この記事で説明するアーキテクチャでは、Teradata VantageCloud Enterprise を Azure Data Factory と共に使用して、ローコードまたはコードなしのアプローチでデータ統合パイプラインを作成する方法を示します。 Data Factory を使用して、セキュリティが強化された接続を介して Vantage データをすばやく取り込む、または抽出する方法を示します。
Apache®、Hadoop および炎のロゴは、Apache Software Foundation の米国およびその他の国における登録商標です。 これらの商標を使用することが、Apache Software Foundation による保証を意味するものではありません。
アーキテクチャ
次の図は、仮想ネットワーク ピアリング接続を使用するアーキテクチャのバージョンを示しています。 セルフホステッド統合ランタイム (IR) を使用して分析データベースに接続します。 Teradata の VM は、プライベート IP アドレスのみを使用してデプロイされます。

このアーキテクチャの Visio ファイルをダウンロードします。
次の図は、Azure Private Link の接続を使用するアーキテクチャのバージョンを示しています。

このアーキテクチャの Visio ファイルをダウンロードします。
Azure での VantageCloud Enterprise は、Teradata 所有の Azure サブスクリプションにデプロイされるフル マネージド サービスです。 お客様自身の Azure サブスクリプションにクラウド サービスをデプロイし、承認された接続オプションのいずれかを使用して Teradata マネージド サブスクリプションに接続します。 Teradata では、Azure サブスクリプションと Azure での VantageCloud Enterprise の間で、次の種類の接続がサポートされています。
- 仮想ネットワーク ピアリング
- Private Link
- Azure Virtual WAN
仮想ネットワーク ピアリングを使用する予定の場合、Teradata サポートまたは Teradata アカウント チームと協力して、セルフホステッド IR からデータベースへのトラフィックを仮想ネットワーク ピアリング リンク経由で開始するために必要なセキュリティ グループ設定が設定されていることを確認します。
コンポーネント
このアーキテクチャを実装するには、Data Factory、Azure Blob Storage、Teradata VantageCloud Enterprise、Teradata Tools and Utilities (TTU) について理解しておく必要があります。
統合シナリオでは、次のコンポーネントとバージョンが使用されます。
- Azure でホストされている Teradata VantageCloud Enterprise 17.20
- Azure Data Factory
- Azure Blob Storage
- TTU 17.20
- Teradata ODBC ドライバー 17.20.12
- Teradata Studio 17.20
Teradata 視点
Vantage は、Teradata がパーベイシブ データ インテリジェンスと呼ぶものを提供します。 組織全体のユーザーはこれを使用して、自分の質問に対するリアルタイムでインテリジェントな回答を得ることができます。 このアーキテクチャでは、Azure での Vantage がデータ統合タスクのソースまたは宛先として使用されます。 Vantage の Native Object Storage (NOS) は、Blob Storage 内のデータと統合するために使用されます。
Data Factory
Data Factory は、サーバーレスのクラウド ETL (抽出、変換、読み込み) サービスです。 データ移動と変換を調整して自動化するために使用できます。 データ インジェストと直感的な作成のためのコード不要のユーザー インターフェイスを提供し、1 つのウィンドウから監視と管理を行うことができます。
Data Factory を使用して、データ ストアからデータを取り込むデータ主導ワークフロー (パイプラインと呼ばれます) を作成し、スケジュールを設定できます。 Spark またはコンピューティング サービス (Azure Batch、Azure Machine Learning、Apache Spark、SQL、Hadoop での Azure HDInsight、Azure Databricks など) で実行されるデータフローを使用して、データを視覚的に変換する複雑な ETL プロセスを作成できます。 Data Factory の操作には、次のレイヤーが含まれます。これらは、最高レベルの抽象化からデータに最も近いソフトウェアの順に記載されています。
- パイプラインは、アクティビティとデータ パスを含むグラフィカル インターフェイスです。
- アクティビティは、データに対して操作を実行します。
- ソースとシンクは、データの送信元と移動先を指定するアクティビティです。
- データセットは、Data Factory が取り込み、読み込み、変換する適切に定義された一連のデータです。
- リンク サービスを使用すると、Data Factory は特定の外部データ ソースの接続情報にアクセスできます。
- 統合ランタイム (IR) は、Data Factory とデータまたはコンピューティング リソースの間のゲートウェイを提供します。
セルフホステッド IR
セルフホステッド IR は、クラウド データ ストアとプライベートネットワーク データ ストアの間でコピー操作を実行できます。 オンプレミス ネットワークまたは Azure 仮想ネットワーク内のコンピューティング リソースを変換することもできます。 セルフホステッド IR をインストールするには、プライベート ネットワーク上のローカル コンピューターまたは仮想マシンが必要です。 詳細については、「セルフホステッド IR の使用に関する注意点」をご覧ください。 この記事では、セルフホステッド IR を使用して VantageCloud に接続し、Azure Data Lake Storage に読み込むデータを抽出する方法について説明します。
Teradata コネクタ
このアーキテクチャでは、Data Factory は Vantage に接続するために Teradata コネクタを使用します。 Teradata コネクタでは、以下がサポートされます。
- Teradata バージョン 14.10、15.0、15.10、16.0、16.10、16.20。
- 基本認証、Windows 認証、または LDAP 認証を使用したデータのコピー。
- Teradata ソースからの並列コピー。 詳細については、「Teradata からの並列コピー」をご覧ください。
この記事では、データを Vantage から取り込んで Data Lake Storage に読み込む Data Factory のデータ コピー アクティビティのリンク サービスとデータセットを設定する方法について説明します。
シナリオの詳細
この記事では、次の 3 つのシナリオについて説明します。
- Data Factory がデータを VantageCloud Enterprise からプルし、Blob Storage に読み込む
- Data Factory が Blob Storage から VantageCloud Enterprise にデータを読み込む
- Vantage NOS 機能を使用して、Data Factory によって変換され、Blob Storage に読み込まれたデータにアクセスする
シナリオ 1: VantageCloud から Blob Storage にデータを読み込む
このシナリオでは、Data Factory を使用して VantageCloud Enterprise からデータを抽出し、基本的な変換をいくつか実行してから、Blob Storage コンテナーにデータを読み込む方法について説明します。
このシナリオでは、Data Factory と Vantage 間のネイティブ統合と、エンタープライズ ETL パイプラインを構築して Vantage 内のデータを統合する方法について説明します。
この手順を完了するには、アーキテクチャ図に示すように、サブスクリプションに Blob Storage コンテナーが必要です。
Vantage へのネイティブ コネクタを作成するには、データ ファクトリで [管理] タブ、[リンク サービス]、[新規] の順に選びます。
![[リンク サービス] の [新規] ボタンを示すスクリーンショット。](/ja-jp/azure/architecture/databases/guide/_images/create-linked-service.png)
"Teradata" と検索して Teradata コネクタを選びます。 その後、[続行] を選びます。
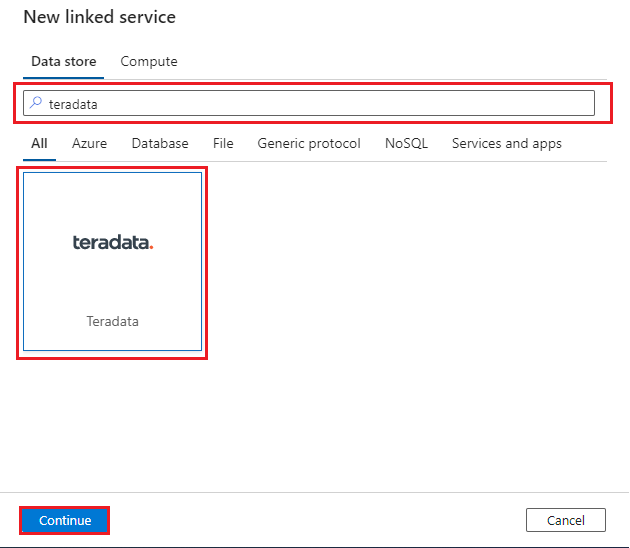
Vantage データベースに接続するようにリンク サービスを構成します。 この手順では、ユーザー ID とパスワードを含む基本認証メカニズムを使用する方法を示します。 または、セキュリティのニーズに応じて、別の認証メカニズムを選択し、それに応じて他のパラメーターを設定することもできます。 詳細については、「Teradata コネクタのリンク サービス プロパティ」をご覧ください。 セルフホステッド IR を使用します。 詳細については、セルフホステッド IR のデプロイに関するこちらの手順をご覧ください。 データ ファクトリと同じ仮想ネットワークにデプロイします。
次の値を使用して、リンク サービスを構成します。
- 名前: リンク サービス接続の名前を入力します。
- 統合ランタイム経由で接続: SelfHostedIR を選びます。
- サーバー名:
- 仮想ネットワーク ピアリング経由で接続する場合、Teradata クラスター内の VM の IP アドレスを指定します。 クラスター内の任意の VM の IP アドレスに接続できます。
- Private Link 経由で接続する場合、仮想ネットワークで作成したプライベート エンドポイントの IP アドレスを指定して、Private Link 経由で Teradata クラスターに接続します。
- 認証の種類: 認証の種類を選びます。 この手順では、基本認証を使用する方法を示します。
- ユーザー名とパスワード: 資格情報を指定します。
- [接続テスト]をクリックし、[作成]をクリックします。 テスト接続機能が機能するように、IR に対してインタラクティブな編集が有効になっていることをご確認ください。
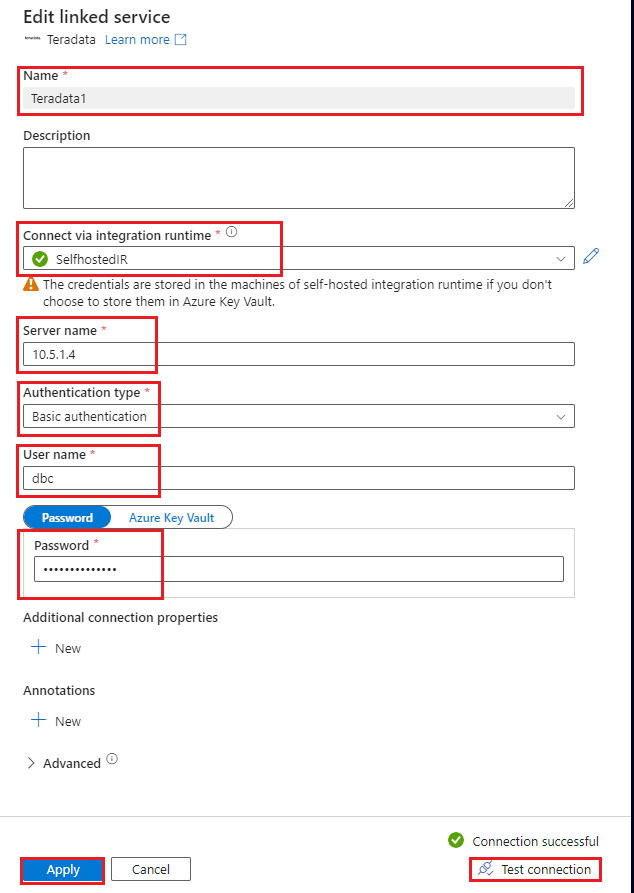
テストでは、
NYCTaxiADFIntegrationと呼ばれる Vantage のテスト データベースを使用できます。 このデータベースには、Green_Taxi_Trip_Dataという名前の単一のテーブルがあります。 データベースは NYC OpenData からダウンロードできます。 次の CREATE TABLE ステートメントは、テーブルのスキーマを理解するのに役立ちます。CREATE MULTISET TABLE NYCTaxiADFIntegration.Green_Taxi_Trip_Data, FALLBACK , NO BEFORE JOURNAL, NO AFTER JOURNAL, CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO, MAP = TD_MAP1 ( VendorID BYTEINT, lpep_pickup_datetime DATE FORMAT ‘YY/MM/DD’, lpep_dropoff_datetime DATE FORMAT ‘YY/MM/DD’, store_and_fwd_flag VARCHAR(1) CHARACTER SET LATIN CASESPECIFIC, RatecodeID BYTEINT, PULocationID SMALLINT, DOLocationID SMALLINT, passenger_count BYTEINT, trip_distance FLOAT, fare_amount FLOAT, extra DECIMAL(18,16), mta_tax DECIMAL(4,2), tip_amount FLOAT, tolls_amount DECIMAL(18,16), ehail_fee BYTEINT, improvement_surcharge DECIMAL(3,1), total_amount DECIMAL(21,17), payment_type BYTEINT, trip_type BYTEINT, congestion_surcharge DECIMAL(4,2)) NO PRIMARY INDEX ;次に、テーブルからデータをコピーし、基本的な変換をいくつか実行し、Blob Storage コンテナーにデータを読み込む単純なパイプラインを作成します。 この手順の冒頭で説明したように、サブスクリプションに Blob Storage コンテナーが既に作成されているはずです。 最初に、コンテナーに接続するリンク サービスを作成します。これは、データのコピー先となるシンクです。
データ ファクトリで [管理] タブ、[リンク サービス]、[新規] の順に選びます。
![[新規] ボタンを示すスクリーンショット。](/ja-jp/azure/architecture/databases/guide/_images/new-linked-service.png)
"Azure Blob" と検索し、Azure Blob Storage コネクタ、[続行] の順に選びます。
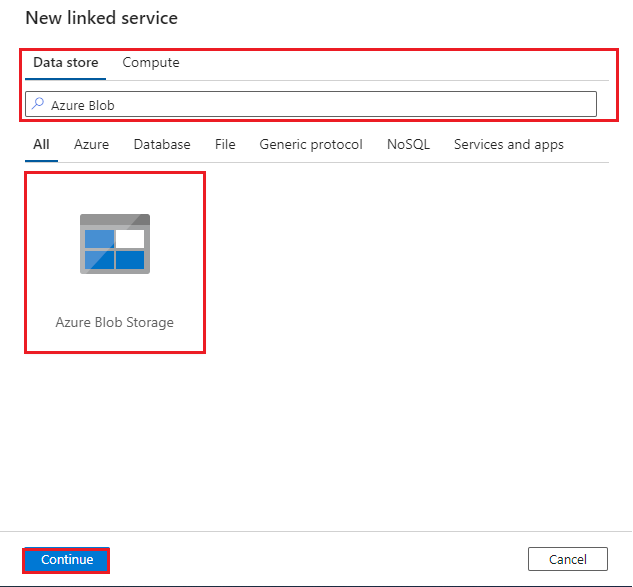
Blob Storage アカウントに接続するリンク サービスを構成します。
- 名前: リンク サービス接続の名前を入力します。
- 統合ランタイム経由で接続: [AutoResolveIntegrationRuntime] を選びます。
- 認証の種類: [アカウント キー] を選びます。
- Azure サブスクリプション: Azure サブスクリプション ID を入力します。
- ストレージ アカウント名: Azure ストレージ アカウント名を入力します。
接続を確認するために [接続テスト] を選び、[作成] を選びます。

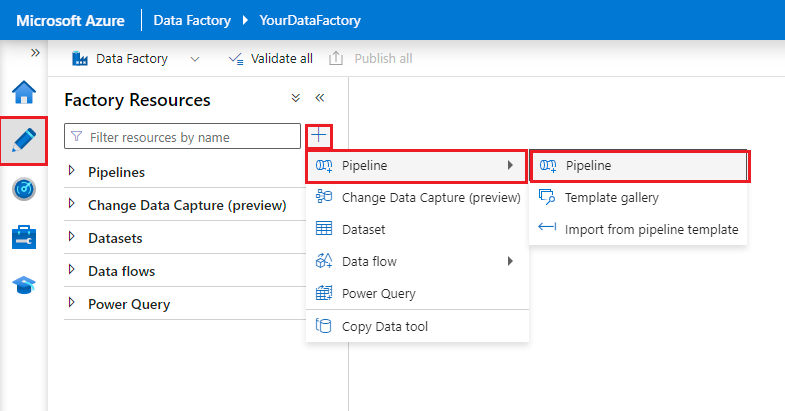
Data Factory パイプラインを作成します。
- [作成者] タブを選択します。
- + ボタンを選択します。
- [パイプライン] を選択します。
- パイプラインの名前を入力します。
2 つのデータセット (
- [作成者] タブを選択します。
- + ボタンを選択します。
- [データセット] を選択します。
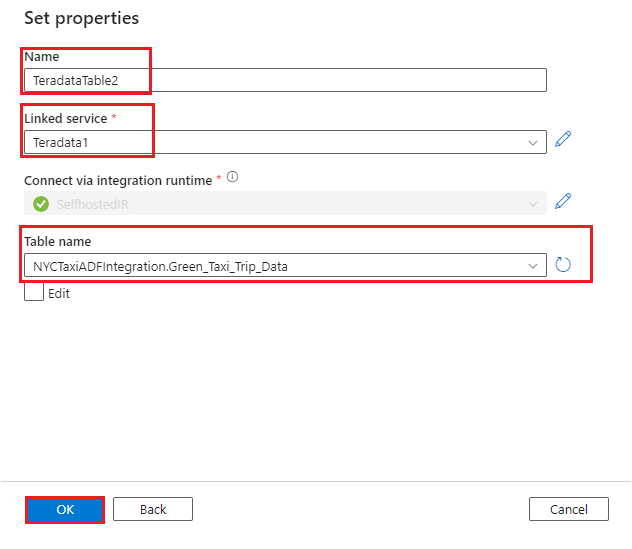
Green_Taxi_Trip_DataTeradata テーブルのデータセットを作成します。
- [データ ストア] として [Teradata] を選びます。
- 名前: データセットの名前を入力します。
- リンク サービス: 手順 2 と 3 で Teradata 用に作成したリンク サービスを選びます。
- テーブル名: 一覧からテーブルを選びます。
- [OK] を選択します。
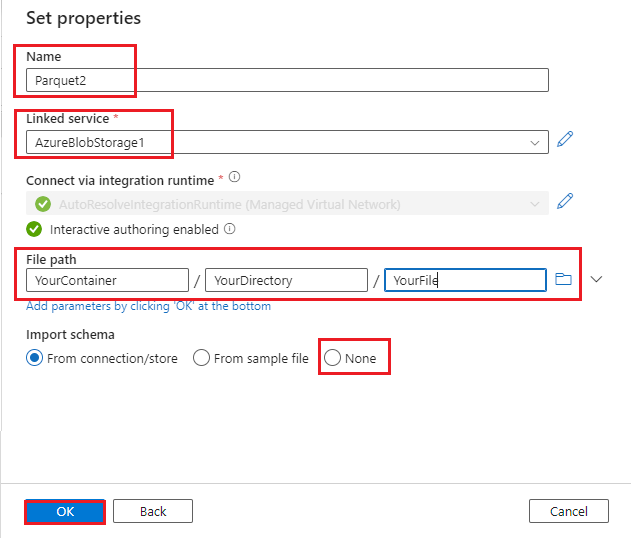
- Azure Blob データセットを作成します。
- [データ ストア] として [Azure Blob] を選びます。
- データの形式を選びます。 このデモでは Parquet を使用します。
- リンク サービス: 手順 6 で作成したリンク サービスを選びます。
- ファイル パス: BLOB ファイルのファイル パスを入力します。
- スキーマのインポート: [なし] を選びます。
- [OK] を選択します。
データ コピー アクティビティをパイプラインにドラッグします。
Note
現在、Teradata コネクタでは、Data Factory の Data Flow アクティビティがサポートされていません。 データに対して変換を実行する場合、Copy アクティビティの後に Data Flow アクティビティを追加することをお勧めします。
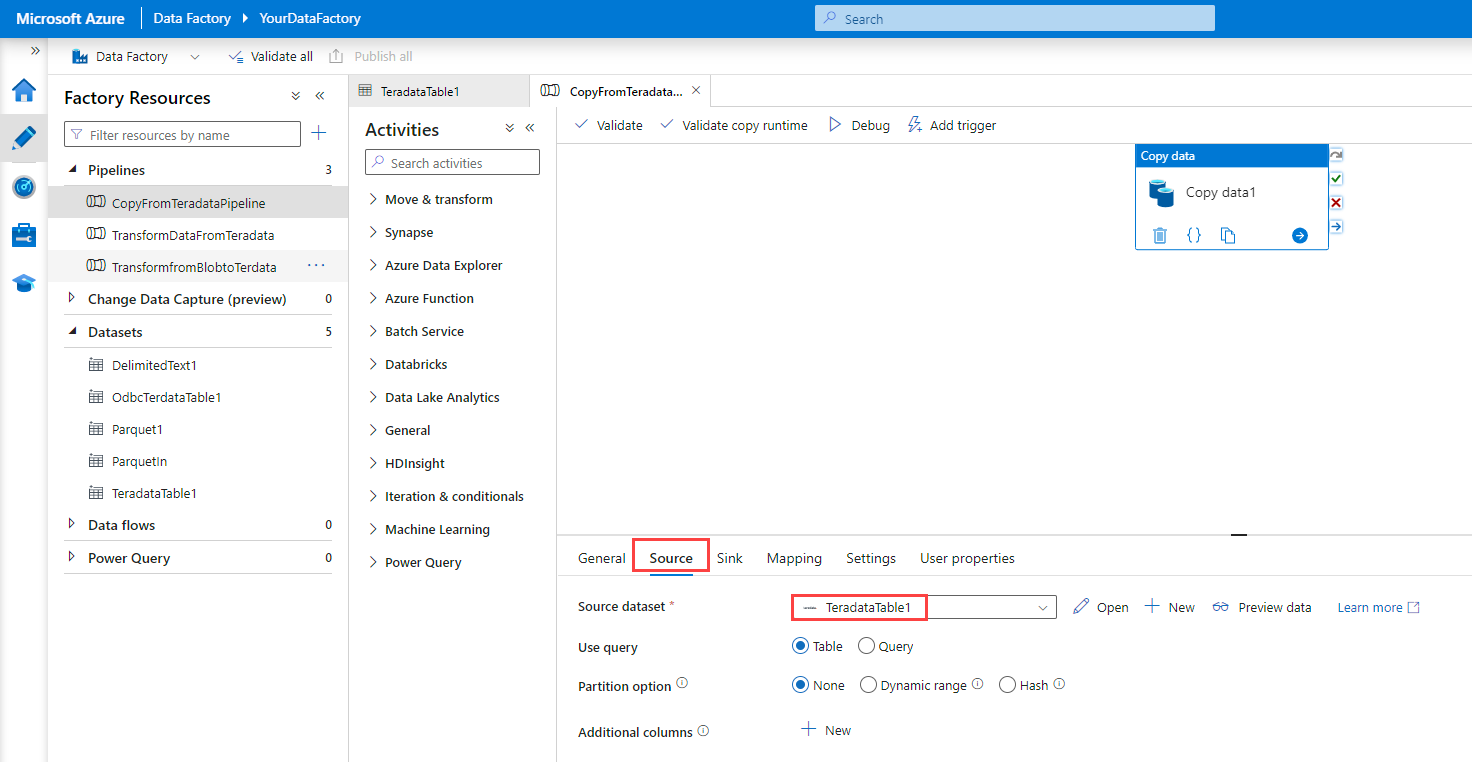
データ コピー アクティビティを構成します。
[ソース] タブの [ソース データセット] で、前の手順で作成した Teradata テーブルのデータセットを選びます。
[クエリの使用] で、[クエリ] を選びます。
他のオプションには既定値をそのまま使用します。
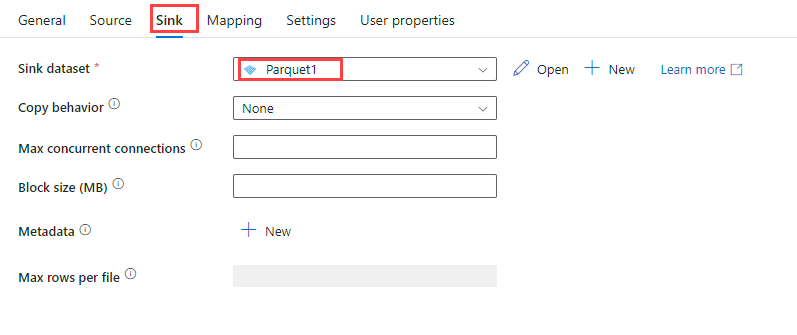
[シンク] タブの [シンク データセット] で、前の手順で作成した Azure Blob データセットを選びます。
他のオプションには既定値をそのまま使用します。
[デバッグ] を選択します。 パイプラインは、Teradata テーブルから Blob Storage 内の Parquet ファイルにデータをコピーします。
![[リンク サービス] の [新規] ボタンを示すスクリーンショット。](/ja-jp/azure/architecture/databases/guide/_images/create-linked-service.png#lightbox)


![[新規] ボタンを示すスクリーンショット。](/ja-jp/azure/architecture/databases/guide/_images/new-linked-service.png#lightbox)







シナリオ 2: VantageCloud から Blob Storage にデータを読み込む
このシナリオでは、ODBC コネクタを使用して、セルフホステッド IR VM 経由で VantageCloud に接続してデータを読む方法について説明します。 IR は Teradata ODBC ドライバーを使用してインストールおよび構成する必要があるため、このオプションは Data Factory のセルフホステッド IR でのみ機能します。
TTU、Data Factory カスタム アクティビティ、Azure Batch を使用して、データを Vantage に読み込んで変換することもできます。 詳細については、「カスタム アクティビティ機能を使用して Teradata Vantage を Azure Data Factory に接続する」をご覧ください。 パフォーマンス、コスト、管理に関する考慮事項について両方のオプションを評価し、お客様の要件に最も適したオプションを選択することをお勧めします。
まず、前のシナリオで作成したセルフホステッド IR を準備します。 それに Teradata ODBC ドライバーをインストールする必要があります。 このシナリオでは、セルフホステッド IR に Windows 11 VM を使用します。
- RDP を使用して VM に接続します。
- Teradata ODBC ドライバーをダウンロードしてインストールします。
- JAVA JRE がまだ VM 上にない場合は、ダウンロードしてインストールします。
ODBC データ ソースを追加して、Teradata データベース用の 64 ビット システム DSN を作成します。
必ず 64 ビット DSN ウィンドウを使用してください。
次のスクリーンショットに示すように、[Teradata データベース ODBC ドライバー] を選びます。
[完了] を選んで、ドライバーのセットアップ ウィンドウを開きます。
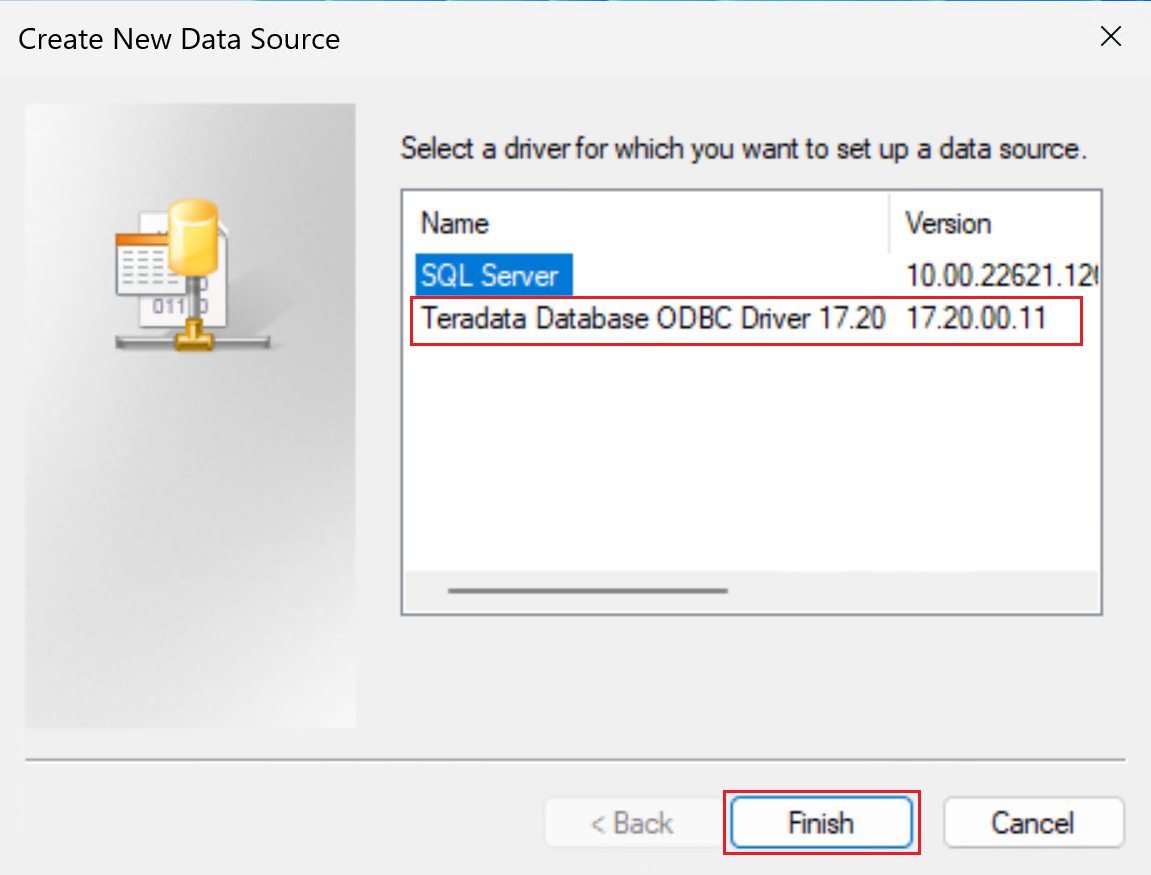
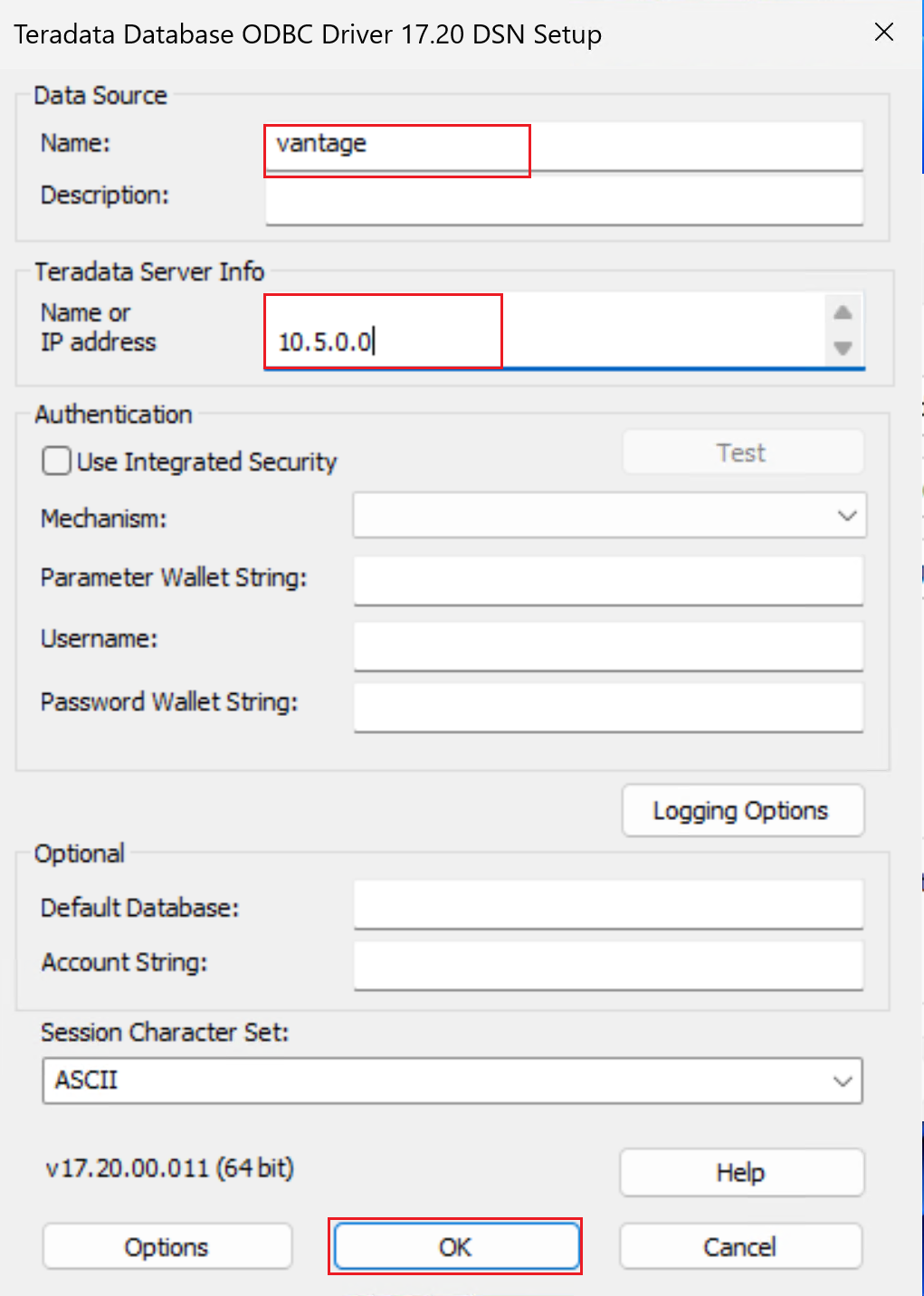
DSN プロパティを構成します。
名前: DSN の名前を入力します。
[Teradata サーバー情報] の [名前] または [IP アドレス] で、次の操作を行います。
- 仮想ネットワーク ピアリング経由で接続する場合、Teradata クラスター内の VM の IP アドレスを指定します。 クラスター内の任意の VM の IP アドレスに接続できます。
- Private Link 経由で接続する場合、仮想ネットワークで作成したプライベート エンドポイントの IP アドレスを指定して、Private Link 経由で Teradata クラスターに接続します。
必要に応じて、[ユーザー名] を指定し、[テスト] を選びます。 資格情報を入力するよう求められます。 [OK] を選び、接続に成功したことを確認します。 Data Factory から Teradata データベースへの接続に使用される ODBC リンク サービスを作成するときに、Data Factory でユーザー名とパスワードを指定します。
その他のフィールドは空のままにしておきます。
[OK] を選択します。
[ODBC データ ソース アドミニストレーター] ウィンドウは、次のスクリーンショットのようになります。 [適用] を選択します。 これで、ウィンドウを終了できます。 セルフホステッド IR が ODBC を使用して Vantage に接続する準備ができました。
![[ODBC データ ソース アドミニストレーター] ウィンドウを示すスクリーンショット。](/ja-jp/azure/architecture/databases/guide/_images/odbc-driver-configuration-2.png)
Data Factory で、リンク サービスの接続を作成します。 データ ストアとして [ODBC] を選びます。
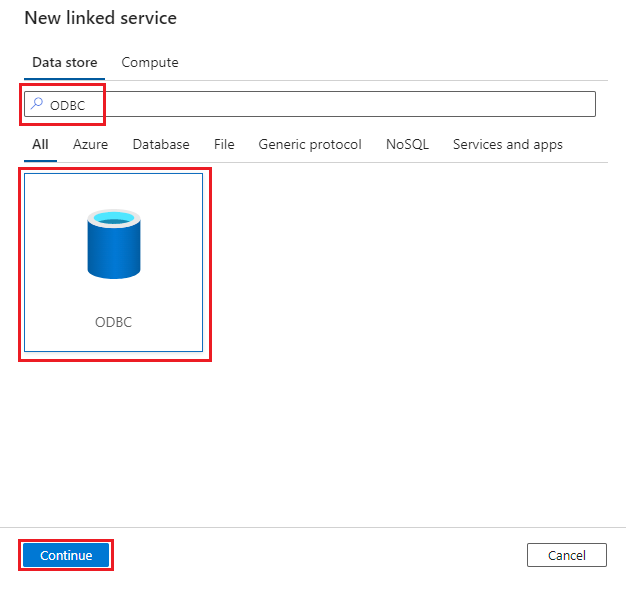
前の手順で構成した IR を使用して、リンク サービスを構成します。
名前: リンク サービスの名前を入力します。
統合ランタイム経由で接続: [SelfhostedIR] を選びます。
接続文字列: 前の手順で作成した DSN の名前を持つ DSN 接続文字列を入力します。
認証の種類: [基本] を選びます。
Teradata ODBC 接続のユーザー名とパスワードを入力します。
[接続テスト]をクリックし、[作成]をクリックします。

次の手順を実行して、ODBC をデータ ストアとして使用してデータセットを作成します。 前に作成したリンク サービスを使用します。
- [作成者] タブを選択します。
- + ボタンを選択します。
- [データセット] を選択します。
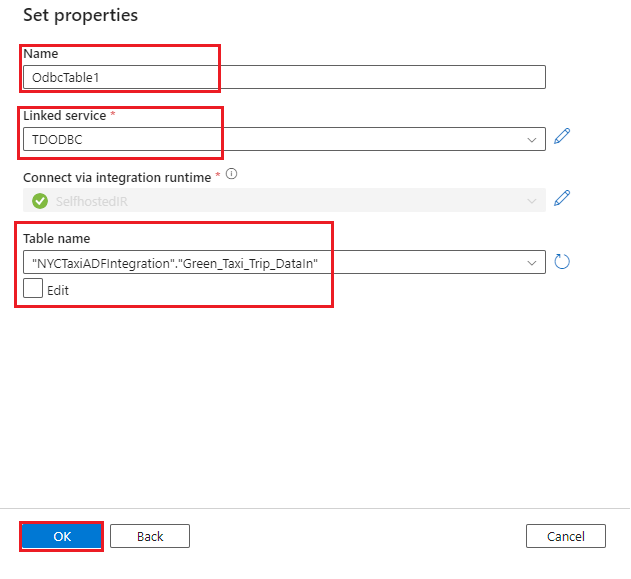
Green_Taxi_Trip_DataInTeradata テーブルのデータセットを作成します。
- データ ストアとして [ODBC] を選び、[続行] を選びます。
- 名前: データセットの名前を指定します。
- リンク サービス: 前の手順で作成した ODBC リンク サービスを選びます。
- テーブル名: 一覧からテーブルを選びます。
- [OK] を選択します。
ヒント
データを読み込むときは、データ型の不一致エラーを回避するために、ジェネリック データ型のステージング テーブルを使用します。 たとえば、列に 10 進データ型を使用する代わりに、Varchar を使用します。 その後、Vantage データベースでデータ型変換を実行できます。
最初のシナリオの手順 4 - 6 および手順 8 に従って、Vantage に読み込むソース ファイルへの Azure Blob 接続を作成します。 この接続はソース ファイルに対して作成しているため、ファイルのパスが異なります。
シナリオ 1 で説明されているように、データ コピー アクティビティを含むパイプラインを作成します。
データ コピー アクティビティをパイプラインにドラッグします。
Note
現在、Teradata ODBC コネクタでは、Data Factory の Data Flow アクティビティがサポートされていません。 データに対して変換を実行する場合、データ コピー アクティビティの前に Data Flow アクティビティを作成することをお勧めします。
データ コピー アクティビティを構成します。
[ソース] タブで、Teradata に読み込むファイル データセットを選びます。
他のオプションには既定値をそのまま使用します。
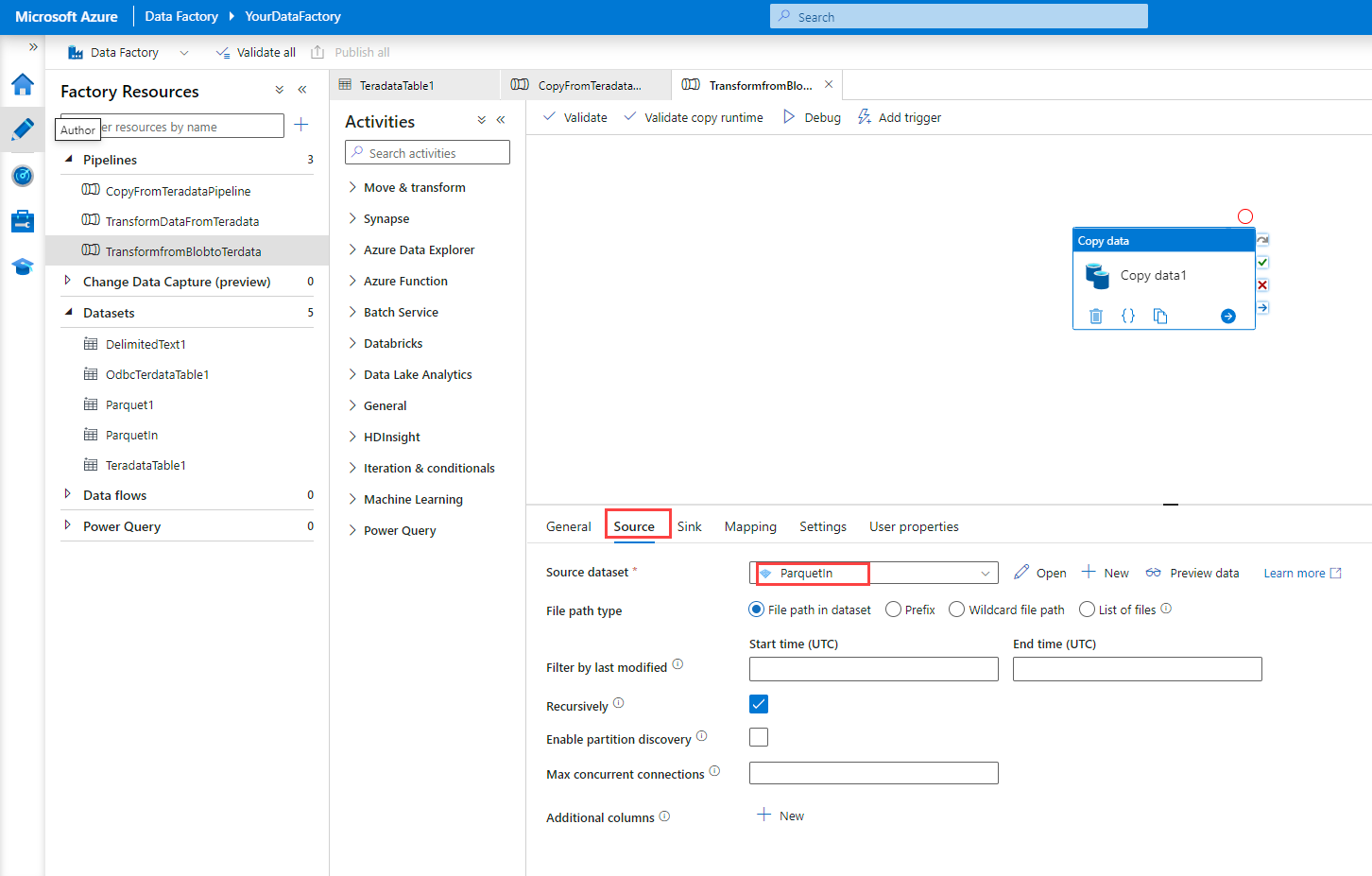
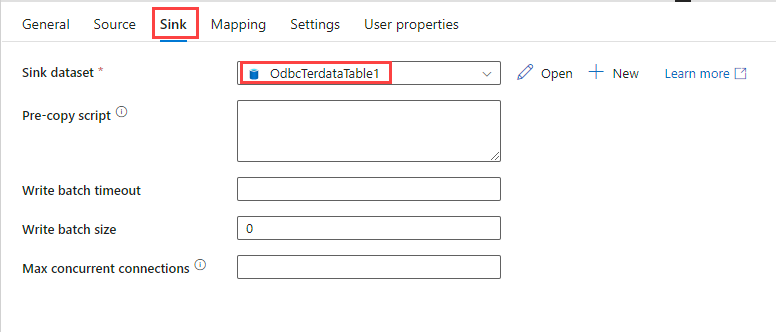
[シンク] タブの [シンク データセット] で、ODBC 接続を使用して作成した Teradata テーブル データセットを選びます。
他のオプションには既定値をそのまま使用します。
[デバッグ] を選択します。 パイプラインは Parquet ファイルから Vantage にデータをコピーします。

![[ODBC データ ソース アドミニストレーター] ウィンドウを示すスクリーンショット。](/ja-jp/azure/architecture/databases/guide/_images/odbc-driver-configuration-2.png#lightbox)





シナリオ 3: Vantage Cloud から Blob Storage 内のデータにアクセスする
このシナリオでは、Vantage の Native Object Storage (NOS) 機能を使用して Blob Storage 内のデータにアクセスする方法について説明します。 前のシナリオは、継続的に、またはスケジュールに基づいてデータを Vantage に読み込む場合に最適です。 このシナリオでは、データを Vantage に読み込むかどうかに関係なく、Blob Storage から 1 回限りの方法でデータにアクセスする方法について説明します。
Note
NOS を使用して Blob Storage にデータをエクスポートすることもできます。
次のクエリを使用すると、Vantage にデータを読み込むことなく、Data Factory 経由で変換されて Blob Storage に読み込まれたデータを Vantage から読み取ることができます。 Teradata SQL エディターを使用してクエリを実行できます。 BLOB 内のデータにアクセスするには、
Access_IDフィールドとAccess_Keyフィールドにストレージ アカウント名とアクセス キーを指定します。 クエリは、Locationというフィールドも返します。このフィールドは、レコードの読み取り元のファイルのパスを指定します。FROM ( LOCATION='/AZ/yourstorageaccount.blob.core.windows.net/vantageadfdatain/NYCGreenTaxi/' AUTHORIZATION='{"ACCESS_ID":"yourstorageaccountname","ACCESS_KEY":"yourstorageaccesskey"}' ) as GreenTaxiData;
データのクエリの別の例を次に示します。
READ_NOSのテーブル演算子を使用しています。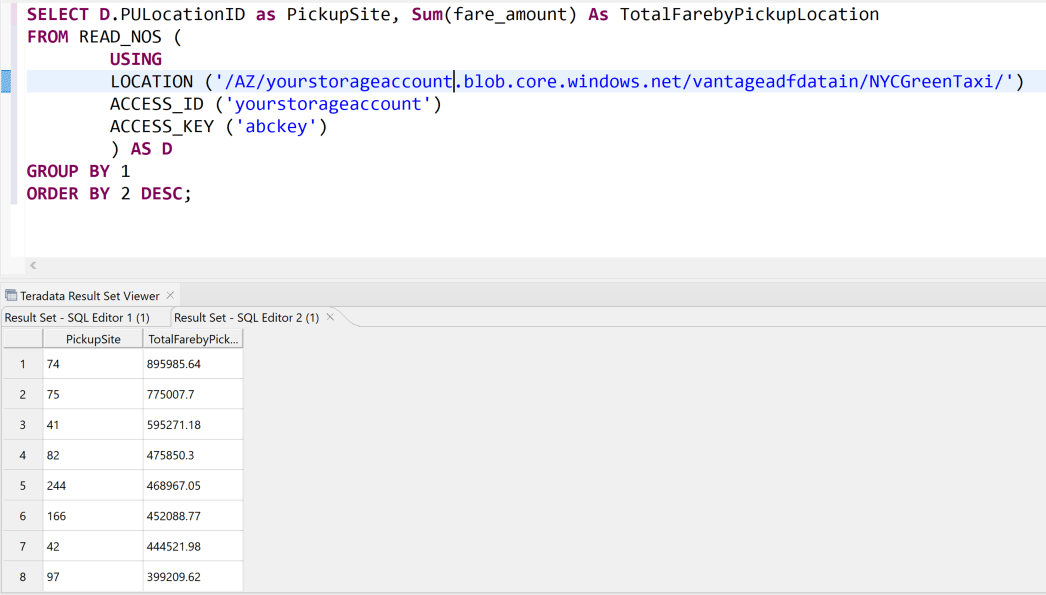
また、オブジェクト ストアに外部テーブルを作成して、データをクエリしたり、Vantage データベースにデータを読み込んだりすることもできます。 次の構文に示すように、まず、
USERフィールドとPASSWORDフィールドにあるストレージ アカウント名とアクセス キーを使用する承認オブジェクトを作成する必要があります。 このオブジェクトを使用して外部テーブルを作成して、テーブルの作成時にキーを指定する必要がないようにできます。USER 'YOUR-STORAGE-ACCOUNT-NAME' PASSWORD 'YOUR-ACCESS-KEY';ここで、データにアクセスする外部テーブルを作成できます。 次のクエリでは、グリーン タクシーのデータのテーブルを作成します。 承認オブジェクトを使用します。
Note
Parquet ファイルを読み込むときは、必ずデータ型を正しくマップしてください。 データ型の一致については、READ_NOS コマンドを使用して Parquet スキーマをプレビューできます。
Create Foreign Table NYCTaxiADFIntegration.GreenTaxiForeignTable , External security definer trusted DefAuth3 ( VendorID INT, lpep_pickup_datetime TIMESTAMP, lpep_dropoff_datetime TIMESTAMP, store_and_fwd_flag VARCHAR(40) CHARACTER SET UNICODE CASESPECIFIC, RatecodeID INT, PULocationID INT, DOLocationID INT, passenger_count INT, trip_distance FLOAT, fare_amount FLOAT, extra DECIMAL(38,18), mta_tax DECIMAL(38,18), tip_amount FLOAT, tolls_amount DECIMAL(38,18), ehail_fee INT, improvement_surcharge DECIMAL(38,18), total_amount DECIMAL(38,18), payment_type INT, trip_type INT, congestion_surcharge DECIMAL(38,18) ) USING ( LOCATION('/AZ/adfvantagestorageaccount.blob.core.windows.net/vantageadfdatain/NYCGreenTaxi') STOREDAS ('PARQUET')) NO PRIMARY INDEX , PARTITION BY COLUMN;これで、他のテーブルをクエリするように、外部テーブルのデータをクエリできるようになりました。

オブジェクト ストレージ内のデータをクエリする方法を確認しました。 ただし、クエリ パフォーマンスを向上させるために、データベース内のテーブルにデータを永続的に読み込むことにするかもしれません。 次のステートメントを使用して、Blob Storage から永続的なテーブルにデータを読み込むことができます。 一部のオプションは、特定のデータ ファイル形式でのみ機能する場合があります。 詳細については、Teradata のドキュメントをご覧ください。 サンプル コードについては、「データベースに外部データを読み込む」をご覧ください。
メソッド 説明 CREATE TABLE AS…WITH DATA 既存の外部テーブルからテーブル定義とデータにアクセスし、データベースに新しい永続テーブルを作成します CREATE TABLE AS...FROM READ_NOS オブジェクト ストアからデータに直接アクセスし、データベースに永続的なテーブルを作成します INSERT SELECT 外部データの値を永続データベース テーブルに保存します 次の例は、
GreenTaxiDataから永続的なテーブルを作成する方法を示しています。CREATE Multiset table NYCTaxiADFIntegration.GreenTaxiNosPermanent As ( SELECT D.PULocationID as PickupSite, Sum(fare_amount) AS TotalFarebyPickuploation FROM NYCTaxiADFIntegration.GreenTaxiForeignTable AS D GROUP BY 1 ) with Data No Primary Index;INSERT INTO NYCTaxiADFIntegration.GreenTaxiNosPermanent SELECT D.PULocationID as PickupSite, Sum(fare_amount) AS TotalFarebyPickuploation FROM NYCTaxiADFIntegration.GreenTaxiForeignTable AS D GROUP BY 1;



ベスト プラクティス
- 「ソースとしての Teradata」で説明されているコネクタのパフォーマンスに関するヒントとベスト プラクティスに従います。
- セルフホステッド IR のサイズがデータ量に合わせて正しく設定されていることを確認します。 パフォーマンスの向上のため、IR をスケールアウトさせる必要がある場合があります。 詳細については、このセルフホステッド IR のパフォーマンス ガイドをご覧ください。
- 「Copy アクティビティのパフォーマンスとスケーラビリティに関するガイド」を使用して、パフォーマンスのために Data Factory パイプラインを微調整します。
- Data Factory のデータ コピー ツールを使用して、パイプラインをすばやく設定し、スケジュールに従って実行します。
- 実行パイプラインのコストを管理するために、セルフホステッド IR で Azure VM を使用することを検討します。 パイプラインを 1 日に 2 回実行する場合、VM を 2 回起動してからシャットダウンします。
- Data Factory での CI/CD を使用して、Git 対応の継続的インテグレーションと開発プラクティスを実装することを検討します。
- パイプライン アクティビティ数を最適化します。 不要なアクティビティによってコストが増加し、パイプラインが複雑になります。
- マッピング データ フローを使用して、コードなしのプロセスとローコード プロセスを使用して Blob Storage データを視覚的に変換し、Power BI レポートなどの使用のために Vantage データを準備することを検討します。
- スケジュール トリガーを使用することに加えて、タンブリング ウィンドウとイベント トリガーを組み合わせて使用して、Vantage データを宛先の場所に読み込むことを検討します。 不要なトリガーを削減してコストを削減します。
- アドホック クエリに Vantage NOS を使用して、アップストリーム アプリケーションのデータを簡単に提供します。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパルの作成者:
- スニル サバート | プリンシパル プログラム マネージャー
- Divyesh Sah | ディレクター WW クラウド アーキテクチャ
- Jianlei Shen | シニア プログラム マネージャー
その他の共同作成者:
- Mick Alberts | テクニカル ライター
- Emily Chen | プリンシパル PM マネージャー
- Wee Hyong Tok | パートナー ディレクター PM
- Bunty Ranu | シニア ディレクター、ワールドワイド クラウド アーキテクチャ
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次の手順
- Azure での Teradata Vantage
- Teradata Tools and Utilities 17.20
- Data Factory
- Azure 仮想ネットワーク ピアリング
- Private Link サービス
- Data Factory Teradata コネクタ
- セルフホステッド IR
- BLOB ストレージのドキュメント