チュートリアル: Azure Monitor で KQL 機械学習機能を使用して異常を検出して分析する
Kusto 照会言語 (KQL) には、時系列分析、異常検出、予測、根本原因分析のための機械学習演算子、関数、プラグインが含まれています。 これらの KQL 機能を使用して、外部の機械学習ツールにデータをエクスポートするオーバーヘッドなしで Azure Monitor で高度なデータ分析を実行します。
このチュートリアルでは、以下の内容を学習します。
- 時系列を作成する
- 時系列の異常を特定する
- 異常検出設定を調整して結果を絞り込む
- 異常の根本原因を分析する
Note
このチュートリアルでは、KQL クエリの例を実行できる Log Analytics デモ環境へのリンクを提供します。 デモ環境のデータは動的であるため、クエリ結果は、この記事に示されているクエリ結果と同じではありません。 ただし、独自の環境と、KQL を使用するすべての Azure Monitor ツールに、同じ KQL クエリとプリンシパルを実装できます。
前提条件
- アクティブなサブスクリプションが含まれる Azure アカウント。 無料でアカウントを作成できます。
- ログ データを含むワークスペース。
必要なアクセス許可
クエリを実行する Log Analytics ワークスペースに対し、Microsoft.OperationalInsights/workspaces/query/*/read アクセス許可が必要です。これは、たとえば、Log Analytics 閲覧者組み込みロールによって提供されます。
時系列を作成する
KQL make-series 演算子を使用して時系列を作成します。
Usage テーブルのログに基づいて時系列を作成しましょう。これには、ワークスペース内の各テーブルが 1 時間ごとに取り込むデータの量に関する情報 (課金対象データや課金対象外データなど) が含まれます。
このクエリでは、make-series を使用して、過去 21 日間にワークスペース内の各テーブルによって毎日取り込まれた課金対象データの合計量がグラフ化されます。
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
結果のグラフでは、AzureDiagnostics と SecurityEvent のデータ型など、いくつかの異常を明確に確認できます。
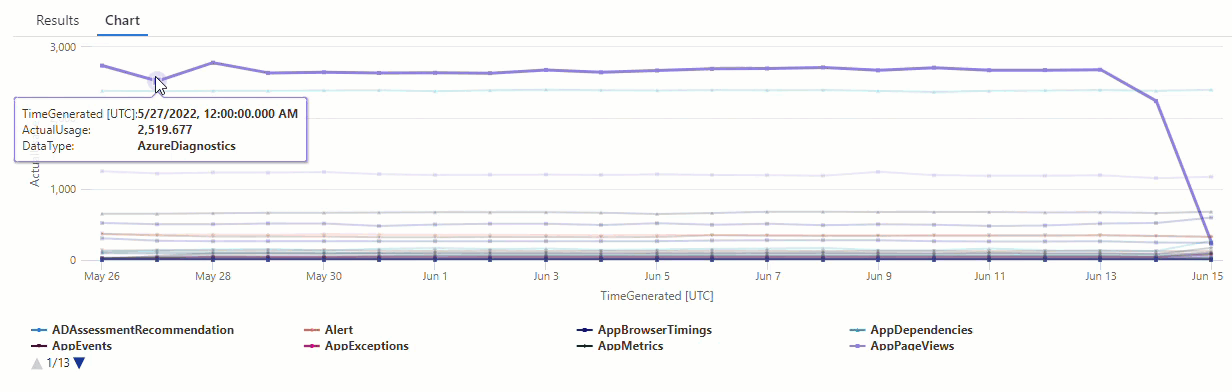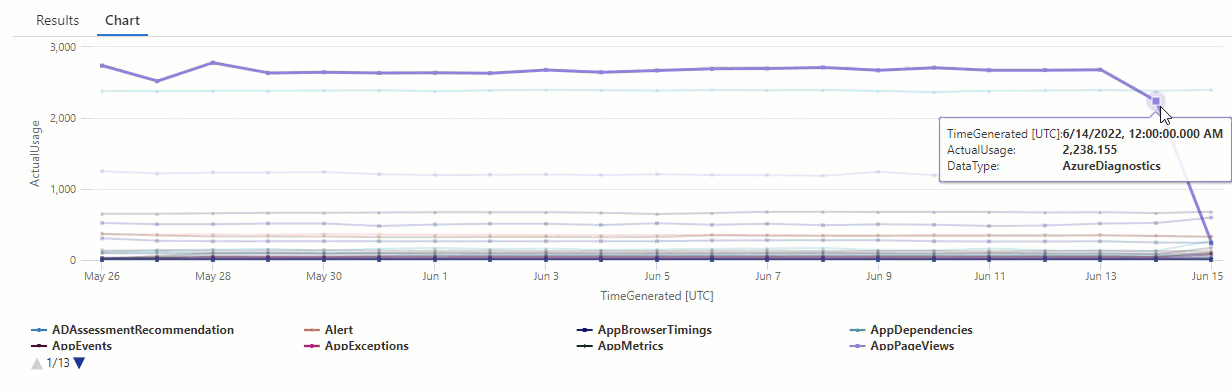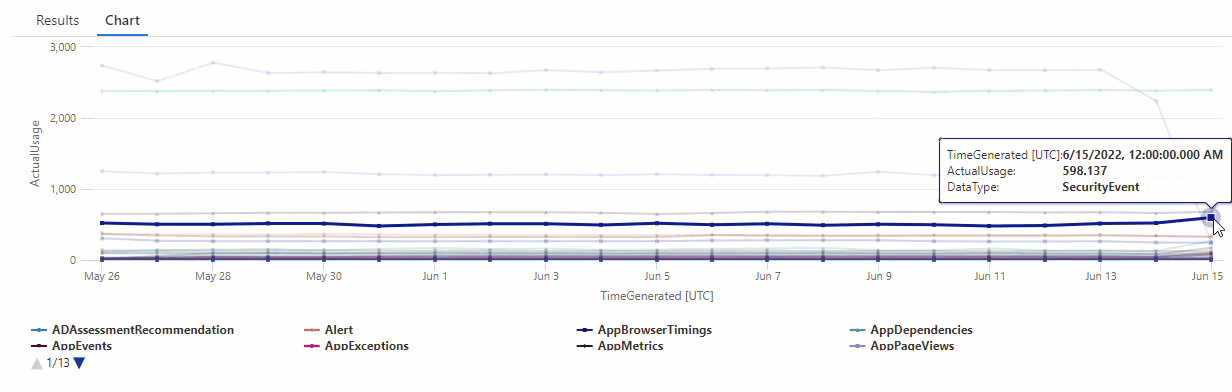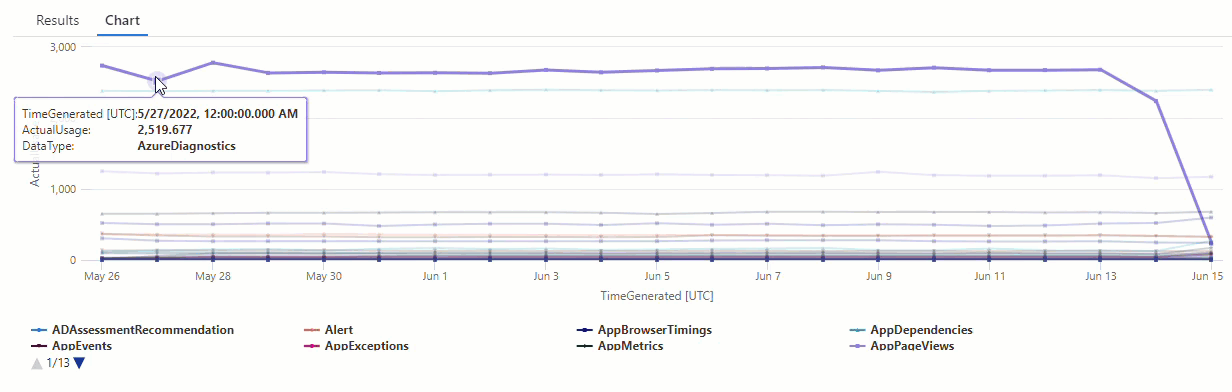
次に、KQL 関数を使用して、時系列のすべての異常を一覧表示します。
Note
make-series 構文と使用方法の詳細については、「make-series 演算子」を参照してください。
時系列の異常を見つける
series_decompose_anomalies() 関数では、一連の値を入力として受け取り、異常を抽出します。
時系列クエリの結果セットを series_decompose_anomalies() 関数への入力として指定しましょう。
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
このクエリでは、過去 3 週間のすべてのテーブルのすべての使用状況の異常を返します。

クエリ結果を見ると、関数が次のように機能していることが分かります。
- 各テーブルの予想される毎日の使用量を計算する。
- 実際の毎日の使用量と予想される使用量を比較する。
- 各データ ポイントに異常スコアを割り当て、予想される使用量からの実際の使用量の偏差の程度を示す。
- 各テーブルの正 (
1) と負 (-1) の異常を識別する。
Note
series_decompose_anomalies() 構文と使用方法の詳細については、「series_decompose_anomalies()」を参照してください。
異常検出設定を調整して結果を絞り込む
最初のクエリ結果を確認し、必要に応じてクエリを調整することをお勧めします。 入力データの外れ値は関数の学習に影響を与える可能性があり、より正確な結果を得るには関数の異常検出設定の調整が必要になる場合があります。
AzureDiagnostics データ型の異常について series_decompose_anomalies() クエリの結果をフィルター処理します。

結果は、6 月 14 日と 6 月 15 日の 2 つの異常を示しています。 これらの結果を最初の make-series クエリのグラフと比較すると、他にも 5 月 27 日と 28 日に異常を確認できます。

結果の違いは、series_decompose_anomalies() 関数が入力系列の値の全範囲に基づいて算出する使用量の期待値を基準として異常をスコア付けするために発生します。
関数からより正確な結果を得るには、6 月 15 日の使用量 (系列内の他の値との比較による外れ値) を関数の学習プロセスから除外します。
series_decompose_anomalies() 関数の構文は次のとおりです。
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points では、学習 (回帰) プロセスから除外する系列の末尾にあるポイントの数を指定します。
最後のデータ ポイントを除外するには、Test_points を 1 に設定します。
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
AzureDiagnostics データ型の結果をフィルター処理します。

最初の make-series クエリによるグラフのすべての異常が、結果セットに表示されるようになりました。
異常の根本原因を分析する
期待値と異常値を比較すると、2 つのセットの差の原因を理解するのに役立ちます。
KQL の diffpatterns() プラグインでは、構造が同じ 2 つのデータ セットを比較して、2 つのデータ セット間の差異を特徴づけるパターンを検出します。
このクエリでは、この例の極端な外れ値である 6 月 15 日の AzureDiagnostics の使用量と、他の日のテーブルの使用量を比較します。
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
クエリでは、テーブル内の各エントリが AnomalyDate (6 月 15 日) または OtherDates で発生しているものとして識別されています。 その後、diffpatterns() プラグインでは、これらの A (この例では OtherDates) と B (この例では AnomalyDate) というデータ セットを分割し、2 つのセットの差に寄与するいくつかのパターンを返します。

クエリ結果を見ると、次の違いを確認できます。
- クエリの時間範囲内の他のすべての日に CH1-GEARAMAAKS リソースからのインジェストのインスタンスは 24,892,147 個あり、6 月 15 日にこのリソースからのデータ インジェストはありません。 CH1-GEARAMAAKS リソースからのデータは、クエリの時間範囲内の他の日の合計インジェストの 73.36% を占め、6 月 15 日の合計インジェストの 0% を占めています。
- クエリの時間範囲内の他のすべての日に NSG-TESTSQLMI519 リソースからのインジェストのインスタンスは 2,168,448 個あり、6 月 15 日にこのリソースからのインジェストのインスタンスは 110,544 個あります。 NSG-TESTSQLMI519 リソースからのデータは、クエリの時間範囲内の他の日の合計インジェストの 6.39% を占め、6 月 15 日のインジェストの 25.61% を占めています。
平均して、NSG-TESTSQLMI519 リソースからのインジェストのインスタンスは、他の日の期間を構成する 20 日間に 108,422 個あることに注目してください (2,168,448 を 20 で除算)。 そのため、6 月 15 日の NSG-TESTSQLMI519 リソースからのインジェストは、他の日のこのリソースからのインジェストと大きく異なります。 ただし、6 月 15 日に CH1-GEARAMAAKS からのインジェストがないため、NSG-TESTSQLMI519 からのインジェストによって、異常のある日の合計インジェストの割合が、他の日と比較して大幅に大きくなります。
PercentDiffAB 列には、A と B の間の絶対パーセント ポイントの差 (|PercentA - PercentB|) が表示されます。これは、2 つのセットの差の主要な基準です。 既定では、diffpatterns() プラグインは 2 つのデータ セット間で 5% を超える差を返しますが、このしきい値を調整することができます。 たとえば、2 つのデータ セット間で 20% 以上の差のみを返すには、上記のクエリで | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) を設定できます。 クエリから返される結果は 1 つだけになりました。

Note
diffpatterns() 構文と使用方法の詳細については、「diff patterns プラグイン」を参照してください。
次のステップ
各項目の詳細情報