Team Data Science Process ライフサイクルのビジネスの把握ステージ
この記事では、Team Data Science Process (TDSP) のビジネスの把握ステージに関連付けられている目標、タスク、成果物のアウトラインを示します。 このプロセスは、チームがデータサイエンスプロジェクトを構築するために使用できる推奨ライフサイクルを提供します。 ライフサイクルは、チームが (多くの場合、反復的に) 実行する主要なステージの概要を示します。
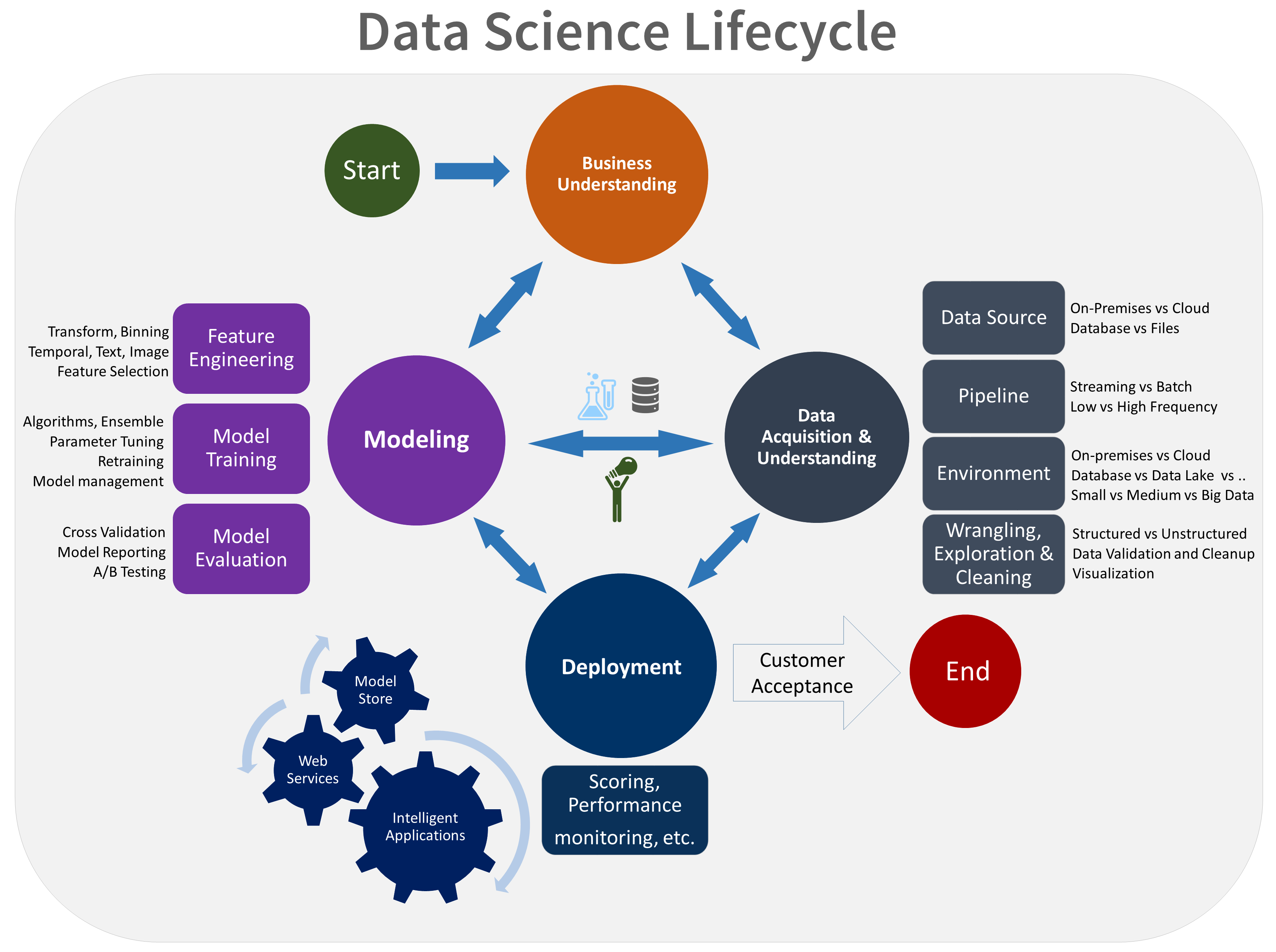
- ビジネスの把握
- データの取得と理解
- モデリング
- デプロイ
- 顧客による受け入れ
TDSPライフサイクルの視覚的な表現を次に示します。
目標
ビジネス理解ステージの目標は次のとおりです。
モデルターゲットとして機能する主要な変数を指定します。 また、プロジェクトの成功を決定するターゲットのメトリックを指定します。
ビジネスがアクセスできるまたは取得する必要がある、関連性のあるデータ ソースを特定する。
タスクを完了する方法
ビジネス理解ステージには、2つの主要なタスクがあります。
目標を定義する: 顧客およびその他の利害関係者と連携し、ビジネス上の問題を把握し、特定します。 データ サイエンス手法のターゲットにできるような、ビジネスの目標を定義付ける質問を考案します。
データ ソースを特定する: プロジェクトの目標を定義付ける質問に対して答えを出すために利用できる関連データを見つけます。
目標を定義する
このステージの主な目的は、分析で予測する必要がある主要なビジネス変数を特定することです。 これらの変数はモデルターゲットと呼ばれ、それらに関連付けられたメトリックを使用してプロジェクトの成功を判断します。 たとえば、売上予測や注文が不正である確率などがターゲットになります。
プロジェクトの目標を定義するには、関連性があり、具体的で、明確な鋭い質問をして調整します。 データ サイエンスは、名前と数字を使用してこのような質問に回答するプロセスです。 データ サイエンスや機械学習は、一般的には以下の 5 種類の質問に回答するために使用されます。
- どのくらいの量または数か (回帰)
- どのカテゴリか (分類)
- どのグループか (クラスタリング)
- これは異常ですか。 (異常の検出)
- どの選択肢を選ぶべきか (推奨)
どのような質問をするか、またその質問に答えることがビジネス目標の達成にどのように役立つかを決定します。
プロジェクトチームを定義するには、そのメンバーの役割と責任を指定します。 見つかる情報の増加に伴い繰り返し実行する、大まかなマイルストーン プランを作成します。
成功の測定基準を定義する必要があります。 たとえば、顧客離れの予測を3か月のプロジェクトの終わりまでにx%の精度で達成する必要があるとします。 このデータを使用して、顧客離れを減らすためのプロモーションを実施できます。 SMART (スマート) なメトリックを定義する必要があります。
- Specific (具体的)
- Measurable (測定可能)
- Achievable (達成可能)
- Relevant (関連性がある)
- Time-bound (期限付き)
データ ソースを特定する
質問に対する既知の回答例を含むデータソースを特定します。 以下のようなデータを探します。
- 質問に対して関連性のあるデータ。 ターゲットの測定値と、ターゲットに関連する特徴があるか。
- モデル ターゲットの正確な測定値であるデータと、対象とする特徴。
たとえば、既存のシステムには、問題に対処してプロジェクトの目標を達成するために必要なデータがない場合があります。 このような状況では、外部データソースを見つけたり、システムを更新して新しいデータを収集したりすることが必要になる場合があります。
MLflowとの統合
ビジネスの理解段階では、チームはMLflowツールを使用しませんが、MLflowのドキュメントと実験追跡機能から間接的にメリットを得ることができます。 これらの機能は、プロジェクトをビジネス目標に合わせるための洞察と履歴コンテキストを提供できます。
Artifacts
このステージでは、チームは次のものを提供します。
憲章ドキュメント。 チャーター ドキュメントは、常に変化するドキュメントです。 プロジェクト全体を通じて、新しい発見やビジネス要件の変化に応じてドキュメントを更新します。 重要なのは、このドキュメントを反復処理することです。 検出プロセスの進行に応じて詳細を追加します。 顧客やその他の関係者に、変更とその理由を通知します。
データ ソース。 Azure Machine Learningを使用して、データソースの管理を処理できます。 このAzureサービスはMLflowと統合されるため、アクティブで特に大規模なプロジェクトにお勧めします。
データディクショナリ。 このドキュメントでは、クライアントが提供するデータについて説明します。 これらの説明にはスキーマ (データ型、検証ルールに関する情報 (ある場合)) とエンティティ関連の図 (ある場合) に関する情報が含まれています。 チームは、この情報の一部またはすべてを文書化する必要があります。
ピアレビューされた文献
研究者は、査読済み文献でTDSPに関する研究を発表しています。 引用により、他のアプリケーション、または TDSP に似たアイデア (ビジネスの把握に関するライフサイクル ステージなど) を調査する機会が生まれます。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Mark Tabladillo | シニア クラウド ソリューション アーキテクト
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
関連リソース
これらの記事では、TDSPライフサイクルの他のステージについて説明しています。