カスタム テキスト分類で自動ラベル付けを使用する方法
ラベル付けプロセス は、データセットを準備する上で重要な部分です。 このプロセスには多くの時間と労力が必要なため、自動ラベル付け機能を使用して、分類するクラスをドキュメントに自動でラベル付けすることができます。 現在、GPT モデルを使用してモデルに基づいて自動ラベル付けジョブを開始できます。この場合、モデルのトレーニングを行わずに、自動ラベル付けジョブをすぐにトリガーできます。 この機能を使用すると、ドキュメントに手動でラベル付けする時間と労力を節約できます。
前提条件
GPT で自動ラベル付けを使用するには、次のものが必要です。
- 構成済みの Azure Blob Storage アカウントで正常に作成されたプロジェクト
- ストレージ アカウントにアップロードされたテキスト データ。
- わかりやすいクラス名。 GPT モデルでは、指定したクラスの名前に基づいてドキュメントにラベルが付けられます。
- ラベル付きデータは必要ありません。
- Azure OpenAI のリソースとデプロイ。
自動ラベル付けジョブをトリガーする
GPT で自動ラベル付けジョブをトリガーすると、使用量に従って Azure OpenAI リソースに対して課金されます。 自動ラベル付けされている各ドキュメントのトークンの数の見積もりに対して課金されます。 さまざまなモデルのトークンごとの価格の詳細な内訳については、Azure OpenAI の価格に関するページを参照してください。
左側のナビゲーション メニューから、[データの自動ラベル付け] を選択します。
ページの右側にある [アクティビティ ウィンドウ] の下にある [自動ラベル] ボタンを選択します。
![[アクティビティ ウィンドウ] から自動タグ ジョブをトリガーする方法を示すスクリーンショット。](../media/trigger-autotag.png)
[GPT を使用した自動ラベル付け] を選択し、[次へ] をクリックします。

Azure OpenAI のリソースとデプロイを選択します。 続行するには、Azure OpenAI リソースを作成し、モデルをデプロイする必要があります。
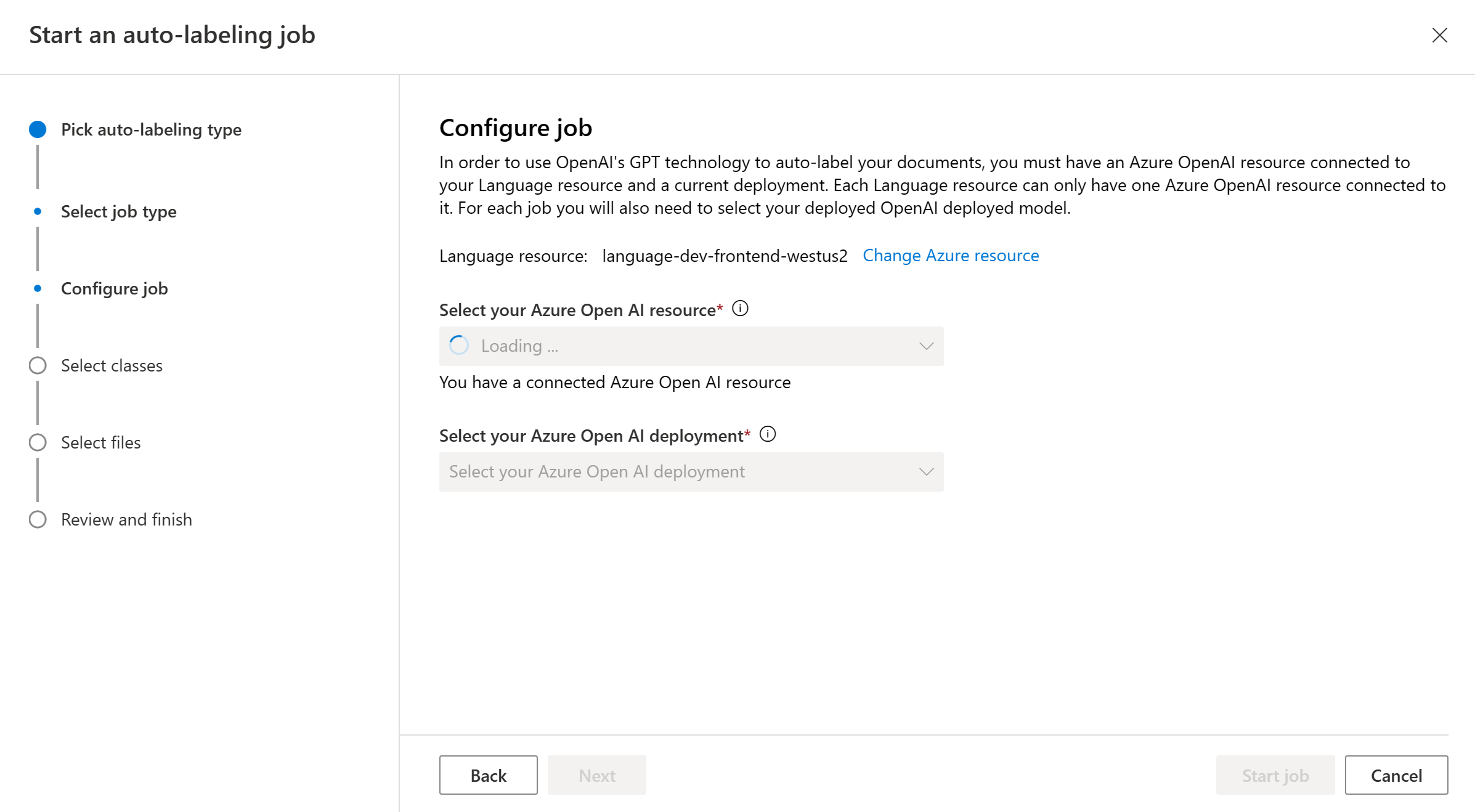
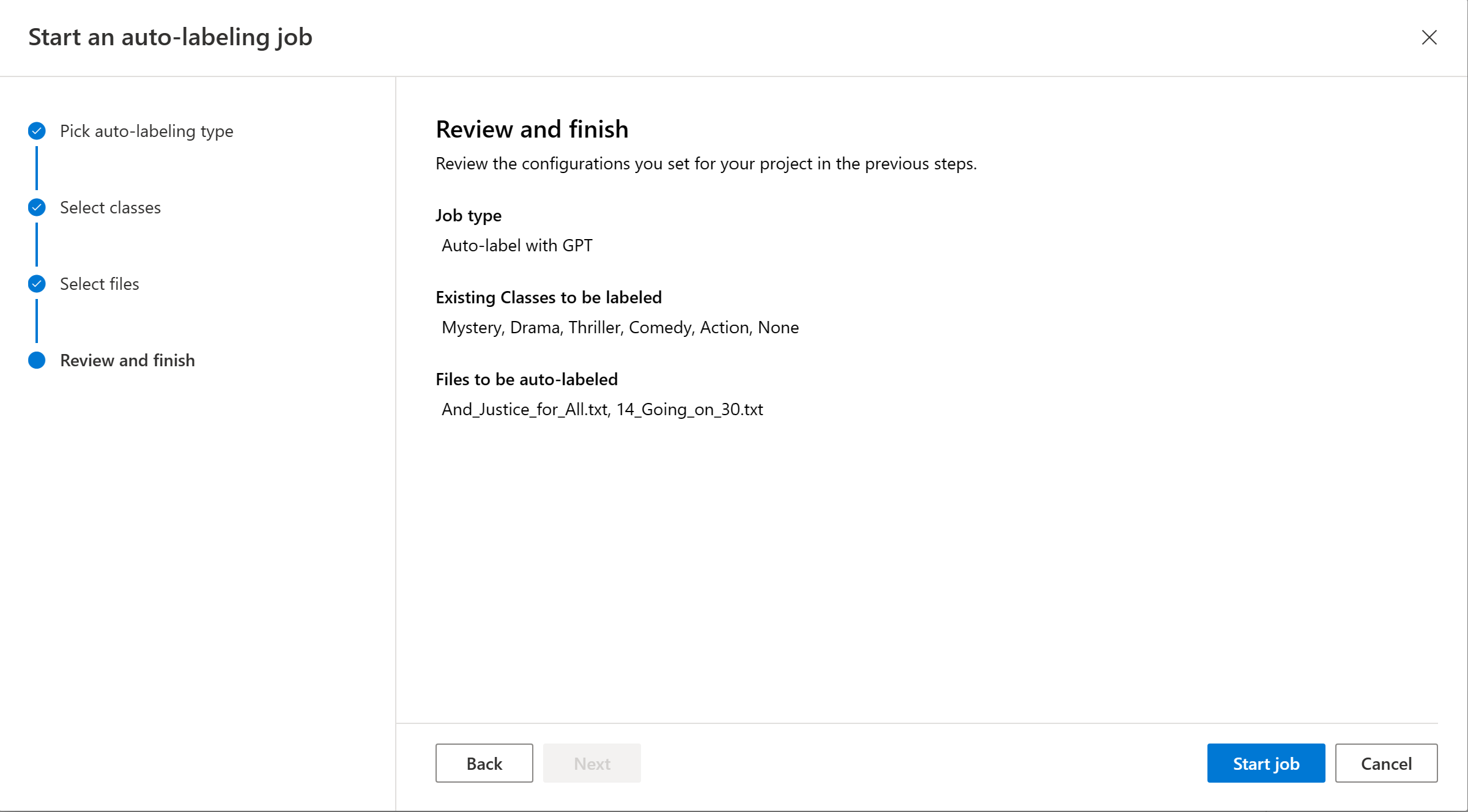
自動ラベル付けジョブに含めるクラスを選択します。 既定では、すべてのクラスが選択されています。 GPT を使用して高品質のラベル付けを実現するには、クラスにわかりやすい名前を付け、各クラスの例を含めることをお勧めします。

自動的にラベル付けするドキュメントを選択します。 フィルターからラベル付けされていないドキュメントを選択することをお勧めします。
注意
- ドキュメントに自動的にラベルが付けられたものの、そのラベルが既にユーザー定義されていた場合は、ユーザー定義ラベルのみが使用されます。
- ドキュメント名をクリックすると、ドキュメントを表示できます。

[ジョブの開始] を選択して、自動ラベル付けジョブをトリガーします。 開始された自動ラベル付けジョブが表示される自動ラベル付けページにリダイレクトされます。 自動ラベル付けジョブは、含まれているドキュメントの数に応じて、数秒から数分間かかることがあります。
![[アクティビティ ウィンドウ] から自動タグ ジョブをトリガーする方法を示すスクリーンショット。](../media/trigger-autotag.png#lightbox)





自動ラベル付けされたドキュメントを確認する
自動ラベル付けジョブが完了すると、Language Studio の [データのラベル付け] ページに出力ドキュメントが表示されます。 [Review documents with autolabels](自動ラベル付きのドキュメントを確認) を選択すると、[Auto labeled](自動ラベル付き) フィルターが適用されたドキュメントが表示されます。

自動的に分類されたドキュメントは、[アクティビティ ウィンドウ] で推奨ラベルが紫色で強調表示されます。 それぞれの推奨ラベルには、自動ラベルを受け入れるか拒否するかを選択できる 2 つのセレクター (チェックマークとキャンセル アイコン) があります。
ラベルを受け入れると、紫色が既定の青色に変わり、そのラベルはそれ以降のモデル トレーニングに含められ、ユーザー定義ラベルになります。
自動ラベル付けされたドキュメントを承諾または拒否したら、[ラベルの保存] を選択して変更を適用します。
注意
- 自動的にラベル付けされたドキュメントを受け入れる前に検証することをお勧めします。
- 受け入れられなかったラベルはすべて、モデルをトレーニングするときに削除されます。

次の手順
- データのラベル付けの詳細を確認する。