クイックスタート: 根拠性検出 (プレビュー)
このガイドでは、根拠性検出 API を使用する方法について説明します。 この機能は、提供されたソース ドキュメントに基づいて、根拠付けられていないテキストを自動的に検出して修正し、生成されたコンテンツが事実または意図した参照と一致していることを保証するものです。 以下では、これらの機能を適用して最適な結果を得る方法と適用のタイミングを理解するのに役立ついくつかの一般的なシナリオについて説明します。
前提条件
- Azure サブスクリプション - 無料アカウントを作成します
- Azure サブスクリプションを入手したら、Azure portal で Content Safety リソースを作成し、キーとエンドポイントを取得します。 リソースの一意の名前を入力し、サブスクリプションを選択して、リソース グループ、サポートされているリージョン、サポートされている価格レベルを選択します。 [作成] を選択します。
- リソースのデプロイには数分かかります。 完了したら、新しいリソースに移動します。 左ペインの [リソース管理] で、[API キーとエンドポイント] を選択します。 後で使用するために、サブスクリプション キーの値の 1 つとエンドポイントを一時的な場所にコピーします。
- (省略可能) "推論" 機能を使用する場合は、GPT モデルがデプロイされた Azure OpenAI Service リソースを作成します。
- cURL または Python がインストールされていること。
推論なしで根拠性をチェックする
"推論" 機能がない場合はシンプルで、Groundedness detection API により、送信されたコンテンツの非根拠性が true または false として分類されます。
このセクションでは、cURL を使ったサンプル要求について説明します。 以下のコマンドをテキスト エディターに貼り付け、次の変更を加えます。
<endpoint>を、リソースに関連付けられたエンドポイント URL に置き換えます。<your_subscription_key>をお使いのリソースのいずれかのキーで置き換えます。必要に応じて、本文の
"query"または"text"フィールドを、分析する独自のテキストに置き換えます。curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \ --header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \ --header 'Content-Type: application/json' \ --data-raw '{ "domain": "Generic", "task": "QnA", "qna": { "query": "How much does she currently get paid per hour at the bank?" }, "text": "12/hour", "groundingSources": [ "I'm 21 years old and I need to make a decision about the next two years of my life. Within a week. I currently work for a bank that requires strict sales goals to meet. IF they aren't met three times (three months) you're canned. They pay me 10/hour and it's not unheard of to get a raise in 6ish months. The issue is, **I'm not a salesperson**. That's not my personality. I'm amazing at customer service, I have the most positive customer service \"reports\" done about me in the short time I've worked here. A coworker asked \"do you ask for people to fill these out? you have a ton\". That being said, I have a job opportunity at Chase Bank as a part time teller. What makes this decision so hard is that at my current job, I get 40 hours and Chase could only offer me 20 hours/week. Drive time to my current job is also 21 miles **one way** while Chase is literally 1.8 miles from my house, allowing me to go home for lunch. I do have an apartment and an awesome roommate that I know wont be late on his portion of rent, so paying bills with 20hours a week isn't the issue. It's the spending money and being broke all the time.\n\nI previously worked at Wal-Mart and took home just about 400 dollars every other week. So I know i can survive on this income. I just don't know whether I should go for Chase as I could definitely see myself having a career there. I'm a math major likely going to become an actuary, so Chase could provide excellent opportunities for me **eventually**." ], "reasoning": false }'
コマンド プロンプトを開き、cURL コマンドを実行します。
質問応答 (QnA) タスクの代わりに要約タスクをテストするには、次のサンプル JSON 本文を使用します。
{
"domain": "Medical",
"task": "Summarization",
"text": "Ms Johnson has been in the hospital after experiencing a stroke.",
"groundingSources": [
"Our patient, Ms. Johnson, presented with persistent fatigue, unexplained weight loss, and frequent night sweats. After a series of tests, she was diagnosed with Hodgkin’s lymphoma, a type of cancer that affects the lymphatic system. The diagnosis was confirmed through a lymph node biopsy revealing the presence of Reed-Sternberg cells, a characteristic of this disease. She was further staged using PET-CT scans. Her treatment plan includes chemotherapy and possibly radiation therapy, depending on her response to treatment. The medical team remains optimistic about her prognosis given the high cure rate of Hodgkin’s lymphoma."
],
"reasoning": false
}
URL には次のフィールドを含める必要があります。
| 名前 | 必須 | 説明 | 種類 |
|---|---|---|---|
| API バージョン | 必須 | これが使用される API のバージョンです。 現在のバージョンは api-version=2024-09-15-preview です。 例: <endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview |
String |
要求本文のパラメーターは、次の表のように定義されています。
| 名前 | Description | Type |
|---|---|---|
| domain | (省略可能) MEDICAL または GENERIC。 既定値: GENERIC。 |
列挙型 |
| タスク | (省略可能) タスクの種類: QnA、Summarization。 既定値: Summarization。 |
列挙型 |
| qna | (省略可能) タスクの種類が QnA の場合は QnA データを保持します。 |
String |
- query |
(省略可能) これは QnA タスクの質問を表します。 文字数制限: 7,500 文字。 | String |
| text | (必須) チェックする LLM 出力テキスト。 文字数制限: 7,500 文字。 | String |
| groundingSources | (必須) 根拠となるソースの配列を使用して、AI によって生成されたテキストを検証します。 制限については、「入力に関する要件」を参照してください。 | 文字列配列 |
| reasoning | (省略可能) 推論機能を使用するかどうかを指定します。 既定値は false です。 true の場合、説明を提供するには独自の Azure OpenAI GPT-4 Turbo (1106-preview) リソースを用意する必要があります。 推論を使用すると処理時間が長くなることにご注意ください。 |
Boolean |
API 応答を解釈する
要求を送信後、実行された根拠性分析が反映された JSON 応答を受け取ります。 一般的な出力は次のようになります。
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "12/hour."
}
]
}
出力の JSON オブジェクトは次のように定義されています。
| 名前 | Description | Type |
|---|---|---|
| ungroundedDetected | テキストが非根拠性を示しているかどうかを示します。 | Boolean |
| ungroundedPercentage | 根拠なしとして識別されるテキストの比率を 0 から 1 の間の数値で表します。0 は根拠なしのコンテンツはないことを示し、1 は完全に根拠なしのコンテンツであることを示します。 | Float |
| ungroundedDetails | 具体的な例と割合を使用して、根拠なしのコンテンツに関する分析情報を提供します。 | Array |
-text |
根拠なしの具体的なテキスト。 | String |
推論を使用して根拠性をチェックする
根拠性検出 API には、API 応答に "推論" を含めるオプションが備わっています。 推論が有効になっていると、応答には、検出された非根拠性の具体的なインスタンスと説明の詳細を示す "reasoning" フィールドが含まれます。
独自の GPT デプロイを持ち込む
ヒント
Azure OpenAI GPT-4 Turbo (1106-preview) リソースのみがサポートされており、他の GPT の種類はサポートされていません。 任意のリージョンに GPT-4 Turbo (1106-preview) リソースを柔軟にデプロイできます。 ただし、潜在的な待機時間を最小限に抑え、地理的境界データのプライバシーとリスクに関する懸念を回避するには、コンテンツの安全性リソースと同じリージョンに配置することをお勧めします。 データのプライバシーに関する包括的な詳細については、Azure OpenAI Service のデータ、プライバシー、セキュリティに関するガイドラインと Azure AI Content Safety のデータ、プライバシー、セキュリティに関する記事を参照してください。
自分の Azure OpenAI GPT4-Turbo (1106-preview) リソースを使用して推論機能を有効にするには、マネージド ID を使用して Content Safety リソースから Azure OpenAI リソースへのアクセスを許可にします。
Azure AI Content Safety のマネージド ID を有効にします。
Azure portal で Azure AI Content Safety インスタンスに移動します。 [設定] カテゴリで [ID] セクションを見つけます。 システム割り当てのマネージド ID を有効にします。 このアクションにより、Azure AI Content Safety インスタンスに、他のリソースにアクセスするために Azure 内で認識されて使用できる ID が付与されます。

マネージド ID にロールを割り当てます。
Azure OpenAI インスタンスに移動し、[ロールの割り当てを追加] を選択して、Azure AI Content Safety の ID に Azure OpenAI のロールを割り当てるプロセスを開始します。
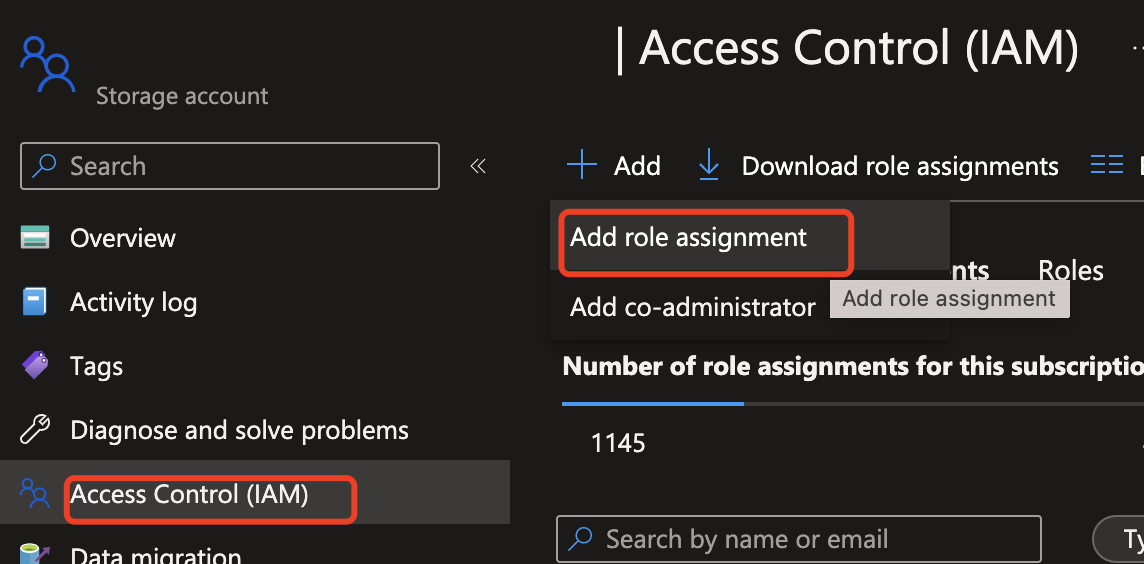
ユーザー ロールまたは共同作成者ロールを選択します。



API 要求を行う
根拠性検出 API への要求で、本文パラメーター "reasoning" を true に設定し、他の必要なパラメーターを指定します。
{
"domain": "Medical",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"reasoning": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}
このセクションでは、cURL を使ったサンプル要求について説明します。 以下のコマンドをテキスト エディターに貼り付け、次の変更を加えます。
<endpoint>を、Azure AI Content Safety リソースに関連付けられているエンドポイント URL に置き換えます。<your_subscription_key>をお使いのリソースのいずれかのキーで置き換えます。<your_OpenAI_endpoint>は、Azure OpenAI リソースに関連付けられたエンドポイント URL に置き換えます。<your_deployment_name>は、Azure OpenAI デプロイの名前に置き換えます。必要に応じて、本文の
"query"または"text"フィールドを、分析する独自のテキストに置き換えます。curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \ --header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \ --header 'Content-Type: application/json' \ --data-raw '{ "domain": "Generic", "task": "QnA", "qna": { "query": "How much does she currently get paid per hour at the bank?" }, "text": "12/hour", "groundingSources": [ "I'm 21 years old and I need to make a decision about the next two years of my life. Within a week. I currently work for a bank that requires strict sales goals to meet. If they aren't met three times (three months) you're canned. They pay me 10/hour and it's not unheard of to get a raise in 6ish months. The issue is, **I'm not a salesperson**. That's not my personality. I'm amazing at customer service, I have the most positive customer service \"reports\" done about me in the short time I've worked here. A coworker asked \"do you ask for people to fill these out? you have a ton\". That being said, I have a job opportunity at Chase Bank as a part time teller. What makes this decision so hard is that at my current job, I get 40 hours and Chase could only offer me 20 hours/week. Drive time to my current job is also 21 miles **one way** while Chase is literally 1.8 miles from my house, allowing me to go home for lunch. I do have an apartment and an awesome roommate that I know wont be late on his portion of rent, so paying bills with 20hours a week isn't the issue. It's the spending money and being broke all the time.\n\nI previously worked at Wal-Mart and took home just about 400 dollars every other week. So I know i can survive on this income. I just don't know whether I should go for Chase as I could definitely see myself having a career there. I'm a math major likely going to become an actuary, so Chase could provide excellent opportunities for me **eventually**." ], "reasoning": true, "llmResource": { "resourceType": "AzureOpenAI", "azureOpenAIEndpoint": "<your_OpenAI_endpoint>", "azureOpenAIDeploymentName": "<your_deployment_name>" }'コマンド プロンプトを開き、cURL コマンドを実行します。
要求本文のパラメーターは、次の表のように定義されています。
| 名前 | Description | Type |
|---|---|---|
| domain | (省略可能) MEDICAL または GENERIC。 既定値: GENERIC。 |
列挙型 |
| タスク | (省略可能) タスクの種類: QnA、Summarization。 既定値: Summarization。 |
列挙型 |
| qna | (省略可能) タスクの種類が QnA の場合は QnA データを保持します。 |
String |
- query |
(省略可能) これは QnA タスクの質問を表します。 文字数制限: 7,500 文字。 | String |
| text | (必須) チェックする LLM 出力テキスト。 文字数制限: 7,500 文字。 | String |
| groundingSources | (必須) 根拠となるソースの配列を使用して、AI によって生成されたテキストを検証します。 制限については、「入力に関する要件」を参照してください。 | 文字列配列 |
| reasoning | (省略可能) true に設定すると、サービスで Azure OpenAI リソースを使用して説明が提供されます。 ただし、推論を使用すると処理時間が長くなり、追加の費用が発生することにご注意ください。 |
Boolean |
| llmResource | (必須) 独自の Azure OpenAI GPT4-Turbo (1106-preview) リソースを使用して推論を有効にする場合は、このフィールドを追加し、使用するリソースのサブフィールドを含めます。 | String |
- resourceType |
使用されるリソースの種類を指定します。 現時点では、AzureOpenAI のみを指定できます。 Azure OpenAI GPT-4 Turbo (1106-preview) リソースのみがサポートされており、他の GPT の種類はサポートされていません。 |
列挙型 |
- azureOpenAIEndpoint |
Azure OpenAI Service のエンドポイント URL。 | String |
- azureOpenAIDeploymentName |
使用する具体的な GPT デプロイの名前。 | String |
API 応答を解釈する
要求を送信後、実行された根拠性分析が反映された JSON 応答を受け取ります。 一般的な出力は次のようになります。
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "12/hour.",
"offset": {
"utf8": 0,
"utf16": 0,
"codePoint": 0
},
"length": {
"utf8": 8,
"utf16": 8,
"codePoint": 8
},
"reason": "None. The premise mentions a pay of \"10/hour\" but does not mention \"12/hour.\" It's neutral. "
}
]
}
出力の JSON オブジェクトは次のように定義されています。
| 名前 | Description | Type |
|---|---|---|
| ungroundedDetected | テキストが非根拠性を示しているかどうかを示します。 | Boolean |
| ungroundedPercentage | 根拠なしとして識別されるテキストの比率を 0 から 1 の間の数値で表します。0 は根拠なしのコンテンツはないことを示し、1 は完全に根拠なしのコンテンツであることを示します。 | Float |
| ungroundedDetails | 具体的な例と割合を使用して、根拠なしのコンテンツに関する分析情報を提供します。 | Array |
-text |
根拠なしの具体的なテキスト。 | String |
-offset |
さまざまなエンコードでの根拠なしのテキストの位置を示すオブジェクト。 | String |
- offset > utf8 |
UTF-8 エンコードでの根拠なしのテキストのオフセット位置。 | Integer |
- offset > utf16 |
UTF-16 エンコードでの根拠なしのテキストのオフセット位置。 | Integer |
- offset > codePoint |
Unicode コード ポイントを単位とする根拠なしのテキストのオフセット位置。 | Integer |
-length |
さまざまなエンコードでの根拠なしのテキストの長さを示すオブジェクト。 (utf8、utf16、codePoint)、オフセットに類似。 | Object |
- length > utf8 |
UTF-8 エンコードでの根拠なしのテキストの長さ。 | Integer |
- length > utf16 |
UTF-16 エンコードでの根拠なしのテキストの長さ。 | Integer |
- length > codePoint |
Unicode コード ポイントを単位とする根拠なしのテキストの長さ。 | Integer |
-reason |
検出された非根拠性の説明を提供します。 | String |
修正機能を使用して根拠性状態を確認する
根拠性検出 API には、提供された根拠となるソースに基づいて、テキスト内で検出された根拠付けられていないテキストを自動的に修正する修正機能が組み込まれています。 修正機能が有効になっている場合、応答には、根拠となるソースに合わせて修正されたテキストを提示する "correction Text" フィールドが含まれます。
独自の GPT デプロイを持ち込む
ヒント
現在、修正機能では、Azure OpenAI GPT-4 Turbo (1106-preview) リソースのみがサポートされています。 待機時間を最小限に抑え、データ プライバシー ガイドラインに準拠するには、GPT-4 Turbo (1106-preview) リソースをコンテンツの安全性リソースと同じリージョンにデプロイすることをお勧めします。 データのプライバシーに関して詳しくは、Azure OpenAI Service のデータ、プライバシー、セキュリティに関するガイドラインと Azure AI Content Safety のデータ、プライバシー、セキュリティに関する記事を参照してください。
修正機能を有効にするために自分の Azure OpenAI GPT4-Turbo (1106-preview) リソースを使用するには、マネージド ID を使用して Content Safety リソースから Azure OpenAI リソースへのアクセスを許可にします。 前のセクションの手順に従って、マネージド ID を設定します。
API 要求を行う
根拠性検出 API への要求で、"correction" 本文パラメーターを true に設定し、他の必要なパラメーターを指定します。
{
"domain": "Medical",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"correction": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}
このセクションでは、cURL を使用したサンプル要求を示します。 プレースホルダーは必要に応じて置き換えます。
<endpoint>は、リソースのエンドポイント URL に置き換えます。<your_subscription_key>は、実際のサブスクリプション キーで置き換えてください。- 必要に応じて、"text" フィールドを分析するテキストに置き換えます。
curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \
--header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"domain": "Generic",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"correction": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}'
要求本文のパラメーターは、次の表のように定義されています。
| 名前 | Description | Type |
|---|---|---|
| domain | (省略可能) MEDICAL または GENERIC。 既定値: GENERIC。 |
列挙型 |
| タスク | (省略可能) タスクの種類: QnA、Summarization。 既定値: Summarization。 |
列挙型 |
| qna | (省略可能) タスクの種類が QnA の場合は QnA データを保持します。 |
String |
- query |
(省略可能) これは QnA タスクの質問を表します。 文字数制限: 7,500 文字。 | String |
| text | (必須) チェックする LLM 出力テキスト。 文字数制限: 7,500 文字。 | String |
| groundingSources | (必須) 根拠となるソースの配列を使用して、AI によって生成されたテキストを検証します。 制限については、「入力に関する要件」を参照してください。 | String Array |
| 修正 | (省略可能) true に設定すると、このサービスは Azure OpenAI リソースを使用して修正されたテキストを提供し、根拠となるソースとの一貫性を確保します。 ただし、修正を使用すると処理時間が長くなり、追加の費用が発生することにご注意ください。 |
Boolean |
| llmResource | (必須) 独自の Azure OpenAI GPT4-Turbo (1106-preview) リソースを使用して推論を有効にする場合は、このフィールドを追加し、使用するリソースのサブフィールドを含めます。 | String |
- resourceType |
使用されるリソースの種類を指定します。 現時点では、AzureOpenAI のみを指定できます。 Azure OpenAI GPT-4 Turbo (1106-preview) リソースのみがサポートされており、他の GPT の種類はサポートされていません。 |
列挙型 |
- azureOpenAIEndpoint |
Azure OpenAI Service のエンドポイント URL。 | String |
- azureOpenAIDeploymentName |
使用する具体的な GPT デプロイの名前。 | String |
API 応答を解釈する
応答には、修正されたテキストを格納する "correction Text" フィールドが含まれ、提供された根拠となるソースとの一貫性が確保されます。
修正機能は、Kevin が根拠となるソース Jane と競合しているために、根拠付けられていないことを検出します。 この API は、次の修正されたテキストを返します。"The patient name is Jane."
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "The patient name is Kevin"
}
],
"correction Text": "The patient name is Jane"
}
出力の JSON オブジェクトは次のように定義されています。
| 名前 | Description | Type |
|---|---|---|
| ungroundedDetected | 根拠付けられていないコンテンツが検出されたかどうかを示します。 | Boolean |
| ungroundedPercentage | テキスト内の根拠付けられていないコンテンツの割合。 | Float |
| ungroundedDetails | 特定のテキスト セグメントを含む、根拠付けられていないコンテンツの詳細。 | Array |
-text |
根拠なしの具体的なテキスト。 | String |
-offset |
さまざまなエンコードでの根拠なしのテキストの位置を示すオブジェクト。 | String |
- offset > utf8 |
UTF-8 エンコードでの根拠なしのテキストのオフセット位置。 | Integer |
- offset > utf16 |
UTF-16 エンコードでの根拠なしのテキストのオフセット位置。 | Integer |
-length |
さまざまなエンコードでの根拠なしのテキストの長さを示すオブジェクト。 (utf8、utf16、codePoint)、オフセットに類似。 | Object |
- length > utf8 |
UTF-8 エンコードでの根拠なしのテキストの長さ。 | Integer |
- length > utf16 |
UTF-16 エンコードでの根拠なしのテキストの長さ。 | Integer |
- length > codePoint |
Unicode コード ポイントを単位とする根拠なしのテキストの長さ。 | Integer |
-correction Text |
根拠となるソースとの一貫性を確保する、修正されたテキスト。 | String |
リソースをクリーンアップする
Azure AI サービス サブスクリプションをクリーンアップして削除したい場合は、リソースまたはリソース グループを削除することができます。 リソース グループを削除すると、それに関連付けられている他のリソースも削除されます。
関連するコンテンツ
- 根拠性検出の概念
- 根拠性検出を、プロンプト シールドなどの他の LLM の安全性機能と組み合わせます。