Query_hash и Query_plan_hash, что в этих числах? Часть первая.
Добрый день коллеги.
Работая недавно у одного из заказчиков я обнаружил достаточно интересное поведение системы, что сподвигло меня к написанию данной статьи, которая, возможно, будет интересна и полезна многим.
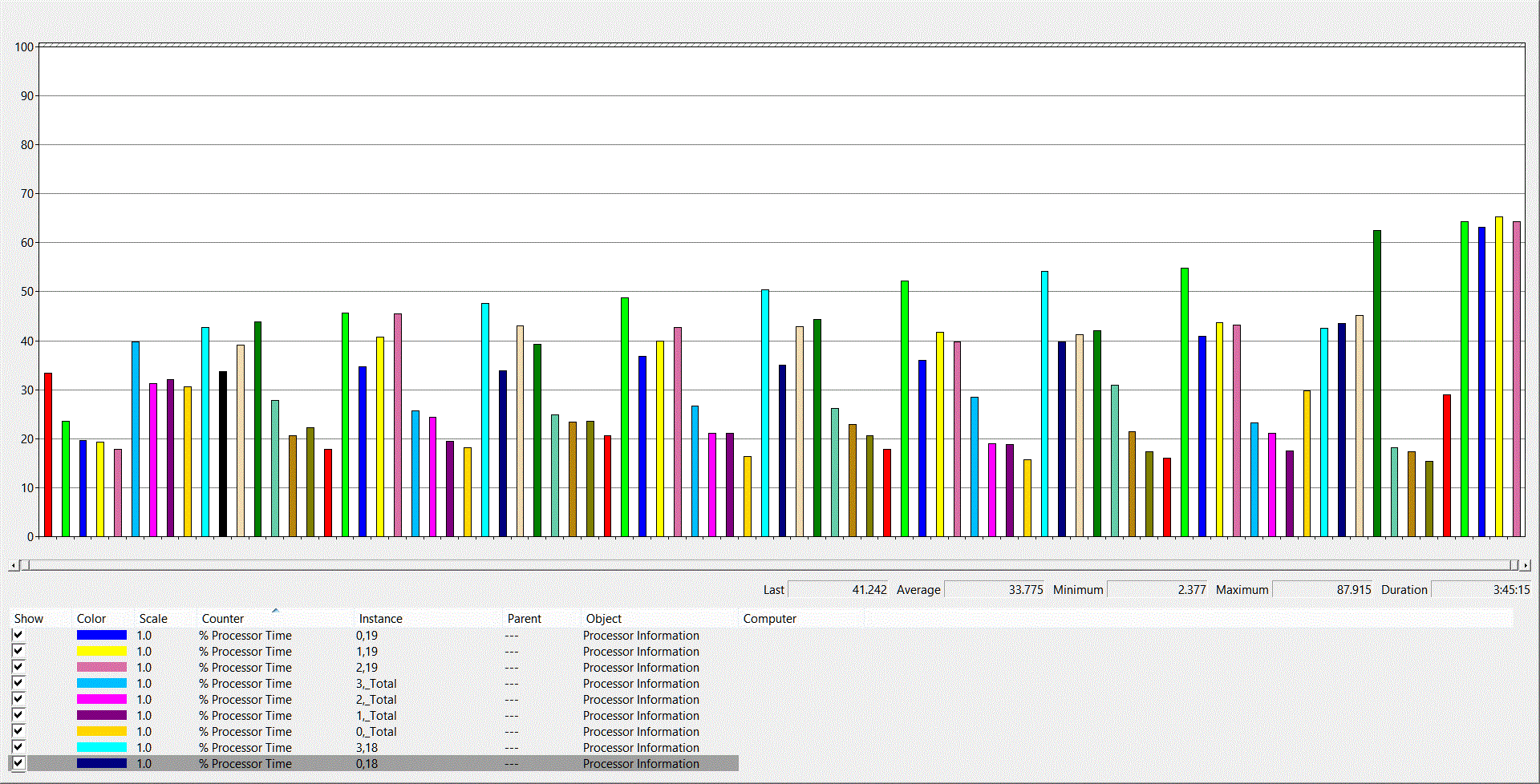
При анализе загруженности процессоров на сервере клиента я обнаружил, что средняя нагрузка на них составляет до 35…40%%, что в общем-то нормально. Странно, что такая нагрузка присутствует на 80-ти процессорной системе всего при 580 Batch Requests/sec.
{kind=link}
Из моего предыдущего блога (https://blogs.technet.com/b/sqlruteam/archive/2014/01/12/server.aspx) известно, что основными источниками нагрузки на процессоры являются операции компиляции, сортировки и хеширования.
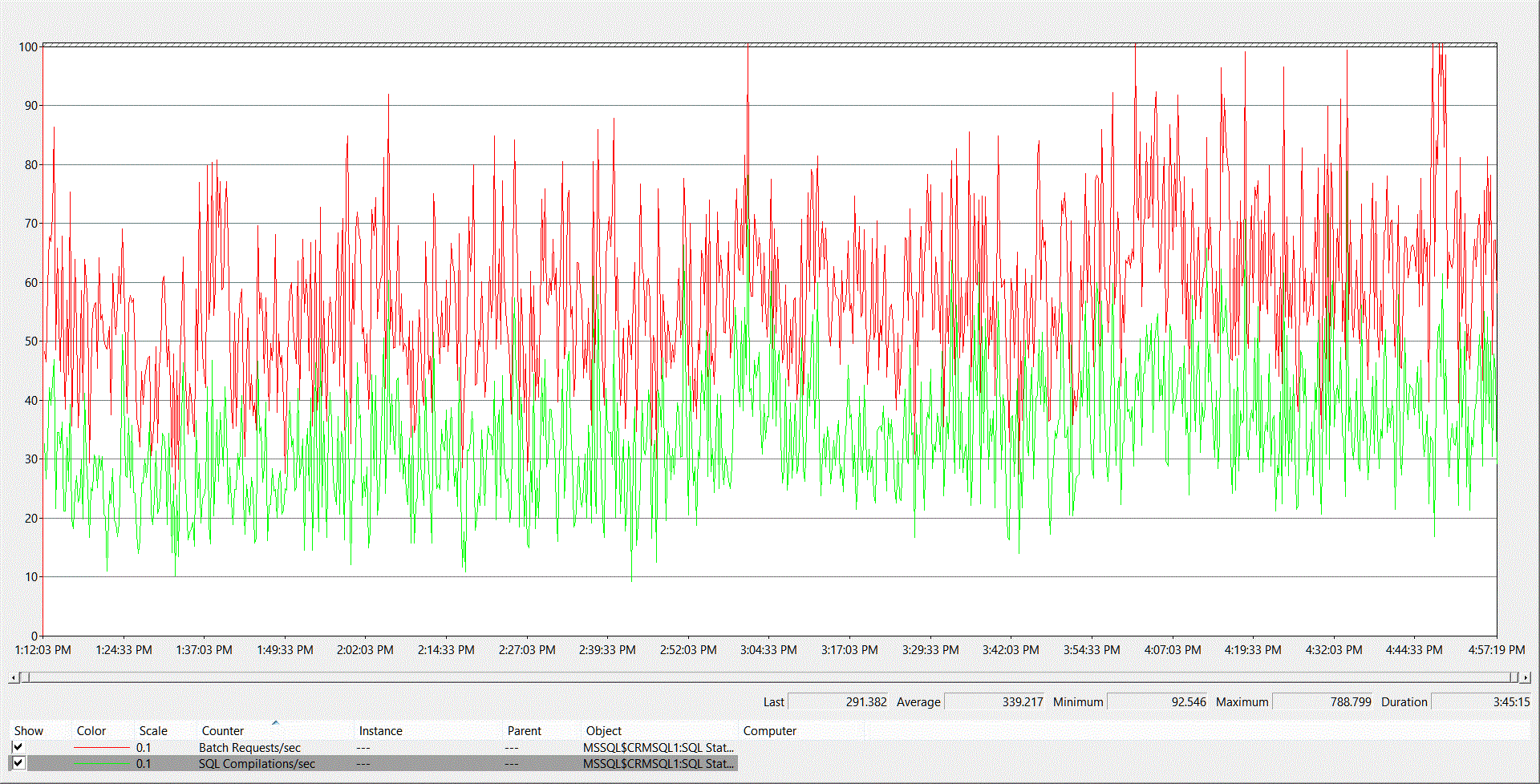
В данном случае причиной нагрузки на процессоры оказалось огромное количество компиляций, превышающее норму в пять раз. Т.е. на 580 Batch Requests/sec выполняется 339 компиляций, при норме не более 58.
Анализ содержимого процедурного кэша показал, что огромное количество одинаковых по коду запросов имеют записи в процедурном кэше. Как видно на рисунке ниже некоторые планы повторяются по 200 и более раз. Для получения этих данных я воспользовался этим "волшебным" числом "query_hash".
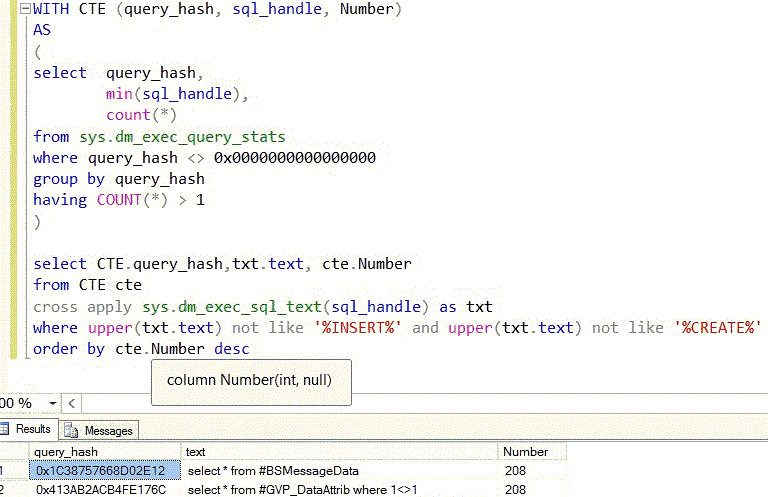
За счет многократного повторения запросов израсходовано дополнительно 62 ГБ оперативной памяти. Как видно из рисунка ниже если бы планы выполнения многократно не повторялись, то для их размещения понадобилось бы 20 ГБ вместо 82 ГБ.
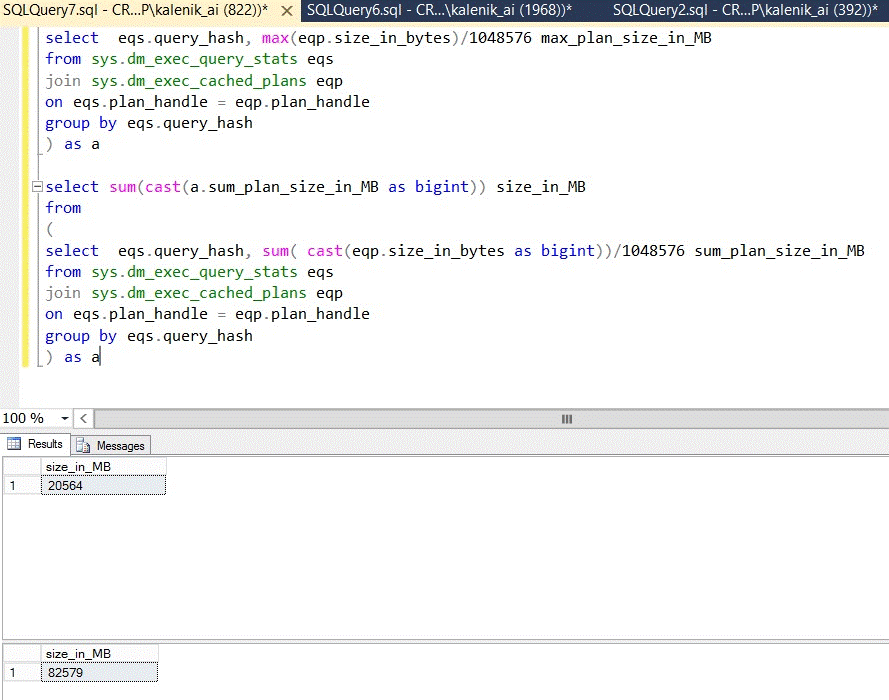
Собственно таких "волшебных" числа два, это - query_hash и query_plan_hash. Появились эти числа в SQL Server 2008 и именно ими можно пользоваться для оптимизации использования процедурного кэша и уменьшения компиляции и нагрузки на процессор.
Как воспользоваться этими новыми возможностями мы рассмотрим в нашем следующем блоге.
Александр Каленик, Senior Premier Field Engineer (PFE), MSFT (Russia)