значению 3, либо значению 4. Т.е. имеет место hash-коллизия. Как SQL Server поступает в этом случае? В таком случае он будет балансировать систему, что бы длины цепочек были приблизительно одинаковы. Т.е. одна строка может попасть в цепочку строк, соответствующую значению 3, а вторая, значению 4.
Для балансировки используется Poison-алгоритм. Суть которого состоит в том, что если вы пытаетесь распределить N-значений ключей среди M-значений hash-функций, то приблизительно 1/3 ячеек будет пустой, приблизительно 1/3 ячеек будет содержать по одному значению, приблизительно 1/3 ячеек будет содержать по два значения, и малая часть будет содержать два и более значения.
Таким образом наличие hash-коллизии приводит к увеличению операций чтения, которые должна сделать система для выборки строк, поскольку будут считываться строки из нескольких hash-ключей.
Как изменится структура таблицы если добавить еще один hash-индекс?
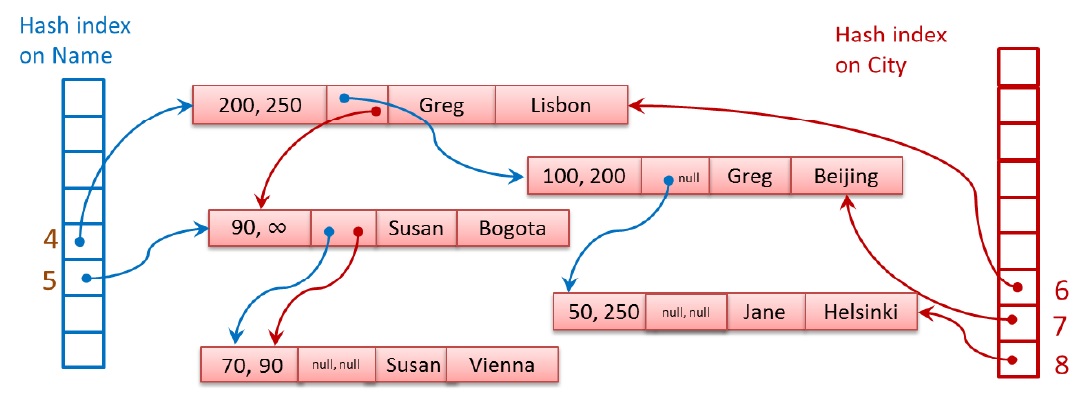
На рисунке показано добавление нового индекса по полю город. Здесь также показана ситуация, когда произошло обновление поля City в строке с полем Name "Susan". Обратите внимание на появление новой строки с временной меткой "90, OO". Эта строка с момента времени 90 становиться актуальной, а предыдущая с меткой времени "70, 90" не актуальной, информация о ней помещается в Delta-файл и со временем она будет удалена. Последняя строка в цепочке будет содержать NULL в поле индекса. Если в данной ситуации вы выполните запрос SELECT * FROM t1 WHERE City='Bogota', то SQL Server будет вынужден считать две строки: строку "Lisbon" и строку "Bogota", но возвращена будет только одна, соответствующая критерию поиска. Такое поведение обусловлено наличием hash коллизии, поскольку оба названия городов содержат по 6 букв (мы договорились, что для упрощения мы будем в качестве hash-функции использовать количество букв в поле).
Необходимо помнить о том, что если вы создаете композитный (состоящий из нескольких столбцов) hash-индекс, то при выполнении поиска, вам необходимо указать (в качестве критерия поиска) все столбцы, входящие в этот индекс, поскольку поиск по частичному hash-значению невозможен.
Например. Если вы построили hash-индекс по LastName, FirstName, MiddleName, то при выполнении запроса вам необходимо указать все три значения в операторе WHERE. Еще одна проблема (особенность) hash-индексов, с их помощью невозможен поиск по диапазону значений.
Для выполнения поиска по диапазону значений в In-Memory database SQL 2014 используются специальные Bw-tree индексы, которые внешне схожи со стандартными B-tree индексами классической СУБД, но отличаются по ряду свойств. Но о них пойдет рассказ в нашем следующем блоге.
Александр Каленик, Senior Premier Field Engineer (PFE), MSFT (Russia)