Azure Data Studio で Jupyter Notebook を使用する
重要
Azure Data Studio は、2026 年 2 月 28 日に廃止されます。 Visual Studio Code を使用することをお勧めします。 Visual Studio Code への移行の詳細については、「Azure Data Studio の概要」を参照してください。
適用対象:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Jupyter Notebook はオープン ソースの Web アプリケーションであり、ライブ コード、数式、視覚化、説明テキストを含むドキュメントを作成して共有するために使用できます。 用途には、データのクリーニングと変換、数値シミュレーション、統計モデリング、データの視覚化、機械学習などが含まれています。
この記事では、Azure Data Studio の最新リリースで新しいノートブックを作成する方法と、異なるカーネルを使用して独自のノートブックの作成を開始する方法について説明します。
Azure Data Studio のノートブックの概要については、次の 5 分間の短いビデオをご覧ください。
ノートブックを作成する
新しいノートブックを作成するには、複数の方法があります。 いずれの場合でも、Notebook-1.ipynb という名前の新しいファイルが開きます。
Azure Data Studio の [ファイル] メニューに移動し、 [新しいノートブック] を選択します。
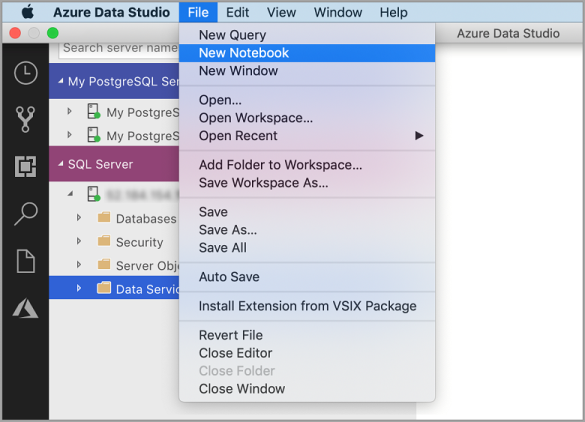
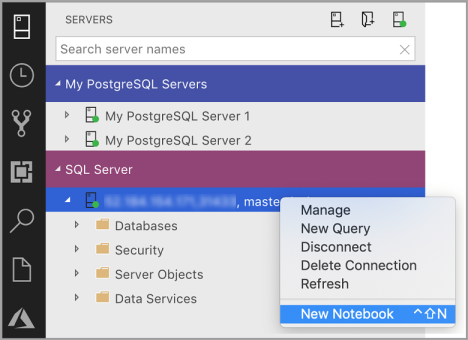
[SQL Server] 接続を右クリックし、 [新しいノートブック] を選択します。
コマンド パレットを開き (Ctrl + Shift + P キー)、「新しいノートブック」と入力し、 [新しいノートブック] コマンドを選択します。

カーネルに接続する
Azure Data Studio のノートブックは、SQL Server、Python、PySpark など、さまざまなカーネルをサポートしています。 各カーネルは、ノートブックのコード セルで異なる言語をサポートしています。 たとえば、SQL Server カーネルに接続すると、ノートブックのコード セルには T-SQL ステートメントを入力して実行できます。
[アタッチ先] には、カーネルのコンテキストを指定します。 たとえば、SQL カーネルを使用している場合は、任意の SQL Server インスタンスにアタッチすることができます。 Python3 カーネルを使用している場合は、localhost にアタッチし、そのカーネルをローカルの Python 開発に使用することができます。
また、SQL カーネルを使用して、PostgreSQL サーバー インスタンスに接続することもできます。 あなたが PostgreSQL 開発者であり、ノートブックを PostgreSQL サーバーに接続する場合は、Azure Data Studio 拡張機能 Marketplace で PostgreSQL 拡張機能をダウンロードし、PostgreSQL サーバーに接続します。
SQL Server 2019 ビッグ データ クラスターに接続している場合、既定の [アタッチ先] はクラスターのエンド ポイントです。 クラスターの Spark コンピューティングを使用して、Python、Scala、および R コードを送信できます。
| カーネル | 説明 |
|---|---|
| SQL カーネル | リレーショナル データベースを対象とした SQL コードを記述します。 |
| PySpark3 と PySpark カーネル | クラスターから Spark コンピューティングを使用して Python コードを作成します。 |
| Spark カーネル | クラスターから Spark コンピューティングを使用して Scala および R コードを作成します。 |
| Python カーネル | ローカル開発用の Python コードを作成します。 |
特定のカーネルの詳細については、以下を参照してください。
- SQL Server ノートブックを作成して実行する
- Python ノートブックを作成して実行する
- Azure Data Studio の Kqlmagic 拡張機能 - これにより、Python カーネルの機能が拡張されます
コード セルを追加する
コード セルを使用すると、ノートブック内で対話形式でコードを実行できます。
ツール バーの [+ セル] コマンドをクリックし、 [コード セル] を選択して、新しいコード セルを追加します。 現在選択されているセルの後に新しいコード セルが追加されます。
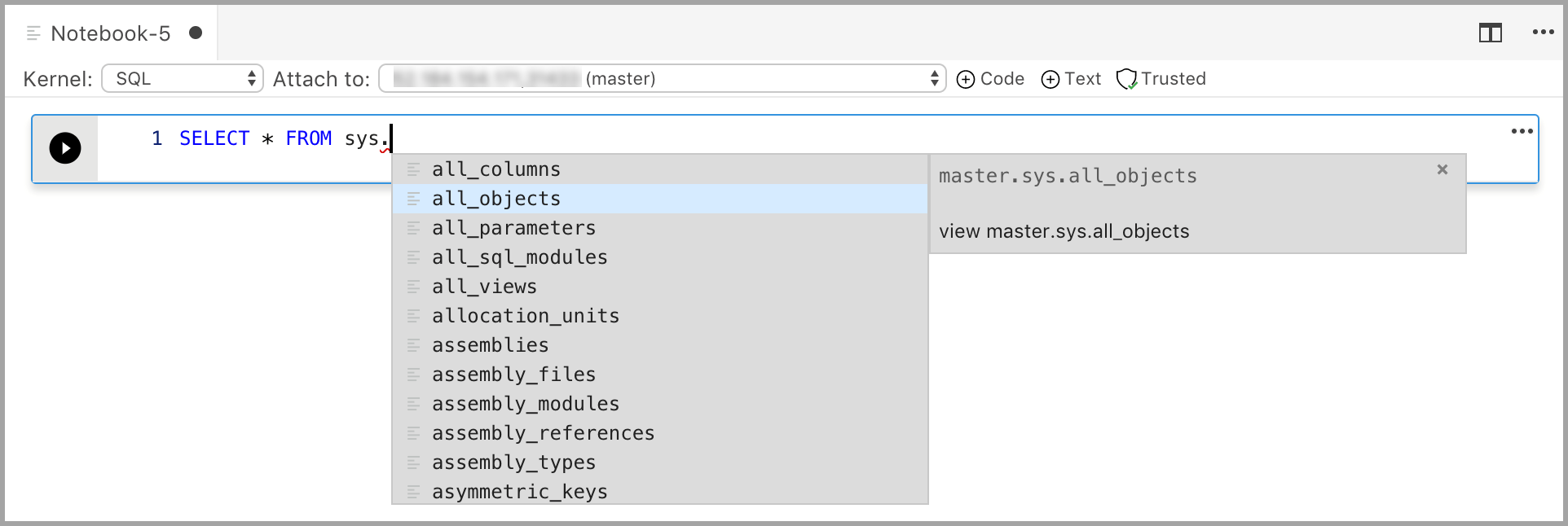
選択したカーネルのセルにコードを入力します。 たとえば、SQL カーネルを使用している場合は、コード セルに T-SQL コマンドを入力できます。
SQL カーネルでコードの入力は、SQL クエリ エディターの場合と似ています。 コード セルは最新の SQL コーディング エクスペリエンスをサポートし、豊富な SQL エディター、IntelliSense、組み込みのコード スニペットなどの組み込み機能を備えています。 コード スニペットを使用すると、データベース、テーブル、ビュー、ストアド プロシージャなどを作成するための適切な SQL 構文を生成したり、既存のデータベース オブジェクトを更新したりできます。 開発またはテストを目的としたデータベースのコピーをすばやく作成したり、スクリプトを生成および実行したりするには、コード スニペットを使用します。
テキスト セルを追加する
テキスト セルを使用すると、コード セルの間に Markdown テキスト ブロックを追加して、コードをドキュメント化することができます。
ツール バーの [+ セル] コマンドをクリックし、 [テキスト セル] を選択して、新しいテキスト セルを追加します。
Markdown テキストを入力できる編集モードでセルが起動します。 入力すると、プレビューが下に表示されます。
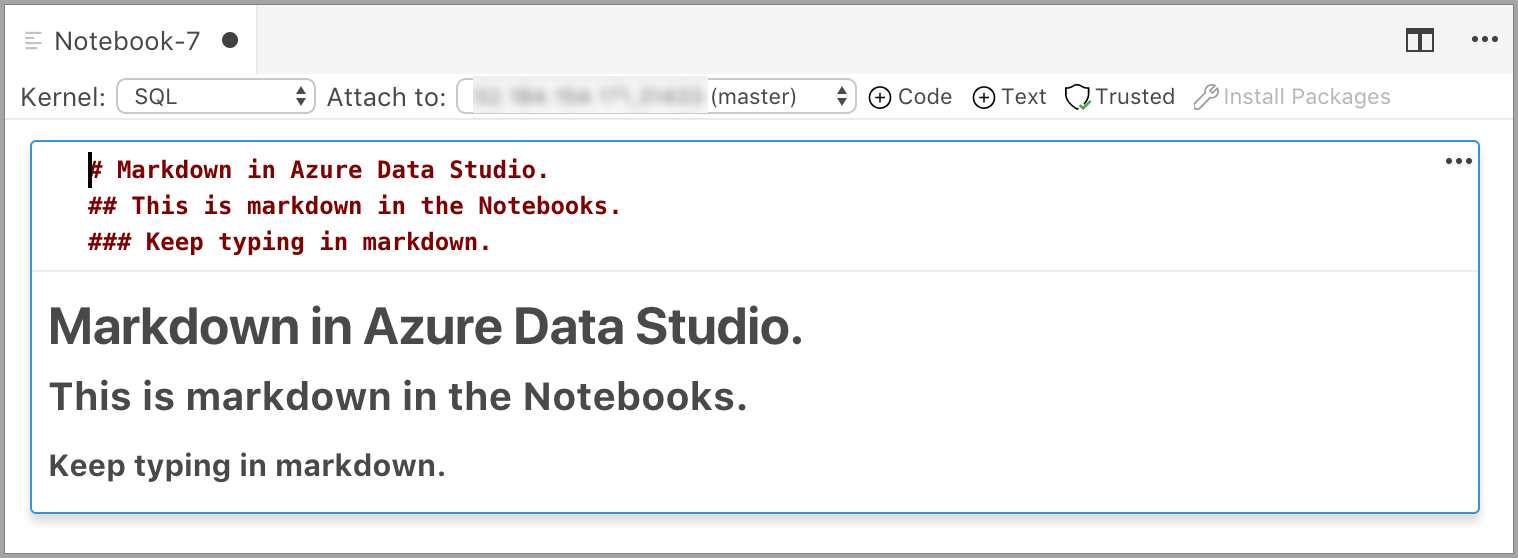
テキスト セルの外側を選択すると、Markdown テキストが表示されます。
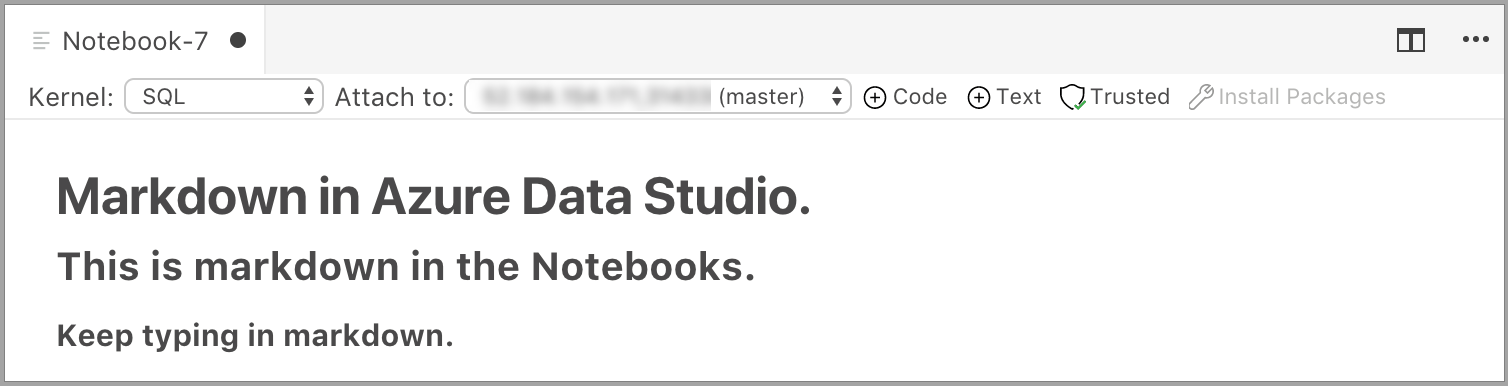
テキスト セルをもう一度クリックすると、編集モードに変わります。
セルを実行する
1 つのセルを実行するには、セルの左側にある [セルの実行] (黒丸の矢印) をクリックするか、セルを選択して F5 キーを押します。 ツール バーの [すべて実行] をクリックすると、ノートブックのすべてのセルを実行できます。セルは一度に 1 つずつ実行され、セルでエラーが発生すると実行が停止します。
セルの結果がセルの下に表示されます。 ノートブックで実行されたすべてのセルの結果を消去するには、ツール バーの [結果をクリア] ボタンを選択します。
ノートブックを保存する
ノートブックを保存するには、次のいずれかの操作を実行します。
- Ctrl + S キーを押す
- [ファイル] メニューから [保存] を選択する
- [ファイル] メニューから [名前を付けて保存] を選択する
- [ファイル] メニューから [すべて保存] を選択する - 開いているすべてのノートブックが保存されます
- コマンドパレットで、「ファイル:保存」と入力します。
ノートブックは .ipynb ファイルとして保存されます。
"信頼されている" と "信頼されていない"
Azure Data Studio で開いているノートブックは、既定で [信頼済み] に設定されています。
他のソースからノートブックを開くと、 [信頼されていない] モードで開かれます。後で [信頼済み] に設定することができます。
例
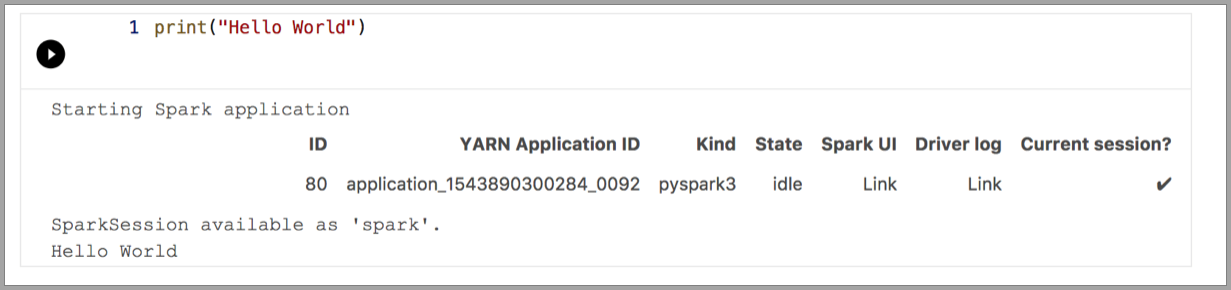
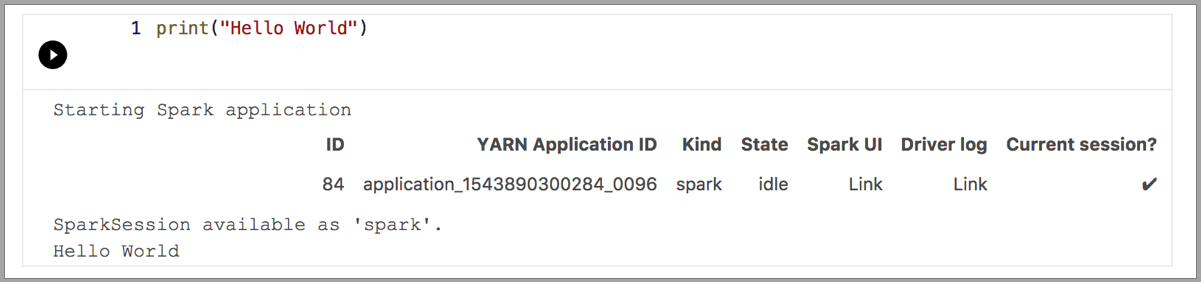
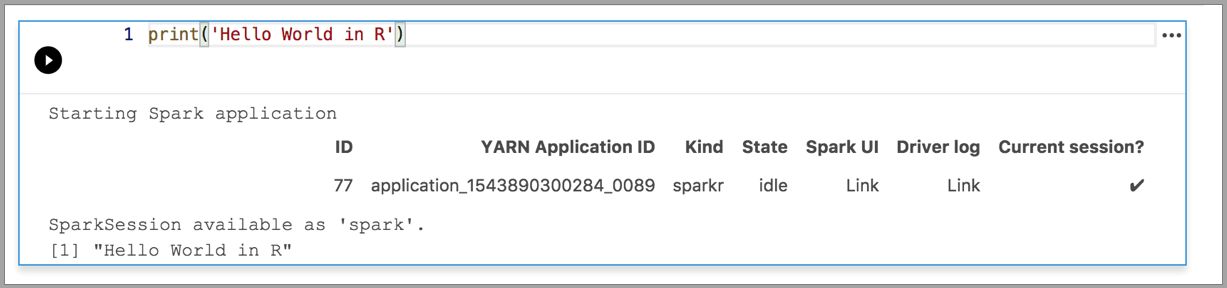
次の例は、さまざまなカーネルを使用して簡単な "Hello World" コマンドを実行する方法を示しています。 カーネルを選択し、セルにコード例を入力して、 [セルの実行] をクリックします。
Pyspark
Spark | Scala 言語
Spark | R 言語
Python 3
