モデルの正確性スコアと分析の信頼度スコアの解釈と改善
信頼度スコアは、抽出された結果が正しく検出されているという統計的確実性の度合いを測定して、確率を示しています。 正確性の推定値は、トレーニング データの何通りかの組み合わせを実行して、ラベル付けされた値を予測することによって計算されます。 この記事では、正確性と信頼度のスコアを解釈する方法と、これらのスコアを使用して正確性と信頼度の結果を改善するためのベスト プラクティスについて説明します。
信頼度スコア
Note
- フィールド レベルの信頼度は、2024-07-31-preview API バージョン以降の単語信頼度スコアを考慮して、 カスタム モデル用の更新プログラムを取得しています。
- テーブル、テーブル行、テーブル セルの信頼度スコアは、 2024-07-31-preview API バージョン以降、カスタム モデルで使用できます。
Document Intelligence Studio の分析結果は、予測された単語、キーと値のペア、選択マーク、領域、署名に関して、信頼度の推定値を返します。 現時点では、すべてのドキュメント フィールドが信頼度スコアを返すわけではありません。
フィールド信頼度は、予測が正しいことの推定確率を 0 から 1 までの値で示します。 たとえば、0.95 (95%) という信頼度の値は、20 回中 19 回は予測が正しい可能性が高いことを示します。 正確性が非常に重要なシナリオでは、信頼度を使用して、予測を自動的に受け入れるか、それとも人間によるレビューのためにフラグを付けるかを決めることができます。
Document Intelligence Studio
分析済みの請求書と事前構築済みの請求書モデル
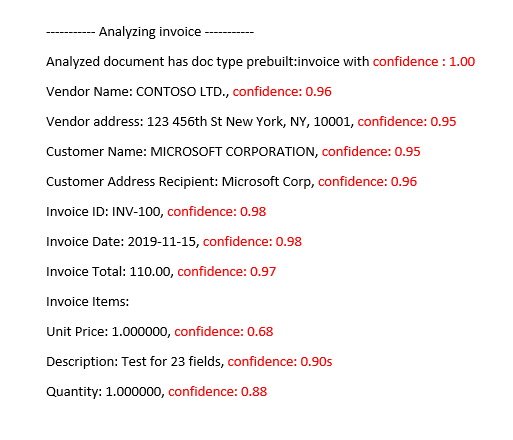
信頼度スコアの向上
分析操作の後に、JSON 出力を確認します。 pageResults ノードの下で、キーと値形式の結果ごとに confidence 値を調べます。 また、readResults ノード内の信頼度スコアにも注目してください。こちらはテキスト読み取り操作に対応します。 読み取り結果の信頼度は、キーと値の抽出結果の信頼度には影響しません。したがって両方を確認する必要があります。 いくつかのヒントを次に示します。
readResultsオブジェクトの信頼度スコアが低い場合は、入力ドキュメントの品質を改善します。pageResultsオブジェクトの信頼度スコアが低い場合は、分析しているドキュメントが同じ種類であることを確認します。人間によるレビューをワークフローに組み込むことを検討します。
各フィールド内の値が異なるフォームを使用します。
カスタム モデルの場合は、トレーニング ドキュメントのより大きなセットを使用します。 より大きなトレーニング セットでは、モデルによるフィールド認識の正確性が向上します。
カスタム モデルの精度スコア
Note
- カスタム ニューラル モデルとジェネレーティブ モデルは、トレーニング中に正確性スコアを提供しません。
build (v3.0 以降) または train (v2.1) カスタム モデル操作の出力には、正確性スコアの推定値が含まれます。 このスコアは、視覚的に類似したドキュメント上のラベル付けされた値を正確に予測するモデルの能力を表します。 正確性は、0% (低) から 100% (高) までのパーセンテージ値の範囲内で測定されます。 最も良いのは、80% 以上のスコアを目標にすることです。 より機密性の高いケース (財務や医療の記録など) では、100% に近いスコアをお勧めします。 さらに重要な自動化ワークフローを検証するために、ヒューマン レビュー ステージを追加することもできます。
Document Intelligence Studio
トレーニング済みカスタム モデル (請求書)
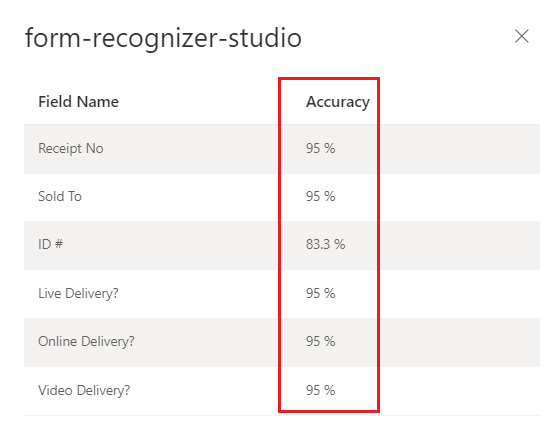
カスタム モデルの正確性スコアと信頼度スコアの解釈
カスタム テンプレート モデルは、トレーニングすると、正確性スコアの推定値を生成します。 カスタム モデルを使用して分析されたドキュメントは、抽出されたフィールドの信頼度スコアを生成します。 カスタム モデルから信頼度スコアを解釈する場合は、モデルから返されるすべての信頼度スコアを考慮する必要があります。 まず、すべての信頼度スコアの一覧から始めましょう。
- ドキュメントの種類の信頼度スコア: ドキュメントの種類の信頼度は、分析されたドキュメントがトレーニング データセット内のドキュメントによく似ていることを示すインジケーターです。 ドキュメントの種類の信頼度が低い場合、分析されたドキュメントのテンプレートまたは構造のバリエーションを示します。 ドキュメントの種類の信頼度を向上させるには、その特定のバリエーションでドキュメントにラベルを付け、トレーニング データセットに追加します。 モデルを再トレーニングしたら、そのクラスのバリエーションを処理するために、より適切に装備する必要があります。
- フィールド レベルの信頼度: 抽出されたラベル付きフィールドには、それぞれ信頼スコアが関連付けられています。 このスコアは、抽出された値の位置に対するモデルの信頼度を反映します。 信頼度スコアを評価するときは、基になる抽出の信頼度を調べて、抽出された結果に対する包括的な信頼度を生成する必要もあります。 フィールドの種類に応じてテキスト抽出または選択マークの
OCR結果を評価し、フィールドの複合信頼度スコアを生成します。 - Word の信頼度スコア ドキュメント内で抽出された各単語には、関連する信頼度スコアがあります。 スコアは、文字起こしの信頼度を表します。 ページ配列には単語の配列が含まれており、各単語にはスパンと信頼度スコアが関連付けられています。 カスタム フィールドから抽出された値のスパンは、抽出された単語のスパンと一致します。
- 選択マークの信頼度スコア: ページ配列には、選択マークの配列も含まれています。 各選択マークには、選択マークと選択状態検出の信頼度を表す信頼度スコアがあります。 ラベル付きフィールドに選択マークがあるとき、カスタム フィールドの選択と選択マーク信頼度の組み合わせは、全体的な信頼度の精度を正確に表すものです。
次の表は、正確性スコアと信頼度スコアの両方を解釈して、カスタム モデルのパフォーマンスを測定する方法を示しています。
| 精度 | Confidence | 結果 |
|---|---|---|
| 高 | 高 | • ラベル付けされたキーとドキュメントの形式により、モデルは高いパフォーマンスを発揮しています。 • バランスの取れたトレーニング データセットがあります。 |
| 高 | 低 | • 分析対象のドキュメントは、トレーニング データセットと見た目が異なります。 • 少なくともあと 5 つの、ラベル付けされたドキュメントを使用して再トレーニングすると、モデルの向上が期待できます。 • これらの結果は、トレーニング データセットと分析対象ドキュメントの形式の違いを示している可能性もあります。 新しいモデルの追加を検討します。 |
| 低 | 高 | • これは最も可能性が低い結果です。 • 正確性スコアが低い場合、ラベル付きデータをさらに追加するか、視覚的な違いが明らかなドキュメントを複数のモデルに分割します。 |
| 低 | 低 | • ラベル付きデータをさらに追加します。 • 視覚的な違いが明らかなドキュメントを複数のモデルに分割します。 |
カスタム モデルの高いモデル精度を確保する
ドキュメントの視覚的構造の差異は、モデルの正確性に影響します。 分析対象のドキュメントとトレーニングに使用したドキュメントが異なる場合、報告される正確性スコアに一貫性がない可能性があります。 人間から見ると似ているように見えるドキュメント セットでも、AI モデルにはそのように見えない可能性があることに注意してください。 以下は、最も正確性が高くなるようにモデルをトレーニングするためのベスト プラクティスの一覧です。 これらのガイドラインに従うことで、分析中、モデルの正確性と信頼度のスコアがさらに向上し、人間によるレビューのフラグが付けられるドキュメントの数が減少するはずです。
ドキュメントのすべてのバリエーションがトレーニング データセットに含まれていることを確認します。 バリエーションには、デジタル PDF かスキャンされた PDF かといった形式の違いが含まれます。
どちらの種類の PDF ドキュメントもモデルによって分析されることを期待する場合は、種類ごとに少なくとも 5 つのサンプルをトレーニング データセットに追加します。
視覚的に異なるドキュメントの種類を分離して、カスタム テンプレートとニューラル モデルのさまざまなモデルをトレーニングします。
- 一般的な規則として、ユーザーが入力したすべての値を削除し、ドキュメントが類似している場合は、トレーニング データを既存のモデルに追加する必要があります。
- ドキュメントが類似していない場合は、トレーニング データを別々のフォルダーに分割し、バリエーションごとにモデルをトレーニングします。 その後、さまざまなバリエーションから 1 つのモデルを作成することができます。
余分なラベルがないことを確認します。
署名と領域のラベル付けでは、周囲のテキストを含めないでください。
テーブル、行、セルの信頼度
2024-02-29-preview API 以降を使用してテーブル、行、セルの信頼度を追加して、テーブル、行、セルのスコアを解釈するのに役立つ一般的な質問を次に示します。
Q: セルの信頼度スコアが高い一方で、行の信頼度スコアが低いということはありますか。
A: はい。 さまざまなレベルのテーブル信頼度 (セル、行、テーブル) は、その特定のレベルでの予測の正確性をキャプチャすることを目的としています。 正しく予測されたセルでも、他のミスの可能性がある行に属する場合、セルの信頼度が高くなりますが、行の信頼度は低いはずです。 同様に、他の行に課題があるテーブルの正しい行の信頼度は高くなりますが、テーブルの全体的な信頼度は低くなります。
Q: セルがマージされるときに予想される信頼度スコアは何ですか? マージによって識別される列の数が変わりますが、スコアにはどのように影響しますか?
A: テーブルの種類に関係なく、マージされたセルの信頼度は低くなることが想定されます。 さらに、欠落しているセル (隣接するセルとマージされため) も、信頼度の低い NULL 値となるはずです。 これらの値がどれだけ小さいかは、トレーニング データセットによって異なります。マージされたセルと、スコアが低い欠落したセルの両方の一般的な傾向は保持されます。
Q: 値が省略可能な場合の信頼度スコアはどうなりますか。 値が欠落している場合、NULL 値と高い信頼度スコアを持つセルを予想できますか。
A: トレーニング データセットがセルのオプション性を表している場合、モデルは、値がトレーニング セットに出現する頻度、および推論中に期待される内容を把握するのに役立ちます。 この機能は、予測の信頼度を計算するとき、またはまったく予測しないときの信頼度を計算するときに使用されます (NULL)。 トレーニング セット内でほとんど空の欠損値に対しては、高い信頼度を持つ空のフィールドとなるはずです。
Q: フィールドが省略可能で、存在しない、または欠落している場合、信頼度スコアにはどのように影響しますか? 信頼度スコアがその質問に答えることを期待できますか。
A: 行に値がない場合、セルには NULL 値と信頼度が割り当てられます。 ここでの信頼度スコアが高いということは、(値が存在しない場合の) モデル予測が正しい可能性が高いということです。 これに対し、スコアが低いということは、モデルからより多くの不確実性を示しています (したがって、値が欠落しているなど、エラーの可能性があります)。
Q: ページ間で行が分割された複数ページのテーブルを抽出する場合、セルの信頼度と行の信頼度はどうなると予想されますか。
A: セルの信頼度は高く、行の信頼度は分割されていない行よりも低くなる可能性があります。 トレーニング データ セット内の分割された行の割合は、信頼度スコアに影響する可能性があります。 一般に、分割された行はテーブル内の他の行とは異なって見えます (したがって、モデルは正しいとは確信が持てなくなります)。
Q: ページ境界で正常に終了して開始する行を含むクロスページ テーブルの場合、ページ間で信頼度スコアが一貫していると想定するのは正しいですか?
A: はい。 行は、ドキュメント (またはページ) 内の場所に関係なく、形と内容が似て見えるので、それぞれの信頼度スコアは一貫している必要があります。
Q: 新しい信頼度スコアを利用する最善の方法は何ですか?
A: 上から下へのアプローチで、すべてのテーブル信頼度を確認します。まず、テーブル全体の信頼度を確認してから、行レベルにドリルダウンして個々の行を確認し、最後にセル レベルの信頼度を確認します。 テーブルの種類に応じて、次の点に注意してください。
固定テーブルの場合、セルレベルの信頼度では、物事の正確性に関するかなりの情報が既にキャプチャされています。 つまり、単に各セルを調べて信頼度を確認するだけで、予測の質を十分に判断できます。 動的テーブルの場合、レベルは互いに基づいて構築されるため、上から下へのアプローチがより重要になります。
次のステップ
カスタム メトリックの詳細を確認します。