Azure Monitor の自動スケーリングのトラブルシューティング
Azure Monitor 自動スケーリングを使用すると、適切な量のリソースを実行して、アプリケーションに対する負荷を処理する際に役立ちます。 リソースを追加して負荷の増加に対処したり、アイドル状態のリソースを削除して経費を節約したりできます。 スケジュール、特定の日時、または選択したリソース メトリックに基づいてスケールできます。 詳細については、自動スケールの概要に関するページを参照してください。
自動スケーリング サービスは、発生したスケール アクションと、それらのアクションを引き起こした条件の評価を理解するのに役立つ、メトリックとログを提供します。 次のような質問に対する回答を見つけることができます。
- サービスがスケールアウトまたはスケールインした理由
- サービスがスケールされていない理由
- 自動スケーリングが失敗する理由
- 自動スケーリング アクションによってスケーリングするのに時間がかかる理由
Flex Virtual Machine Scale Sets
自動スケーリングのスケーリング アクションは、特定の仮想マシン操作セットの Flex Microsoft.Compute/virtualMachineScaleSets (VMSS) リソースに手動スケーリング アクションが適用された後、最大で数時間遅延します。
たとえば、操作が個々の VM に対して実行される Azure VM CLI Delete や Azure VM Rest API Delete などがあります。
このような場合、自動スケーリング サービスは個々の VM 操作を認識しません。
このシナリオを回避するには、同じ操作を仮想マシン スケール セット レベルで使用します。 たとえば、Azure VMSS CLI Delete instance、または Azure VMSS Rest API Delete Instance などです。 自動スケーリングは、仮想マシン スケール セット内のインスタンス数の変更を検出し、適切なスケーリング アクションを実行します。
自動スケーリング メトリック
自動スケーリングでは、操作を理解するための 4 つのメトリックが提供されます。
- [Observed Metric Value](実際のメトリック値): スケール アクションを実行するために選択したメトリックの値。自動スケーリング エンジンによって表示または計算されます。 1 つの自動スケーリング設定に複数のルールを設定できるため、"メトリック ソース" をディメンションとして使用して、複数のメトリック ソースをフィルター処理できます。
- [Metric Threshold](メトリックのしきい値): スケール アクションを実行するために設定するしきい値。 1 つの自動スケーリング設定に複数のルールを設定できるため、"メトリック ルール" をディメンションとして使用して、複数のメトリック ソースをフィルター処理できます。
- [Observed Capacity](実際の容量): 自動スケーリング エンジンから見たターゲット リソースのアクティブなインスタンス数。
- 開始されたスケール アクション: 自動スケーリング エンジンによって開始されたスケールアウトおよびスケールイン アクションの数。 スケールアウトとスケールイン アクションでフィルター処理できます。
メトリックス エクスプローラー を使用すると、上記のメトリックをすべて 1 か所でグラフ化できます。 グラフには次が表示されます。
- 実際のメトリック。
- 自動スケーリング エンジンから見た/計算されたメトリック。
- スケール アクションのしきい値。
- 容量の変更。
例 1: 自動スケーリング ルールを分析する
仮想マシン スケール セットの自動スケーリング設定:
- セットの平均 CPU 使用率が 10 分間 70% を超えたときにスケールアウトする。
- セットの CPU 使用率が 10 分以上 5 % 未満のときにスケールインする。
自動スケーリング サービスのメトリックを確認してみましょう。
次のグラフは、仮想マシン スケール セットの [CPU 使用率] メトリックを示しています。

次のグラフは、自動スケーリング設定の [Observed Metric Value](実際のメトリック値) メトリックを示しています。

最後のグラフは、[Metric Threshold](メトリックのしきい値) と [Observed Capacity](実際の容量) メトリックを示しています。 スケールアウト ルールの上部にある [Metric Threshold](メトリックのしきい値) メトリックは 70 です。 [Observed Capacity](実際の容量) メトリックは、アクティブなインスタンスの数 (現在は 3) を示しています。
 と [Observed Capacity](実際の容量) を示すスクリーンショット。](media/autoscale-troubleshoot/autoscale-metric-threshold-capacity-ex-full.png#lightbox)
注意
スケールアウトのしきい値を確認するには、メトリック トリガー ルール ディメンションのスケールアウト (増加) ルールと、スケールイン ルール (減少) で [Metric Threshold](メトリックのしきい値) をフィルター処理できます。
例 2: 仮想マシン スケール セットの高度な自動スケーリング
自動スケーリング設定により、仮想マシン スケール セットのリソースが、独自の送信フローメトリックに基づいてスケールアウトすることができます。 メトリックのしきい値に対する [Divide metric by instance count](メトリックをインスタンス数で割る) オプションが選択されています。
スケール アクション ルールでは、[Outbound Flow per instance](インスタンスごとの送信フロー) が10 を超える場合、自動スケーリング サービスは 1 インスタンスずつスケールアウトする必要があります。
この場合、自動スケーリング エンジンの実際のメトリック値は、インスタンスの数で割った実際のメトリック値として計算されます。 実際のメトリック値がしきい値未満の場合、スケールアウト アクションは開始されません。
次のスクリーンショットは、2 つのメトリック グラフを示しています。
[Avg Outbound Flows](平均送信フロー) グラフには、[送信フロー] メトリックの値が表示されます。 実際の値は 6 です。
 ページで、仮想マシン スケール セットの自動スケーリング メトリック グラフの例を示すスクリーンショット。](media/autoscale-troubleshoot/autoscale-vmss-metric-chart-ex-1.png#lightbox)
次のグラフは、いくつかの値を示しています。
- 中央の [Observed Metric Value](実際のメトリック値) メトリックは 3 です。これは、アクティブなインスタンスが 2 つあり、6 を 2 で割った数が 3 であるためです。
- 下部の [Observed Capacity](実際の容量) メトリックは、自動スケーリング エンジンによって検出されたインスタンス数を示します。
- 上部の [メトリックのしきい値] メトリックは 10 に設定されています。
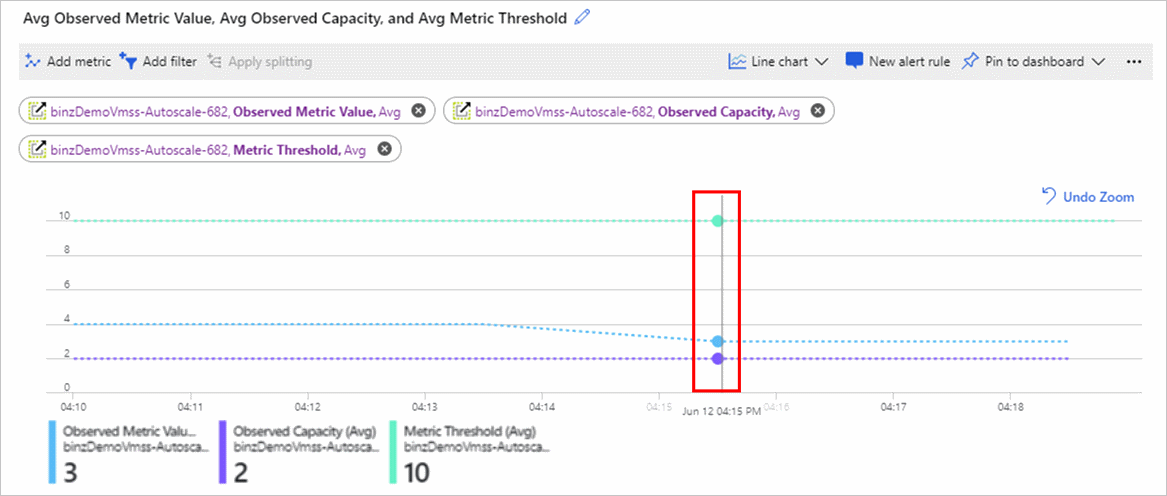

複数のスケール アクション ルールがある場合は、分割を使用するか、メトリックス エクスプローラー グラフの [フィルターを追加する] オプションを選択して、特定のソースまたはルールでメトリックを確認できます。 メトリック グラフの分割の詳細については、メトリック グラフの高度な機能 - 分割に関する記事を参照してください。
例 3: 自動スケーリング イベントを理解する
自動スケーリングの設定画面で、 [実行履歴] タブにアクセスして、最新のスケール アクションを確認します。 また、このタブには実際の容量が時系列で示されます。 自動スケーリング設定の更新や削除などの操作を含む、すべての自動スケーリング アクションに関する情報を確認するには、アクティビティ ログを表示し、自動スケーリング アクションでフィルター処理します。

自動スケーリングのリソース ログ
自動スケーリング サービスでは、リソース ログが提供されます。 ログには次の 2 つのカテゴリがあります。
- 自動スケーリング評価: 自動スケーリング エンジンでは、チェックを行うたびに、単一の条件評価ごとにログ エントリが記録されます。 エントリには、メトリックの実際の値、評価されたルール、評価の結果がスケール アクションであったかどうかに関する詳細が含まれます。
- 自動スケーリング アクション: エンジンは、自動スケーリング サービスによって開始されるスケール アクション イベントと、スケール アクションの結果 (成功、失敗、および自動スケーリング サービスから見たスケーリングの数) を記録します。
サポートされている Azure Monitor サービスと同様に、診断設定を使用して、これらのログを次の場所にルーティングできます。
- 詳細な分析用の Log Analytics ワークスペース。
- Azure Event Hubs。その後 Azure 以外のツールへ。
- アーカイブ用の Azure Storage アカウント。

上記のスクリーンショットは、Azure portal の自動スケーリングの [Diagnostics settings](診断設定) ペイン示しています。 ここで、[Diagnostic Logs](診断ログ) または [Resource Logs](リソース ログ) タブを選択し、ログの収集とルーティングを有効にすることができます。 また、REST API、Azure CLI、PowerShell、Azure Resource Manager テンプレートを使用して診断設定を行うこともできます。これを行うには、リソースの種類として [Microsoft Insights/AutoscaleSettings] を選択します。
自動スケーリング ログを使用したトラブルシューティング
最適なトラブルシューティングを行うには、自動スケーリング設定を作成するときに、ワークスペースを使用して Azure Monitor ログ (Log Analytics) にログをルーティングすることをお勧めします。 このプロセスについては、前のセクションのスクリーンショットを参照してください。 Log Analytics を使用すると、評価とスケーリング アクションをより適切に検証できます。
Log Analytics ワークスペースに送信されるように自動スケーリング ログを構成したら、次のクエリを実行してログを確認できます。
開始するには、次のクエリを実行して、最新の自動スケーリング評価ログを表示します。
AutoscaleEvaluationsLog
| limit 50
または、次のクエリを実行して、最新のスケール アクション ログを表示します。
AutoscaleScaleActionsLog
| limit 50
これらの質問の回答については、次のセクションを参照してください。
予期していなかったスケール アクションが発生した
まず、スケール アクションのクエリを実行して、目的のスケール アクションを見つけます。 最新のスケール アクションの場合は、次のクエリを使用します。
AutoscaleScaleActionsLog
| take 1
スケール アクション ログから CorrelationId フィールドを選択します。 正しい評価ログを検索するには、CorrelationId を使用します。 次のクエリを実行すると、評価され、そのスケール アクションにつながったすべてのルールと条件が表示されます。
AutoscaleEvaluationsLog
| where CorrelationId = "<correliationId>"
スケール アクションの原因となったプロファイルは何か
スケーリングされたアクションが発生しましたが、ルールとプロファイルが重複しており、このアクションの原因となったものを追跡する必要があります。
例 1 で説明したように、スケール アクションの CorrelationId を見つけます。 次に、評価ログに対してクエリを実行し、プロファイルの詳細を確認します。
AutoscaleEvaluationsLog
| where CorrelationId = "<correliationId_Guid>"
| where ProfileSelected == true
| project ProfileEvaluationTime, Profile, ProfileSelected, EvaluationResult
次のクエリを使用して、プロファイル全体の評価をより適切に理解することもできます。
AutoscaleEvaluationsLog
| where TimeGenerated > ago(2h)
| where OperationName contains == "profileEvaluation"
| project OperationName, Profile, ProfileEvaluationTime, ProfileSelected, EvaluationResult
スケール アクションが発生しませんでした
スケール アクションを想定していましたが、発生しませんでした。 スケール アクション イベントまたはログがない可能性があります。
メトリック ベースのスケール ルールを使用している場合は、自動スケーリング メトリックを確認します。 [Observed Metric](実際のメトリック) 値または [Observed Capacity](実際の容量) 値が想定したものではないため、スケール ルールが起動されなかった可能性があります。 評価は引き続き表示されますが、スケールアウト ルールは表示されません。 また、クールダウン時間によりスケール アクションが実行されなかった可能性もあります。
スケール アクションが発生すると想定された期間の自動スケーリングの評価ログを確認します。 実行したすべての評価と、スケール アクションがトリガーされなかった理由を確認します。
AutoscaleEvaluationsLog
| where TimeGenerated > ago(2h)
| where OperationName == "MetricEvaluation" or OperationName == "ScaleRuleEvaluation"
| project OperationName, MetricData, ObservedValue, Threshold, EstimateScaleResult
スケール アクションに失敗しました
自動スケーリング サービスではスケール アクションが実行されましたが、システムによりスケーリングが中止されたか、スケーリング アクションの完了に失敗した可能性があります。 このクエリを使用して、失敗したスケール アクションを検索します。
AutoscaleScaleActionsLog
| where ResultType == "Failed"
| project ResultDescription
アラート ルールを作成して、自動スケーリングのアクションまたはエラーが通知されるようにします。 アラート ルールを作成して、自動スケーリング イベントについて通知を受け取ることもできます。
自動スケーリングのリソース ログのスキーマ
詳細については、自動スケーリングのリソース ログに関するページを参照してください。
次のステップ
自動スケーリングのベストプラクティスに関する情報を参照してください。