このアーティクルでは、自動運転システムのオフライン データ操作とデータ管理 (DataOps) を開発するためのソリューションとガイダンスについて説明します。 DataOps ソリューションは、 自律運転車操作 (AVOps) 設計ガイドに記載されているフレームワークに基づいて構築されています。 DataOps は、AVOps の構成要素の 1 つです。 その他の構成要素には、機械学習操作 (MLOps)、検証操作 (ValOps)、DevOps、一元化された AVOps 関数などがあります。
Apache®、Apache Spark、Apache Parquet は、Apache Software Foundation の北米およびその他の国における登録商標です。 これらの商標を使用することが、Apache Software Foundation による保証を意味するものではありません。
アーキテクチャ

この記事のアーキテクチャの図を含む Visio ファイルをダウンロードしてください。
データフロー
測定データは、車両のデータ ストリームに由来します。 ソースには、カメラ、車両テレメトリ、レーダー、超音波、およびライダー センサーが含まれます。 車両内のデータ ロガーは、ロガー ストレージ デバイスに測定データを格納します。 ロガー ストレージ データはランディング データ レイクにアップロードされます。 Azure Data Box や Azure Stack Edge などのサービス、または Azure ExpressRoute などの専用接続を使って、Azure にデータが取り込まれます。 次の形式の測定データは、Azure Data Lake Storage: 測定データ形式バージョン 4 (MDF4)、技術データ管理システム (TDMS)、rosbag に格納されます。 アップロードされたデータは、データの受信と検証用に指定された Landing という専用のストレージ アカウントに入ります。
Azure Data Factory パイプラインは、ランディング ストレージ アカウント内のデータを処理するためにスケジュールされた間隔でトリガーされます。 パイプラインは、次のステップを処理します。
- チェックサムなどのデータ品質チェックを実行します。 このステップでは、低品質のデータが削除され、高品質のデータのみが次のステージに渡されます。 Azure App Service は、品質チェックコードを実行するために使用されます。 不完全と見なされるデータは、将来の処理のためにアーカイブされます。
- 系列の追跡では、App Service を使用してメタデータ API を呼び出します。 このステップでは、Azure Cosmos DB に格納されているメタデータを更新して、新しいデータ ストリームを作成します。 測定ごとに、生データ ストリームがあります。
- Data Lake Storage の Raw というストレージ アカウントにデータをコピーします。
- メタデータ API を呼び出してデータ ストリームを完全としてマークし、他のコンポーネントやサービスがデータ ストリームを使用できるようにします。
- 測定をアーカイブし、ランディング ストレージ アカウントから削除します。
Data Factory と Azure Batch は、生ゾーン内のデータを処理して、ダウンストリーム システムが使用できる情報を抽出します。
- バッチは、生ファイル内のトピックからデータを読み取り、それぞれのフォルダー内の選択したトピックにデータを出力します。
- 生ゾーン内のファイルはそれぞれ 2 GB を超えるサイズにできるため、並列処理抽出関数は各ファイルで実行されます。 これらの関数は、画像処理、ライダー、レーダー、GPS データを抽出します。 また、メタデータ処理も実行します。 Data Factory と Batch は、スケーラブルな方法で並列処理を実行する方法を提供します。
- データはダウンサンプリングされ、ラベル付けと注釈付けが必要なデータの量を減らします。
車両ロガーのデータがさまざまなセンサー間で同期されていない場合は、データを同期して有効なデータセットを作成する Data Factory パイプラインがトリガーされます。 同期アルゴリズムは Batch で実行されます。
Data Factory パイプラインが実行され、データがエンリッチされます。 機能強化の例としては、テレメトリ、車両ロガー データ、天気、マップ、オブジェクト データなどのその他のデータがあります。 強化されたデータは、たとえば、アルゴリズム開発で使用できる分析情報をデータ サイエンティストに提供するのに役立ちます。 生成されたデータは、同期されたデータと互換性のある Apache Parquet ファイルに保持されます。 エンリッチされたデータに関するメタデータは、Azure Cosmos DB のメタデータ ストアに格納されます。
サードパーティパートナーは、手動または自動ラベル付けを実行します。 データは、Azure Data Share 経由でサードパーティパートナーと共有され、Microsoft Purview に統合されています。 Data Share では、 Data Lake Storage の Labeled という名前の専用ストレージ アカウントを使用して、ラベル付きデータを organization に返します。
Data Factory パイプラインは、シーン検出を実行します。 シーン メタデータはメタデータ ストアに保持されます。 シーン データは、Parquet または Delta ファイルにオブジェクトとして格納されます。
エンリッチメント データと検出されたシーンのメタデータに加えて、Azure Cosmos DB のメタデータ ストアには、ドライブ データなどの測定値のメタデータが格納されます。 このストアには、抽出、ダウンサンプリング、同期、エンリッチメント、シーン検出のプロセスを経る際のデータ系列のメタデータも含まれています。 メタデータ API は、測定値、系列、シーン データにアクセスし、データが格納されている場所を検索するために使用されます。 その結果、メタデータ API はストレージ レイヤー マネージャーとして機能します。 ストレージ アカウント間でデータが分散されます。 また、メタデータベースの検索を使用してデータの場所を取得する方法も開発者に提供されます。 そのため、メタデータ ストアは、ソリューションのデータ フロー全体で追跡可能性と系列を提供する一元化されたコンポーネントとなります。
Azure Databricks と Azure Synapse Analytics は、メタデータ API と接続し、Data Lake Storage にアクセスし、データに関する調査を行うために使用されます。
Components
- Data Box は、Azure との間でテラバイト単位のデータをすばやく、低コストで信頼性の高い方法で提供します。 このソリューションでは、Data Box は、収集された車両データを地域の通信事業者を介して Azure に転送するために使われます。
- Azure Stack Edge デバイスは、エッジの場所で Azure 機能を提供します。 Azure の機能の例としては、コンピューティング、ストレージ、ネットワーク、ハードウェアアクセラレータ機械学習などがあります。
- ExpressRoute は、オンプレミスのネットワークをプライベート接続を介して Microsoft Cloud に拡張します。
- Data Lake Storage では、大量のデータがネイティブの未加工の形式で保持されます。 このケースでは、Data Lake Storage は、例えば、生や抽出などのステージに基づいてデータを格納します。
- Data Factory は、Extract/Transform/Load (ETL) と Extract/Load/Transform (ELT) ワークフローを作成およびスケジュールするためのフル マネージドのサーバーレス ソリューションです。 ここでは、Azure Data Factory は、バッチ コンピューティングを使って ETL を実行し、データ移動とデータ変換を調整するためのデータ駆動型ワークフローを作成します。
- Batch は、大規模な並列コンピューティングやハイパフォーマンス コンピューティング (HPC) のバッチ ジョブを Azure で効率的に実行します。 このソリューションでは、Batch を使用して、データ ラングリング、データのフィルター処理と準備、メタデータの抽出などのタスクのための大規模なアプリケーションを実行します。
- Azure Cosmos DB は、グローバル分散型の複数モデル データベースです。 ここでは、格納された測定値などのメタデータの結果を格納します。
- Data Share では、セキュリティーが強化されたパートナー組織とデータを共有します。 インプレース共有の使用により、データ プロバイダーがデータをコピーしたりスナップショットを取ったりすることなく、データが置かれている場所でデータを共有できます。 このソリューションでは、Data Share はラベル付け会社とデータを共有します。
- Azure Databricks には、大規模なエンタープライズ レベルのデータ ソリューションを保守するためのツール セットが用意されています。 これは、大量の車両データに対する長時間の操作に必要です。 データ エンジニアは、分析ワークベンチとして Azure Databricks を使います。
- Azure Synapse Analytics は、データ ウェアハウスやビッグ データ システム全体で分析情報を取得する時間を短縮します。
- Azure Cognitive Search は、データ カタログ検索サービスを提供します。
- App Service は、サーバーレス ベースの Web App Service を提供します。 この場合、App Service はメタデータ API をホストします。
- Microsoft Purview は、組織全体のデータ ガバナンスを提供します。
- Azure Container Registry は、コンテナー イメージのマネージド レジストリを作成するサービスです。 このソリューションでは、Container Registry を使用して、トピックを処理するためのコンテナーを格納します。
- Application Insights は、アプリケーション パフォーマンス管理を行う Azure Monitor の拡張機能です。 このシナリオでは、Application Insights を使用すると、測定抽出に関する可観測性を構築できます。Application Insights を使用して、カスタム イベント、カスタム メトリック、その他の情報をログに記録し、ソリューションが抽出のために各測定を処理します。 また、Log Analytics に対するクエリを作成して、各測定に関する詳細情報を取得することもできます。
シナリオの詳細
自律走行車向けの堅牢な DataOps フレームワークを設計することは、データを使用し、その系列をトレースし、組織全体で利用できるようにする上で重要です。 適切に設計された DataOps プロセスがないと、自律走行車が生成する大量のデータがすぐに圧倒的になり、管理が困難になる可能性があります。
効果的な DataOps 戦略を実装する場合は、データが適切に格納され、簡単にアクセスでき、明確な系列があることを確認するのに役立ちます。 また、データの管理と分析が容易になり、情報に基づいた意思決定と車両パフォーマンスの向上につながります。
効率的な DataOps プロセスにより、組織全体にデータを簡単に分散できます。 その後、さまざまなチームが、必要な情報にアクセスし操作を最適化することができます。 DataOps を使用すると、共同作業や分析情報の共有が簡単になり、組織の全体的な効果を向上させることができます。
自律運転車のコンテキストにおけるデータ操作の一般的な課題は次のとおりです。
- 研究開発車両からの日々送られてくるテラバイト規模またはペタバイト規模の測定データ量の管理。
- ラベル付け、注釈、品質チェックなど、複数のチームやパートナー間でのデータ共有とコラボレーション。
- バージョン管理と測定データの系列をキャプチャする安全クリティカルな認識スタックの追跡可能性と系列。
- セマンティック セグメント化、画像分類、物体検出モデルを改善するためのメタデータとデータ検出。
この AVOps DataOps ソリューションは、これらの課題に対処する方法に関するガイダンスを提供します。
考えられるユース ケース
このソリューションは、自動運転ソリューションを開発する自動車メーカー (OEM)、階層 1 ベンダー、および独立系ソフトウェア ベンダー (ISV) にベネフィットがあります。
フェデレーション データ操作
AVOps を実装する組織では、AVOps に必要な複雑さにより、複数のチームが DataOps に貢献します。 たとえば、1 つのチームがデータ コレクションとデータ インジェストを担当している場合があります。 別のチームが、ライダー データのデータ品質管理を担当する場合があります。 そのため、DataOps では、データ メッシュ アーキテクチャの次の原則を考慮することが重要です。
- データ所有権とアーキテクチャのドメイン指向の分散化。 1 つの専用チームが、ラベル付けされたデータセットなど、そのドメインのデータ製品を提供する 1 つのデータ ドメインを担当します。
- 製品としてのデータ。 各データ ドメインには、data-lake によって実装されたストレージ コンテナー上のさまざまなゾーンがあります。 内部使用のゾーンがあります。 また、データの重複を避けるために、他のデータ ドメインまたは外部使用用に公開されたデータ製品を含むゾーンもあります。
- 自律的なドメイン指向のデータ チームを可能にするプラットフォームとしてのセルフサービスデータ。
- 一元化されたメタデータ ストアとデータ カタログを必要とする AVOps データ ドメイン間の相互運用性とアクセスを可能にするフェデレーション ガバナンス。 たとえば、ラベル付けデータ ドメインでは、データ収集ドメインへのアクセスが必要な場合があります。
データ メッシュの実装の詳細については、「クラウド規模の分析」を参照してください。
AVOps データ ドメインの構造例
次の表に、AVOps データ ドメインを構築するためのアイデアをいくつか示します。
| データ ドメイン | パブリッシュされたデータ製品 | ソリューションステップ |
|---|---|---|
| データ コレクション | アップロードおよび検証済みの測定ファイル | ランディングと生 |
| 抽出された画像 | 選択および抽出された画像またはフレーム、ライダー、レーダー データ | 抽出 |
| 抽出されたレーダーまたはライダー | 選択および抽出されたライダーとレーダー データ | 抽出 |
| 抽出されたテレメトリ | 選択および抽出された自動車のテレメトリ データ | 抽出 |
| ラベル付き | ラベル付きデータセット | ラベル付き |
| 再計算 | 繰り返しのシミュレーション実行に基づいて生成された主要業績評価指標 (KPI) | 再計算 |
各 AVOps データ ドメインは、ブループリント構造に基づいて設定されます。 この構造には、Azure Databricks または Azure Synapse Analytics を介した Data Factory、Data Lake Storage、データベース、Batch、Apache Spark ランタイムが含まれます。
メタデータとデータの検出
各データ ドメインは分散化され、対応する AVOps データ製品を個別に管理します。 中央データ検出とデータ製品の場所を把握するには、次の 2 つのコンポーネントが必要です。
- 処理された測定ファイルとデータ ストリーム (ビデオ シーケンスなど) に関するメタデータを保持するメタデータ ストア。 このコンポーネントは、ラベル付けされていないファイルのメタデータを検索する場合など、インデックスを作成する必要がある注釈を使用してデータを検出および追跡できるようにします。 たとえば、メタデータ ストアで、特定の車両識別番号 (VIN) のすべてのフレーム、または歩行者またはその他のエンリッチメント ベースのオブジェクトを含むフレームを返すようにすることができます。
- 系列、AVOps データ ドメイン間の依存関係、AVOps データ ループに関係するデータ ストアを示すデータ カタログ。 データ カタログの例として、Microsoft Purview があります。
Azure Data Explorer または Azure Cognitive Search を使用して、Azure Cosmos DB に基づくメタデータ ストアを拡張できます。 選択は、データ検出に必要な最終的なシナリオによって異なります。 セマンティック検索機能には Azure Cognitive Search を使用します。
次のメタデータ モデル図は、いくつかの AVOps データ ループの柱で使用される一般的な統合メタデータ モデルを示しています。
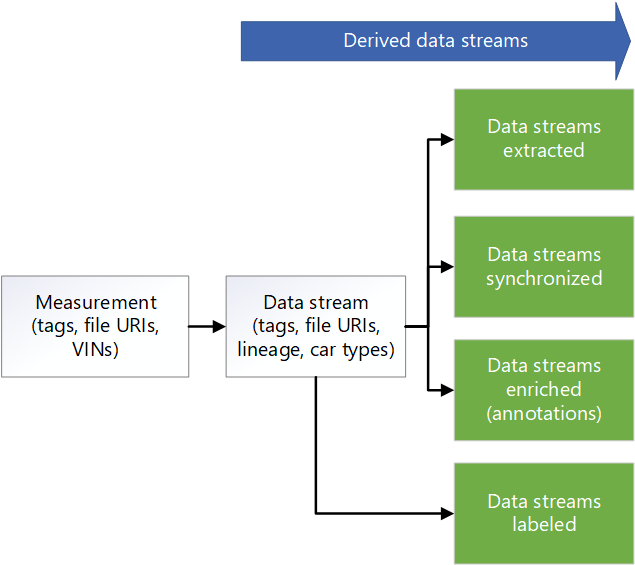
データ共有
データ共有は、AVOps データ ループの一般的なシナリオです。 使用には、ラベル付けパートナーを統合する場合など、データ ドメイン間のデータ共有や外部共有が含まれます。 Microsoft Purview には、データ ループでの効率的なデータ共有のための次の機能が用意されています。
ラベル データ交換に推奨される形式には、コンテキスト内の共通オブジェクト (COCO) データセット と Azure Automation および測定システムの標準化の関連付け (ASAM) OpenLABEL データセットが含まれます。
このソリューションでは、MLOps プロセスでラベル付けされたデータセットを使用して、認識モデルやセンサー 融合モデルなどの特殊なアルゴリズムを作成します。 このアルゴリズムでは、車の車線変更、ブロックされた道路、歩行者の交通、信号機、交通標識など、環境内のシーンやオブジェクトを検出できます。
データ パイプライン
この DataOps ソリューションでは、データ パイプライン内のさまざまなステージ間でのデータの移動が自動化されます。 このアプローチにより、このプロセスは効率、スケーラビリティ、一貫性、再現性、適応性、エラー処理のベネフィットを提供します。 開発プロセス全体を強化し、進歩を加速させ、自動運転技術の安全で効果的なデプロイをサポートします。
次のセクションでは、ステージ間のデータ移動を実装する方法と、ストレージ アカウントを構成する方法について説明します。
階層フォルダー構造
適切に整理されたフォルダー構造は、自律運転開発におけるデータ パイプラインの重要なコンポーネントです。 このような構造は、データ ファイルの体系的かつ簡単にナビゲート可能な配置を提供し、効率的なデータ管理と取得を容易にします。
このソリューションでは、 生フォルダー内のデータは次の階層構造になっています。
リージョン/生/<測定-ID>/<データ-ストリーム-ID>/YYYY/MM/DD
抽出されたゾーン ストレージ アカウント内のデータは、同様の階層構造を使用します。
リージョン/抽出/<測定-ID>/<data-stream-ID>/YYYY/MM/DD
同様の階層構造を使用することで、Data Lake Storage の階層型名前空間機能を利用できます。 階層構造は、スケーラブルでコスト効率の高いオブジェクト ストレージを作成するのに役立ちます。 これらの構造により、オブジェクトの検索と取得の効率も向上します。 年と VIN でパーティション分割すると、特定の車両から関連する画像を簡単に検索できます。 データ レイクでは、カメラ、GPS デバイス、ライダー、レーダー センサーなど、センサーごとにストレージ コンテナーが作成されます。
ランディング ストレージ アカウントから Raw ストレージ アカウントへ
Data Factory パイプラインは、スケジュールに基づいてトリガーされます。 パイプラインがトリガーされると、データはランディング ストレージ アカウントから Raw ストレージ アカウントにコピーされます。

パイプラインは、すべての測定フォルダーを取得し、それらを反復処理します。 測定ごとに、ソリューションは次のアクティビティを実行します。
測定を検証する機能。 この機能により、測定マニフェストからマニフェスト ファイルが取得されます。 次に、現在の測定のすべての MDF4、TDMS、rosbag 測定ファイルが測定フォルダーに存在するかどうかが確認されます。 検証が成功すると、この機能により次のアクティビティに進みます。 検証に失敗した場合、この機能により現在の測定をスキップし、次の測定フォルダーに移動します。
測定を作成する API に対して Web API 呼び出しが行われ、測定マニフェスト JSON ファイルからの JSON ペイロードが API に渡されます。 呼び出しが成功すると、応答が解析され、測定 ID が取得されます。 呼び出しが失敗した場合、測定はエラー処理のためにエラー時アクティビティに移動されます。
Note
この DataOps ソリューションは、アプリ サービスへの要求の数を制限することを前提に構築されています。 ソリューションが不確定な数の要求を行う可能性がある場合は、レート制限パターンを検討してください。
Web API 呼び出しは、必要な JSON ペイロードを作成することによってデータ ストリームを作成する API に対して行われます。 呼び出しが成功すると、応答が解析され、データ ストリーム ID とデータ ストリームの場所が取得されます。 呼び出しが失敗した場合、測定はエラー時アクティビティに移動されます。
Web API 呼び出しが行われ、データ ストリームの状態が
Start Copyに 更新されます。 呼び出しが成功すると、コピー アクティビティは測定ファイルをデータ ストリームの場所にコピーします。 呼び出しが失敗した場合、測定はエラー時アクティビティに移動されます。Data Factory パイプラインによって Batch が呼び出され、測定ファイルがランディング ストレージ アカウントから Raw ストレージ アカウントにコピーされます。 オーケストレーター アプリのコピー モジュールは、測定ごとに次のタスクを含むジョブを作成します。
- 測定ファイルを Raw ストレージ アカウントにコピーします。
- 測定ファイルをアーカイブ ストレージ アカウントにコピーします。
- ランディング ストレージ アカウントから測定ファイルを削除します。
Note
これらのタスクでは、Batch はオーケストレーター プールと AzCopy ツールを使用してデータのコピーと削除を行います。 AzCopy では、SAS トークンを使用してコピーまたは削除タスクを実行します。 SAS トークンはキー コンテナーに格納され、
landingsaskey、archivesaskey、rawsaskeyという用語を使用して参照されます。Web API 呼び出しが行われ、データ ストリームの状態が
Copy Completeに 更新されます。 呼び出しが成功すると、シーケンスは次のアクティビティに進みます。 呼び出しが失敗した場合、測定はエラー時アクティビティに移動されます。測定ファイルは、ランディング ストレージ アカウントからランディング アーカイブに移動されます。 このアクティビティは、ハイドレート コピー パイプラインを介してランディング ストレージ アカウントに戻すことによって、特定の測定を再実行できます。 このゾーンの測定が自動的に削除またはアーカイブされるように、このゾーンのライフサイクル管理が有効になっています。
測定でエラーが発生した場合、測定はエラー ゾーンに移動されます。 そこから、もう一度実行するランディング ストレージ アカウントに移動できます。 または、ライフサイクル管理によって、測定を自動的に削除またはアーカイブすることもできます。
以下の点に注意してください。
- これらのパイプラインは、スケジュールに基づいてトリガーされます。 この方法は、パイプライン実行の追跡可能性を向上させ、不要な実行を回避するのに役立ちます。
- 各パイプラインは、次のスケジュールされた実行が開始される前に、以前の実行が完了するようにコンカレンシー値 1 で構成されます。
- 各パイプラインは、測定値を並列にコピーするように構成されています。 たとえば、スケジュールされた実行でコピーする測定値が 10 個取得された場合、パイプラインステップは 10 個の測定値すべてに対して同時に実行できます。
- 各パイプラインは、パイプラインの完了に予想される時間よりも長い時間がかかる場合に、Monitor でアラートを生成するように構成されています。
- エラー時アクティビティは、後の監視ストーリーで実装されます。
- ライフサイクル管理では、欠落している rosbag ファイルを含む測定値など、部分的な測定値が自動的に削除されます。
バッチ設計
すべての抽出ロジックは、抽出プロセスごとに 1 つのコンテナーを使用して、異なるコンテナー イメージにパッケージ化されます。 バッチは、測定ファイルから情報を抽出するときに、コンテナー ワークロードを並列で実行します。

Batch では、ワークロードの処理にオーケストレーター プールと実行プールが使用されます。
- オーケストレーター プールには、コンテナー ランタイムをサポートしない Linux ノードがあります。 プールは、Batch API を使用して実行プールのジョブとタスクを作成する Python コードを実行します。 このプールでは、これらのタスクも監視されます。 Data Factory はオーケストレーター プールを呼び出します。これにより、データを抽出するコンテナー ワークロードが調整されます。
- 実行プールには、コンテナー ワークロードの実行をサポートするためのコンテナー ランタイムを含む Linux ノードがあります。 このプールでは、ジョブとタスクはオーケストレーター プールを介してスケジュールされます。 実行プールでの処理に必要なすべてのコンテナー イメージは、JFrog を使用してコンテナー レジストリにプッシュされます。 実行プールは、このレジストリに接続し、必要なイメージをプルするように構成されています。
データの読み取りと書き込みが行われるストレージ アカウントは、バッチ ノード上の NFS 3.0 とノードで実行されるコンテナーを介してマウントされます。 この方法により、バッチ ノードとコンテナーは、データ ファイルをバッチ ノードにローカルにダウンロードすることなく、データをすばやく処理できます。
Note
マウントするには、バッチ アカウントとストレージ アカウントが同じ仮想ネットワーク内にあることが必要です。
Data Factory から Batch を呼び出す
抽出パイプラインでは、トリガーはメタデータ ファイルのパスと、パイプライン パラメーター内の生データ ストリーム パスを渡します。 Data Factory では、 ファイルから JSON を解析しま検索回数アクティビティを使用して、マニフェストす。 生データ ストリーム ID は、パイプライン変数を解析することで、生データ ストリーム パスから抽出できます。
Data Factory は API を呼び出してデータ ストリームを作成します。 API は、抽出されたデータ ストリームのパスを返します。 抽出されたパスが現在のオブジェクトに追加され、Data Factory は、抽出されたデータ ストリーム パスを追加した後、現在の オブジェクトを渡すことによって、カスタム アクティビティを介して Batch を呼び出します。
{
"measurementId":"210b1ba7-9184-4840-a1c8-eb£397b7c686",
"rawDataStreamPath":"raw/2022/09/30/KA123456/210b1ba7-9184-4840-
alc8-ebf39767c68b/57472a44-0886-475-865a-ca32{c851207",
"extractedDatastreamPath":"extracted/2022/09/30/KA123456
/210bIba7-9184-4840-a1c8-ebf39767c68b/87404c9-0549-4a18-93ff-d1cc55£d8b78",
"extractedDataStreamId":"87404bc9-0549-4a18-93ff-d1cc55fd8b78"
}
ステップワイズ抽出プロセス

Data Factory では、抽出用の測定を処理するオーケストレーター プール用の 1 つのタスクを含むジョブがスケジュールされます。 Data Factory は、次の情報をオーケストレーター プールに渡します。
- 測定 ID
- 抽出する必要がある MDF4、TDMS、または rosbag 型の測定ファイルの場所
- 抽出されたコンテンツの保存場所の同期先パス
- 抽出されたデータ ストリーム ID
オーケストレーター プールは API を呼び出してデータ ストリームを更新し、その状態を
Processingに設定します。オーケストレーター プールは、測定の一部である各測定ファイルのジョブを作成します。 各ジョブには、次のタスクが含まれています。
タスク 目的 Note 検証 測定ファイルからデータを抽出できることを検証します。 その他のタスクはすべて、このタスクによって異なります。 メタデータを処理する 測定ファイルからメタデータを派生させ、API を使用してファイルのメタデータを更新することで、ファイルのメタデータをエンリッチします。 Process StructuredTopics特定の測定ファイルから構造化データを抽出します。 構造化データを抽出するトピックのリストは、構成オブジェクトとして渡されます。 プロセス CameraTopics特定の測定ファイルから画像データを抽出します。 画像を抽出するトピックのリストは、構成オブジェクトとして渡されます。 Process LidarTopics特定の測定ファイルからライダー データを抽出します。 ライダー データを抽出するトピックのリストは、構成オブジェクトとして渡されます。 Process CANTopics特定の測定ファイルからコントローラー エリア ネットワーク (CAN) データを抽出します。 データを抽出するトピックのリストは、構成オブジェクトとして渡されます。 オーケストレーター プールは、各タスクの進行状況を監視します。 すべての測定ファイルのすべてのジョブが完了すると、プールは API を呼び出してデータ ストリームを更新し、その状態を
Completedに設定します。オーケストレーターは正常に終了します。
Note
各タスクは、目的に合わせて適切に定義されたロジックを持つ個別のコンテナー イメージです。 タスクは、構成オブジェクトを入力として受け入れます。 たとえば、入力では、出力を書き込む場所と、処理する測定ファイルを指定します。
sensor_msgs/Imageなどの トピック型の配列は、入力のもう 1 つの例です。 他のすべてのタスクは検証タスクに依存するため、依存タスクが作成されます。 他のすべてのタスクは個別に処理でき、並列で実行できます。
考慮事項
以降の考慮事項には、ワークロードの品質向上に使用できる一連の基本原則である Azure "Well-Architected Framework" の要素が組み込まれています。 詳細については、「Microsoft Azure Well-Architected Framework」を参照してください。
[信頼性]
信頼性により、顧客に確約したことをアプリケーションで確実に満たせるようにします。 詳細については、「信頼性の重要な要素の概要」を参照してください。
- ソリューションでは、同じ Azure リージョン内の一意の物理的な場所である Azure 可用性ゾーンの使用を検討してください。
- ディザスター リカバリーとアカウントのフェールオーバーのためのプランを立てる。
セキュリティ
セキュリティは、重要なデータやシステムの意図的な攻撃や悪用に対する保証を提供します。 詳細については、「セキュリティの重要な要素の概要」を参照してください。
自動車メーカーと Microsoft との責任の分担を理解することが重要です。 車両では、メーカーはスタック全体を所有しますが、データがクラウドに移動すると、責任の一部は Microsoft に移譲されます。 Azure PaaS (サービスとしてのプラットフォーム) レイヤーでは、オペレーティング システムなど、物理スタックにセキュリティが組み込まれています。 既存のインフラストラクチャ セキュリティ コンポーネントには、次の機能を追加できます。
- Microsoft Entra ID と Microsoft Entra 条件付きアクセス ポリシーを使用する ID 管理とアクセス管理。
- Azure Policy を使用するインフラストラクチャ ガバナンス。
- Microsoft Purview を使用するデータ ガバナンス。
- ネイティブ Azure Storage とデータベース サービスを使用する保存データの暗号化。 詳細については、「データ保護に関する考慮事項」を参照してください。
- 暗号化キーとシークレットの保護。 この目的を果たすために、Azure Key Vault を使用します。
コスト最適化
コストの最適化では、不要な費用を削減し、運用効率を向上させる方法を検討します。 詳しくは、コスト最適化の柱の概要に関する記事をご覧ください。
自動運転車用の DataOps を運用する OEM および Tier 1 サプライヤーにとって重要な懸念事項は、運用コストです。 このソリューションでは、次の方法を使用してコストを最適化します。
- Azure がアプリケーション コードをホストするために提供するさまざまなオプションを利用する。 このソリューションでは、App Service と Batch を使用します。 デプロイに適したサービスを選択する方法のガイダンスについては、「Azure コンピューティング サービスを選択する」を参照してください。
- Azure Storage のインプレース データ共有の使用。
- ライフサイクル管理を使用してコストを最適化する。
- 予約インスタンスを使用して App Service のコストを削減する。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパルの作成者:
- Ryan Matsumura | シニア プログラム マネージャー
- Jochen Schroeer | リード アーキテクト (サービス ライン モビリティ)
- Brij Singh | プリンシパル ソフトウェア エンジニア
- ジネット・ヴェラーラ |シニア ソフトウェア エンジニアリング リーダー
公開されていない LinkedIn プロフィールを見るには、LinkedIn にサインインしてください。
次の手順
- Azure Batch とは
- Azure Data Factory とは
- Azure Data Lake Storage Gen2 の概要
- Azure Cosmos DB へようこそ
- App Service の概要
- Azure Data Share とは
- Azure Data Box とは何ですか?
- Azure Stack Edge のドキュメント
- Azure ExpressRoute とは
- Azure Machine Learning とは
- Azure Databricks とは
- Azure Synapse Analytics とは
- Azure Monitor の概要
- ROS Log Files (rosbags)
- 自律運転車のための大規模データ運用プラットフォーム
関連リソース
自動運転システム用の ValOps の開発方法の詳細については、以下を参照してください。
必要に応じて次の関連する記事も参照してください。