Docker を使用したカスタム音声テキスト変換コンテナー
カスタム音声テキスト変換コンテナーでは、中間結果を含むリアルタイム音声またはバッチ音声録音を文字起こしします。 Custom Speech ポータルで作成したカスタム モデルを使用できます。 この記事では、カスタム音声テキスト変換コンテナーをダウンロード、インストール、実行する方法について説明します。
前提条件の詳細、コンテナーが実行されていることの検証、同じホスト上での複数コンテナーの実行、切断されたコンテナーの実行については、「Docker を使用して音声コンテナーをインストールして実行する」を参照してください。
コンテナー イメージ
サポートされているすべてのバージョンとロケールのカスタム音声テキスト変換コンテナー イメージは、Microsoft Container Registry (MCR) シンジケートにあります。 azure-cognitive-services/speechservices/ リポジトリ内にあり、custom-speech-to-text という名前が付いています。

完全修飾コンテナー イメージ名は mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text です。 特定のバージョンを追加するか、:latest を追加して最新バージョンを取得します。
| Version | Path |
|---|---|
| 最新 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.10.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.10.0-amd64 |
latest を除くすべてのタグは次の形式であり、大文字と小文字が区別されます。
<major>.<minor>.<patch>-<platform>-<prerelease>
注意
カスタム音声テキスト変換コンテナーの locale と voice は、コンテナーによって取り込まれるカスタム モデルによって決定されます。
作業を容易にするために、このタグは JSON 形式でも使用できます。 本文には、コンテナー パスとタグの一覧が含まれています。 タグはバージョン別に並べ替えられませんが、次のスニペットに示すように、"latest" は必ずリストの末尾に含まれます。
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
<--redacted for brevity-->
"4.4.0-amd64",
"4.5.0-amd64",
"4.6.0-amd64",
"4.7.0-amd64",
"4.8.0-amd64",
"4.9.0-amd64",
"4.10.0-amd64",
"latest"
]
}
docker pull でコンテナー イメージを取得する
必要なハードウェアを含む前提条件を満たす必要があります。 また、各音声コンテナーに対して推奨されるリソースの割り当ても参照してください。
Microsoft Container Registry からコンテナー イメージをダウンロードするには、docker pull コマンドを使用します。
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
注意
Custom Speech コンテナーの locale と voice は、コンテナーによって取り込まれるカスタム モデルによって決定されます。
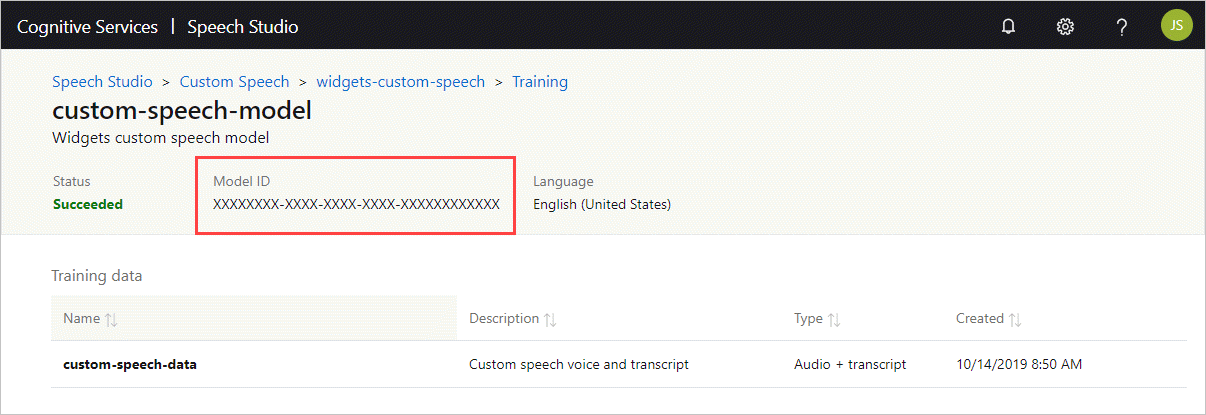
モデル ID を取得する
コンテナーを実行する前に、カスタム モデルのモデル ID または基本モデル ID を把握しておく必要があります。 コンテナーを実行するときに、ダウンロードして使用するモデル ID として、いずれかを指定します。
カスタム モデルは、Speech Studio を使用してトレーニングされる必要があります。 モデル ID を取得する方法については、「Custom Speech モデルのライフサイクル」を参照してください。
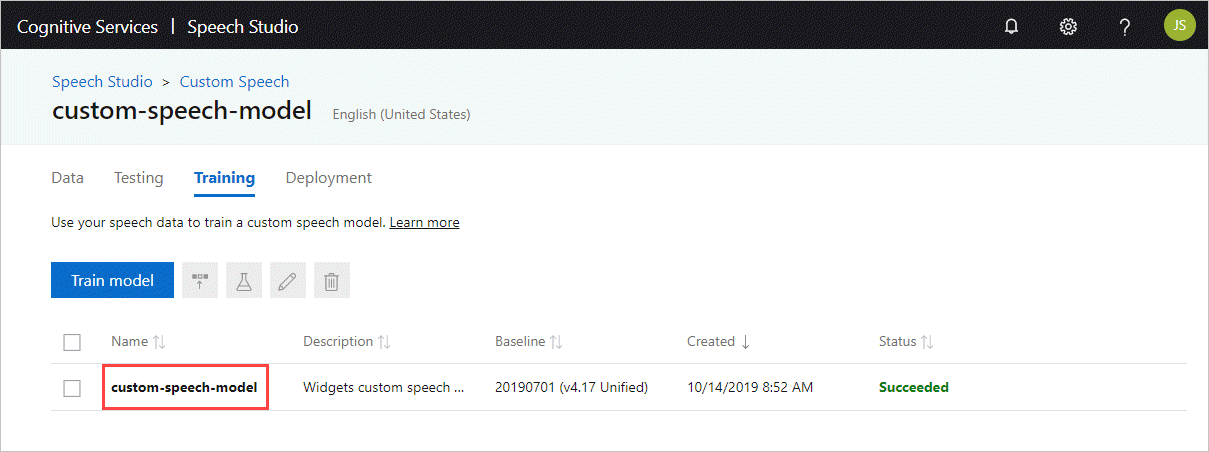
docker run コマンドの ModelId パラメーターの引数として使用するモデル ID を取得します。
表示モデルのダウンロード
コンテナーを実行する前に、必要に応じて使用可能な表示モデル情報を取得し、それらのモデルを音声テキスト変換コンテナーにダウンロードして、最終的な表示出力を大きく改善することができます。 表示モデルのダウンロードは、カスタム音声テキスト変換コンテナー バージョン 3.1.0 以降で使用できます。
注意
docker run コマンドを使用しますが、コンテナーはサービス用に開始されません。
これらの表示モデルの種類 (再スコアリング (Rescore)、句読点 (Punct)、再セグメント化 (Resegment)、wfstitn (Wfstitn)) のいずれかまたはすべてをクエリまたはダウンロードできます。 または、FullDisplay オプション (他の種類あり、またはなし) を使用して、すべての種類の表示モデルをクエリまたはダウンロードできます。
ターゲット ロケールで使用可能な最新の表示モデルに対してクエリを実行するには、BaseModelLocale を設定します。 複数の表示モデルの種類を含める場合、コマンドでは、各種類で使用可能な最新の表示モデルが返されます。 次に例を示します。
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
ターゲット ロケールで使用可能な最新の表示モデルをダウンロードするには、DisplayLocale を設定します。 DisplayLocale を設定する場合は、FullDisplay またはスペースで区切られた表示モデルのサブセットも指定する必要があります。 コマンドを実行すると、指定した種類ごとに使用可能な最新の表示モデルがダウンロードされます。 次に例を示します。
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
1 つのモデル ID パラメーターを設定して、特定の表示モデル (再スコアリング (RescoreId)、句読点 (PunctId)、再セグメント化 (ResegmentId)、wfstitn (WfstitnId)) をダウンロードします。 これは、ModelId パラメーターを使用して基本モデルをダウンロードする方法と似ています。 たとえば、再スコアリング表示モデルをダウンロードするには、RescoreId パラメーターを指定した次のコマンドを使用できます。
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
注意
複数のクエリまたはダウンロード パラメーターを設定した場合、コマンドでは、BaseModelLocale、モデル ID、DisplayLocale (表示モデルにのみ適用されます) という順序で優先順位が付けられます。
docker run でコンテナーを実行する
サービス用にコンテナーを実行するには、docker run コマンドを使用します。
次の表は、さまざまな docker run パラメーターとその説明をまとめたものです。
| パラメーター | 説明 |
|---|---|
{VOLUME_MOUNT} |
ホスト コンピューターのボリューム マウント。Docker では、これを使用してカスタム モデルを保持します。 たとえば、c:\CustomSpeech です。c:\ ドライブはホスト マシンにあります。 |
{MODEL_ID} |
カスタム音声または基本モデル ID。 詳細については、「モデル ID を取得する」を参照してください。 |
{ENDPOINT_URI} |
測定と課金にはエンドポイントが必須です。 詳細については、「課金引数」を参照してください。 |
{API_KEY} |
API キーは必須です。 詳細については、「課金引数」を参照してください。 |
カスタム音声テキスト変換コンテナーを実行する場合は、カスタム音声テキスト変換コンテナーの要件と推奨事項に従って、ポート、メモリ、CPU を構成します。
プレースホルダー値を含む docker run コマンドの例を次に示します。 VOLUME_MOUNT、MODEL_ID、ENDPOINT_URI、API_KEY の値を指定する必要があります。
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
このコマンドは、次の操作を行います。
- コンテナー イメージからカスタム音声変換コンテナーを実行します
- 4 つの CPU コアと 8 GB のメモリを割り当てます。
- カスタム音声テキスト変換モデルをボリューム入力マウント (例: C:\CustomSpeech) から読み込みます。
- TCP ポート 5000 を公開し、コンテナーに pseudo-TTY を割り当てます。
ModelIdが指定されたモデルをダウンロードします (ボリューム マウントで見つからない場合)。- カスタム モデルが以前にダウンロードされた場合、
ModelIdは無視されます。 - コンテナーの終了後にそれを自動的に削除します。 ホスト コンピューター上のコンテナー イメージは引き続き利用できます。
音声コンテナーでの docker run の詳細については、「Docker を使用して音声コンテナーをインストールして実行する」を参照してください。
コンテナーを使用する
音声コンテナーは、WebSocket ベースのクエリ エンドポイント API シリーズを提供します。これには、Speech SDK および Speech CLI を介してアクセスします。 既定では、Speech SDK と Speech CLI ではパブリック音声サービスが使用されます。 コンテナーを使用するには、初期化方法を変更する必要があります。
重要
コンテナーで音声サービスを使用する場合は、必ずホスト認証を使用してください。 キーとリージョンを構成すると、要求はパブリック音声サービスに送信されます。 音声サービスからの結果は、期待どおりではない場合があります。 切断されたコンテナーからの要求は失敗します。
この Azure クラウド初期化構成は使用しません。
var config = SpeechConfig.FromSubscription(...);
コンテナー ホストで、この構成を使用します。
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
この Azure クラウド初期化構成は使用しません。
auto speechConfig = SpeechConfig::FromSubscription(...);
コンテナー ホストで、この構成を使用します。
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
この Azure クラウド初期化構成は使用しません。
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
コンテナー ホストで、この構成を使用します。
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
この Azure クラウド初期化構成は使用しません。
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
コンテナー ホストで、この構成を使用します。
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
この Azure クラウド初期化構成は使用しません。
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
コンテナー ホストで、この構成を使用します。
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
この Azure クラウド初期化構成は使用しません。
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
コンテナー ホストで、この構成を使用します。
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
この Azure クラウド初期化構成は使用しません。
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
コンテナー ホストで、この構成を使用します。
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
この Azure クラウド初期化構成は使用しません。
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
コンテナー エンドポイントで、この構成を使用します。
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
コンテナーで Speech CLI を使用する場合は、--host ws://localhost:5000/ オプションを含めます。 CLI が認証に音声キーを使用しないようにするには、--key none も指定する必要があります。 Speech CLI を構成する方法については、「Azure AI Speech CLI の概要」をご覧ください。
キーとリージョンではなく、ホスト認証を使用して、音声テキスト変換のクイックスタートをお試しください。
次のステップ
- 「音声コンテナーの概要」を参照する
- 構成設定について、コンテナーの構成を確認します。
- より多くの Azure AI コンテナーを使用する