ソリューションのアイデア
この記事ではソリューションのアイデアについて説明します。 クラウド アーキテクトはこのガイダンスを使用すると、このアーキテクチャの一般的な実装の主要コンポーネントを視覚化しやすくなります。 ワークロードの特定の要件に適合する、適切に設計されたソリューションを設計するための出発点として、この記事を使用してください。
Azure でカスタム自然言語処理 (NLP) ソリューションを実装します。 トピックやセンチメントの検出や分析などのタスクで Spark NLP を使用します。
Apache®、Apache Spark、および炎のロゴは、Apache Software Foundation の米国およびその他の国における登録商標です。 これらのマークを使用することが、Apache Software Foundation による保証を意味するものではありません。
アーキテクチャ

このアーキテクチャの Visio ファイルをダウンロードします。
ワークフロー
- Azure Event Hubs、Azure Data Factory、またはその両方のサービスが、ドキュメントまたは非構造化テキスト データを受け取ります。
- Event Hubs と Data Factory により、Azure Data Lake Storage にファイル形式でデータが格納されます。 ビジネス要件に準拠するディレクトリ構造を設定することをお勧めします。
- Azure Computer Vision API が、光学式文字認識 (OCR) 機能を使用してデータを処理します。 その後、API によって、ブロンズ レイヤーにデータが書き込まれます。 この処理プラットフォームでは、レイクハウス アーキテクチャを使用します。
- ブロンズ レイヤーで、さまざまな Spark NLP 機能によってテキストが前処理されます。 たとえば、分割、スペル修正、クリーニング、文法の理解などです。 ブロンズ レイヤーでドキュメント分類を実行してから、結果をシルバー レイヤーに書き込むことをお勧めします。
- シルバー レイヤーでは、高度な Spark NLP 機能によって、名前付きエンティティ認識、要約、情報取得などのドキュメント分析タスクが実行されます。 一部のアーキテクチャでは、結果はゴールド レイヤーに書き込まれます。
- ゴールド レイヤーでは、Spark NLP はテキスト データに対してさまざまな言語ビジュアル分析を実行します。 これらの分析は、言語の依存関係に関する分析情報を提供し、NER ラベルの視覚化に役立ちます。
- ユーザーは、ゴールド レイヤーのテキスト データをデータ フレームとして照会し、Power BI または Web アプリで結果を表示します。
処理中に、Azure Databricks、Azure Synapse Analytics、Azure HDInsight が Spark NLP と共に使用され、NLP 機能が提供されます。
Components
- Data Lake Storage は、統合された階層型名前空間と、Azure Blob Storage の巨大な規模と経済性を備えた Hadoop 互換のファイル システムです。
- Azure Synapse Analytics は、データ ウェアハウスおよびビッグ データ システム用の分析サービスです。
- Azure Databricks は、簡単に使用できて共同作業を容易にする、Apache Spark に基づくビッグ データ用の分析サービスです。 Azure Databricks は、データ サイエンスと Data Engineering 向けに設計されています。
- Event Hubs は、クライアント アプリケーションが生成するデータ ストリームを取り込みます。 Event Hubs はストリーミング データを格納し、受信したイベントのシーケンスを保持します。 コンシューマーはハブ エンドポイントに接続して、処理するメッセージを取得できます。 このソリューションが示すように、Event Hubs は Data Lake Storage と統合されます。
- Azure HDInsight は、全範囲に対応した、クラウドでのオープンソースの企業向けマネージド分析サービスです。 Hadoop、Apache Spark、Apache Hive、LLAP、Apache Kafka、Apache Storm、R などのオープンソース フレームワークを Azure HDInsight と共に使用できます。
- Data Factory は、異なるセキュリティ レベルのストレージ アカウント間でデータを自動的に移動し、職務を確実に分離します。
- Computer Vision ではテキスト認識 API を使用して、画像内のテキスト認識し、その情報を抽出します。 Read API では、最新の認識モデルが使用されおり、大規模でテキスト量の多いドキュメントとノイズの多い画像用に最適化されています。 OCR API は大きなドキュメント用に最適化されていませんが、Read API よりも多くの言語をサポートしています。 このソリューションでは、OCR を使用して hOCR 形式のデータを生成します。
シナリオの詳細
自然言語処理 (NLP) には、感情分析、トピック検出、言語検出、キー フレーズ抽出、ドキュメント分類などの多くの用途があります。
Apache Spark は、NLP などのビッグ データ分析アプリケーションのパフォーマンスを向上させるメモリ内処理をサポートする並列処理フレームワークです。 Azure Synapse Analytics、Azure HDInsight、Azure Databricks は Spark へのアクセスを提供し、その処理能力を活用します。
カスタマイズされた NLP ワークロードの場合、オープンソース ライブラリ Spark NLP は、大量のテキストを処理するための効率的なフレームワークとして機能します。 この記事では、Azure での大規模なカスタム NLP のソリューションについて説明します。 このソリューションでは、Spark NLP の機能を使用してテキストを処理および分析します。 Spark NLP の詳細については、この記事で後述する「Spark NLP の機能とパイプライン」を参照してください。
考えられるユース ケース
ドキュメント分類: Spark NLP には、テキスト分類のいくつかのオプションが用意されています。
- Spark NLP でのテキスト前処理と Spark MLに基づく機械学習アルゴリズム
- Spark NLP でのテキストの前処理と単語埋め込みおよび GloVe、BERT、ELMo などの機械学習アルゴリズム
- Spark NLP でのテキストの前処理と文の埋め込みおよび Universal Sentence Encoder などの機械学習アルゴリズムとモデル
- ClassifierDL アノテーターを使用し、TensorFlow に基づく Spark NLP でのテキストの前処理と分類
名前エンティティ抽出 (NER): Spark NLP では、数行のコードを使用して、BERT を使用する NER モデルをトレーニングし、最先端の精度を実現できます。 NER は、情報抽出のサブタスクです。 NER は、非構造化テキスト内の名前付きエンティティを検出し、人物名、組織、場所、医療コード、時間表現、数量、通貨値、パーセンテージなどの定義済みのカテゴリに分類します。 Spark NLP では、BERT を使用した最先端の NER モデルが使用されます。 このモデルは、以前の NER モデルである双方向 LSTM-CNN から着想を得たモデルです。 以前のモデルでは、単語レベルと文字レベルの特徴を自動的に検出する新しいニューラル ネットワーク アーキテクチャが使用されています。 この目的のために、このモデルではハイブリッドの双方向 LSTM と CNN アーキテクチャが使用されるため、ほとんどの特徴エンジニアリングが不要になります。
センチメントと感情の検出: Spark NLP は、言語の肯定的、否定的、中立的な側面を自動的に検出できます。
品詞 (POS): この機能は、入力テキスト内の各トークンに文法ラベルを割り当てます。
文検出 (SD): SD は、テキスト内の文を識別する文境界検出のための汎用ニューラル ネットワーク モデルに基づいています。 多くの NLP タスクは、入力単位として文を受け取ります。 これらのタスクの例としては、POS のタグ付け、依存関係の解析、名前付きエンティティ認識、機械翻訳などがあります。
Spark NLP の機能とパイプライン
Spark NLP には、spaCy、NLTK、Stanford CoreNLP、Open NLP などの従来の NLP ライブラリの完全な機能を提供する Python、Java、Scala のライブラリが用意されています。 Spark NLP には、スペル チェック、センチメント分析、ドキュメント分類などの機能もあります。 Spark NLP は、最新の精度、速度、スケーラビリティを提供することで、以前の取り組みを改善します。
Spark NLP は、圧倒的に高速なオープンソース NLP ライブラリです。 最近のパブリック ベンチマークでは、Spark NLP が spaCy の 38 倍および 80 倍速く、カスタム モデルのトレーニングに対して同等の精度を持つことが示されています。 Spark NLP は、分散 Spark クラスターを使用できる唯一のオープンソース ライブラリです。 Spark NLP は、データ フレーム上で直接動作する Spark ML のネイティブ拡張機能です。 その結果、クラスターの高速化により、パフォーマンスが大幅に向上します。 すべての Spark NLP パイプラインは Spark ML パイプラインであるため、Spark NLP は、ドキュメント分類、リスク予測、レコメンダー パイプラインなどの NLP と機械学習を統合したパイプラインの構築に適しています。
Spark NLP は、優れたパフォーマンスに加え、増え続ける NLP タスクに対して最新の精度も提供します。 Spark NLP チームは、関連する最新の学術論文を定期的に読み、最も正確なモデルを生成しています。
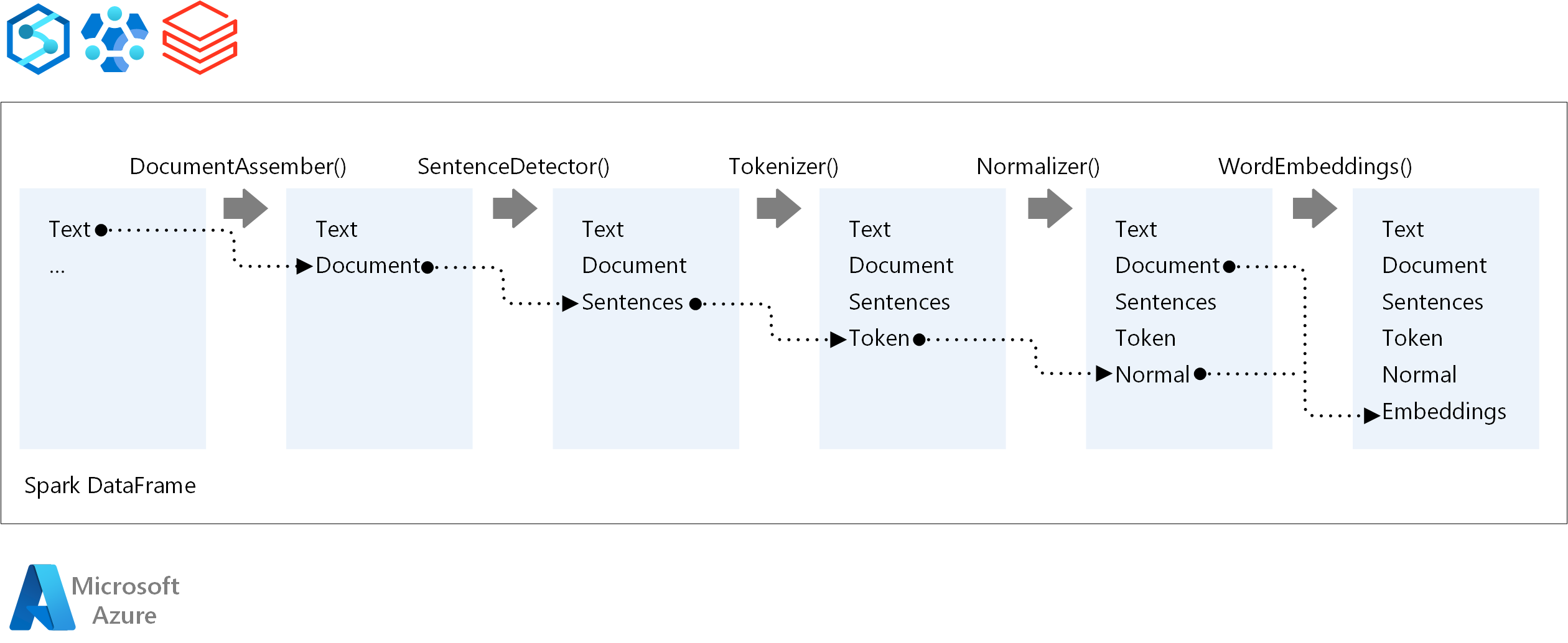
NLP パイプラインの実行順序について、Spark NLP では従来の Spark 機械学習モデルと同じ開発概念に従います。 ただし、Spark NLP には NLP 手法が適用されます。 次の図は、Spark NLP パイプラインのコア コンポーネントを示しています。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Moritz Steller | シニア クラウド ソリューション アーキテクト
次のステップ
Spark NLP のドキュメント
Azure コンポーネント: