高可用性を得るために複数の Azure Stack Hub リージョンで n 層アプリケーションを実行する
このリファレンス アーキテクチャは、可用性と堅牢なディザスター リカバリー インフラストラクチャを実現するために、複数の Azure Stack Hub リージョンで n 層アプリケーションを実行するための一連の実証済みのプラクティスを示しています。 このドキュメントでは、高可用性を実現するために Traffic Manager が使用されていますが、お使いの環境に Traffic Manager が適していない場合は、可用性の高いロード バランサーのペアに置き換えることもできます。
注意
以下のアーキテクチャで使用されている Traffic Manager は Azure で構成する必要があり、Traffic Manager プロファイルの構成に使用されるエンドポイントは、パブリックにルーティング可能な IP である必要があります。
Architecture
このアーキテクチャは、「SQL Server を使用した n 層アプリケーション」に示されているアーキテクチャの上に構築されています。
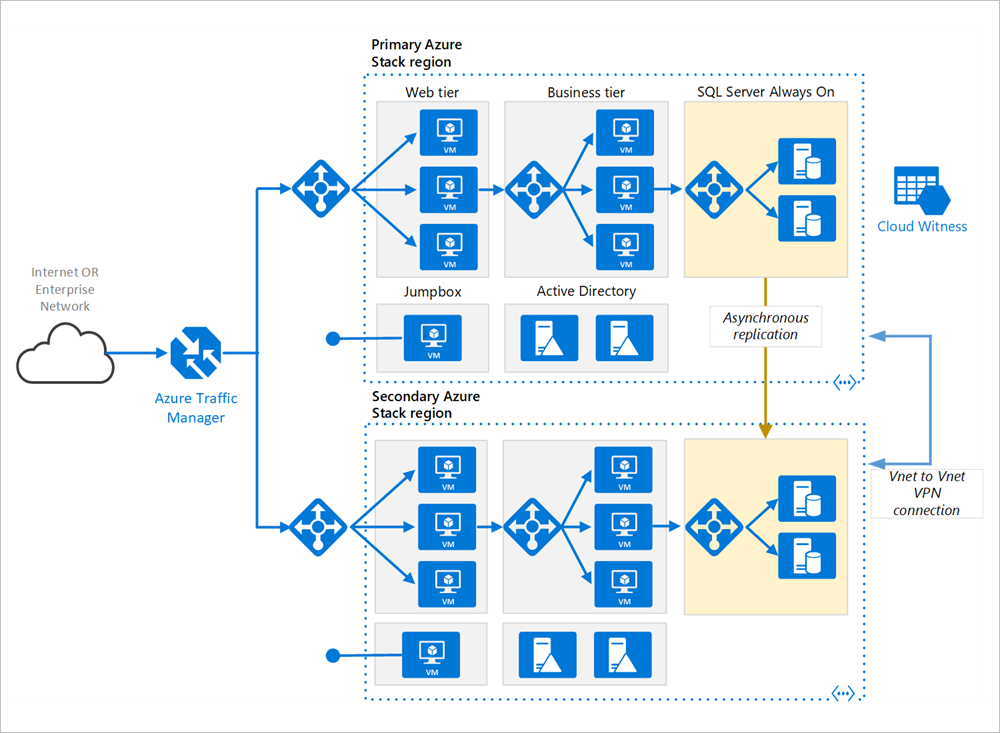
プライマリ リージョンとセカンダリ リージョン。 2 つのリージョンを使用して高可用性を実現します。 1 つはプライマリ リージョンであり、 他方のリージョンはフェールオーバー用です。
Azure Traffic Manager。 Traffic Manager では、着信要求がいずれかのリージョンにルーティングされます。 通常の運用中は、プライマリ リージョンに要求をルーティングします。 そのリージョンが使用できなくなった場合、Traffic Manager はセカンダリ リージョンへのフェールオーバーを実行します。 詳細については、「Traffic Manager の構成」を参照してください。
リソース グループ。 プライマリ リージョンとセカンダリ リージョン用に個別のリソース グループを作成します。 これにより、各リージョンをリソースの 1 つのコレクションとして柔軟に管理できます。 たとえば、片方のリージョンの再デプロイを、他方のリージョンをダウンさせずに実行できます。 リソース グループをリンクして、アプリケーション用のすべてのリソースを一覧表示するクエリを実行できるようにします。
仮想ネットワーク。 リージョンごとに個別の仮想ネットワークを作成します。 アドレス空間が重複していないことを確認してください。
SQL Server Always On 可用性グループ。 SQL Server を使用している場合は、SQL Always On 可用性グループを使用して高可用性を実現することをお勧めします。 両方のリージョンの SQL Server インスタンスを含む単一の可用性グループを作成します。
VNET 間 VPN 接続。 Azure Stack Hub で VNET ピアリングがまだ使用できないため、2 つの VNET を接続するには、VNET 間 VPN 接続を使用します。 詳細については、Azure Stack Hub での VNET 対 VNET に関するページを参照してください。
Recommendations
マルチリージョン アーキテクチャは、単一のリージョンにデプロイするよりも高い可用性を提供できます。 地域的な停止がプライマリ リージョンに影響する場合は、Traffic Manager を使用して、セカンダリ リージョンにフェールオーバーできます。 このアーキテクチャは、アプリケーションの個々のサブシステムが失敗した場合にも役立ちます。
リージョン間で高可用性を実現する一般的な方法はいくつかあります。
アクティブ/パッシブ (ホット スタンバイ) 。 トラフィックが片方のリージョンにルーティングされている間、他方のリージョンは、ホット スタンバイ状態で待機します。 ホット スタンバイとは、セカンダリ リージョン内の VM が割り当て済みであり、常に実行されていることを意味します。
アクティブ/パッシブ (コールド スタンバイ) 。 トラフィックが片方のリージョンにルーティングされている間、他方のリージョンは、コールド スタンバイ状態で待機します。 コールド スタンバイとは、セカンダリ リージョン内の VM がフェールオーバーが必要になるまで割り当てられないことを意味します。 この方法のほうが実行コストは低くなりますが、ほとんどの場合、障害発生時にオンラインになるまでの時間が長くなります。
アクティブ/アクティブ。 両方のリージョンがアクティブであり、要求はそれらの間で負荷分散されます。 片方のリージョンが使用できなくなった場合は、ローテーションから外されます。
この参照アーキテクチャでは、Traffic Manager を使用してフェールオーバーを行うアクティブ/パッシブ (ホット スタンバイ) に焦点を当てています。 ホット スタンバイ用の少数の VM をデプロイした後、必要に応じてスケール アウトできます。
Traffic Manager の構成
Traffic Manager を構成するときは、次の点を検討してください。
ルーティング。 Traffic Manager では、複数のルーティング アルゴリズムがサポートされています。 この記事で説明するシナリオでは、"優先度による" ルーティング (旧称 "フェールオーバー" ルーティング) を使用します。 この設定では、プライマリ リージョンが到達不能にならない限り、Traffic Manager はプライマリ リージョンにすべての要求を送信します。 到達不能になった時点で、セカンダリ リージョンに自動的にフェールオーバーします。 フェールオーバーのルーティング方法の構成に関する記事を参照してください。
正常性プローブ。 Traffic Manager では、HTTP (または HTTPS) プローブを使用して、各リージョンが使用可能かどうかが監視されます。 プローブは、特定の URL パスの HTTP 200 応答をチェックします。 ベスト プラクティスとして、アプリケーションの全体的な正常性を報告するエンドポイントを作成し、そのエンドポイントを正常性プローブ用に使用します。 これを行わなかった場合、プローブは、アプリケーションの重要な部分で実際には障害が発生しているにもかかわらず、エンドポイントが正常であると報告する可能性があります。 詳細については、「正常性エンドポイントの監視パターン」を参照してください。
Traffic Manager がフェールオーバーを実行すると、クライアントがアプリケーションに到達できない時間が発生します。 この持続時間は、次の要因に影響されます。
正常性プローブが、プライマリ リージョンが到達不能になっていることを検出する必要があります。
DNS サーバーが、IP アドレスのキャッシュされた DNS レコードを更新する必要があります。これは DNS 有効期限 (TTL) に依存します。 TTL の既定値は 300 秒 (5 分) ですが、この値は、Traffic Manager プロファイルを作成するときに構成できます。
詳細については、Traffic Manager の監視に関する記事を参照してください。
Traffic Manager でフェールオーバーを実行する場合は、自動フェールバックを実装するのではなく、手動でフェールバックを実行することをお勧めします。 これを行わなかった場合、リージョン間でアプリケーションが切り替わる状況が発生する可能性があります。 フェールバックする前に、すべてのアプリケーション サブシステムが正常であることを確認します。
Traffic Manager は、既定では自動的にフェールバックすることに注意してください。 これが起こらないようにするには、フェールオーバー イベントの後、手動でプライマリ リージョンの優先度を下げます。 たとえば、プライマリ リージョンの優先度は 1、セカンダリ リージョンの優先度は 2 であるとします。 フェールオーバーした後、プライマリ リージョンの優先度を 3 に設定して、自動フェールバックが起こらないにします。 元に戻す準備ができたら、優先度を 1 に更新します。
次の Azure CLI コマンドでは、優先度が更新されます。
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --priority 3
別の方法は、フェールバックの準備ができるまで、エンドポイントを一時的に無効にすることです。
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --endpoint-status Disabled
フェールオーバーの原因によっては、リソースをリージョン内に再デプロイする必要があります。 フェールバックする前に、運用準備テストを実行します。 このテストでは、以下のような点を検証する必要があります。
VM が正しく構成されている (すべての必要なソフトウェアがインストールされていること、IIS が実行されていることなど)。
アプリケーションのサブシステムが正常である。
機能テスト (たとえば、Web 層からデータベース層に到達可能である)。
SQL Server Always On 可用性グループを構成する
Windows Server 2016 より前に、SQL Server Always On 可用性グループではドメイン コントローラーを必要とし、可用性グループ内のすべてのノードが同じ Active Directory (AD) ドメイン内にある必要があります。
可用性グループを構成するには:
各リージョンに少なくとも 2 つのドメイン コントローラーを配置します。
各ドメイン コントローラーに静的 IP アドレスを指定します。
VPN を作成して、2 つの仮想ネットワーク間で通信できるようにします。
各仮想ネットワークで、DNS サーバーのリストに (両方のリージョンの) ドメイン コントローラーの IP アドレスを追加します。 次の CLI コマンドを使用できます。 詳細については、「DNS サーバーの変更」を参照してください。
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"両方のリージョンの SQL Server インスタンスを含む Windows Server フェールオーバー クラスタリング (WSFC) クラスターを作成します。
プライマリ リージョンとセカンダリ リージョンの SQL Server インスタンスを含む SQL Server Always On 可用性グループを作成します。 手順については、Always On 可用性グループのリモート Azure データセンターへの拡張 (PowerShell)に関する記事を参照してください。
プライマリ レプリカをプライマリ リージョンに配置します。
1 つ以上のセカンダリ レプリカをプライマリ リージョンに配置します。 それらを自動フェールオーバーを伴う同期コミット モードを使用するように構成します。
1 つ以上のセカンダリ レプリカをセカンダリ リージョンに配置します。 パフォーマンス上の理由で、それらは非同期コミットを使用するように構成します (これを行わなかった場合、すべての T-SQL トランザクションがセカンダリ リージョンへのネットワーク上にラウンド トリップで待機する必要があります)。
注意
非同期コミット レプリカでは、自動フェールオーバーはサポートされていません。
可用性に関する考慮事項
複雑な N 層アプリケーションでは、アプリケーション全体をセカンダリ リージョンにレプリケートする必要はない場合があります。 代わりに、ビジネス継続性をサポートするために必要な重要なサブシステムのみをレプリケートできます。
Traffic Manager は、システムの障害ポイントになる可能性があります。 Traffic Manager サービスが失敗すると、クライアントは、ダウンタイム中はアプリケーションにアクセスできなくなります。 「Traffic Manager の SLA」を確認して、Traffic Manager の使用だけで高可用性のビジネス要件が満たされるかどうかを確かめてください。 満たされない場合は、フェールバックとして別のトラフィック管理ソリューションを追加することを検討してください。 Azure Traffic Manager サービスで障害が発生した場合は、他のトラフィック管理サービスを参照するように、DNS の CNAME レコードを変更します (この手順は手動で実行する必要があり、DNS の変更が反映されるまでアプリケーションを使用することはできません)。
SQL Server クラスターでは、2 つのフェールオーバー シナリオを考慮する必要があります。
プライマリ リージョン内のすべての SQL Server データベースのレプリカが失敗する。 これは、たとえば地域的な停止中に発生することがあります。 この場合は、Traffic Manager がフロント エンドで自動的にフェールオーバーを実行する場合でも、可用性グループを手動でフェールオーバーする必要があります。 「Perform a Forced Manual Failover of a SQL Server Availability Group」(SQL Server 可用性グループの強制手動フェールオーバーを実行する) の手順に従います。この記事では、SQL Server 2016 で SQL Server Management Studio、Transact-SQL、または PowerShell を使用して強制フェールオーバーを実行する方法が説明されています。
警告
強制フェールオーバーには、データ損失のリスクがあります。 プライマリ リージョンがオンラインに戻ったら、データベースのスナップショットを取得し、tablediff を使用して差異を検出してください。
Traffic Manager がセカンダリ リージョンへのフェールオーバーを実行するが、SQL Server データベースのプライマリ レプリカが引き続き使用可能である。 たとえば SQL Server VM に影響しない障害がフロント エンド層で発生することがあります。 この場合、インターネット トラフィックはセカンダリ リージョンにルーティングされますが、セカンダリ リージョンは引き続きプライマリ レプリカに接続できます。 ただし、SQL Server の接続がリージョンにまたがるため、待機時間が長くなります。 この状況では、次のように手動フェールオーバーを実行する必要があります。
セカンダリ リージョンの SQL Server データベースのレプリカを一時的に同期コミットに切り替えます。 これにより、フェールオーバー中にデータの損失が発生しないことが保証されます。
そのレプリカにフェールオーバーします。
プライマリ リージョンにフェールバックするときに、設定を非同期コミットに戻します。
管理容易性に関する考慮事項
デプロイを更新するときは、一度に 1 つのリージョンを更新することで、アプリケーションの不適切な構成やエラーによってグローバル エラーが発生する機会を減らします。
システムのエラーに対する回復性をテストします。 テストされる一般的な障害シナリオを次に示します。
VM インスタンスのシャットダウン。
CPU やメモリなどのリソースへの負荷。
ネットワークの切断/遅延。
プロセスのクラッシュ。
証明書の期限切れ。
ハードウェア障害のシミュレート。
ドメイン コントローラー上の DNS サービスのシャットダウン。
回復時間を測定し、ビジネス要件を満たしていることを確認します。 障害モードの組み合わせもテストします。
次のステップ
- Azure のクラウド パターンの詳細については、「Cloud Design Pattern (クラウド設計パターン)」を参照してください。