この記事では、Azure Machine Learning を使用してローン申込者が延滞およびデフォルトする確率を予測するアーキテクチャについて説明します。 モデルの予測は、申込者の財政行動に基づくものです。 このモデルは、膨大なデータ ポイントを使用して申込者を分類し、各申込者の適格性スコアを提供します。
Apache®、 Spark、および炎のロゴは、Apache Software Foundation の米国およびその他の国における登録商標です。 これらの商標を使用することが、Apache Software Foundation による保証を意味するものではありません。
アーキテクチャ

このアーキテクチャの Visio ファイルをダウンロードします。
データフロー
次のデータフローは、前の図に対応しています。
ストレージ: 構造化されているデータは、Azure Synapse Analytics プールなどのデータベースに格納されます。 古い SQL データベースは、システムに統合することが可能です。 半構造化データと非構造化データは、データ レイクに読み込むことができます。
取り込みと前処理: Azure Synapse Analytics の処理パイプラインと Extract/Transform/Load (ETL) 処理は、組み込みのコネクタを介して Azure またはサードパーティのソースに格納されているデータに接続できます。 Azure Synapse Analytics では、SQL、Spark、Azure Data Explorer、Power BI を使用する複数の分析手法がサポートされています。 データ パイプラインには、既存の Azure Data Factory オーケストレーションを使用することもできます。
処理: 機械学習モデルの開発と管理には、Azure Machine Learning が使用されます。
初期処理: この段階では、機械学習モデルをトレーニングするために使用するキュレーションされたデータセットを作成するために、生データの処理を行います。 典型的な処理にはデータ型のフォーマッティング、欠損値の補完、特徴量エンジニアリング、特徴量選択、次元削減などがあります。
トレーニング: トレーニング段階では、処理済みのデータセットを使用して、Azure Machine Learning によって信用リスク モデルがトレーニングされ、最適なモデルが選択されます。
モデルのトレーニング: 従来の機械学習やディープ ラーニング モデルなど、さまざまな機械学習モデルを使用できます。 ハイパーパラメーター チューニングを行って、モデルのパフォーマンスを最適化することもできます。
モデルの評価: Azure Machine Learning では、トレーニングされた各モデルのパフォーマンス評価を行うことができるため、デプロイに最適なものを選択できます。
モデルの登録: Azure Machine Learning で最も優れたパフォーマンスを発揮するモデルを登録します。 この手順により、モデルをデプロイできるようになります。
責任ある AI: 責任ある AI とは、安全で信頼できる倫理的な方法で AI システムを開発、評価、デプロイするためのアプローチです。 このモデルはローン申請を承認または拒否するかという意思決定の推論を行うため、責任ある AI の原則を適用する必要があります。
"公平性メトリクス" は、不公平な挙動の影響を評価し、緩和戦略を可能にします。 センシティブな特徴と属性は、データセットとデータのコーホート (サブセット) で特定します。 詳細については、「モデルのパフォーマンスと公平性」を参照してください。
"解釈可能性" は、機械学習モデルの挙動がどの程度理解可能かを示す尺度です。 責任ある AI のこのコンポーネントは、モデルの予測について人間が理解できる説明を生成します。 詳細については、「モデルの解釈可能性」を参照してください。
リアルタイム機械学習のデプロイ: 承認のために要求をすぐに確認する必要がある場合は、リアルタイムのモデル推論を使用する必要があります。
- 機械学習のマネージド オンライン エンドポイント。 リアルタイム スコアリングを行うためには、適切なコンピューティング先を選択する必要があります。
- オンラインでのローン申請では、申請フォームまたはローンの申込内容からの入力に基づくリアルタイム スコアリングが使用されます。
- モデル スコアリングに使用される決定と入力は永続ストレージに格納され、将来参照するために取得できます。
機械学習のバッチ デプロイ: ローン処理をオフラインで行う場合、モデルは一定の間隔でトリガーされるようにスケジュールされます。
- マネージド バッチ エンドポイント。 バッチ推論がスケジュールされ、結果のデータセットが作成されます。 決定は、申込者の信用度に基づいています。
- バッチ処理によるスコアリングの結果セットは、データベースまたは Azure Synapse Analytics データ ウェアハウスに保持されます。
申込者アクティビティに関するデータのインターフェイス: 申込者が入力した詳細、内部のクレジット プロファイル、モデルの決定はすべてステージングされ、適切なデータ サービスに格納されます。 これらの詳細は将来のスコアリングのために意思決定エンジンで使用されるため、ドキュメント化されます。
- ストレージ: 与信処理の詳細はすべて、永続ストレージに保持されます。
- ユーザー インターフェイス: 承認または拒否の判断結果が申込者に提示されます。
レポート: 処理されたアプリケーションの数と承認または拒否に関するリアルタイムの分析情報が、マネージャーやリーダーに継続的に提示されます。 レポートの例としては、承認された金額のほぼリアルタイムのレポート、作成されたローン ポートフォリオ、モデルのパフォーマンスなどがあります。
コンポーネント
- Azure Blob Storage は、非構造化データ用のスケーラブルなオブジェクト ストレージを提供します。 これは、バイナリ ファイル、アクティビティ ログ、特定の形式に準拠していないファイルなどのファイルを格納するために最適化されています。
- Azure Data Lake Storage は、Azure で費用対効果の高いデータ レイクを作成するためのストレージ基盤です。 階層的なフォルダー構造を持つ BLOB トレージを提供し、パフォーマンス、管理、セキュリティを強化します。 これは、数百ギガビットのスループットを維持しながら、数ペタバイトの情報を管理します。
- Azure Synapse Analytics は、SQL と Spark の最高のテクノロジと、データ エクスプローラーおよびパイプラインの統一されたユーザー エクスペリエンスを実現する分析サービスです。 Power BI、Azure Cosmos DB、Azure Machine Learning と統合されています。 このサービスでは、専用リソース モデルとサーバーレス リソース モデルの両方がサポートされており、それらのモデルを切り替えることができます。
- Azure SQL Database は、クラウド向けに構築されたフル マネージドで常に最新のリレーショナル データベースです。
- Azure Machine Learning は、機械学習プロジェクトのライフサイクルを管理するためのクラウド サービスです。 データの探索、モデルの構築や管理、デプロイのための統合環境を提供し、機械学習のコードファースト、ローコード/ノーコードのアプローチをサポートします。
- Power BI は、Azure リソースと簡単に統合できる視覚化ツールです。
- Azure App Service を使用すると、インフラストラクチャを管理せずに、Web アプリ、モバイル バック エンド、RESTful API を構築してホストできます。 サポートされている言語には、.NET、.NET Core、Java、Ruby、Node.js、PHP、Python が含まれます。
代替
Azure Databricksを使用して、機械学習モデルと分析ワークロードを開発、デプロイ、管理できます。 このサービスは、モデル開発のための統合環境を提供します。
シナリオの詳細
金融業界の企業では、融資を希望する個人または企業の信用リスクを予測する必要があります。 このモデルでは、ローン申込者の延滞とデフォルトの確率を評価します。
信用リスクの予測には、母集団の行動の深い分析と、財政責任に基づいた顧客ベースのセグメントへの分類が含まれます。 その他の要因には、市場要因や経済状況があり、これらは結果に大きな影響を及ぼします。
課題。 入力データには、数千万の顧客プロファイルと、さまざまなシステムから集約した数十億件のレコードに基づく顧客信用行動と支出習慣に関するデータ (内部の顧客アクティビティ システムなど) が含まれます。 経済状況と国内や地域の市場分析に関するサードパーティのデータは、月次または四半期ごとのスナップショットによるもので、何百 GB ものファイルの読み込みとメンテナンスが必要です。 申込者に関する信用調査機関の情報、または何行にもおよぶ半構造化された顧客データがあるだけでなく、これらのデータセットをクロス統合して、そのデータの完全性を検証する品質チェックが必要になります。
データは通常、信用情報機関の顧客情報からなる横長の列のテーブルと市場分析の情報で構成されています。 顧客アクティビティは、構造化されていない可能性のある動的なレイアウトのレコードで構成されています。 データは、顧客サービスで記入されたメモや申込者との対話フォームから収集された自由形式のテキストで提供されることもあります。
これらの大量のデータを処理し、結果を最新に保つには、合理的な処理が必要です。 そのため、低遅延のストレージと取得プロセスが不可欠になります。 データ インフラストラクチャは、さまざまなデータ ソースをサポートするようにスケーリングでき、さらにデータ境界を管理およびセキュリティで保護する機能が備わっている必要があります。 機械学習プラットフォームは、多くの母集団セグメントでトレーニング、テスト、検証される多くのモデルの複雑な分析をサポートする必要があります。
データの機密性とプライバシー。 このモデルのデータ処理には、個人データと人口統計の詳細が含まれます。 そのため、母集団のプロファイリングは避ける必要があります。 個人データはすべて、直接閲覧できないように制限する必要があります。 個人データの例としては、アカウント番号、クレジット カードの詳細、社会保障番号、名前、住所、郵便番号などがあります。
クレジット カードと銀行口座番号は、常に難読化する必要があります。 特定のデータ要素は、基本的な情報に一切アクセスすることなく分析には利用できるようにするため、マスクして常に暗号化しておく必要があります。
データは、セキュリティで保護されたエンクレーブを使用して、保存時、転送時、処理時を問わず暗号化しておく必要があります。 また、データ項目へのアクセスは、監視ソリューションに記録されるようにします。 運用システムは、モデルのデプロイとプロセスをトリガーする承認を持つ適切な CI/CD パイプラインで設定する必要があります。 ログとワークフローの監査により、コンプライアンス要件に必要なデータとのやり取りを確認できるようにする必要があります。
処理 : このモデルは、分析、コンテクスト化、モデルのトレーニングおよびデプロイのために高い計算能力を必要とします。 また、信用判断に人種、性別、民族、地理的位置の偏りがないことを確認するため、ランダムなサンプルを用いてモデル スコアリングの検証が行われます。 意思決定モデルは、将来参照できるようにドキュメント化し、保存しておく必要があります。 意思決定の結果に関わるすべての要素が保存されます。
データ処理には高い CPU 使用率が必要です。 これには、DB および JSON 形式の構造化データの SQL 処理、データ フレームの Spark 処理、さまざまなドキュメント形式のテラバイト単位の情報に対するビッグ データ分析が含まれます。 データ Extract/Load/Transform (ELT)/ETL ジョブは、データの最新の値に応じて、定期的またはリアルタイムでスケジュールまたはトリガーされます。
コンプライアンスと規制のフレームワーク。 送信された申請書、モデル スコアリングで使用される特徴量、モデルの結果セットなど、ローン処理のすべての詳細は、ドキュメント化する必要があります。 モデルのトレーニング情報、トレーニングに使用されたデータ、そしてトレーニング結果は、将来の参照や監査、コンプライアンスの要求のために登録しておく必要があります。
バッチ スコアリングとリアルタイム スコアリング。 事前に承認された残高の転送など、特定のタスクはプロアクティブであるため、バッチ ジョブとして処理できます。 一方、オンラインでの与信枠の増加のように、リアルタイムの承認が必要なものもあります。
オンラインローン申請の状態へのリアルタイムアクセスは、申込者が利用できる必要があります。 ローン発行金融機関は、信用モデルのパフォーマンスを継続的に監視し、ローンの承認状態、発行額、新規に発行したローンの質などの指標を把握する必要があります。
責任ある AI
責任ある AI ダッシュボード には、責任ある AI の実装に役立つ複数のツールをまとめた 1 つのインターフェイスが用意されています。 責任ある AI の標準は、次の 6 つの原則に基づいています。
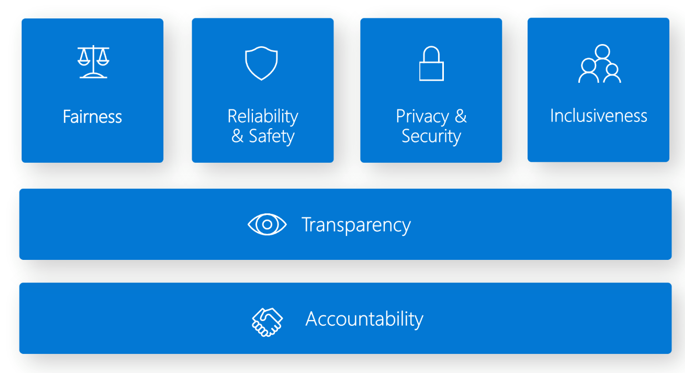
Azure Machine Learning における公平性と包括性。 責任ある AI ダッシュボードのこのコンポーネントは、配分の弊害やサービスの質追及による弊害を回避して、不公平な行動を評価するのに役立ちます。 これを使用することで、性別、年齢、民族性、およびその他の特性の観点から定義された機密グループ全体の公平性を評価できます。 評価では、公平性は不均衡メトリックによって定量化されます。 その際、不均衡の制約を使用する Fairlearn のオープンソース パッケージの緩和アルゴリズムを実装する必要があります。
Azure Machine Learning の信頼性と安全性。 責任ある AI のエラー分析の要素は、次の場合に役立ちます。
- モデルのエラーがどのように分散しているかについて深く理解する。
- 全体的なベンチマークよりもエラー率が高いデータのコーホートを特定する。
Azure Machine Learning の透明性。 透明性において重要なのは、特徴量が機械学習モデルにどのように影響するかを理解することです。
- "モデルの解釈可能性" は、モデルの挙動に何が影響しているかを理解するのに役立ちます。 これは、モデルの予測について、人間が理解できるような説明を生成します。 理解することで、モデルが信頼できることを確認し、その理解をデバッグや改良に役立てることができます。 InterpretML は、グラスボックス型モデルの構造や、ブラックボックス型のディープ ニューラル ネットワーク モデルの特徴量間の関係を理解するのに役立ちます。
- "反事実条件文 What-If" を使うと、特徴量の変更や摂動にどのように反応するかという観点から、機械学習モデルを理解し、デバッグすることができます。
Azure Machine Learning におけるプライバシーとセキュリティ。 機械学習関連の管理者は、モデルの開発とデプロイを管理するために、セキュリティで保護された構成を作成する必要があります。 セキュリティとガバナンスの機能 は、組織のセキュリティ ポリシーに準拠するのに役立ちます。 モデルの評価とセキュリティ保護に役立つ、その他のツールもあります。
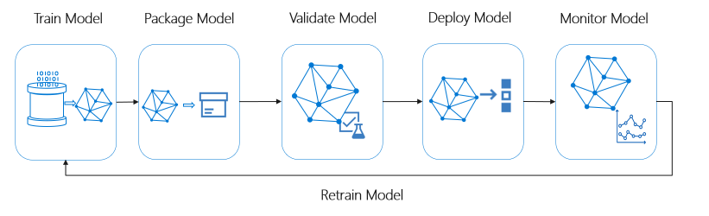
Azure Machine Learning のアカウンタビリティ。 機械学習の運用 (MLOps) は、AI ワークフローの効率を向上させる DevOps の原則と実践に基づいています。 Azure Machine Learning は、次のような MLOps 機能の実装を支援します。
- モデルの登録、パッケージ化、デプロイ
- モデルの変更に関する通知とアラートの取得
- エンドツーエンド ライフサイクルのガバナンス データの取得
- 運用上の問題がないかアプリケーションを監視する
この図は、Azure Machine Learning の MLOps 機能を示しています。
考えられるユース ケース
このソリューションを次のシナリオに適用できます。
- 財務: 顧客の財務分析や顧客のクロスセールス分析を行い、ターゲットを絞ったマーケティング キャンペーンを行うことができます。
- 医療: 患者情報を入力として使用して、治療法の提案を行うことができます。
- ホスピタリティ: 顧客プロファイルを作成し、ホテル、航空券、クルーズ パッケージ、メンバーシップなどの提案を行います。
考慮事項
これらの考慮事項は、ワークロードの品質向上に使用できる一連の基本原則である Azure Well-Architected Framework の要素を組み込んでいます。 詳細については、「Microsoft Azure Well-Architected Framework」を参照してください。
セキュリティ
セキュリティは、重要なデータやシステムの意図的な攻撃や悪用に対する保証を提供します。 詳細については、「セキュリティの重要な要素の概要」を参照してください。
Azure ソリューションは、多層防御とゼロ トラスト アプローチを提供します。
このアーキテクチャでは、次のセキュリティ機能を実装することを検討してください。
- 仮想ネットワークに専用の Azure サービスをデプロイする
- Azure SQL Database のセキュリティ機能
- Key Vault を使用してデータ ファクトリの資格情報をセキュリティで保護する
- Azure Machine Learning のエンタープライズ セキュリティとガバナンス
- Synapse Analytics ワークスペース用の Azure セキュリティ ベースライン
コスト最適化
コストの最適化とは、不要な費用を削減し、運用効率を向上させることです。 詳しくは、 コスト最適化の柱の概要に関する記事をご覧ください。
このソリューションの実装コストを見積もるには、 Azure 料金計算ツールを使用してください。
また、次のリソースもあわせてご参照ください。
オペレーショナル エクセレンス
オペレーショナル エクセレンスは、アプリケーションをデプロイし、それを運用環境で実行し続ける運用プロセスをカバーします。 詳細については、「オペレーショナル エクセレンスの重要な要素の概要」を参照してください。
機械学習ソリューションは、管理とメンテナンスを容易にするために、スケーラブルで標準化されている必要があります。 ソリューションが、モデルの再トレーニング サイクルと自動再デプロイを使用して継続的な推論をサポートしていることを確認しましょう。
詳細については、Azure MLOps v2 GitHub リポジトリを参照してください。
パフォーマンス効率
パフォーマンス効率とは、ユーザーによって行われた要求に合わせて効率的な方法でワークロードをスケーリングできることです。 詳細については、「パフォーマンス効率の柱の概要」を参照してください。
- スケーラブルなソリューションの設計の詳細については、「パフォーマンス効率のチェックリスト」を参照してください。
- 規制対象の業界の詳細については、「規制対象の業界で AI と機械学習のイニシアチブを拡大する」を参照してください。
- SQL、 Spark、または サーバーレス SQL プールを使用して、Azure Synapse Analytics 環境を管理します。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Charitha Basani | シニア クラウド ソリューション アーキテクト
その他の共同作成者:
- Mick Alberts | テクニカル ライター
LinkedIn の非パブリック プロファイルを表示するには、LinkedIn にサインインします。
次のステップ
- Azure Machine Learning の Azure セキュリティ ベースライン
- Azure Synapse Analytics
- 機械学習モデルを Azure にデプロイする
- 責任ある AI とは