キャッシュは、システムのパフォーマンスとスケーラビリティを改善することを目的とする一般的な手法です。 アプリケーションに近い場所にある高速ストレージに、アクセス頻度が高いデータを一時的にコピーしてデータをキャッシュします。 この高速データ ストレージを元のソースよりもアプリケーションに近い場所に配置すると、キャッシュにより、データがよりすばやく提供され、クライアント アプリケーションの応答時間を大幅に改善できます。
キャッシュが最も効果的なのは、クライアント インスタンスが同じデータを繰り返し読み取る場合です。元のデータ ストアが次のすべての条件に該当する場合は、特に効果的です。その条件は次のとおりです。
- 比較的静的である。
- キャッシュの速度に比べて遅い。
- 高レベルの競合が発生する可能性がある。
- ネットワークの待機時間によってアクセスが低速になることがほとんどない。
分散アプリケーションでのキャッシュ
データをキャッシュする場合、分散アプリケーションでは通常、次の戦略のどちらか、または両方を実装します。
- プライベート キャッシュを使用する (アプリケーションまたはサービスのインスタンスが実行されているコンピューター上でデータがローカルに保持されている場合)。
- 共有キャッシュ (複数のプロセスやマシンがアクセス可能な共通ソースとして機能) を使用する。
いずれの場合でも、クライアント側とサーバー側でキャッシュを実行できます。 クライアント側キャッシュは、システムのユーザー インターフェイスを提供するプロセスによって実行されます。たとえば、Web ブラウザーやデスクトップ アプリケーションなどのプロセスです。 サーバー側キャッシュは、リモートで実行されるビジネス サービスを提供するプロセスによって実行されます。
プライベート キャッシュ
最も基本的な種類のキャッシュはメモリ内ストアです。 単一プロセスのアドレス空間に保持され、そのプロセス内で実行されるコードから直接アクセスされます。 この種類のキャッシュには、高速にアクセスできます。 また、少量の静的データを格納するための効果的な手段を提供することもできます。 通常、キャッシュのサイズは、プロセスをホストするマシンで使用可能なメモリの量によって制限されます。
メモリ内で物理的に可能な量よりも多くの情報をキャッシュする必要がある場合は、キャッシュされたデータをローカル ファイル システムに書き込むことができます。 このプロセスでは、メモリ内に保持されたデータへのアクセスよりも遅くなりますが、ネットワーク経由でデータを取得するよりも速く、信頼性も高まります。
このモデルを使用するアプリケーションの複数のインスタンスを同時に実行する場合、各アプリケーション インスタンスは、それ自身のデータのコピーを保持する独立したキャッシュを持ちます。
キャッシュは、過去のある時点における元のデータのスナップショットであると考えてください。 このデータが静的ではない場合、それぞれのアプリケーション インスタンスが、自身のキャッシュにある異なるバージョンのデータを保持する可能性があります。 したがって、これらのインスタンスで同じクエリを実行しても、図 1 に示すように異なる結果が返される可能性があります。
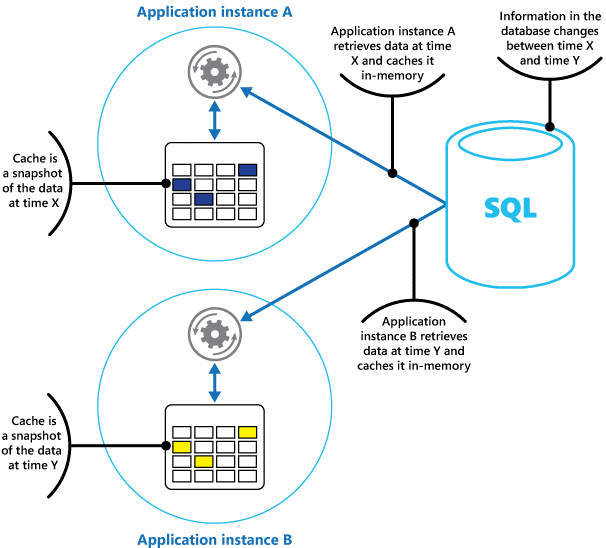
"図 1:アプリケーションの複数のインスタンスにおけるメモリ内キャッシュの使用。
Shared Caching
共有キャッシュを使用すると、メモリ内キャッシュで起きる可能性があるような、キャッシュごとにデータが異なるかもしれないという不安を和らげることができます。 Shared Caching を使用すると、複数のアプリケーション インスタンスから見えるキャッシュ データのビューは同じになります。 図 2 のように、別の場所 (通常は別のサービスの一部としてホストされている場所) にあるキャッシュを特定します。
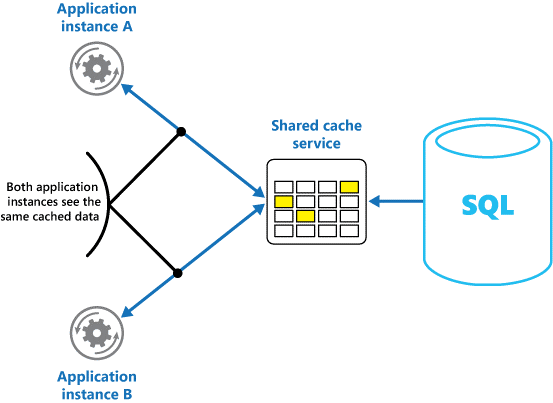
"図 2:共有キャッシュの使用。
Shared Caching を使用する方法の重要な利点は、スケーラビリティがあることです。 多くの共有キャッシュ サービスは、サーバーのクラスターを使用して実装され、ソフトウェアを使用してデータを透過的にクラスター全体に分散させます。 アプリケーション インスタンスからは、キャッシュ サービスに対して要求が送信されるだけです。 基になるインフラストラクチャにより、クラスター内のキャッシュ データの場所が決定されます。 サーバーの数を増やすことで、キャッシュを簡単に拡張できます。
Shared Caching を使用する方法の主な欠点が 2 つあります。
- 各アプリケーション インスタンスのローカルにキャッシュが保持されないので、キャッシュのアクセス速度は遅くなります。
- 個別のキャッシュ サービスを実装する要件がある場合、ソリューションはさらに複雑になる可能性があります。
キャッシュの使用に関する注意点
次のセクションでは、キャッシュの設計と使用に関する注意点を詳細に説明します。
データをキャッシュするタイミングを決める
キャッシュによって、パフォーマンス、スケーラビリティ、および可用性が大幅に向上します。 データが多いほど、またそのデータにアクセスする必要があるユーザー数が多いほど、キャッシュの利点は大きくなります。 元のデータ ストアで大量の同時要求を処理する場合に発生する待機時間や競合が、キャッシュによって軽減されます。
たとえば、サポートされるコンカレント接続数が制限されているデータベースがあるとします。 基になるデータベースではなく、共有キャッシュからデータを取得すると、接続数の上限に達している場合でも、クライアント アプリケーションからそのデータにアクセスできます。 また、データベースを利用できなくなっても、クライアント アプリケーションはキャッシュに保持されているデータを使用して継続できる可能性があります。
読み取り頻度が高く、変更頻度が低いデータのキャッシュを検討してみてください (たとえば、書き込み操作よりも読み取り操作の割合が高いデータなどです)。 ただし、重要な情報の信頼できるストアとしてキャッシュを使用することはお勧めしません。 アプリケーションが損失を許容できないすべての変更は、必ず永続的なデータ ストアに保存してください。 キャッシュを使用できない場合でも、アプリケーションは永続的なデータ ストアを使用して処理を続行できるため、重要な情報を失うことはありません。
データを効率的にキャッシュする方法を決める
キャッシュを効果的に使用する鍵は、最もキャッシュに適したデータを決定し、適切なタイミングでそのデータをキャッシュすることにあります。 データは、アプリケーションから初めて取得されるときに必要に応じてキャッシュに追加できます。 アプリケーションがデータ ストアからデータを取得する必要があるのは 1 回のみで、以降のアクセスにはキャッシュを利用できるようになります。
また、前もって (通常はアプリケーションの開始時に) データの一部またはすべてをキャッシュに保存することもできます (シード処理と呼ばれる方法です)。 ただし、この方法では、アプリケーションの実行開始時に、元のデータ ストアに大きな負荷が急激にかかる可能性があるため、大きなキャッシュのシード処理は実装しないことをお勧めします。
多くの場合、使用パターンを分析することで、キャッシュの事前作成を完全にまたは部分的のどちらで行うのか決定し、キャッシュする必要のあるデータを選択しやすくなります。 たとえば、アプリケーションを定期的 (たとえば毎日) に使用する顧客の場合は、静的なユーザー プロファイル データでキャッシュをシード処理できますが、1 週間に 1 度だけアプリケーションを使用する顧客の場合はシード処理できません。
通常、キャッシュは、変更することのできないデータまたは変更の頻度の低いデータでは十分に機能します。 たとえば、e コマースアプリケーションの製品および価格情報などの参考情報や、構築するのに費用がかかる共有静的リソースなどです。 こうしたデータの一部またはすべてをアプリケーションの起動時にキャッシュに読み込むことで、リソースに対する要求を最小限に抑えるとともに、パフォーマンスを向上させることができます。 また、キャッシュ内の参照データを定期的に更新して最新の状態に保つバックグラウンド プロセスが必要になる場合もあります。 または、参照データが変更されたときにバックグラウンド プロセスでキャッシュが更新される場合もあります。
この注意点にはいくつかの例外がありますが、動的なデータではキャッシュはあまり有用ではありません (詳細については、この記事の「非常に動的なデータをキャッシュする」セクションを参照してください)。 元のデータが定期的に変更される場合、キャッシュされた情報がすぐに古くなるか、キャッシュを元のデータ ストアと同期させ続けるオーバーヘッドによってキャッシュの有効性が低下する可能性があります。
キャッシュにはエンティティの完全なデータを含める必要はありません。 たとえば、あるデータ項目が、名前、住所、および口座残高を持つ銀行の顧客のような複数値オブジェクトを表す場合、こうした要素の一部 (名前や住所など) は静的なままです。 他の要素 (口座残高など) はより動的な場合があります。 このような場合、データの静的な部分をキャッシュし、残りの情報は必要に応じて取得 (または計算) するだけにした方が有効な可能性があります。
キャッシュの事前入力、オンデマンドの読み込み、またはその両方の組み合わせのどれが適しているかを判断するには、パフォーマンス テストと使用状況の分析を行うことをお勧めします。 データの変化の頻度と使用パターンに基づいて判断する必要があります。 キャッシュの使用率とパフォーマンスの分析は、大きな負荷がかかるため拡張性を高める必要のあるアプリケーションでは重要です。 たとえば、拡張性の高いシナリオでは、キャッシュをシードしてピーク時にデータ ストアへの負荷を軽減することができます。
キャッシュを使用して、アプリケーションの実行時に計算が繰り返し行われることを防ぐこともできます。 ある操作でデータの変換または複雑な計算を実行する場合、キャッシュ内に操作の結果を保存できます。 以降、同じ計算が必要になった場合、アプリケーションはキャッシュからその結果を取得するだけで済みます。
アプリケーションは、キャッシュ内に保存されているデータを変更できます。 ただし、キャッシュは、あらゆるタイミングで消える可能性がある一時的なデータ ストアとして考えることをお勧めします。 重要なデータはキャッシュのみに保存せず、元のデータ ストアにも情報を保存してください。 こうすることで、キャッシュが利用できなくなった場合でも、データを失う可能性を最小限に抑えられます。
非常に動的なデータをキャッシュする
変更頻度が高い情報を永続的なデータ ストアに保存すると、システムにオーバーヘッドが発生する可能性があります。 たとえば、状態などの測定値を継続的に報告するデバイスがあるとします。 キャッシュされた情報がほとんどいつも期限切れであることを踏まえて、アプリケーションがこのデータをキャッシュしないことを選択した場合、この情報を保存およびデータ ストアから取得するときも同じ考察が行われます。 このデータの保存および取得にかかる時間の間に、データが変更される可能性があるのです。
このような状況では、動的な情報を永続的なデータ ストアではなく、キャッシュに直接保存するメリットを検討してください。 データが重要なものではなく、監査する必要がない場合、不定期の変更内容が失われても問題にはなりません。
キャッシュ内のデータの有効期限を管理する
ほとんどの場合は、キャッシュに保持されるデータは、元のデータ ストアに保持されているデータのコピーです。 元のデータ ストアのデータがキャッシュ後に変更されると、キャッシュされたデータが古いものになります。 多くのキャッシュ システムでは、キャッシュでデータの有効期限を設定して、データが期限切れになる期間を短縮することができます。
キャッシュされたデータは有効期限が切れるとキャッシュから削除され、アプリケーションは元のデータ ストアからそのデータを取得する必要があります (新しく取得した情報をキャッシュ内に戻すことができます)。 キャッシュを設定するときに、既定の有効期限ポリシーを設定できます。 多くのキャッシュ サービスでは、プログラムからキャッシュにオブジェクトを保存するときに、個々のオブジェクトの有効期限を設定することもできます。 絶対値として有効期限を指定できるキャッシュや、指定した期間内にアクセスされなかった場合にキャッシュから項目を削除するスライド式の値として有効期限を指定できるキャッシュがあります。 この設定は、指定したオブジェクトについてのみ、任意のキャッシュ全体の有効期限ポリシーをオーバーライドします。
注意
キャッシュの有効期限とキャッシュに含まれるオブジェクトを慎重に検討してください。 有効期限を短くしすぎると、オブジェクトはすぐに期限切れになり、キャッシュを使用するメリットが損なわれます。 有効期限を長くしすぎると、データが古くなる危険性があります。
データが長期間にわたって保持できるように設定されていると、キャッシュがいっぱいになる可能性もあります。 この場合、キャッシュに新規項目を追加する要求により、削除と呼ばれるプロセスで、一部の項目が強制的に削除される可能性があります。 キャッシュ サービスは、通常、最低使用頻度法 (LRU) に基づいてデータを削除しますが、一般にはこのポリシーをオーバーライドして項目が削除されないようにすることができます。 ただし、この方法を採用すると、キャッシュの利用できるメモリ上限を超える危険性があります。 この場合、アプリケーションからキャッシュに項目を追加しようとすると、例外で失敗します。
キャッシュの実装方法によっては、追加の削除ポリシーを使用できます。 削除ポリシーにはいくつの種類があります。 これには以下が含まれます。
- 最近使用されたデータから削除される後入れ先出しポリシー (データが再利用されないと想定される場合に使用されます)。
- 先入れ先出しポリシー (最も古いデータから削除されます)。
- トリガーされたイベント (データの変更など) に基づく明示的な削除ポリシー。
クライアント側キャッシュ内のデータを無効にする
クライアント側キャッシュに保持されているデータは、一般的に、データをクライアントに提供するサービスの範囲外と見なされます。 サービスからクライアントに対して、クライアント側キャッシュの情報の追加または削除を直接強制することはできません。
つまり、適切に構成されていないキャッシュを使用しているクライアントは、古い情報を使い続ける可能性があります。 たとえば、キャッシュの有効期限ポリシーが適切に実装されていない場合、元のデータ ストアの情報が変更されている場合でも、クライアントはローカルにキャッシュされた古い情報を使用する可能性があります。
HTTP 接続経由でデータを提供する Web アプリケーションを作成する場合、Web クライアント (ブラウザーまたは Web プロキシなど) に対して、最新の情報を取得するように暗黙的に強制できます。 この処理は、リソースの URI の変更によってリソースが更新された場合に実行できます。 Web クライアントは通常、クライアント側キャッシュのキーとしてリソースの URI を使用するため、URI を変更すると、Web クライアントは以前にキャッシュされたバージョンのリソースは無視して、代わりに新しいバージョンを取得します。
キャッシュ内でのコンカレンシーの管理
多くの場合、キャッシュは、アプリケーションの複数のインスタンスで共有されるように設計されています。 各アプリケーション インスタンスは、キャッシュ内のデータを読み取り、変更できます。 このため、共有データ ストアで生じるものと同じコンカレンシーの問題が、キャッシュにも当てはまります。 キャッシュ内に保持されているデータをアプリケーションが変更する必要がある状況では、アプリケーションの 1 つのインスタンスによって行われた更新が、他のインスタンスによって行われた変更を上書きしないようにする必要があります。
データの性質と競合が発生する可能性に応じて、2 つのコンカレンシー制御方法のいずれかを採用することができます。
- オプティミスティック同時実行制御。 アプリケーションは、キャッシュ内のデータを更新する直前に、取得後にそのデータが変更されたかどうかを確認します。 データが同じままの場合、変更できます。 同じではない場合、アプリケーションはデータを更新するかどうかを決定する必要があります (この決定を左右するビジネス ロジックは、アプリケーションによって異なります)。この方法は、更新が頻繁に行われる状況、または競合が発生する可能性がない状況に適しています。
- ペシミスティック同時実行制御。 アプリケーションは、キャッシュ内のデータを取得するときにそのデータをロックして、他のインスタンスがそのデータを変更できないようにします。 このプロセスによって競合は起きなくなりますが、同じデータを処理する必要がある他のインスタンスもブロックされる可能性もあります。 ペシミスティック コンカレンシー制御は、ソリューションのスケーラビリティに影響をあたえる可能性があるため、一時的な操作にのみ使用することをお勧めします。 この方法は、競合が発生する可能性が高い状況、特にアプリケーションがキャッシュ内の複数の項目を更新するため、こうした変更が矛盾なく適用されるようにする必要がある場合に適しています。
高可用性とスケーラビリティの実装とパフォーマンスの向上
データのプライマリ リポジトリとしてキャッシュを使用しないでください。この役割は、キャッシュの入力元である元のデータ ストアのものです。 元のデータ ストアは、データの永続性を確保するために使用します。
ソリューションに、共有キャッシュ サービスの可用性に関する重要な依存関係が発生しないように注意してください。 共有キャッシュを提供するサービスが利用できなくなった場合でも、アプリケーションは継続的に機能する必要があります。 キャッシュ サービスが再開されるのを待つ間に、アプリケーションが応答しなくなったり、失敗したりしないようにする必要があります。
そのため、アプリケーションは、キャッシュ サービスの可用性を検出し、キャッシュにアクセスできない場合に元のデータ ストアにフォール バックするようにしておく必要があります。 サーキット ブレーカー パターン が、このシナリオを処理するときに役立ちます。 キャッシュアサイド パターンなどの戦略に従うと、キャッシュを提供するサービスを復元でき、サービスが使用可能になると、元のデータ ストアからデータを読み取るときにキャッシュに再入力することができます。
ただし、キャッシュが一時的に利用できなくなったときに、アプリケーションが元のデータ ストアにフォール バックした場合、システムのスケーラビリティに影響が出る可能性があります。 キャッシュのデータ ストアを回復している間に、元のデータ ストアがデータの要求に対応しきれず、タイムアウトや接続の失敗が発生する可能性があります。
すべてのアプリケーション インスタンスがアクセスできる共有キャッシュとともに、アプリケーションの各インスタンスにローカルなプライベート キャッシュを実装することをお勧めします。 アプリケーションは、項目を取得するときに、ローカル キャッシュ内、共有キャッシュ内、元のデータ ストア内の順に確認します。 ローカル キャッシュは、共有キャッシュのデータを使用して、または共有キャッシュが使用できない場合はデータベースのデータを使用して設定できます。
この方法の場合、共有キャッシュと比較してローカル キャッシュが古くなりすぎないように、慎重に構成する必要があります。 ただし、共有キャッシュにアクセスできない場合、ローカル キャッシュはバッファーとして機能します。 図 3 に、この構造を示します。
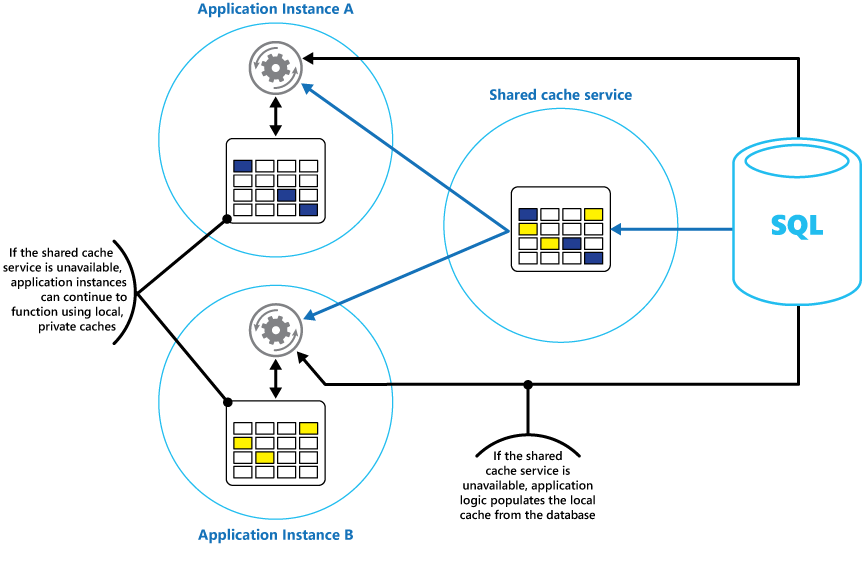
"図 3:共有キャッシュとローカル プライベート キャッシュの使用。
一部のキャッシュ サービスでは、有効期間が比較的長いデータを保持する大規模なキャッシュをサポートするために、キャッシュが使用できなくなった場合に自動フェールオーバーを実装する、高可用性オプションを使用できます。 通常、この方法では、プライマリ キャッシュ サーバーに格納されているキャッシュされたデータをセカンダリ キャッシュ サーバーにレプリケートして、プライマリ サーバーで障害が発生するか接続が失われた場合にセカンダリ サーバーに切り替えます。
複数の送信先への書き込みに伴う待機時間を短くするために、プライマリ サーバーのキャッシュにデータが書き込まれるときに、セカンダリ サーバーへのレプリケーションが非同期的に行われる場合があります。 この方法では、障害発生時に一部のキャッシュされた情報が失われる可能性が生じますが、こうしたデータの量はキャッシュのサイズ全体と比べると小さい割合です。
共有キャッシュのサイズが大きい場合、キャッシュされたデータを複数のノードに分割して、競合の可能性を抑えてスケーラビリティを高めることをお勧めします。 多くの共有キャッシュでは、ノードを直接追加 (および削除) し、パーティション間でデータを再調整する機能がサポートされています。 この方法にはクラスタリングが使用される場合があります。クラスタリングの場合、複数ノードのコレクションがシームレスな 1 つのキャッシュとしてクライアント アプリケーションに提供されます。 ただし、内部的には、負荷を均等に分散する事前定義の分散戦略に従って、データは複数のノードに分散されています。 パーティション分割戦略の詳細については、「データのパーティション分割のガイダンス」をご覧ください。
クラスタリングによって、キャッシュの可用性も向上できます。 ノードが停止した場合でも、その他のキャッシュにはアクセスできます。 多くの場合、クラスタリングはレプリケーションとフェールオーバーと組み合わせて使用されます。 各ノードをレプリケートすることができます。また、ノードが停止した場合、レプリカをすばやくオンラインにすることができます。
多くの読み取り操作および書き込み操作では、単一のデータの値またはオブジェクトが使用されます。 ただし、ときには、大量のデータをすばやく保存または取得する必要がある状況も発生します。 たとえば、キャッシュのシード処理では、数百から数千単位の項目をキャッシュに書き込む場合があります。 また、1 つの要求でキャッシュから関連する項目を多数取得する場合もあります。
多くの大規模なキャッシュ サービスには、このような目的に対応できるバッチ操作が用意されています。 この機能を利用すると、クライアント アプリケーションは大量の項目を 1 つの要求にパッケージ化し、小さな要求を多数の実行する場合に発生するオーバーヘッドを軽減することができます。
キャッシュおよび最終的な整合性
キャッシュアサイド パターンが機能するには、キャッシュを設定するアプリケーションのインスタンスから、最新かつ一貫性のあるバージョンのデータにアクセスできる必要があります。 最終的な一貫性を実装するシステム (レプリケートされたデータ ストアなど) では、これに当てはまらない場合があります。
アプリケーションの 1 つのインスタンスが、データ項目を変更し、その項目のキャッシュされたバージョンを無効化する可能性があります。 アプリケーションの別のインスタンスはキャッシュからこの項目を読み取ろうとする場合がありますが、この試行はキャッシュミスの原因になります。このため、このインスタンスは、データをデータ ストアから読み取ってキャッシュに追加します。 ただし、データ ストアが他のレプリカと完全には同期していない場合は、アプリケーション インスタンスは値が古いキャッシュを読み取り、設定する可能性があります。
データ整合性の処理については、データ整合性入門を参照してください。
キャッシュ データを保護する
使用するキャッシュ サービスにかかわらず、キャッシュ内に保持されているデータを不正なアクセスから守る方法を検討してください。 次の 2 つの主な懸念事項があります。
- キャッシュ内のデータのプライバシー。
- キャッシュとキャッシュを使用するアプリケーションとの間を移動するデータのプライバシー。
キャッシュ内のデータを保護するには、アプリケーションが次の情報を指定することを必須とする認証メカニズムをキャッシュ サービスに実装する方法があります。
- キャッシュ内のデータにアクセスできる ID。
- その ID に実行を許可する操作 (読み取りと書き込み)。
データの読み取りおよび書き込みに伴うオーバーヘッドを抑えるために、ある ID にキャッシュへの書き込みや読み取りのアクセス権が付与されると、その ID はキャッシュ内のデータを使用できるようになります。
キャッシュされたデータのサブセットに対するアクセスを制限する場合は、次のいずれかの処理を実行できます。
- (別のキャッシュ サーバーを使用して) キャッシュをパーティションに分割し、使用を許可するパーティションへのアクセス権のみを ID に付与する。
- 異なるキーを使用して各サブセット内のデータを暗号化し、各サブセットへのアクセス権を設定する必要がある ID にだけ暗号化キーを提供する。 この場合、クライアント アプリケーションはキャッシュ内のすべてのデータを取得することができますが、キーを持っているデータの暗号化のみを解除することができます。
また、キャッシュの書き込み時と読み取り時には、データを保護する必要があります。 保護する方法は、クライアント アプリケーションがキャッシュに接続するときに使用するネットワーク インフラストラクチャで提供されているセキュリティ機能によって異なります。 クライアント アプリケーションをホストする同じ組織内のオンサイト サーバーを使用してキャッシュを実装する場合、ネットワークの隔離自体では追加の手順を行う必要はありません。 キャッシュがリモートに配置され、パブリック ネットワーク (インターネットなど) 経由の TCP 接続または HTTP 接続が必要な場合、SSL の実装を検討してください。
Azure でのキャッシュの実装に関する考慮事項
Azure Cache for Redis は、Azure データセンターでサービスとして実行される オープン ソースの Redis Cache の実装です。 Redis Cache は、Azure アプリケーションがクラウド サービスとして、Web サイトとして、または Azure 仮想マシン内に実装されているかにかかわらず、このアプリケーションからアクセスできるキャッシュ サービスを提供します。 キャッシュは、適切なアクセス キーを持つクライアント アプリケーションで共有できます。
Azure Cache for Redis は、可用性、スケーラビリティ、およびセキュリティを提供する高パフォーマンスのキャッシュ ソリューションです。 通常、Azure Redis Cache は、1 つまたは複数の専用マシン全体でサービスとして実行されます。 Azure Redis Cache は、確実に高速にアクセスできるメモリ内に可能な限り多くの情報を格納しようと試みます。 このアーキテクチャは低速な I/O 操作を実行する必要性を減らすことで、待機時間の短縮とスループットの増加を実現するためのものです。
Azure Cache for Redis には、クライアント アプリケーションで使用されるさまざまな API の多くとの互換性があります。 オンプレミスで実行される Azure Cache for Redis を既に使用している既存のアプリケーションがある場合、Azure Cache for Redis を使用して簡単にクラウド内のキャッシュへと移行することができます。
Redis の機能
Redis は単なるキャッシュ サーバーではありません。 分散型のメモリ内データベース機能があり、多くの一般的なシナリオに対応する多数のコマンドが用意されています。 詳細については、このドキュメントの「Redis のキャッシュの使用」を参照してください。 このセクションでは、Redis が提供するいくつかの重要な機能の概要を示します。
メモリ内データベースとしての Redis
Redis は読み取り操作と書き込み操作の両方をサポートしています。 Redis では、書き込みはローカルのスナップショット ファイルまたは追加専用のログ ファイルに定期的に保存されるので、システム障害が発生した場合でも保護できます。 多くのキャッシュではこの状態は当てはまりません。一時的なデータ ストアと考える必要があります。
すべての書き込みは非同期であり、クライアントによるデータの読み取りと書き込みをブロックしません。 Redis の実行を開始すると、スナップショットまたはログ ファイルからデータを読み取り、そのデータを使用してメモリ内キャッシュを構築します。 詳細については、Redis Web サイトの「 Redis Persistence (Redis の永続性)」を参照してください。
注意
Redis では、重大な障害が発生したときにすべての書き込みが保存されることは保証されませんが、最悪の場合でも数秒間のデータを失うだけです。 キャッシュは信頼できるデータ ソースとして機能するものではなく、重要なデータが適切なデータ ストアに正常に保存されるようにするのは、キャッシュを使用するアプリケーションの役割であることを忘れないでください。 詳細については、「キャッシュ アサイド パターン」を参照してください。
Redis データ型
Redis はキー値ストアであり、値には単純な型や、ハッシュ、リスト、およびセットなどの複雑なデータ構造を含めることができます。 Redis は、このようなデータ型に対する一連のアトミック操作をサポートしています。 キーは永続的なものにすることも、キーとその対応する値が自動的にキャッシュから削除される制限時間を指定することもできます。 Redis のキーおよび値の詳細については、Redis Web サイトの「 An Introduction to Redis data types and abstractions (Redis のデータ型と抽象化の概要)」のページを参照してください。
Redis のレプリケーションとクラスタリング
Redis は、可用性を確保し、スループットを維持できるように、プライマリ/下位のレプリケーションをサポートしています。 Redis プライマリ ノードに対する書き込み操作は、1 つまたは複数の下位ノードにレプリケートされます。 読み取り操作は、プライマリまたはいずれかの下位のものに対して行うことができます。
ネットワーク パーティションがある場合、下位ではデータの処理を継続してから、接続が再度確立されたときにプライマリと透過的に再同期することができます。 詳細については、Redis Web サイトの「 Replication 」(レプリケーション) ページを参照してください。
Redis ではクラスタリングも提供されるため、サーバー間のシャードにデータを透過的に分割して、負荷を分散することができます。 この機能によって、キャッシュのサイズの増加に合わせて新しい Redis サーバーを追加し、データを再分割することができるため、スケーラビリティが向上します。
また、クラスター内の各サーバーは、プライマリ/下位のレプリケーションを使用してレプリケートすることができます。 そのため、クラスターの各ノード全体で可用性を確保できます。 クラスタリングとシャーディングの詳細については、Redis Web サイトの「 Redis Cluster Tutorial (Redis クラスターのチュートリアル)」のページを参照してください。
Redis のメモリ使用量
Redis キャッシュのサイズは、ホスト コンピューターで使用可能なリソースによって制限されます。 Redis サーバーを構成するときに、使用できるメモリの最大量を指定できます。 Redis Cache 内のキーには有効時間を構成することができます。この時間を過ぎるとキーがキャッシュから自動的に削除されます。 この機能によって、古いまたは最新でなくなったデータでメモリ内キャッシュが埋め尽くされるのを防ぐことができます。
メモリが上限に達すると、Redis は多くのポリシーに従ってキーとその値を自動的に削除します。 既定値は LRU (Least Recently Used、使われてから最も時間が経ったもの) ですが、キーのランダムな削除や、削除をすべて無効化する (この場合、キャッシュがいっぱいになるとキャッシュに項目を追加する試行は失敗します) など、他のポリシーも選択することができます。 詳細については、「 Using Redis as an LRU Cache (LRU キャッシュとしての Redis の使用)」を参照してください。
Redis のトランザクションとバッチ
Redis では、クライアント アプリケーションは、キャッシュ内のデータの読み取りおよび書き込みを行う一連の操作を、アトミック トランザクションとして送信することができます。 トランザクション内のすべてのコマンドは必ず順番に実行され、他の同時実行クライアントにより発行されたコマンドがそれらに混ざることはありません。
ただし、これらは正確にはトランザクションではなく、リレーショナル データベースが一連の操作を実行しています。 トランザクション処理は 2 つの段階から構成されます。第 1 段階はコマンドがキューに保存されるとき、第 2 段階はコマンドが実行されるときです。 コマンド キューの段階では、トランザクションに含まれるコマンドがクライアントによって送信されます。 この時点でなんらかのエラー (構文エラー、不正な数のパラメーターなど) が発生すると、Redis はトランザクション全体の処理を拒否して、廃棄します。
実行フェーズでは、Redis はシーケンス内の各キューに登録されたコマンドを実行します。 このフェーズでコマンドが失敗した場合、Redis は次のキューに登録されたコマンドの実行を継続しますが、既に実行されたコマンドの影響をロール バックすることはありません。 このように簡略化された形式のトランザクションにより、パフォーマンスを維持して、競合によって生じるパフォーマンスの問題を回避することができます。
Redis は、一貫性の維持を支援するオプティミスティック同時実行制御の形式を実装しています。 Redis を使用したトランザクションと同時実行制御の詳細については、Reids Web サイトの「 Transactions 」(トランザクション) ページを参照してください。
Redis では、要求の非トランザクション バッチ処理もサポートされています。 Redis サーバーへのコマンドの送信にクライアントが使用する Redis プロトコルにより、クライアントは同じ要求の一部として一連の操作を送信することができます。 これにより、ネットワーク上でのパケットの断片化を抑えることができます。 バッチが処理されると、各コマンドが実行されます。 いずれかのコマンドの形式が不正である場合、それらは拒否されますが (トランザクションでは拒否されません)、残りのコマンドは実行されます。 また、バッチ内のコマンドが処理される順番は保証されません。
Redis のセキュリティ
Redis ではデータへの高速アクセスを実現することのみに重点が置かれており、信頼された環境内で実行され、信頼されたクライアントのみがアクセスするように設計されています。 Redis は、パスワード認証に基づく制限付きのセキュリティ モデルをサポートしています (認証を完全に削除することもできますが、推奨されません)。
すべての認証されたクライアントは同じグローバル パスワードを共有し、同じリソースにアクセスできます。 より包括的なサインインのセキュリティが必要な場合、Redis サーバーの前に独自のセキュリティ層を実装し、すべてのクライアント要求がその追加の層を通過するようにする必要があります。 信頼されていないクライアントや認証されていないクライアントに Redis を直接公開しないでください。
コマンドを無効化するか、その名前を変更して (および特権のあるクライアントにだけ新しい名前を提供して)、コマンドへのアクセスを制限することができます。
Redis ではデータの暗号化形式は直接的にサポートされていないため、すべてのエンコードはクライアント アプリケーションが実行する必要があります。 また、Redis は、どのような形式のトランスポート セキュリティも提供していません。 データがネットワーク内を移動する際に保護する必要がある場合、SSL プロキシを実装することをお勧めします。
詳細については、Redis Web サイトの「 Redis Security (Redis のセキュリティ)」のページを参照してください。
注意
Azure Cache for Redis には、クライアントが接続する独自のセキュリティ層があります。 基になる Redis サーバーは、パブリック ネットワークには公開されません。
Azure Redis Cache
Azure Cache for Redis は、Azure データセンターでホストされている Redis サーバーへのアクセスを提供します。 Azure Redis Cache はアクセス制御とセキュリティを提供するファサードとして機能します。 Azure ポータルを使用して、キャッシュをプロビジョニングすることができます。
ポータルには、定義済みの構成が多数用意されています。 具体的には、SSL 通信 (プライバシー用) と、99.9% の可用性を持つサービス レベル アグリーメント (SLA) とのマスター/下位のレプリケーションをサポートする専用サービスとして実行される 53 GB キャッシュから、共有ハードウェア上で実行される、レプリケーションを持たない (可用性の保証がない) 250 MB キャッシュがあります。
Azure ポータルを使用する場合、キャッシュの削除ポリシーを設定したり、提供されるロールにユーザーを追加することでキャッシュへのアクセスを制御したりすることができます。 これらのロールには、メンバーが実行できる操作を定義されており、所有者、共同作業者、閲覧者などがあります。 たとえば、所有者ロールのメンバーは、キャッシュ (セキュリティを含む) とその内容を完全に制御することができ、共同作業者ロールのメンバーはキャッシュ内の情報の読み取りおよび書き込みを行うことができ、閲覧者ロールのメンバーはキャッシュからのデータの取得だけが可能です。
ほとんどの管理タスクは Azure ポータルから実行します。 このため、プログラムを使用した設定の変更機能、Redis サーバーのシャットダウン機能、追加の下位ノードの設定機能、またはディスクへのデータの保存機能など、標準バージョンの Redis で使用可能な管理コマンドの多くは使用できません。
Azure ポータルには、キャッシュのパフォーマンスを監視できるようにする、便利なグラフィカル表示が含まれています。 たとえば、確立されている接続の数、実行された要求の数、読み込みおよび書き込みの量、キャッシュ ミスに対するキャッシュ ヒットの数を確認できます。 この情報を使用してキャッシュの有効性を判断し、必要に応じて、別の構成に切り替えるか、削除ポリシーを変更することができます。
さらに、1 つ以上の重要な指標が想定される範囲を超えた場合に管理者に電子メール メッセージを送信する、アラートを作成することもできます。 たとえば、多数のキャッシュ ミスが発生し、過去 1 時間に指定した値を超えた場合、キャッシュが小さすぎるか、データが削除されるまでの時間が短すぎる可能性があるため、管理者に通知することができます。
また、CPU、メモリ、およびキャッシュのネットワーク使用率を監視することもできます。
詳細と Azure Cache for Redis の作成および設定方法を示す例については、Azure ブログの Azure Cache for Redis の概要のページを参照してください。
セッション状態と HTML 出力のキャッシュ
Azure の Web ロールを使用して実行される ASP.NET Web アプリケーションを構築する場合、セッション状態の情報と HTML 出力を Azure Cache for Redis 内に保存することができます。 Azure Cache for Redis 用のセッション状態プロバイダーを使用すると、ASP.NET Web アプリケーションの複数のインスタンス間でセッション情報を共有できます。これは、クライアント サーバーのアフィニティを使用できず、メモリ内のセッション データをキャッシュするのに適切でない Web ファームの状況で役立ちます。
セッション状態プロバイダーを Azure Cache for Redis と併用すると、次のようないくつかのメリットが得られます。
- セッション状態を多数の ASP.NET Web アプリケーションと共有できます。
- スケーラビリティが向上します。
- 複数のリーダーと単一のライターによる、同じセッション状態データへの制御された同時アクセスをサポートします。
- 圧縮を使用してメモリを節約し、ネットワーク パフォーマンスを改善できます。
詳細については、「Azure Cache for Redis の ASP.NET セッション状態プロバイダー」を参照してください。
注意
Azure 環境の外で実行される ASP.NET アプリケーションには、Azure Cache for Redis 用のセッション状態プロバイダーを使用しないでください。 Azure の外部からのキャッシュへのアクセスで発生する待機時間によって、データをキャッシュするパフォーマンスの利点が失われる可能性があります。
同様に、Azure Cache for Redis 用の出力キャッシュ プロバイダーを使用すると、ASP.NET Web アプリケーションによって生成される HTTP 応答を削減できます。 出力キャッシュ プロバイダーと Azure Cache for Redis を使用すると、複雑な HTML 出力をレンダリングするアプリケーションの応答時間を改善できます。 同様の応答を生成するアプリケーション インスタンスであれば、この HTML 出力を新たに生成するのではなく、キャッシュ内の共有出力フラグメントを利用できます。 詳細については、「Azure Cache for Redis の ASP.NET 出力キャッシュ プロバイダー」を参照してください。
カスタムの Redis キャッシュの構築
Azure Cache for Redis は、基になる Redis サーバーに対するファサードとして機能します。 Azure Redis Cache の対象ではない高度な構成 (53 GB を超えるキャッシュなど) が必要な場合は、Azure Virtual Machines を使用して独自の Redis サーバーを構築し、ホストできます。
このプロセスは、レプリケーションを実装する場合にプライマリと下位のノードとして機能する複数の VM を作成する必要があるため、複雑になる可能性があります。 また、クラスターを作成する場合、複数のプライマリと下位のサーバーが必要になります。 最小限のクラスター化されたレプリケーション トポロジで、高度な可用性とスケーラビリティを提供するには、3 つのペアのプライマリ/下位サーバーとして編成された 6 個以上の VM が必要です (1 つのクラスターには、少なくとも 3 個のプライマリ ノードを含める必要があります)。
待機時間を最小限に抑えるには、各プライマリ/下位のペアは近くに配置する必要があります。 ただし、各ペアは、必要に応じて別のリージョンにある別の Azure データセンターで実行し、最もよく使用するアプリケーションの近くにキャッシュ データを配置することができます。 Azure VM として実行される Redis ノードの構築と構成の例については、Azure の CentOS Linux VM 上での Redis の実行を参照してください。
注意
この方法で独自の Redis キャッシュを実装する場合、サービスを監視、管理、および保護する責任があります。
Redis キャッシュのパーティション分割
キャッシュのパーティション分割では、複数のコンピューター間にキャッシュを分割します。 この構造では、1 つのキャッシュ サーバーを使用することに比べて、次のような複数の利点があります。
- 1 つのサーバーに保存できるサイズよりもはるかに大きなキャッシュを作成できます。
- サーバー間でデータを配布することで、可用性を向上できます。 1 つのサーバーで障害が発生するかアクセスできなくなった場合でも、使用できなくなるのはそのサーバーが保持しているデータだけであり、残りのサーバー上のデータにはアクセスできます。 キャッシュ データはデータベースに保持されているデータの一時的なコピーでしかないので、キャッシュの場合は重大な問題はありません。 サーバー上のキャッシュ データがアクセスできなくなった場合、代わりに別のサーバーにキャッシュできます。
- サーバー間で負荷を分散することで、パフォーマンスとスケーラビリティが向上します。
- 位置情報データを基にアクセスしたユーザーに近づき、待機時間を短縮します。
キャッシュの最も一般的なパーティション分割の形態はシャーディングです。 この方法では、各パーティション (シャード) はそれ自体の Redis キャッシュです。 データは、シャーディング ロジックを使用して特定のパーティションに送られます。シャーディング ロジックではさまざまな方法を使用してデータを配布できます。 「Sharding Pattern (シャーディング パターン)」で、シャーディングの実装について詳しく説明します。
Redis キャッシュでパーティション分割を実装するには、次の方法のいずれかを採用します。
- サーバー側でクエリをルーティングする。 この方法では、クライアント アプリケーションはキャッシュを構成する任意の Redis サーバー (ほとんどの場合は最も近いサーバー) に要求を送信します。 各 Redis サーバーには、保持するパーティションを説明するメタデータが格納され、他のサーバーに配置されたパーティションに関する情報も含まれています。 Redis サーバーは、クライアント要求を調べます。 ローカルで解決できる場合、要求された操作が実行されます。 ローカルで解決できない場合、適切なサーバーに要求が転送されます。 このモデルは Redis クラスタリングによって実装されます。詳細は、Redis Web サイトの「Redis cluster tutorial」(Redis クラスターのチュートリアル) ページに記載されています。 Redis クラスタリングはクライアント アプリケーションにとって透過的なものであり、クライアントを再構成しなくても追加の Redis サーバーをクラスター (および再パーティション分割されたデータ) に追加できます。
- クライアント側でパーティション分割する。 このモデルでは、要求を適切な Redis サーバーにルーティングするロジックは (ほとんどの場合はライブラリの形態で)、クライアント アプリケーションに含まれます。 この方法は Azure Cache for Redis に使用できます。 複数の Azure Cache for Redis を (データ パーティションごとに 1 つ) 作成し、要求を適切なキャッシュにルーティングするクライアント側ロジックを実装します。 パーティション分割の設定を変更する場合 (追加の Azure Cache for Redis を作成するなど) は、クライアント アプリケーションの再構成が必要になることがあります。
- プロキシでパーティション分割する。 この設定では、クライアント アプリケーションは、データのパーティション分割方法を理解し適切な Redis サーバーに要求をルーティングする中間プロキシ サービスに要求を送信します。 この方法も Azure Cache for Redis で使用できます。プロキシ サービスは、Azure クラウド サービスとして実装することができます。 この方法では複雑さのレベルを追加してサービスを実装する必要があり、クライアント側でのパーティション分割よりも要求の実行に時間がかかる場合があります。
Redis Web サイトの「 Partitioning: how to split data among multiple Redis instances 」(パーティション分割: 複数の Redis インスタンス間でデータを分割する方法) ページに、Redis へのパーティション分割の実装に関する詳細情報が記載されています。
Redis キャッシュ クライアント アプリケーションを実装する
Redis は、さまざまなプログラミング言語で記述されたクライアント アプリケーションをサポートします。 .NET Framework を使用して新しいアプリケーションを作成する場合は、StackExchange.Redis クライアント ライブラリを使用することをお勧めします。 このライブラリは Redis サーバーへの接続、コマンドの送信、および応答の受信の詳細を抽象化する .NET Framework のオブジェクト モデルを提供します。 このライブラリは NuGet パッケージとして Visual Studio で入手できます。 この同じライブラリを使用すると、Azure Cache for Redis または VM でホストされているカスタムの Redis Cache に接続することができます。
Redis サーバーに接続するには、ConnectionMultiplexer クラスの静的な Connect メソッドを使用します。 このメソッドで作成される接続は、クライアント アプリケーションの有効期間中は使用できるように設計されています。また、同じ接続を複数の同時スレッドで使用できます。 Redis 操作を実行するたびに再接続と切断を繰り返さないでください。パフォーマンスが低下する可能性があります。
Redis ホストのアドレスやパスワードなどの接続パラメーターを指定できます。 Azure Cache for Redis を使用する場合、このパスワードは、Azure portal を使用して Azure Cache for Redis 用に生成されたプライマリまたはセカンダリ キーになります。
Redis サーバーに接続すると、キャッシュとして機能する Redis データベースを操作できます。 Redis 接続では、これを行う GetDatabase メソッドが提供されます。 キャッシュから項目を取得したりキャッシュにデータを格納したりするには、StringGet メソッドと StringSet メソッドを使用します。 これらのメソッドにはパラメーターとしてキーを指定する必要があります。一致する値を持つキャッシュ内の項目 (StringGet) が返されるか、このキーを持つキャッシュに項目が追加されます (StringSet)。
Redis サーバーの場所によっては、多くの操作で、要求がサーバーに転送され応答がクライアントに返されるまでの待機時間が発生する可能性があります。 StackExchange ライブラリには、クライアント アプリケーションの応答性を保つために公開されている、非同期バージョンのメソッドが多数あります。 これらのメソッドは、.NET Framework の タスクベースの非同期パターン をサポートします。
次のコード スニペットは、 RetrieveItemというメソッドの例です。 これは、Redis と StackExchange ライブラリに基づくキャッシュアサイド パターンの実装例です。 このメソッドは、文字列のキー値を取り、StringGetAsync メソッド (非同期バージョンの StringGet) を呼び出すことによって Redis キャッシュから対応する項目を取得しようとします。
項目が見つからない場合、GetItemFromDataSourceAsync メソッド (ローカル メソッドであり、StackExchange ライブラリには含まれません) を使用して基になるデータ ソースから取得されます。 次に、StringSetAsync メソッドを使用してキャッシュに追加されます。次回から、すばやく取得できるようになります。
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
StringGet メソッドと StringSet メソッドは、文字列値の取得または保存に制限されていません。 これらのメソッドには、バイトの配列としてシリアル化された項目を使用できます。 .NET オブジェクトを保存する必要がある場合は、バイト ストリームとしてシリアル化し、 StringSet メソッドを使用してキャッシュに書き込むことができます。
同様に、 StringGet メソッドを使用してキャッシュからオブジェクトを読み取り、.NET オブジェクトとして逆シリアル化できます。 次のコードは、IDatabase インターフェイスの一連の拡張メソッド (Redis 接続のGetDatabase メソッドは IDatabase オブジェクトを返します) と、これらのメソッドを使用して BlogPost オブジェクトを読み取りキャッシュに書き込むサンプル コードを示しています。
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
次のコードに示す RetrieveBlogPost という名前のメソッドは、これらの拡張メソッドを使用してシリアル化可能な BlogPost オブジェクトを読み取り、キャッシュアサイド パターンに従ってキャッシュに書き込みます。
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
Redis は、クライアント アプリケーションが複数の非同期要求を送信する場合のコマンド パイプライン処理をサポートします。 Redis は、厳密な順序でコマンドを受信して応答するのではなく、同じ接続を使用して要求を多重化できます。
この方法では、ネットワークの使用効率を高めて待機時間を短縮できます。 次のコード スニペットに、同時に 2 人の顧客の詳細を取得する例を示します。 このコードは、2 つの要求を送信後、結果の受信を待機する前に他の処理 (ここでは示されていません) を実行します。 キャッシュ オブジェクトの Wait メソッドは、.NET Framework の Task.Wait メソッドに似ています。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Azure Cache for Redis を使用できるクライアント アプリケーションの作成について詳しくは、「Azure Cache for Redis のドキュメント」をご覧ください。 詳細については、StackExchange.Redis も参照してください。
また同サイトの「 Pipelines and multiplexers (パイプラインとマルチプレクサー)」のページには、Redis と StackExchange ライブラリを使用した非同期操作とパイプライン処理が詳しく説明されています。
Redis のキャッシュの使用
キャッシュの問題に Redis を使用する最も簡単な例は、キーと値のペアです。この値は、任意のバイナリ データを含む可能性がある、任意の長さの解釈されていない文字列です (値は、基本的に、文字列として扱うことができるバイトの配列です)。 このシナリオについては、この記事の「Redis Cache クライアント アプリケーションを実装する」セクションで説明しました。
キーには解釈されていないデータも含まれるので、任意のバイナリ情報をキーとして使用できます。 ただし、キーが長くなるほど、保存に必要な領域が多くなり、参照操作にも時間がかかるようになります。 使いやすさと保守のしやすさを考慮して、キースペースは慎重に設計し、意味のある (しかし冗長ではない) キーを使用してください。
たとえば ID が 100 の顧客のキーを表す場合は、単純に “100” とするのではなく、“customer:100” のような構造化されたキーを使用します。 このような設定にすると、さまざまなデータ型を格納する複数の値を簡単に区別することができます。 たとえば ID が 100 の注文のキーを表すために、キー “orders:100” を使用することもできます。
Redis のキー/値のペアの値には、1 次元のバイナリ文字列以外にも、リスト、セット (並べ替えあり、並べ替えなし)、ハッシュなどのより構造化された情報も格納できます。 Redis には、これらの型を操作できる包括的なコマンド セットが用意されています。これらのコマンドの多くは StackExchange などのクライアント ライブラリを介して .NET Framework アプリケーションで使用できます。 Redis Web サイトの「An introduction to Redis data types and abstractions」(Redis のデータ型と抽象化の概要) ページに、これらの型と操作に使用できるコマンドのより詳細な概要が記載されています。
このセクションでは、これらのデータ型とコマンドの一般的なユースケースをいくつか示します。
アトミック操作とバッチ操作を実行する
Redis は、文字列値を取得および設定する一連のアトミック操作をサポートします。 これらの操作では、GET コマンドと SET コマンドを個別に使用するときに発生する可能性のある競合状態によるハザードを排除します。 次の操作を使用できます。
INCR、INCRBY、DECR、およびDECRBYは、整数データ値をインクリメントおよびデクリメントするアトミック操作を実行します。 StackExchange ライブラリには、これらの操作を実行し、キャッシュに格納された結果の値を返すオーバーロード バージョンのIDatabase.StringIncrementAsyncメソッドとIDatabase.StringDecrementAsyncメソッドがあります。 次のコード スニペットに、これらのメソッドを使用する方法を示します。ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSETは、キーに関連付けられている値を取得し、新しい値に変更します。 StackExchange ライブラリでは、この操作をIDatabase.StringGetSetAsyncメソッドで実行できます。 以下のコード スニペットに、このメソッドの例を示します。 このコードは、前の例のキー "data:counter" と関連付けられている現在の値を返します。 また、同じ操作の一環でこのキーの値はゼロにリセットされます。ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGETとMSETは、単一の操作として、一連の文字列値を返すか変更します。IDatabase.StringGetAsyncメソッドとIDatabase.StringSetAsyncメソッドは、次の例のように、この機能をサポートするためにオーバーロードされます。ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
この記事の「Redis のトランザクションとバッチ」セクションで説明したように、複数の操作を組み合わせて 1 つの Redis トランザクションにすることもできます。 StackExchange ライブラリは、ITransaction インターフェイスを介してトランザクションをサポートします。
IDatabase.CreateTransaction メソッドを使用して、ITransaction オブジェクトを作成します。 ITransaction オブジェクトに用意されているメソッドを使用して、トランザクションに対してコマンドを実行します。
ITransaction インターフェイスは、すべてのメソッドが非同期であるという点以外は IDatabase インターフェイスからのアクセスと同様の、メソッドのセットに対するアクセスを提供します。 つまり、ITransaction.Execute メソッドが呼び出されたときにのみ実行されます。 ITransaction.Execute メソッドから返される値は、トランザクションが正常に作成されたか (true) 作成に失敗したか (false) を示します。
次のコード スニペットに、同じトランザクションの中で 2 つのカウンターをインクリメントおよびデクリメントする例を示します。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Redis トランザクションはリレーショナル データベースのトランザクションとは異なることに注意してください。 Execute メソッドは、実行するトランザクションを構成するすべてのコマンドをキューに登録するだけです。コマンドのいずれかの形式が正しくない場合は、トランザクションは停止されます。 すべてのコマンドが正常にキューに登録されると、各コマンドは非同期的に実行されます。
いずれかのコマンドが失敗した場合にも、他のコマンドは継続して処理されます。 コマンドが正常に完了したことを確認する必要がある場合は、上の例に示すように、対応するタスクの Result プロパティを使用してコマンドの結果を取得する必要があります。 タスクが完了するまで、 Result プロパティの読み取りは呼び出しスレッドをブロックします。
詳細については、Redis のトランザクションに関するページを参照してください。
バッチ操作を実行するには、StackExchange ライブラリの IBatch インターフェイスを使用します。 このインターフェイスは、すべてのメソッドが非同期であるという点以外は IDatabase インターフェイスからのアクセスと同様の、メソッドのセットに対するアクセスを提供します。
次の例のように、IDatabase.CreateBatch メソッドを使用して IBatch オブジェクトを作成してから、IBatch.Execute メソッドを使用してバッチを実行します。 このコードでは、単純に文字列値を設定し、前の例で使用したのと同じカウンターをインクリメントおよびデクリメントして結果を表示します。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
トランザクションとは異なり、バッチ内の 1 つのコマンドの形式が不適切で失敗した場合でも、他のコマンドは実行できることがあります。 IBatch.Execute メソッドは、成功または失敗を示す値を返しません。
ファイア アンド フォーゲット キャッシュ操作を実行する
Redis は、コマンドのフラグを使用することでファイア アンド フォーゲット操作をサポートします。 この場合は、クライアントは操作を開始するだけで、結果は考慮せず、コマンドの完了も待機しません。 以下の例に、ファイア アンド フォーゲット操作として INCR コマンドを実行する方法を示します。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
自動的に期限切れになるキーを指定する
Redis キャッシュに項目を格納するときに、項目をキャッシュから自動的に削除するまでのタイムアウトを指定できます。 また、 TTL コマンドを使用して、期限切れまでのキーの有効期間をクエリすることもできます。 このコマンドは、 IDatabase.KeyTimeToLive メソッドを使用することで StackExchange アプリケーションに使用できます。
次のコード スニペットは、キーに 20 秒の有効期限を設定して、キーの残り時間をクエリする例です。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
EXPIRE コマンドを使用すると有効期限を特定の日時に設定することもできます。このコマンドは、StackExchange ライブラリでは KeyExpireAsync メソッドとして使用できます。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
ヒント
DEL コマンドを使用して 項目をキャッシュから手動で削除できます。このコマンドは、StackExchange ライブラリの IDatabase.KeyDeleteAsync メソッドとして使用できます。
タグを使用するキャッシュされた項目のクロス関連付け
Redis セットは、1 つのキーを共有する複数の項目のコレクションです。 セットを作成するには、SADD コマンドを使用します。 セット内の項目は、SMEMBERS コマンドを使用して取得できます。 StackExchange ライブラリは、IDatabase.SetAddAsync メソッドで SADD コマンドを実装し、IDatabase.SetMembersAsync メソッドで SMEMBERS コマンドを実装します。
SDIFF (差集合) コマンド、SINTER (積集合) コマンド、および SUNION (和集合) コマンドを使用して、既存のセットを組み合わせて新しいセットを作成することもできます。 StackExchange ライブラリは、 IDatabase.SetCombineAsync メソッドでこれらの操作を統合します。 このメソッドの 1 つ目のパラメーターで、実行するセット操作を指定します。
次のコード スニペットに、関連する項目のコレクションをすばやく格納したり取得したりするのにセットがどれほど威力を発揮するかを示します。 このコードでは、この記事の「Redis Cache クライアント アプリケーションを実装する」セクションで説明した BlogPost 型を使用します。
BlogPost オブジェクトには 4 つのフィールド (ID、タイトル、順位付けスコア、タグのコレクション) が含まれています。 以下の最初のコード スニペットに、 BlogPost オブジェクトの C# コードのリストを設定するために使用するサンプル データを示します。
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
各 BlogPost オブジェクトのタグをセットとして Redis キャッシュに格納し、各セットに BlogPost の ID を関連付けることができます。 これにより、特定のブログの投稿に属するすべてのタグをアプリケーションですばやく検索できます。 逆引き検索を有効にして、特定のタグを共有するすべてのブログの投稿を検索するには、キーに含まれるタグ ID を参照するブログの投稿を保持する別のセットを作成します。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
これらの構造によって、多くの一般的なクエリを非常に効率よく実行することができます。 たとえば、次のようにすると、ブログの投稿 1 のすべてのタグを検索して表示できます。
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
次のような積集合演算を実行することで、ブログの投稿 1 とブログの投稿 2 に共通するすべてのタグを検索できます。
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
また、次のようにすると、特定のタグを含むすべてのブログの投稿を検索できます。
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
最近アクセスした項目を検索する
多くのアプリケーションに伴う共通のタスクに、最近アクセスした項目の検索があります。 たとえば、あるブログ サイトで最近読まれたブログの投稿を表示する必要があるとしましょう。
この機能を実装するには、Redis リストを使用します。 Redis リストには、同じキーを共有する複数の項目が含まれています。 リストは、両端キューとして動作します。 LPUSH (左プッシュ) コマンドと RPUSH (右プッシュ) コマンドを使用すると、リストのどちら側の終端にも項目をプッシュできます。 LPOP コマンドと RPOP コマンドを使用すると、リストのどちら側の終端からも項目を取得できます。 LRANGE コマンドと RRANGE コマンドを使用すると、要素のセットを返すこともできます。
以下のコード スニペットに、StackExchange ライブラリを使用してこれらの操作を実行する方法を示します。 このコードでは、これまでの例の BlogPost 型を使用します。 ユーザーがブログ投稿を読むと、IDatabase.ListLeftPushAsync メソッドによって、Redis Cache 内のキー "blog:recent_posts" と関連付けられたリストにブログ投稿のタイトルがプッシュされます。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
さらに別のブログ投稿が読まれたときにも、それらのタイトルは同じリストにプッシュされます。 リストは、タイトルが追加された順に並べられます。 最近読まれたブログ投稿は、リストの左側にあります。 (同じブログ投稿が複数回読まれると、リストに複数のエントリが生成されます)。
IDatabase.ListRange メソッドを使用すると、最近読まれた投稿のタイトルを表示できます。 このメソッドは、リスト、開始位置、および終了位置を含むキーを取ります。 次のコードでは、リストの左端から 10 個のブログの投稿 (0 ~ 9 の項目) のタイトルを取得します。
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
ListRangeAsync メソッドでは、リストから項目は削除されません。 削除するには、IDatabase.ListLeftPopAsync メソッドと IDatabase.ListRightPopAsync メソッドを使用できます。
リストが無制限に大きくなるのを回避するには、定期的にリストをトリミングすることで項目の数を減らします。 次のコード スニペットは、リストの左から 5 個の項目を除き、すべての項目を削除する方法の例です。
await cache.ListTrimAsync(redisKey, 0, 5);
スコア ボードを実装する
既定では、セット内の項目は特定の順序で保持されていません。 ZADD コマンド (StackExchange ライブラリの IDatabase.SortedSetAdd メソッド) を使用すると、順序付けされたセットを作成することができます。 項目は、コマンドのパラメーターとして指定する、スコアと呼ばれる数値を使用して並べます。
次のコード スニペットでは、ブログの投稿のタイトルを順序付きリストに追加します。 この例では、各ブログの投稿にもブログの投稿の順位を含むスコア フィールドが設定されています。
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
IDatabase.SortedSetRangeByRankWithScores メソッドを使用すると、スコアの昇順で、ブログ投稿のタイトルとスコアを取得できます。
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
注意
StackExchange ライブラリには、スコアの順序でデータを返す IDatabase.SortedSetRangeByRankAsync メソッドもあります。ただしこのメソッドは、スコアは返しません。
IDatabase.SortedSetRangeByRankWithScoresAsync メソッドに追加のパラメーターを指定することで、スコアの降順でも項目を取得でき、返される項目の数を制限することもできます。 次の例では、上位 10 個のブログの投稿のタイトルとスコアを表示します。
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
次の例では、IDatabase.SortedSetRangeByScoreWithScoresAsync メソッドを使用しています。特定のスコアの範囲に含まれる項目を返すように制限するために使用できます。
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
チャネルを使用するメッセージ
Redis サーバーは、データ キャッシュとして機能する以外にも、高パフォーマンスのパブリッシャー/サブスクライバー メカニズムを使用してメッセージング機能を提供します。 クライアント アプリケーションはチャネルにサブスクライブし、他のアプリケーションまたはサービスはチャネルにメッセージを発行できます。 サブスクライブしているアプリケーションは、これらのメッセージを受信し、処理することができます。
Redis には、チャネルにサブスクライブするために使用できるクライアント アプリケーション用の SUBSCRIBE コマンドがあります。 このコマンドでは、アプリケーションがメッセージを受け入れるチャネルの名前を 1 つまたは複数指定する必要があります。 StackExchange ライブラリには ISubscription インターフェイスが含まれ、これにより .NET Framework アプリケーションはチャネルに対するサブスクライブと発行を行うことができます。
Redis サーバーへの接続の GetSubscriber メソッドを使用して、ISubscription オブジェクトを作成します。 次に、このオブジェクトの SubscribeAsync メソッドを使用して、チャネル上のメッセージをリッスンします。 次のコード例に、“messages:blogPosts” という名前のチャネルをサブスクライブする方法を示します。
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
Subscribe メソッドの最初のパラメーターは、チャネルの名前です。 この名前は、キャッシュ内のキーと同じ命名規則に従います。 名前にはバイナリ データを含めることもできますが、比較的短く、意味のある文字列を使用して、適切なパフォーマンスと保守のしやすさを確保することをお勧めします。
また、チャネルから使用される名前空間は、キーに使用される名前空間とは別である点にも注意してください。 同じ名前のチャネルとキーを使用することはできますが、アプリケーション コードの保守が困難になる可能性があるためです。
2 番目のパラメーターは、Action デリゲートです。 このデリゲートは、チャネルに新しいメッセージが出現するたびに、非同期に実行されます。 この例では、単にコンソールにメッセージを表示します (メッセージには、ブログの投稿のタイトルが含まれます)。
チャネルに発行するには、アプリケーションで Redis PUBLISH コマンドを使用します。 StackExchange ライブラリは、この操作を実行する IServer.PublishAsync メソッドを提供します。 次のコード スニペットに、“messages:blogPosts” チャネルにメッセージを発行する方法を示します。
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
発行/サブスクライブ メカニズムについて理解しておくべき点がいくつかあります。
- 複数のサブスクライバーが同じチャネルにサブスクライブでき、すべてのサブスクライバーがそのチャネルに発行されたメッセージを受信します。
- サブスクライバーは、サブスクライブした後に発行されたメッセージのみを受信します。 チャネルはバッファリングされません。メッセージが発行されると、Redis インフラストラクチャは各サブスクライバーにメッセージをプッシュし、メッセージを削除します。
- 既定では、サブスクライバーは、送信された順序でメッセージを受信します。 メッセージの数が多く、サブスクライバーとパブリッシャーの数も多い稼働率の高いシステムでは、メッセージの順次配信を保証すると、システムのパフォーマンスが低下する可能性があります。 各メッセージが独立していて順序が重要ではない場合は、Redis システムによる同時処理を有効にして、応答性を高めることができます。 StackExchange クライアントでこれを実現するには、サブスクライバーで使用する接続の PreserveAsyncOrder を false に設定します。
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
シリアル化に関する考慮事項
シリアル化形式を選択した場合は、パフォーマンス、相互運用性、バージョン管理、既存のシステムとの互換性、データ圧縮、およびメモリのオーバーヘッドとのトレードオフを考慮します。 パフォーマンスを評価するときは、ベンチマークがコンテキストに強く依存していることに注意してください。 これらは、実際のワークロードを表してない場合があり、新しいライブラリまたはバージョンが考慮されていない可能性があります。 すべてのシナリオに対応できる単一の「最高速」シリアライザーはありません。
次のような点を検討します。
Protocol Buffers (protobuf とも呼ばれます) は、構造化データを効率的にシリアル化するために Google によって開発されたシリアル化形式です。 メッセージの構造を定義するために厳密に型指定された定義ファイルを使用します。 これらの定義ファイルは、メッセージのシリアル化と逆シリアル化のために言語固有コードにコンパイルされます。 Protobuf は、既存の RPC メカニズムで使用することも、または RPC サービスを生成することもできます。
Apache Thrift は、厳密に型指定されたファイルとコンパイル手順を使用する同様のアプローチを使用して、シリアル化コードと RPC サービスを生成します。
Apache Avro は、Protocol Buffers および Thrift と同様の機能を提供しますが、コンパイル手順はありません。 代わりに、シリアル化されたデータには、必ず、構造を記述するスキーマが含まれます。
JSON は、人間が判読できるテキスト フィールドを使用するオープン スタンダードです。 このスタンダードは、幅広い種類のプラットフォームをサポートします。 JSON では、メッセージ スキーマは使用しません。 テキスト ベース形式であるため、ネットワーク上の効率があまり高くありません。 ただし、場合によっては、キャッシュされた項目を HTTP 経由でクライアントに直接返すこともあり、この場合、JSON で保存することで、他の形式からの逆シリアル化を行ってから JSON のためにシリアル化するコストが節約できます。
バイナリ JSON (BSON) は、JSON に類似した構造を使用するバイナリのシリアル化形式です。 BSON は、JSON に比較して、軽量で、簡単にスキャンでき、高速で逆シリアル化できるように設計されています。 ペイロードは、JSON のサイズに相当します。 データによっては、BSON ペイロードのサイズが、JSON ペイロードより増減する可能性があります。 BSON には、BinData (バイト配列用) および Date などの、JSON にはない追加のデータ型があります。
MessagePack は、ネットワーク経由での転送サイズを小型化するように設計されたバイナリのシリアル化形式です。 メッセージ スキーマやメッセージ型のチェックはありません。
Bond は、スキーマ化されたデータを扱うためのクロスプラットフォーム フレームワークです。 異なる言語間のシリアル化および逆シリアル化をサポートします。 ここに記載されているその他のシステムとの重要な違いは、継承、型の別名およびジェネリックです。
gRPC は、Google によって開発されたオープン ソース RPC システムです。 既定では、定義言語および基本的なメッセージ交換形式として Protocol Buffers を使用します。
次のステップ
- Azure Cache for Redis のドキュメント
- Azure Cache for Redis に関する FAQ
- タスク ベースの非同期パターン
- Redis のドキュメント
- StackExchange.Redis
- データのパーティション分割のガイド
関連リソース
次のパターンは、アプリケーションでキャッシュを実装するときのシナリオにも関連することがあります。
キャッシュ アサイド パターン:このパターンでは、データ ストアからキャッシュにデータをオンデマンドで読み込む方法について説明します。 このパターンは、キャッシュに保持されているデータと、元のデータ ストア内のデータの一貫性の維持にも役立ちます。
シャーディング パターン : このパターンは、水平方向のパーティション分割に関する情報を提供し、大量のデータを格納したりそれらのデータにアクセスしたりするときのスケーラビリティを向上させます。