注意事項
この記事では、サポート終了 (EOL) となっている Linux ディストリビューションである CentOS について説明します。 適宜、使用と計画を検討してください。 詳細については、「CentOS のサポート終了に関するガイダンス」を参照してください。
このシナリオ例では、Azure で Apache NiFi を実行する方法を示します。 NiFi は、データを処理および配布するためのシステムを提供します。
Apache®、Apache NiFi®、NiFi® は、Apache Software Foundation の米国およびその他の国における登録商標または商標です。 これらのマークを使用することが、Apache Software Foundation による保証を意味するものではありません。
Architecture

このアーキテクチャの Visio ファイルをダウンロードします。
ワークフロー
NiFi アプリケーションは、NiFi クラスター ノード内の VM 上で実行されます。 VM は、構成が可用性ゾーン全体にデプロイされる仮想マシン スケール セット内にあります。
Apache ZooKeeper は、別のクラスター内の VM で実行されます。 NiFi では、次の目的で ZooKeeper クラスターが使用されます。
- クラスター コーディネーター ノードを選択する
- データのフローを調整する
Azure Application Gateway は、NiFi ノードで実行されるユーザー インターフェイスにレイヤー 7 の負荷分散を提供します。
モニターとそのログ分析機能は、NiFi システムからテレメトリを収集、分析、および処理します。 テレメトリには、NiFi システム ログ、システム正常性メトリック、およびパフォーマンス メトリックが含まれます。
Azure Key Vault は、NiFi クラスターの証明書とキーを安全に保存します。
Microsoft Entra ID には、シングル サインオン (SSO) と多要素認証があります。
コンポーネント
- NiFi は、データを処理および配布するためのシステムを提供します。
- ZooKeeper は、分散システムを管理するオープンソース サーバーです。
- Virtual Machines は サービスとしてのインフラストラクチャ (IaaS) オファーです。 Virtual Machines を使用して、オンデマンドのスケーラブルなコンピューティング リソースをデプロイできます。 Virtual Machines は仮想化の柔軟性を提供しながら、物理ハードウェアのメンテナンスの必要性を排除します。
- Azure 仮想マシン スケール セットでは、負荷分散が行われる VM のグループを作成して管理することができます。 セット内の VM インスタンスの数は、需要または定義されたスケジュールに応じて自動的に増減させることができます。
- 可用性ゾーンは、Azure リージョン内の一意の物理的な場所です。 これらの高可用性オファリングは、データセンターの障害からアプリケーションとデータを保護します。
- Azure Application Gateway は、Web アプリケーションへのトラフィックを管理するロード バランサーです。
- モニターでは、環境と Azure リソースに関するデータを収集して分析します。 このデータには、パフォーマンス メトリックやアクティビティ ログなどのアプリ テレメトリが含まれます。 詳細については、この記事で後述する「監視に関する考慮事項」をご覧ください。
- Log Analytics は、モニター ログ データに対してクエリを実行する Azure portal ツールです。 Log Analytics には、クエリ結果をグラフ化および統計分析するための機能も用意されています。
- Azure DevOps Services には、コード プロジェクトとデプロイを管理するためのサービス、ツール、環境などが用意されています。
- Key Vault では、API キー、パスワード、証明書、暗号化キーといったシステムのシークレットが安全に保存され、それらへのアクセスが制御されます。
- Microsoft Entra ID は、Azure およびその他のクラウド アプリへのアクセスを制御するクラウドベースの ID サービスです。
代替
- Azure Data Factory では、このソリューションの代替手段を提供します。
- Key Vault の代わりに、同等のサービスを使用してシステム シークレットを保存できます。
- Apache Airflow。 詳細については、Airflow と NiFi の違いに関する記事を参照してください。
- Cloudera Apache NiFi など、エンタープライズ NiFi の代替手段としてサポートされているものを使用できます。 Cloudera のオファリングは、Azure Marketplace を通じて利用できます。
シナリオの詳細
このシナリオでは、NiFi はスケール セット内の Azure Virtual Machines 全体でクラスター化された構成で実行されます。 ただし、この記事に記載されている推奨事項の大部分は、単一の仮想マシン (VM) で単一インスタンス モードで NiFi を実行するシナリオにも適用されます。 この記事に記載のベスト プラクティスは、スケーラブルで高可用性、かつ安全なデプロイを示しています。
考えられるユース ケース
NiFi は、データの移動とデータ フローの管理に適しています。
- 分離されたシステムをクラウドで接続する
- Azure Storage およびその他のデータ ストアとの間でデータを移動する
- エッジツークラウドおよびハイブリッドクラウド アプリケーションを Azure IoT、Azure Stack、および Azure Kubernetes サービス (AKS) と統合する
その結果、このソリューションは多くの領域に適用されます。
最新のデータ ウェアハウス (MDW) は、大規模に構造化データと非構造化データをまとめています。 さまざまなソース、シンク、および形式からデータを収集して保存します。 NiFi は、次の理由により、Azure ベース MDW へのデータ取り込みに優れています。
- データの読み取り、書き込み、および操作には、200 を超えるプロセッサを使用できます。
- このシステムは、Azure Blob Storage、Azure Data Lake Storage、Azure Event Hubs、Azure Queue Storage、Azure Cosmos DB、Azure Synapse Analytics などのストレージ サービスをサポートしています。
- 堅牢なデータ来歴機能により、準拠したソリューションを実装できます。 Azure Monitor のログ分析機能でデータ来歴をキャプチャする方法については、この記事で後述する「レポートに関する考慮事項」をご覧ください。
NiFiは、フットプリントの小さいデバイスでスタンドアロンで実行できます。 このような場合、NiFi を使用すると、エッジ データを処理し、そのデータをクラウド内のより大きな NiFi インスタンスまたはクラスターに移動できます。 NiFi は、移動中のエッジ データのフィルター処理、変換、優先度付けを行うのに役立ち、信頼性が高く効率的なデータ フローを保証します。
産業用 IoT (IIoT) ソリューションは、エッジからデータセンターへのデータフローを管理します。 そのフローは、産業用制御システムと機器からのデータ取得から始まります。 その後、データはデータ管理ソリューションと MDW に移動します。 NiFi では、データの取得と移動に適した機能を提供しています。
- エッジ データ処理機能
- IoT ゲートウェイおよびデバイスで使用されるプロトコルのサポート
- Event Hubs とストレージ サービスとの統合
予測メンテナンスとサプライ チェーン管理の分野における IoT アプリケーションでは、この機能を利用できます。
推奨事項
このソリューションを使用する場合は、次の点に注意してください。
NiFi の推奨バージョン
Azure でこのソリューションを実行する場合は、バージョン 1.13.2 以降の NiFi を使用することをお勧めします。 他のバージョンを実行することもできますが、このガイドのものとは異なる構成が必要になる場合があります。
Azure VM に NiFi をインストールするには、NiFi ダウンロード ページから便利なバイナリをダウンロードすることをお勧めします。 ソース コードからバイナリをビルドすることもできます。
ZooKeeper の推奨バージョン
このワークロードの例では、バージョン 3.5.5 以降または ZooKeeper 3.6.x を使用することをお勧めします。
公式の便利なバイナリまたはソース コードを使用して、Azure VM に ZooKeeper をインストールできます。 どちらも Apache ZooKeeper リリース ページで入手できます。
考慮事項
以降の考慮事項には、ワークロードの品質向上に使用できる一連の基本原則である Azure "Well-Architected Framework" の要素が組み込まれています。 詳細については、「Microsoft Azure Well-Architected Framework」を参照してください。
NiFi 構成の詳細については、 「Apache NiFi システム管理者ガイド」をご覧ください。 このソリューションを実装する場合は、次の考慮事項にも留意してください。
コスト最適化
コストの最適化とは、不要な費用を削減し、運用効率を向上させる方法を検討することです。 詳しくは、コスト最適化の柱の概要に関する記事をご覧ください。
- このアーキテクチャのリソース コストを見積もるには、Azure 料金計算ツールを使用します。
- このアーキテクチャのすべてのサービス (カスタム警告ソリューションを除く) を含む見積もりについては、このサンプル コスト プロファイルをご覧ください。
VM に関する考慮事項
次のセクションでは、NiFi VM を構成する方法の詳細な概要について説明します。
VM サイズ
この表では、最初に推奨される VM サイズを示しています。 ほとんどの汎用データ フローには、Standard_D16s_v3 が最も適しています。 ただし、NiFi の各データ フローには異なる要件があります。 フローをテストし、フローの実際の要件に基づいて必要に応じてサイズを変更します。
VM で Accelerated Networking を有効にして、ネットワーク パフォーマンスを向上させることを検討してください。 詳細については、「Azure 仮想マシン スケール セットのネットワーク」を参照してください。
| VM サイズ | vCPU | GB 単位のメモリ | MBps* あたりの 1 秒あたりの I/O 操作 (IOPS) でのキャッシュされていないデータ ディスクの最大スループット | 最大ネットワーク インターフェイス (NIC) / 必要なネットワーク帯域幅 (Mbps) |
|---|---|---|---|---|
| Standard_D8s_v3 | 8 | 32 | 12,800/192 | 4/4,000 |
| Standard_D16s_v3** | 16 | 64 | 25,600/384 | 8/8,000 |
| Standard_D32s_v3 | 32 | 128 | 51,200/768 | 8/16,000 |
| Standard_M16m | 16 | 437.5 | 10,000/250 | 8/4,000 |
* NiFi ノードで使用しているすべてのデータ ディスクのデータ ディスク書き込みキャッシュを無効にします。
** ほとんどの汎用データ フローには、この SKU をお勧めします。 vCPU とメモリの構成が類似している Azure VM SKU も適切である必要があります。
VM のオペレーティング システム (OS)
Azure で NiFi を実行する場合は、次のいずれかのゲスト オペレーティング システムで実行することをお勧めします。
- Ubuntu 18.04 LTS 以降
- CentOS 7.9
特定のデータ フロー要件を満たすには、次のような OS レベルの設定をいくつか調整することが重要です。
- フォーク プロセスの最大数。
- ファイル ハンドルの最大数。
- アクセス時刻:
atime。
予想されるユース ケースに合わせて OS を調整した後、Azure VM Image Builder を使用して、これらの調整されたイメージの生成を体系化します。 NiFi に固有のガイダンスについては、「Apache NiFi システム管理者ガイド」の「構成のベスト プラクティス」をご覧ください。
ストレージ
さまざまな NiFi リポジトリを OS ディスクではなくデータ ディスクに保存する主な理由は次の 3 つです。
- フローには、単一のディスクでは満たすことができない高いディスク スループット要件がよくあります。
- NiFi ディスク操作を OS ディスク操作から分離するのが最善です。
- リポジトリを一時ストレージに置くことはできません。
次のセクションでは、データ ディスクを構成するためのガイドラインの概要を説明します。 これらのガイドラインは Azure に固有のものです。 リポジトリの構成に関する詳細については、「Apache NiFi システム管理者ガイド」の状態管理をご覧ください。
データ ディスクの種類とサイズ
NiFi 用にデータ ディスクを構成する場合は、次の要素を考慮してください。
- ディスクの種類
- ディスク サイズ
- ディスクの総数
注意
ディスクの種類、サイズ、および価格に関する最新情報については、「Azure マネージド ディスクの概要」をご覧ください。
次の表は、Azure で現在使用できるマネージド ディスクの種類を示しています。 NiFi では、これらのディスクの種類を使用できます。 ただし、高スループットのデータ フローには、Premium SSD をお勧めします。
| Ultra Disk Storage (NVM Express (NVMe)) | Premium SSD | Standard SSD | Standard HDD | |
|---|---|---|---|---|
| ディスクの種類 | SSD | SSD | SSD | HDD |
| 最大ディスク サイズ | 65,536 GB | 32,767 GB | 32,767 GB | 32,767 GB |
| 最大スループット | 2,000 MiB/秒 | 900 MiB/秒 | 750 MiB/秒 | 500 MiB/秒 |
| 最大 IOPS | 160,000 | 20,000 | 6,000 | 2,000 |
データ フローのスループットを向上させるには、少なくとも 3 つのデータ ディスクを使用します。 ディスク上のリポジトリを構成するためのベスト プラクティスについては、この記事で後述する「リポジトリの構成」をご覧ください。
次の表に、各ディスク サイズと種類に関連するサイズとスループットの数値を示します。
| Standard HDD S15 | Standard HDD S20 | Standard HDD S30 | Standard SSD S15 | Standard SSD S20 | Standard SSD S30 | Premium SSD P15 | Premium SSD P20 | Premium SSD P30 | |
|---|---|---|---|---|---|---|---|---|---|
| ディスクサイズ (GB 単位) | 256 | 512 | 1,024 | 256 | 512 | 1,024 | 256 | 512 | 1,024 |
| ディスクあたりの IOPS | 最大 500 | 最大 500 | 最大 500 | 最大 500 | 最大 500 | 最大 500 | 1,100 | 2,300 | 5,000 |
| ディスクあたりのスループット | 最大 60 Mbps | 最大 60 Mbps | 最大 60 Mbps | 最大 60 Mbps | 最大 60 Mbps | 最大 60 Mbps | 125 MBps | 150 MBps | 200 MBps |
システムが VM の制限に達した場合、ディスクを追加してもスループットが向上しない可能性があります。
- IOPS とスループットの制限は、ディスクのサイズによって異なります。
- 選択した VM サイズにより、VM の IOPS とスループットの制限がすべてのデータ ディスクに設定されます。
VM レベルのディスク スループットの制限については、「Azure の Linux 仮想マシンのサイズ」をご覧ください。
VM ディスクのキャッシュ
Azure VM では、ホスト キャッシュ機能によってディスクの書き込みキャッシュが管理されます。 リポジトリに使用するデータ ディスクのスループットを向上させるには、ホスト キャッシュを None に設定して、ディスクの書き込みキャッシュをオフにします。
リポジトリの構成
NiFi では、これらのリポジトリごとに個別のディスクを使用することをお勧めします。
- Content
- FlowFile
- 来歴
この方法では、最低 3 台のディスクが必要です。
NiFi は、アプリケーションレベルのストライピングもサポートしています。 この機能により、データ リポジトリのサイズやパフォーマンスが向上します。
次の抜粋は、nifi.properties 構成ファイルからのものです。 この構成では、VM に接続されているマネージド ディスク間でリポジトリを分割し、ストライピングします。
nifi.provenance.repository.directory.stripe1=/mnt/disk1/ provenance_repository
nifi.provenance.repository.directory.stripe2=/mnt/disk2/ provenance_repository
nifi.provenance.repository.directory.stripe3=/mnt/disk3/ provenance_repository
nifi.content.repository.directory.stripe1=/mnt/disk4/ content_repository
nifi.content.repository.directory.stripe2=/mnt/disk5/ content_repository
nifi.content.repository.directory.stripe3=/mnt/disk6/ content_repository
nifi.flowfile.repository.directory=/mnt/disk7/ flowfile_repository
高パフォーマンス ストレージの設計の詳細については、「Azure Premium Storage: 高パフォーマンス ストレージの設計」をご覧ください。
レポート
NiFiには、ログ分析機能の来歴レポート タスクが含まれています。
このレポート タスクを使用すると、来歴イベントをコスト効率が高く耐久性のある長期ストレージにオフロードできます。 ログ分析機能では、個々のイベントを表示およびグラフ化するためのクエリ インターフェイスを提供します。 これらのクエリの詳細については、この記事で後述する「ログ分析クエリ」をご覧ください。
このタスクは、揮発性メモリ内の来歴ストレージと共に使用することもできます。 多くのシナリオでは、スループットの増加を実現できます。 ただし、イベント データを保持する必要がある場合、この方法は危険です。 揮発性ストレージが来歴イベントの耐久性要件を満たしていることを確認します。 詳細については、「Apache NiFi システム管理者ガイド」の「来歴リポジトリ」をご覧ください。
このプロセスを使用する前に、Azure サブスクリプションで Log Analytics ワークスペースを作成します。 ワークスペースは、ワークロードと同じリージョンに設定することをお勧めします。
来歴レポート タスクを構成するには、次の操作を行います。
- NiFi で [コントローラーの設定] を開きます。
- [レポート タスク] メニューを選択します。
- [新しいレポート タスクを作成する] を選択します。
- [Azure Log Analytics レポート タスク] を選択します。
次のスクリーンショットは、このレポート タスクの [プロパティ] メニューを示しています。
![NiFi の [構成レポート タスク] ウィンドウのスクリーンショット。[プロパティ] メニューが表示されます。ログ分析設定の値が一覧表示されます。](/ja-jp/azure/architecture/example-scenario/data/media/nifi-configure-reporting-task-window.png)
2 つのプロパティが必要です。
- Log Analytics ワークスペース ID
- Log Analytics ワークスペース キー
これらの値は、Azure portal で [Log Analytics] ワークスペースに移動して確認できます。
その他のオプションを使用して、システムから送信されるイベントのカスタマイズやフィルター処理を行うこともできます。
セキュリティ
セキュリティは、重要なデータやシステムの意図的な攻撃や悪用に対する保証を提供します。 詳細については、「セキュリティの重要な要素の概要」を参照してください。
NiFi は認証と承認の観点からセキュリティ保護できます。 また、次のようなすべてのネットワーク通信で NiFi を保護することもできます。
- クラスター内。
- クラスターと ZooKeeper の間。
次のオプションをオンにする手順については、「Apache NiFi 管理者ガイド」をご覧ください。
- Kerberos
- ライトウェイト ディレクトリ アクセス プロトコル (LDAP)
- 証明書ベースの認証と承認
- クラスター通信用の双方向 Secure Sockets Layer (SSL)
ZooKeeper のセキュリティで保護されたクライアント アクセスを有効にする場合は、関連するプロパティを bootstrap.conf 構成ファイルに追加して NiFi を構成します。 次の構成エントリに例を示します。
java.arg.18=-Dzookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNetty
java.arg.19=-Dzookeeper.client.secure=true
java.arg.20=-Dzookeeper.ssl.keyStore.location=/path/to/keystore.jks
java.arg.21=-Dzookeeper.ssl.keyStore.password=[KEYSTORE PASSWORD]
java.arg.22=-Dzookeeper.ssl.trustStore.location=/path/to/truststore.jks
java.arg.23=-Dzookeeper.ssl.trustStore.password=[TRUSTSTORE PASSWORD]
一般的な推奨事項については、「Linux のセキュリティ ベースライン」をご覧ください。
ネットワークのセキュリティ
このソリューションを実装する場合は、ネットワーク セキュリティに関する次の点に注意してください。
ネットワーク セキュリティ グループ
Azureでは、ネットワーク セキュリティ グループを使用してネットワーク トラフィックを制限できます。
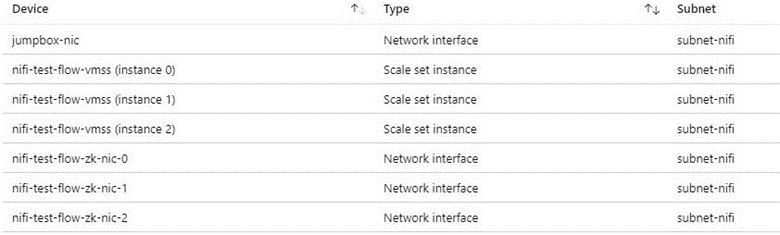
NiFi クラスターに接続して管理タスクを行う場合は、ジャンプボックスをお勧めします。 Just-In-Time (JIT) アクセスまたは Azure Bastion でこのセキュリティが強化された VM を使用します。 ネットワーク セキュリティ グループを設定して、ジャンプボックスまたは Azure Bastion へのアクセスを許可する方法を制御します。 アーキテクチャのさまざまなサブネットでネットワーク セキュリティ グループを慎重に使用することで、ネットワークの分離と制御を実現できます。
次のスクリーンショットは、一般的な仮想ネットワークのコンポーネントを示しています。 これには、ジャンプボックス、仮想マシン スケール セット、および ZooKeeper VM の共通サブネットが含まれています。 この簡略化されたネットワーク トポロジは、コンポーネントを 1 つのサブネットにグループ化します。 職務の分離とネットワーク設計については、組織のガイドラインに従ってください。
送信インターネット アクセスに関する考慮事項
Azure の NiFi では、パブリック インターネットにアクセスして実行する必要はありません。 データ フローがデータを取得するためにインターネット アクセスを必要としない場合は、次の手順に従って送信インターネット アクセスを無効にしてクラスターのセキュリティを強化します。
仮想ネットワーク内に追加のネットワーク セキュリティ グループ ルールを作成します。
次の設定を使用します。
- ソース:
Any - 宛先:
Internet - アクション:
Deny
- ソース:

このルールを設定しても、仮想ネットワークでプライベート エンドポイントを構成すると、データ フローから一部の Azure サービスにアクセスできます。 この目的のために Azure Private Link を使用します。 このサービスは、他の外部ネットワーク アクセスを必要とせずに、トラフィックが Microsoft のバックボーン ネットワーク上を移動する方法を提供します。 NiFi は現在、Blob Storage と Data Lake Storage プロセッサの Private Link をサポートしています。 Network Time Protocol (NTP) サーバーがプライベート ネットワークで使用できない場合は、NTP への送信アクセスを許可します。 詳細については、「Azure での Linux VM の時刻同期」をご覧ください。
データの保護
ワイヤ暗号化、ID およびアクセス管理 (IAM)、またはデータ暗号化を使用せずに、セキュリティで保護されていない NiFi を操作することができます。 ただし、運用環境とパブリック クラウドのデプロイは次の方法で保護することをお勧めします。
- トランスポート層セキュリティ (TLS) を使用した通信の暗号化
- サポートされている認証および承認メカニズムの使用
- 保存データの暗号化
Azure Storage には、サーバー側の透過的なデータ暗号化が用意されています。 ただし、1.13.2 リリース以降、NiFi は既定でワイヤ暗号化や IAM を構成しません。 この動作は、将来のリリースで変更される可能性があります。
次のセクションでは、これらの方法でデプロイをセキュリティで保護する方法について説明します。
- TLS でワイヤ暗号化を有効にする
- 証明書または Microsoft Entra ID に基づく認証を構成する
- Azure で暗号化されたストレージを管理する
ディスクの暗号化
セキュリティを強化するには、Azure Disk Encryption を使用します。 詳細な手順については、「Azure CLI で仮想マシン スケール セット内の OS および接続されているデータ ディスクを暗号化する」をご覧ください。 このドキュメントには、独自の暗号化キーを提供する手順も記載されています。 次の手順では、ほとんどの展開で機能する NiFi の基本的な例の概要を示します。
既存の Key Vault インスタンスでディスク暗号化を有効にするには、次の Azure CLI コマンドを使用します。
az keyvault create --resource-group myResourceGroup --name myKeyVaultName --enabled-for-disk-encryption次のコマンドを使用して、仮想マシン スケール セットのデータ ディスクの暗号化を有効にします。
az vmss encryption enable --resource-group myResourceGroup --name myScaleSet --disk-encryption-keyvault myKeyVaultID --volume-type DATA必要に応じて、キー暗号化キー (KEK) を使用することもできます。 KEK で暗号化するには、次の Azure CLI コマンドを使用します。
az vmss encryption enable --resource-group myResourceGroup --name myScaleSet \ --disk-encryption-keyvault myKeyVaultID \ --key-encryption-keyvault myKeyVaultID \ --key-encryption-key https://<mykeyvaultname>.vault.azure.net/keys/myKey/<version> \ --volume-type DATA
Note
仮想マシンのスケール セットを手動更新モードに構成した場合は、update-instances コマンドを実行します。 Key Vault に保存した暗号化キーのバージョンを含めます。
転送中の暗号化
NiFi では転送中の暗号化に TLS 1.2 がサポートされます。 このプロトコルは、UI へのユーザー アクセスを保護します。 クラスターを使用すると、このプロトコルは NiFi ノード間の通信を保護します。 また、ZooKeeper との通信を保護することもできます。 TLSを有効にすると、NiFi は次の相互認証に相互 TLS (mTLS) を使用します。
- このタイプの認証を構成した場合は、証明書ベースのクライアント認証。
- すべてのクラスター内通信。
TLS を有効にするには、次の手順を実行します。
クライアントとサーバー、クラスター内の通信と認証用のキーストアとトラストストアを作成します。
$NIFI_HOME/conf/nifi.propertiesを構成します。 次の値を設定します。- ホスト名
- Port
- キーストアのプロパティ
- トラストストアのプロパティ
- クラスターおよび ZooKeeper のセキュリティ プロパティ (該当する場合)
$NIFI_HOME/conf/authorizers.xmlで認証を構成します。通常は、証明書ベースの認証または別のオプションを持つ初期ユーザーを使用します。必要に応じて、NiFi とプロキシ、ロード バランサー、または外部エンドポイント間で、mTLS とプロキシ読み取りポリシーを構成します。
完全なチュートリアルについては、Apache プロジェクト ドキュメントの「TLS を使用した NiFi のセキュリティ保護」を参照してください。
注意
バージョン 1.13.2 以降:
- NiFi は既定で TLS を有効にしません。
- TLS 対応のインスタンスに対して、匿名アクセスとシングル ユーザー アクセスをすぐにサポートすることはできません。
転送中の暗号化に対して TLS を有効にするには、$NIFI_HOME/conf/authorizers.xml で認証と承認を行うためにユーザー グループとポリシー プロバイダーを構成します。 詳細については、この記事で後述する「ID およびアクセス制御」をご覧ください。
証明書、キー、およびキーストア
TLS をサポートするには、証明書を生成し、それらを Java キーストアとトラストストアに保存して、NiFi クラスターに配布します。 証明書には、次の 2 つの一般的なオプションがあります。
- 自己署名証明書
- 認証機関 (CA) が署名する証明書
CA 署名の証明書を使用する場合は、中間 CA を使用してクラスター内のノードの証明書を生成することをお勧めします。
キーストアとトラストストアは、Java プラットフォームのキー コンテナーおよび証明書コンテナーです。 キーストアは、クラスター内のノードの秘密キーと証明書を保存します。 トラストストアは、次のいずれかの種類の証明書を保存します。
- 信頼できるすべての証明書 (キーストアの自己署名証明書の場合)
- CA からの証明書 (キーストアの CA 署名証明書の場合)
コンテナーを選択するときには、NiFi クラスターのスケーラビリティを考慮してください。 たとえば、将来的にクラスター内のノード数を増減したい場合があります。 その場合は、キーストアで CA 署名の証明書を選択し、トラストストアで CA から 1 つ以上の証明書を選択します。 のオプションを使用すると、クラスターの既存のノードにある既存のトラストストアを更新する必要はありません。 既存のトラストストアは、次の種類のノードの証明書を信頼して受け入れます。
- クラスターに追加するノード
- クラスター内の他のノードを置き換えるノード
NiFi 構成
NiFi の TLS を有効にするには、$NIFI_HOME/conf/nifi.properties を使用してこのテーブルのプロパティを構成します。 次のプロパティに、NiFi へのアクセスに使用するホスト名が含まれていることを確認します。
nifi.web.https.hostまたはnifi.web.proxy.host- ホスト証明書の指定名前またはサブジェクトの代替名
そうしないと、ホスト名の検証エラーまたは HTTP ホスト ヘッダーの検証エラーが発生し、ユーザーのアクセスが拒否されることがあります。
| プロパティ名 | 説明 | 値の例 |
|---|---|---|
nifi.web.https.host |
UI および REST API に使用するホスト名または IP アドレス。 この値は内部的に解決可能である必要があります。 パブリックにアクセスできる名前は使用しないことをお勧めします。 | nifi.internal.cloudapp.net |
nifi.web.https.port |
UI および REST API に使用する HTTPS ポート。 | 9443 (既定値) |
nifi.web.proxy.host |
クライアントが UI および REST API にアクセスするために使用する代替ホスト名のコンマ区切りリスト。 このリストには通常、サーバー証明書でサブジェクト代替名 (SAN) として指定されているホスト名が含まれます。 このリストには、ロード バランサー、プロキシ、または Kubernetes イングレス コントローラーが使用する任意のホスト名とポートを含めることもできます。 | 40.67.218.235, 40.67.218.235:443, nifi.westus2.cloudapp.com, nifi.westus2.cloudapp.com:443 |
nifi.security.keystore |
証明書の秘密キーを含む JKS または PKCS12 キーストアへのパス。 | ./conf/keystore.jks |
nifi.security.keystoreType |
キーストアの種類。 | JKS または PKCS12 |
nifi.security.keystorePasswd |
キーストアのパスワード。 | O8SitLBYpCz7g/RpsqH+zM |
nifi.security.keyPasswd |
(オプション) 秘密キーのパスワード。 | |
nifi.security.truststore |
信頼できるユーザーとクラスター ノードを認証する証明書または CA 証明書を含む JKS または PKCS12 トラストストアへのパス。 | ./conf/truststore.jks |
nifi.security.truststoreType |
トラストストアの種類。 | JKS または PKCS12 |
nifi.security.truststorePasswd |
トラストストアのパスワード。 | RJlpGe6/TuN5fG+VnaEPi8 |
nifi.cluster.protocol.is.secure |
クラスタ内通信の TLS の状態。 nifi.cluster.is.node が true の場合、この値を true に設定して、クラスター TLS を有効にします。 |
true |
nifi.remote.input.secure |
サイト間通信の TLS の状態。 | true |
次の例は、これらのプロパティが $NIFI_HOME/conf/nifi.properties にどのように表示されるかを示しています。 nifi.web.http.host と nifi.web.http.port の値は空白であることに注意してください。
nifi.remote.input.secure=true
nifi.web.http.host=
nifi.web.http.port=
nifi.web.https.host=nifi.internal.cloudapp.net
nifi.web.https.port=9443
nifi.web.proxy.host=40.67.218.235, 40.67.218.235:443, nifi.westus2.cloudapp.com, nifi.westus2.cloudapp.com:443
nifi.security.keystore=./conf/keystore.jks
nifi.security.keystoreType=JKS
nifi.security.keystorePasswd=O8SitLBYpCz7g/RpsqH+zM
nifi.security.keyPasswd=
nifi.security.truststore=./conf/truststore.jks
nifi.security.truststoreType=JKS
nifi.security.truststorePasswd=RJlpGe6/TuN5fG+VnaEPi8
nifi.cluster.protocol.is.secure=true
ZooKeeper の構成
クォーラム通信とクライアント アクセスのために Apache ZooKeeper で TLS を有効にする手順については、「ZooKeeper 管理者ガイド」をご覧ください。 この機能をサポートしているのは、3.5.5 以降のバージョンのみです。
NiFi は、ゼロリーダー クラスタリングとクラスター調整に ZooKeeper を使用します。 バージョン1.13.0以降、NiFi では、セキュリティで保護されたクライアントが ZooKeeper の TLS 対応インスタンスにアクセスできるようになりました。 ZooKeeper は、クラスターのメンバーシップとクラスター スコープのプロセッサ状態をプレーン テキストで保存します。 そのため、セキュリティで保護されたクライアント アクセスを使用して ZooKeeper にアクセスして ZooKeeper のクライアント要求を認証することが重要です。 また、転送中の機密値も暗号化します。
ZooKeeper への NiFi クライアント アクセスの TLS を有効にするには、$NIFI_HOME/conf/nifi.properties で次のプロパティを設定します。 nifi.zookeeper.security プロパティを校正せずに nifi.zookeeper.client.secure true を設定する場合、NiFi は、nifi.securityproperties で指定したキーストアとトラストストアにフォールバックします。
| プロパティ名 | 説明 | 値の例 |
|---|---|---|
nifi.zookeeper.client.secure |
ZooKeeper に接続するときのクライアント TLS の状態。 | true |
nifi.zookeeper.security.keystore |
認証用に ZooKeeper に提示される証明書の秘密キーを含む JKS、PKCS12、または PEM キーストアへのパス。 | ./conf/zookeeper.keystore.jks |
nifi.zookeeper.security.keystoreType |
キーストアの種類。 | JKS、PKCS12、PEM、または拡張機能による自動検出 |
nifi.zookeeper.security.keystorePasswd |
キーストアのパスワード。 | caB6ECKi03R/co+N+64lrz |
nifi.zookeeper.security.keyPasswd |
(オプション) 秘密キーのパスワード。 | |
nifi.zookeeper.security.truststore |
ZooKeeper の認証に使用される証明書または CA 証明書を含む JKS、PKCS12、または PEM トラストストアへのパス。 | ./conf/zookeeper.truststore.jks |
nifi.zookeeper.security.truststoreType |
トラストストアの種類。 | JKS、PKCS12、PEM、または拡張機能による自動検出 |
nifi.zookeeper.security.truststorePasswd |
トラストストアのパスワード。 | qBdnLhsp+mKvV7wab/L4sv |
nifi.zookeeper.connect.string |
ZooKeeper ホストまたはクォーラムへの接続文字列。 この文字列は host:port 値のコンマ区切りリストです。 通常、secureClientPort の値は clientPort の値と同じではありません。 正しい値については、ZooKeeper の構成をご覧ください。 |
zookeeper1.internal.cloudapp.net:2281, zookeeper2.internal.cloudapp.net:2281, zookeeper3.internal.cloudapp.net:2281 |
次の例は、これらのプロパティが $NIFI_HOME/conf/nifi.properties にどのように表示されるかを示しています。
nifi.zookeeper.client.secure=true
nifi.zookeeper.security.keystore=./conf/keystore.jks
nifi.zookeeper.security.keystoreType=JKS
nifi.zookeeper.security.keystorePasswd=caB6ECKi03R/co+N+64lrz
nifi.zookeeper.security.keyPasswd=
nifi.zookeeper.security.truststore=./conf/truststore.jks
nifi.zookeeper.security.truststoreType=JKS
nifi.zookeeper.security.truststorePasswd=qBdnLhsp+mKvV7wab/L4sv
nifi.zookeeper.connect.string=zookeeper1.internal.cloudapp.net:2281,zookeeper2.internal.cloudapp.net:2281,zookeeper3.internal.cloudapp.net:2281
TLS を使用して ZooKeeper を保護する方法の詳細については、「Apache NiFi 管理ガイド」をご覧ください。
ID とアクセスの制御
NiFi の ID とアクセス制御は、ユーザー認証と承認によって実現されます。 ユーザー認証の場合、NiFi には、シングル ユーザー、LDAP、Kerberos、Security Assertion Markup Language (SAML)、およびOpenID Connect (OIDC) のいずれかを選択できます。 オプションを構成しない場合、NiFi はクライアント証明書を使用して HTTPS 経由でユーザーを認証します。
多要素認証を検討している場合は、Microsoft Entra ID と OIDC を組み合わせて使用することをお勧めします。 Microsoft Entra ID は、OIDC を使用したクラウドネイティブのシングル サインオン (SSO) をサポートしています。 この組み合わせにより、ユーザーは多くのエンタープライズ セキュリティ機能を利用できます。
- ユーザー アカウントからの疑わしいアクティビティのログ記録とアラート
- 非アクティブ化された資格情報へのアクセス試行の監視
- 異常なアカウントのサインイン動作に関するアラート
NiFi は、承認用にユーザー、グループ、およびアクセス ポリシーに基づく強制を提供します。 NiFi は、UserGroupProviders および AccessPolicyProviders を通じてこの強制を行います。 プロバイダーには既定で、ファイル、LDAP、シェル、およびAzure Graph ベースの UserGroupProvider が含まれます。 AzureGraphUserGroupProvider を使用すると、Microsoft Entra ID からユーザー グループをソース化できます。 その後、これらのグループにポリシーを割り当てることができます。 構成手順については、 「Apache NiFi 管理ガイド」をご覧ください。
ファイルと Apache Ranger に基づくAccessPolicyProviders は現在、ユーザーとグループのポリシー管理と保存に使用できます。 詳細については、Apache NiFi のドキュメントと Apache Ranger のドキュメントをご覧ください。
Application gateway
アプリケーション ゲートウェイは、NiFi インターフェイス用のマネージド レイヤー 7 ロード バランサーを提供します。 NiFi ノードの仮想マシン スケール セットをバックエンド プールとして使用するようにアプリケーション ゲートウェイを構成します。
ほとんどの NiFi インストールでは、次の Application Gateway 構成をお勧めします。
- サービス レベル:Standard
- SKU サイズ: 中
- インスタンス数: 2 つ以上
正常性プローブを使用して、各ノードの Web サーバーの正常性を監視します。 ロード バランサーのローテーションから異常なノードを削除します。 この方法を使用すると、クラスター全体が異常な場合にユーザーインターフェイスを簡単に表示できます。 ブラウザーは、現在正常で要求に応答しているノードにのみユーザーを誘導します。
考慮すべき重要な正常性プローブが 2 つあります。 これらを組み合わせることで、クラスター内にあるすべてのノードの全体的な正常性に定期的なハートビートが提供されます。 パス /NiFi を指すように最初の正常性プローブを構成します。 このプローブは、各ノードの NiFi ユーザー インターフェイスの正常性を判断します。 パス /nifi-api/controller/cluster を指すように 2 番目の正常性プローブを構成します。 このプローブは、各ノードが現在正常であり、クラスター全体に結合されているかどうかを示します。
アプリケーション ゲートウェイのフロントエンド IP アドレスを構成するには、次の 2 つのオプションがあります。
- パブリック IP アドレスを使用する
- プライベート サブネットの IP アドレスを使用する
ユーザーがパブリック インターネット経由で UI にアクセスする必要がある場合にのみ、パブリック IP アドレスを含めます。 ユーザーのパブリック インターネット アクセスが必要ない場合は、仮想ネットワークのジャンプボックスから、またはプライベート ネットワークへのピアリングを介して、ロード バランサーのフロントエンドにアクセスします。 パブリック IP アドレスを使用してアプリケーション ゲートウェイを構成する場合は、NiFi のクライアント証明書認証を有効にし、NiFi UIの TLS を有効にすることをお勧めします。 委任されたアプリケーション ゲートウェイ サブネットのネットワーク セキュリティ グループを使用して、送信元 IP アドレスを制限することもできます。
診断と正常性の監視
Application Gateway の診断設定には、メトリックとアクセス ログを送信するための構成オプションがあります。 このオプションを使用すると、ロード バランサーからさまざまな場所にこの情報を送信できます。
- ストレージ アカウント
- Event Hubs
- Log Analytics ワークスペース
この設定を有効にすると、負荷分散の問題をデバッグしたり、クラスター ノードの正常性を把握したりするのに役立ちます。
次の Log Analytics クエリは、Application Gateway の観点からクラスター ノードの正常性を時系列で示しています。 同様のクエリを使用して、異常なノードのアラートや自動修復アクションを生成できます。
AzureDiagnostics
| summarize UnHealthyNodes = max(unHealthyHostCount_d), HealthyNodes = max(healthyHostCount_d) by bin(TimeGenerated, 5m)
| render timechart
次のクエリ結果のグラフは、クラスターの正常性の時間ビューを示しています。

可用性
このソリューションを実装する場合は、可用性に関する次の点に注意してください。
Load Balancer
UI のロードバランサーを使用して、ノードのダウンタイム中の UI の可用性を向上させます。
個別の VM
可用性を向上させるには、ZooKeeper クラスターを NiFi クラスター内の VM とは別の VM にデプロイします。 ZooKeeper の構成に関する詳細については、「Apache NiFi システム管理者ガイド」の状態管理をご覧ください。
可用性ゾーン
NiFi 仮想マシン スケール セットと ZooKeeper クラスターの両方をクロスゾーン構成でデプロイして、可用性を最大化します。 クラスター内のノード間の通信が可用性ゾーンを超えると、わずかな待機時間が発生します。 ただし、この待機時間は通常、クラスターのスループットに対する全体的な影響を最小限に抑えます。
仮想マシン スケール セット
NiFi ノードを、使用できる可用性ゾーンにまたがる単一の仮想マシン スケール セットにデプロイすることをお勧めします。 この方法でスケール セットを使用する方法の詳細については、「Availability Zones を使用する仮想マシン スケール セットを作成する」をご覧ください。
監視
NiFi クラスターの正常性とパフォーマンスを監視するには、レポート タスクを使用します。
レポート タスクベースの監視
監視には、NiFi で構成および実行するレポート タスクを使用できます。 診断と正常性の監視で説明されているように、Log Analytics は NiFi Azure バンドルにレポート タスクを提供します。 このレポート タスクを使用して、監視を Log Analytics および既存の監視システムまたはログ システムと統合できます。
Log Analytics クエリ
次のセクションのサンプル クエリは、作業を開始するのに役立ちます。 Log Analytics データに対してクエリを実行する方法の概要については、「Azure Monitor ログ クエリ」をご覧ください。
Monitor および Log Analytics のログ クエリは、Kusto 照会言語のバージョンを使用します。 ただし、ログ クエリと Kusto クエリには違いがあります。 詳細については、「Kusto クエリの概要」をご覧ください。
構造化学習の詳細については、次のチュートリアルをご覧ください。
Log Analytics レポート タスク
NiFi は既定で、メトリック データを nifimetrics テーブルに送信します。 ただし、レポート タスクのプロパティで別の変換先を構成することもできます。 レポート タスクは、次の NiFi メトリックをキャプチャします。
| メトリックの種類 | メトリックの名前 |
|---|---|
| NiFi メトリック | FlowFilesReceived |
| NiFi メトリック | FlowFilesSent |
| NiFi メトリック | FlowFilesQueued |
| NiFi メトリック | BytesReceived |
| NiFi メトリック | BytesWritten |
| NiFi メトリック | BytesRead |
| NiFi メトリック | BytesSent |
| NiFi メトリック | BytesQueued |
| ポート状態のメトリック | InputCount |
| ポート状態のメトリック | InputBytes |
| 接続状態のメトリック | QueuedCount |
| 接続状態のメトリック | QueuedBytes |
| ポート状態のメトリック | OutputCount |
| ポート状態のメトリック | OutputBytes |
| Java 仮想マシン (JVM) メトリック | jvm.uptime |
| JVM メトリック | jvm.heap_used |
| JVM メトリック | jvm.heap_usage |
| JVM メトリック | jvm.non_heap_usage |
| JVM メトリック | jvm.thread_states.runnable |
| JVM メトリック | jvm.thread_states.blocked |
| JVM メトリック | jvm.thread_states.timed_waiting |
| JVM メトリック | jvm.thread_states.terminated |
| JVM メトリック | jvm.thread_count |
| JVM メトリック | jvm.daemon_thread_count |
| JVM メトリック | jvm.file_descriptor_usage |
| JVM メトリック | jvm.gc.runs jvm.gc.runs.g1_old_generation jvm.gc.runs.g1_young_generation |
| JVM メトリック | jvm.gc.time jvm.gc.time.g1_young_generation jvm.gc.time.g1_old_generation |
| JVM メトリック | jvm.buff_pool_direct_capacity |
| JVM メトリック | jvm.buff_pool_direct_count |
| JVM メトリック | jvm.buff_pool_direct_mem_used |
| JVM メトリック | jvm.buff_pool_mapped_capacity |
| JVM メトリック | jvm.buff_pool_mapped_count |
| JVM メトリック | jvm.buff_pool_mapped_mem_used |
| JVM メトリック | jvm.mem_pool_code_cache |
| JVM メトリック | jvm.mem_pool_compressed_class_space |
| JVM メトリック | jvm.mem_pool_g1_eden_space |
| JVM メトリック | jvm.mem_pool_g1_old_gen |
| JVM メトリック | jvm.mem_pool_g1_survivor_space |
| JVM メトリック | jvm.mem_pool_metaspace |
| JVM メトリック | jvm.thread_states.new |
| JVM メトリック | jvm.thread_states.waiting |
| プロセッサ レベルのメトリック | BytesRead |
| プロセッサ レベルのメトリック | BytesWritten |
| プロセッサ レベルのメトリック | FlowFilesReceived |
| プロセッサ レベルのメトリック | FlowFilesSent |
クラスターの BytesQueued メトリックのサンプルクエリを次に示します。
let table_name = nifimetrics_CL;
let metric = "BytesQueued";
table_name
| where Name_s == metric
| where Computer contains {ComputerName}
| project TimeGenerated, Computer, ProcessGroupName_s, Count_d, Name_s
| summarize sum(Count_d) by bin(TimeGenerated, 1m), Computer, Name_s
| render timechart
このクエリでは、次のスクリーンショットのようなグラフが生成されます。

注意
Azure で NiFi を実行する場合、Log Analytics レポート タスクに限定されません。 NiFi は、多くのサードパーティ製監視テクノロジのレポート タスクをサポートしています。 サポートされているレポート タスクの一覧については、Apache NiFi ドキュメント インデックスの「レポート タスク」セクションをご覧ください。
NiFi インフラストラクチャの監視
レポート タスクの他に、NiFi ノードと ZooKeeper ノードに Log Analytics VM 拡張機能をインストールします。 この拡張機能は、ログ、追加の VM レベルのメトリック、および ZooKeeper からのメトリックを収集します。
NiFi アプリ、ユーザー、ブートストラップ、ZooKeeper のカスタム ログ
さらに多くのログをキャプチャするには、次の手順に従います。
Azure portal で [Log Analytics ワークスペース] を選択してから、目的のワークスペースを選択します。
[設定] で、[カスタム ログ] を選択します。
![Azure portal の [MyWorkspace] ページのスクリーンショット。 設定とカスタム ログが呼び出されます。](/ja-jp/azure/architecture/example-scenario/data/media/nifi-set-up-custom-log.png)
[カスタム ログの追加] を選択します。
![[カスタム ログの追加] が呼び出された Azure portal の [カスタムログ] ページのスクリーンショット。](/ja-jp/azure/architecture/example-scenario/data/media/nifi-add-custom-log.png)
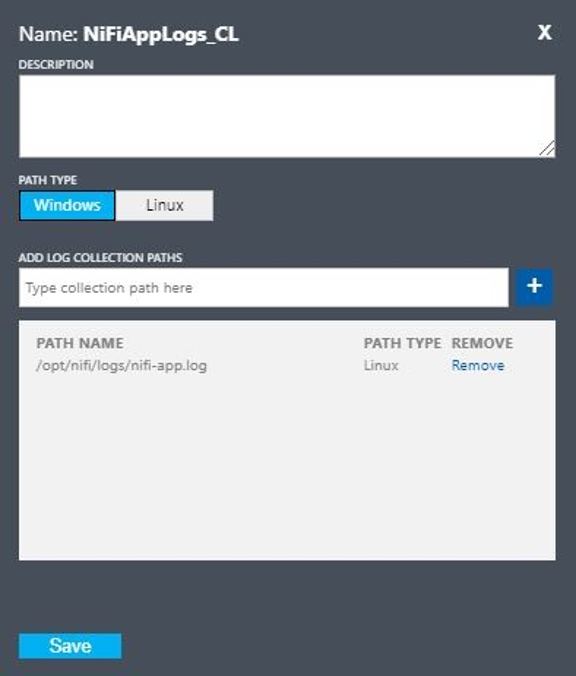
次の値を使用してカスタムログを設定します。
- 名前:
NiFiAppLogs - パスの種類:
Linux - パス名:
/opt/nifi/logs/nifi-app.log
- 名前:
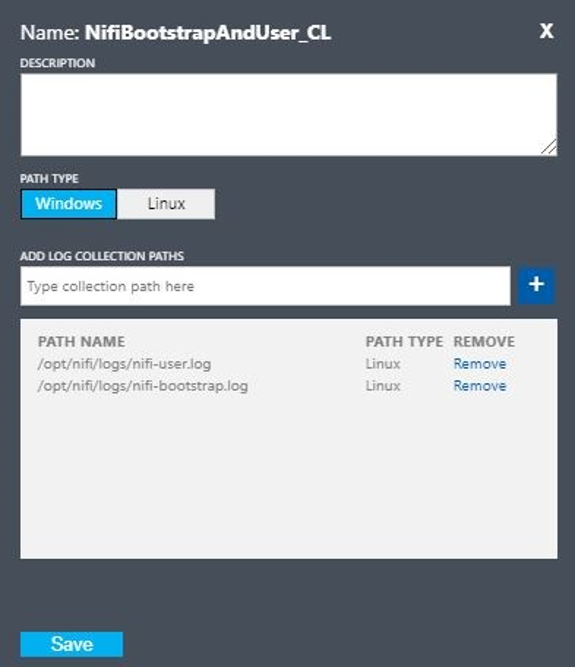
次の値を使用してカスタムログを設定します。
- 名前:
NiFiBootstrapAndUser - 最初のパスの種類:
Linux - 最初のパス名:
/opt/nifi/logs/nifi-user.log - 2 番目のパスの種類:
Linux - 2 番目のパス名:
/opt/nifi/logs/nifi-bootstrap.log
- 名前:
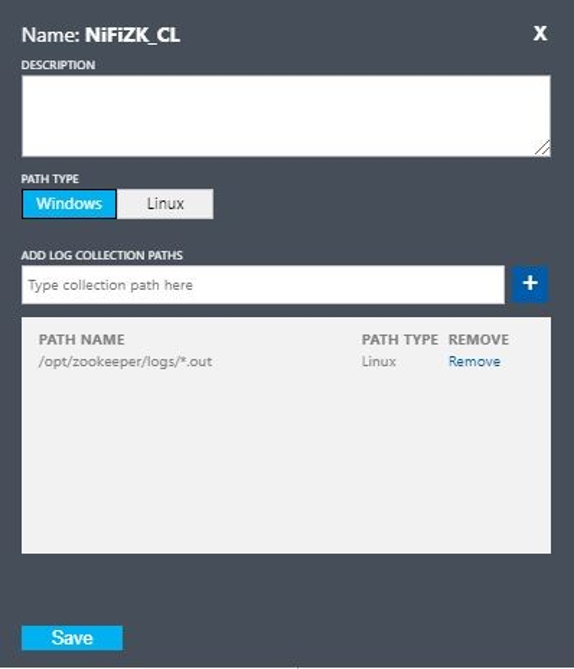
次の値を使用してカスタムログを設定します。
- 名前:
NiFiZK - パスの種類:
Linux - パス名:
/opt/zookeeper/logs/*.out
- 名前:
最初の例で作成された NiFiAppLogs カスタム テーブルのサンプル クエリを次に示します。
NiFiAppLogs_CL
| where TimeGenerated > ago(24h)
| where Computer contains {ComputerName} and RawData contains "error"
| limit 10
このクエリでは、次の結果のような結果が生成されます。

インフラストラクチャ ログの構成
Monitor を使用して、VM または物理コンピューターを監視および管理できます。 これらのリソースは、ローカルのデータセンターや他のクラウド環境に含めることができます。 この監視を設定するには、Log Analytics エージェントをデプロイします。 Log Analytics ワークスペースにレポートするようにエージェントを構成します。 詳細については、「Log Analytics エージェントの概要」を参照してください。
次のスクリーンショットは、NiFi VM のエージェント構成の例を示しています。 この Perf テーブルには、収集されたデータが保存されます。
![[詳細設定] ウィンドウを示すスクリーンショット。 [データと Linux のパフォーマンス カウンター] メニューが強調表示されます。 パフォーマンス カウンターの設定が表示されます。](/ja-jp/azure/architecture/example-scenario/data/media/nifi-linux-performance-counters-data-lightbox.png#lightbox)
NiFi アプリの Perf ログのサンプル クエリを次に示します。
let cluster_name = {ComputerName};
// The hourly average of CPU usage across all computers.
Perf
| where Computer contains {ComputerName}
| where CounterName == "% Processor Time" and InstanceName == "_Total"
| where ObjectName == "Processor"
| summarize CPU_Time_Avg = avg(CounterValue) by bin(TimeGenerated, 30m), Computer
このクエリでは、次のスクリーンショットのようなレポートが生成されます。

警告
モニターを使用して、NiFi クラスターの正常性とパフォーマンスに関するアラートを作成します。 アラートの例を次に示します。
- キューの合計数がしきい値を超えました。
BytesWritten値が予想されるしきい値を下回っています。FlowFilesReceived値がしきい値を下回っています。- クラスターが異常です。
Monitor でアラートを設定する方法の詳細については、「Microsoft Azure でのアラートの概要」をご覧ください。
構成パラメータ
次のセクションでは、NiFi とその依存関係 (ZooKeeper や Java など) で推奨される既定以外の構成について説明します。 これらの設定は、クラウドで可能なクラスターのサイズに適しています。 次の構成ファイルでプロパティを設定します。
$NIFI_HOME/conf/nifi.properties$NIFI_HOME/conf/bootstrap.conf$ZOOKEEPER_HOME/conf/zoo.cfg$ZOOKEEPER_HOME/bin/zkEnv.sh
使用可能な構成プロパティとファイルの詳細については、「Apache NiFi システム管理者ガイド」 および「ZooKeeper 管理者ガイド」をご覧ください。
NiFi
Azure のデプロイでは、$NIFI_HOME/conf/nifi.properties でプロパティを調整することを検討してください。 次の表に、最も重要なプロパティを示します。 その他の推奨事項と分析情報については、「Apache NiFi メーリングリスト」をご覧ください。
| パラメーター | 説明 | Default | 推奨事項 |
|---|---|---|---|
nifi.cluster.node.connection.timeout |
他のクラスター ノードへの接続を開くときの待機時間。 | 5 秒 | 60 秒 |
nifi.cluster.node.read.timeout |
他のクラスター ノードに要求を行うときに応答を待機する時間。 | 5 秒 | 60 秒 |
nifi.cluster.protocol.heartbeat.interval |
ハートビートをクラスター コーディネーターに送り返す頻度。 | 5 秒 | 60 秒 |
nifi.cluster.node.max.concurrent.requests |
他のクラスター ノードへの REST API 呼び出しなどの HTTP 呼び出しをレプリケートするときに使用する並列処理のレベル。 | 100 | 500 |
nifi.cluster.node.protocol.threads |
クラスター間/レプリケートされた通信の初期スレッド プールのサイズ。 | 10 | 50 |
nifi.cluster.node.protocol.max.threads |
クラスター間/レプリケートされた通信に使用するスレッドの最大数。 | 50 | 75 |
nifi.cluster.flow.election.max.candidates |
現在のフローを決定するときに使用するノードの数。 この値は、指定された数の投票をショートサーキットします。 | empty | 75 |
nifi.cluster.flow.election.max.wait.time |
現在のフローを決定する前にノードを待機する時間。 | 5 分 | 5 分 |
クラスターの動作
クラスターを構成するときは、次の点に注意してください。
タイムアウト
ラスターとそのノードの全体的な正常性を確保するために、タイムアウトを増やす方が有益な場合があります。 この方法は、一時的なネットワークの問題や高負荷が原因で障害が発生しないことを保証するのに役立ちます。
分散システムでは、個々のシステムのパフォーマンスが変動します。 この変動には、ネットワーク通信と待機時間が含まれます。これは通常、ノード間通信とクラスター間通信に影響します。 ネットワーク インフラストラクチャまたはシステム自体によって、この変動が発生する可能性があります。 その結果、システムの大規模なクラスターでは、変動の確率が非常に高くなる可能性があります。 負荷がかかっている Java アプリケーションでは、Java 仮想マシン (JVM) のガベージコレクション (GC) の一時停止も、要求の応答時間に影響を与える可能性があります。
システムのニーズに合わせてタイムアウトを構成するには、次のセクションのプロパティを使用します。
nifi.cluster.node.connection.timeout および nifi.cluster.node.read.timeout
nifi.cluster.node.connection.timeout プロパティは、接続を開くときの待機時間を指定します。 nifi.cluster.node.read.timeout プロパティは、要求間でデータを受信するときの待機時間を指定します。 各プロパティの既定値は 5 秒です。 これらのプロパティは、ノード間の要求に適用されます。 これらの値を増やすことで、関連するいくつかの問題を緩和できます。
- ハートビートの中断によりクラスター コーディネーターによって切断されている
- クラスターに結合するときにコーディネーターからフローを取得できない
- サイト間 (S2S) および負荷分散通信の確立
クラスターに 3 ノード以下のような非常に小さなスケール セットがある場合を除き、既定値よりも大きい値を使用します。
nifi.cluster.protocol.heartbeat.interval
NiFi クラスタリング戦略の一環として、各ノードはその正常性状態を伝えるハートビートを送信します。 ノードは既定で、5 秒ごとにハートビートを送信します。 クラスター コーディネーターがノードからの連続した 8 つのハートビートに障害が発生したことを検出すると、ノードは切断されます。 nifi.cluster.protocol.heartbeat.interval プロパティに設定されている間隔を増やして、低速のハートビートに対応し、クラスターがノードを不必要に切断しないようにします。
コンカレンシー
同時実行の設定を構成するには、次のセクションのプロパティを使用します。
nifi.cluster.node.protocol.threads および nifi.cluster.node.protocol.max.threads
nifi.cluster.node.protocol.max.threads プロパティは、S2S 負荷分散や UI 集計などのすべてのクラスター通信に使用するスレッドの最大数を指定します。 このプロパティの既定値は 50 スレッドです。 大規模なクラスターの場合、この値を大きくすると、これらの操作に必要な要求の数が増えます。
nifi.cluster.node.protocol.threads プロパティは、初期スレッド プールのサイズを決定します。 既定値は 10 スレッドです。 この値が最小値です。 必要に応じて、nifi.cluster.node.protocol.max.threads で設定されている最大値まで大きくなります。 起動時に大規模なセットを使用するクラスターの nifi.cluster.node.protocol.threads 値を増やします。
nifi.cluster.node.max.concurrent.requests
REST API 呼び出しや UI 呼び出しなどの多くの HTTP 要求は、クラスター内の他のノードにレプリケートする必要があります。 クラスターのサイズが大きくなると、レプリケートされる要求の数が増えます。 nifi.cluster.node.max.concurrent.requests プロパティは、未処理の要求の数を制限します。 この値は、予想されるクラスター サイズを超える必要があります。 既定値は 100 件の同時要求です。 3 つ以下のノードの小さなクラスターを実行している場合を除き、この値を増やして要求の失敗を防ぎます。
フローの選択
フロー選択設定を構成するには、次のセクションのプロパティを使用します。
nifi.cluster.flow.election.max.candidates
NiFi はゼロリーダー クラスタリングを使用するため、特定の権限のあるノードは 1つもありません。 その結果、ノードはどのフロー定義が正しいものとしてカウントされるかについて投票します。 また、クラスターに参加するノードを決定する投票も行います。
既定では、 nifi.cluster.flow.election.max.candidates プロパティは nifi.cluster.flow.election.max.wait.time プロパティが指定する最大待機時間です。 この値が大きすぎると、起動が遅くなる可能性があります。 nifi.cluster.flow.election.max.wait.time の規定値は 5 分です。 候補の最大数を 1 以上のような空でない値に設定して、待機が必要以上に長くならないようにします。 このプロパティを設定する場合は、クラスター サイズまたは予想されるクラスター サイズの過半数に対応する値を割り当てます。 ノード数が 10 以下の小規模な静的クラスターの場合は、この値をクラスター内のノード数に設定します。
nifi.cluster.flow.election.max.wait.time
柔軟なクラウド環境では、ホストをプロビジョニングする時間がアプリケーションの起動時間に影響します。 nifi.cluster.flow.election.max.wait.time プロパティは、フローを決定する前に NiFi が待機する時間を決定します。 この値を、クラスターの開始サイズでの全体的な起動時間に見合う値にします。 初期テストでは、推奨されるインスタンスの種類を持つすべての Azure リージョンで 5 分で十分です。 ただし、定期的にプロビジョニングする時間が既定値を超える場合は、この値を増やします。
Java
Java の LTS リリースを使用することをお勧めします。 これらのリリースのうち、Java 11 はより高速なガベージ コレクションの実装をサポートしているため、Java 8 よりも Java 11 の方が若干適しています。 ただし、どちらのリリースを使用しても高性能の NiFi をデプロイすることは可能です。
次のセクションでは、NiFi を実行するときに使用する一般的な JVM 構成について説明します。 $NIFI_HOME/conf/bootstrap.conf のブートストラップ構成ファイルで JVM パラメーターを設定します。
ガベージ コレクター
Java 11 を実行している場合は、ほとんどの状況で G1 ガベージ コレクター (G1GC) を使用することをお勧めします。 G1GC は GC の一時停止の長さを短縮するため、ParallelGC よりもパフォーマンスが向上しています。 G1GC は Java 11 の既定値ですが、bootstrap.conf に次の値を設定することで明示的に構成できます。
java.arg.13=-XX:+UseG1GC
Java 8 を実行している場合は、G1GC を使用しないでください。 代わりに ParallelGC を使用してください。 G1GC の Java 8 実装には欠陥があり、推奨されるリポジトリ実装では使用できません。 ParallelGC は G1GC よりも低速です。 ただし、ParallelGC を使用すると、Java 8 で高性能の NiFi をデプロイできます。
ヒープ
bootstrap.conf ファイルにある一連のプロパティによって、NiFi JVM ヒープの構成が決まります。 標準フローの場合は次の設定を使用して 32 GB ヒープを構成します。
java.arg.3=-Xmx32g
java.arg.2=-Xms32g
JVM プロセスに適用する最適なヒープ サイズを選択するには、次の 2 つの要素を考慮してください。
- データ フローの特性
- NiFi が処理でメモリを使用する方法
詳細なドキュメントについては、「Apache NiFi の詳細」をご覧ください。
処理要件を満たすために必要なだけヒープを大きくします。 この方法では、GC の一時停止の長さが最小限に抑えられます。 Java ガベージ コレクションに関する一般的な考慮事項については、Java バージョンのガベージ コレクション チューニング ガイドをご覧ください。
JVM メモリ設定を調整するときは、次の重要な要素を考慮してください。
特定の期間にアクティブな FlowFiles、または NiFi データ レコードの数。 この数には、バック プレッシャーまたはキューに登録済みの FlowFiles が含まれます。
FlowFiles で定義されている属性の数。
プロセッサが特定のコンテンツを処理するために必要なメモリの量。
プロセッサがデータを処理する方法:
- ストリーミング データ
- レコード指向プロセッサの使用
- すべてのデータを一度にメモリに保持する
これらの詳細は重要です。 処理中、NiFi はメモリ内の各 FlowFile の参照と属性を保持します。 ピーク時のパフォーマンスでは、システムが使用するメモリの量は、ライブ FlowFile の数と、それらに含まれるすべての属性に比例します。 の数には、キューに登録済みの FlowFiles が含まれます。 NiFi はディスクにスワップできます。 ただし、このオプションはパフォーマンスを低下させるので避けてください。
また、基本的なオブジェクトのメモリ使用量にも注意してください。 具体的には、オブジェクトをメモリに保持するのに十分な大きさのヒープを作成します。 メモリ設定を構成するには、次のヒントを考慮してください。
- 設定
-Xmx4Gから開始し、必要に応じてメモリを控えめに増やして代表的なデータと最小限のバック プレッシャーでフローを実行します。 - 設定
-Xmx4Gから開始し、必要に応じてクラスター サイズを控えめに増やして代表的なデータとピーク時のバック プレッシャーでフローを実行します。 - VisualVM や YourKit などのツールを使用して、フローの実行中にアプリケーションのプロファイルを作成します。
- ヒープを控えめに増やしてもパフォーマンスが大幅に向上しない場合は、フロー、プロセッサ、およびシステムの他の側面を再設計することを検討してください。
その他の JVM パラメーター
次の表に、その他の JVM オプションを示します。 また、初期テストで最もうまく機能した値も示します。 テストでは GC アクティビティとメモリ使用量を観察し、慎重なプロファイリングを使用しました。
| パラメーター | 説明 | JVM の既定値 | 推奨 |
|---|---|---|---|
InitiatingHeapOccupancyPercent |
マーキング サイクルがトリガーされる前に使用されているヒープの量。 | 45 | 35 |
ParallelGCThreads |
GC が使用するスレッドの数。 この値は、システムへの全体的な影響を制限するために制限されます。 | vCPU 数の 5/8 | 8 |
ConcGCThreads |
並列実行する GC スレッドの数。 この値は、上限のある ParallelGCThreads を考慮して増加します。 | ParallelGCThreads 値の 1/4 |
4 |
G1ReservePercent |
空きメモリを保持する予約メモリの割合。 この値は、スペースの枯渇を回避するために増加され、完全な GC を回避するのに役立ちます。 | 10 | 20 |
UseStringDeduplication |
同一の文字列への参照を識別して重複を削除するかどうかを指定します。 この機能を有効にすると、メモリを節約できます。 | - | present |
NiFi bootstrap.conf に次のエントリを追加して、これらの設定を構成します。
java.arg.17=-XX:+UseStringDeduplication
java.arg.18=-XX:G1ReservePercent=20
java.arg.19=-XX:ParallelGCThreads=8
java.arg.20=-XX:ConcGCThreads=4
java.arg.21=-XX:InitiatingHeapOccupancyPercent=35
ZooKeeper
フォールト トレランスを向上させるには、ZooKeeper をクラスターとして実行します。 ほとんどの NiFi デプロイで ZooKeeper に比較的少ない負荷がかかる場合でも、この方法を使用します。 ZooKeeper のクラスタリングを明示的に有効にします。 既定では、ZooKeeper は単一サーバー モードで実行されます。 詳細については、「ZooKeeper 管理者ガイド」の「クラスター化 (マルチ サーバー) セットアップ」をご覧ください。
クラスタリング設定を除き、ZooKeeper の構成には既定値を使用します。
大規模な NiFi クラスターがある場合は、より多くの ZooKeeper サーバーを使用する必要がある場合があります。 クラスターのサイズが小さい場合は、VM サイズと Standard SSD マネージド ディスクを小さくするだけで十分です。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Muazma Zahid | プリンシパル PM マネージャー
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次のステップ
このドキュメントに記載されている資料と推奨事項は、いくつかのソースからのものです。
- 実験
- Azure のベスト プラクティス
- NiFi コミュニティのナレッジ、ベスト プラクティス、およびドキュメント
詳細については、次のリソースを参照してください。
- Apache NiFi システム管理者ガイド
- Apache NiFi メーリングリスト
- 高パフォーマンス NiFi インストールを設定するための Cloudera のベスト プラクティス
- Azure Premium Storage: ハイ パフォーマンス用に設計する
- Linux または Windows での Azure 仮想マシンのパフォーマンスのトラブルシューティング