アクティブな地理的レプリケーション
適用対象: ![]() Azure SQL データベース
Azure SQL データベース
この記事では、プライマリ データベースから読み取り可能なセカンダリ データベースにデータを継続的に複製できる Azure SQL データベースのアクティブ geo レプリケーション機能の概要について説明します。 読み取り可能なセカンダリ データベースは、プライマリと同じ Azure リージョンにあっても、別のリージョン (こちらの方が一般的) にあってもかまいません。 この種の読み取り可能セカンダリ データベースは、"geo セカンダリ" または "geo レプリカ" と呼ばれることもあります。
データベースごとにアクティブ geo レプリケーションが構成されています。 データベースのグループをフェールオーバーする場合、またはアプリケーションで安定した接続エンドポイントが必要な場合は、代わりにフェールオーバー グループを検討してください。
アクティブ geo レプリケーションで SQL Database を移行することもできます。
概要
アクティブ geo レプリケーションは、ビジネス継続性ソリューションとして設計されています。 アクティブ geo レプリケーションにより、地域的な災害や大規模な障害が発生した場合でも、個々のデータベースを迅速にディザスター リカバリーすることができます。 Geo レプリケーションを設定したら、別の Azure リージョンの geo セカンダリへの geo フェールオーバーを開始できます。 Geo フェールオーバーは、アプリケーションによってプログラムで、またはユーザーが手動で開始します。
次の図に、アクティブ geo レプリケーションを使用して行われる geo 冗長クラウド アプリケーションの一般的な構成を示します。
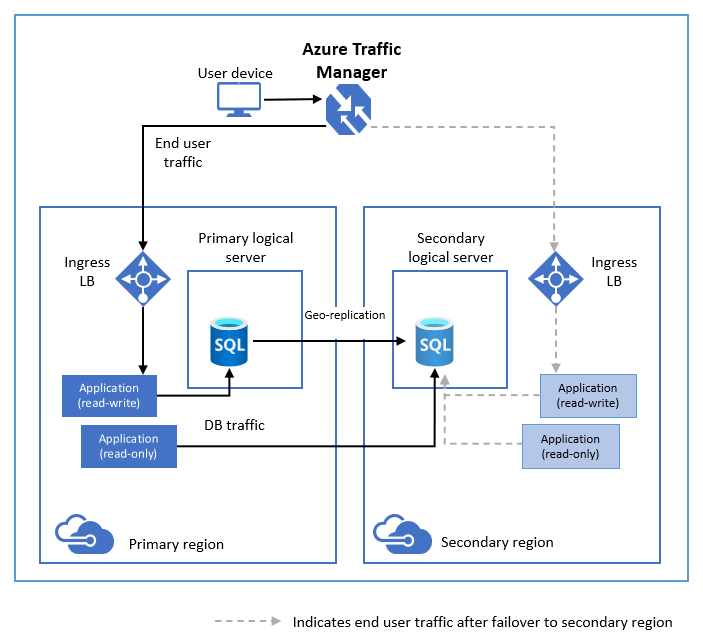
何らかの理由でプライマリ データベースが失敗した場合は、任意のセカンダリ データベースに geo フェールオーバーを開始できます。 セカンダリがプライマリ ロールに昇格すると、他のすべてのセカンダリが新しいプライマリに自動的にリンクされます。
Geo レプリケーションを管理し、以下を使用して geo フェールオーバーを開始できます。
- Azure Portal
- PowerShell: 単一データベース
- PowerShell: エラスティック プール
- Transact-SQL:単一のデータベースまたはエラスティック プール
- REST API: 単一データベース
アクティブ geo レプリケーションでは、Always On 可用性グループ テクノロジを利用して、プライマリ レプリカで生成されたトランザクション ログをすべての geo レプリカに非同期的にレプリケートします。 特定の時点におけるセカンダリ データベースは、プライマリ データベースよりもわずかに古い可能性がありますが、セカンダリ上のデータはトランザクション上の一貫性が保証されます。 つまり、コミットされていないトランザクションによって行われた変更は表示されません。
Note
アクティブ geo レプリケーションでは、プライマリ レプリカからセカンダリ レプリカにデータベース トランザクション ログをストリーミングすることで、変更がレプリケートされます。 これは、サブスクライバー上でDML (INSERT、UPDATE、DELETE) コマンドを実行して変更をレプリケートするトランザクション レプリケーションとは無関係です。
geo レプリケーションは、リージョンの冗長性を提供します。 Geo レプリケーションで提供されるリージョン間の冗長性のため、自然災害、致命的なヒューマンエラー、または悪意のある行為によって Azure リージョン全体またはリージョンの一部が完全に失われた場合でも、アプリをすばやく復元できます。 Geo レプリケーション RPO については、「Azure SQL Database によるビジネス継続性の概要」を参照してください。
次の図は、プライマリが米国西部 2 リージョン、geo セカンダリが米国東部リージョンに構成されたアクティブ geo レプリケーションの例を示しています。

アクティブ geo レプリケーションは、ディザスター リカバリーに加えて次のシナリオで使用できます。
- データベースの移行: アクティブ geo レプリケーションを使用して、最小限のダウンタイムでデータベースをあるサーバーから別のサーバーに移行できます。
- アプリケーションのアップグレード: アプリケーションのアップグレード時に、セカンダリをフェールバック コピーとして余分に作成することができます。
完全なビジネス継続性を実現するために、データベースのリージョンの冗長性を追加することは、ソリューションの一部でしかありません。 致命的な障害の後にアプリケーション (サービス) をエンド ツー エンドで復旧するには、そのサービスと依存しているサービスを構成するすべてのコンポーネントを復旧する必要があります。 このようなコンポーネントの例には、クライアント ソフトウェア (カスタム JavaScript が設定されたブラウザーなど)、Web フロント エンド、ストレージ、DNS などがあります。 すべてのコンポーネントが同じ障害に耐性を持ち、アプリの復元時間目標(RTO)内で利用可能になることが重要です。 そのため、依存するサービスをすべて特定し、これらのサービスが提供する保証と機能について把握しておく必要があります。 そのうえで、依存するサービスのフェールオーバー中もサービスが確実に機能するように対策を講じる必要があります。 ディザスター リカバリー用のソリューション設計の詳細については、「Azure SQL Database を使用して世界規模の可用性を備えたサービスを設計する」を参照してください。
用語と機能
自動非同期レプリケーション
作成できるのは、既存のデータベースの geo セカンダリのみです。 Geo セカンダリは、プライマリ データベースを持つサーバー以外の任意の論理サーバーに作成できます。 作成されると、geo セカンダリ レプリカにプライマリ データベースのデータが設定されます。 このプロセスはシード処理と呼ばれます。 Geo セカンダリ データベースが作成およびシードされた後、プライマリ データベースの更新が geo セカンダリ データベースに非同期で自動的にレプリケートされます。 非同期レプリケーションとは、トランザクションがレプリケートされる前にプライマリデータベース上でコミットされることを意味します。
読み取り可能なセカンダリ レプリカ
アプリケーションは、プライマリ データベースへのアクセスに使用されているのと同じ、または異なるセキュリティ プリンシパルを使用して、geo セカンダリ レプリカにアクセスして読み取り専用クエリを実行できます。 詳細については、「読み取り専用レプリカを使用して読み取り専用クエリ ワークロードをオフロードする」を参照してください。
重要
Geo レプリケーションを使用して、同じリージョンにプライマリとしてセカンダリレプリカを作成できます。 これらのセカンダリを使用して、同じリージョンの読み取りスケールアウト シナリオを満たします。 ただし、同じリージョン内のセカンダリ レプリカは、致命的な障害や大規模な停止に対する更なる回復力を提供しないため、ディザスター リカバリーの目的に適したフェールオーバー ターゲットではありません。 また、可用性ゾーンの分離も保証されません。 ゾーン冗長の構成で Business Critical または Premium サービス レベルを使用するか、General Purpose サービス レベルのゾーン冗長の構成を使用して、可用性ゾーンの分離を行ってください。
フェールオーバー (データ損失なし)
フェールオーバーでは、完全なデータ同期が完了した後、プライマリと geo セカンダリ データベースのロールが切り替わるためデータ損失はありません。 フェールオーバーの期間は、geo セカンダリに同期する必要があるプライマリのトランザクション ログのサイズによって異なります。 フェールオーバーは、次のシナリオ用に設計されています。
- データ損失が許容されない場合は、運用環境で DR ドリルを行います。
- データベースを別のリージョンに再配置します
- 機能停止が軽減 (フェールバックとして知られています) された後、データベースをプライマリ リージョンに返します
強制フェールオーバー (データ損失の可能性)
強制フェールオーバーは、プライマリとの同期を待たずに、geoセカンダリをプライマリの役割に即座に切り替えます。 プライマリにコミットされていても、セカンダリにレプリケートされていないトランザクションは失われます。 この操作は、プライマリにアクセスできない停止時の復元方法として設計されていますが、データベースの可用性を迅速に復元する必要があります。 元のプライマリがオンラインに戻ると、自動的に再接続され、プライマリからの現在のデータを使用して再シードされ、新しいジオ・セカンダリになります。
重要
フェールオーバーまたは強制 フェールオーバーの後、新しいプライマリの接続エンドポイントが変更されます。これは、新しいプライマリが別の論理サーバーに位置されているからです。
複数のセカンダリ geo データベース
プライマリに対して最大 4 つの geo セカンダリを作成できます。 セカンダリが 1 つしか存在しない場合に障害が発生すると、新しいセカンダリ が作成されるまで、アプリケーションは高いリスクにさらされます。 セカンダリ が複数存在する場合、セカンダリ のいずれかに障害が発生しても、アプリケーションは保護された状態が維持されます。 読み取り専用のワークロードをスケール アウトするために、追加のセカンダリを使用することもできます。
ヒント
グローバルに分散されたアプリケーションの構築にアクティブ geo レプリケーションを使用し、4 つを超えるリージョンにデータへの読み取り専用アクセスを提供する必要がある場合は、セカンダリのセカンダリ (チェーンと呼ばれるプロセス) を作成し、追加の geo レプリカを作成できます。 チェーンされた geo レプリカでのレプリケーションのラグは、プライマリに直接接続されている geo レプリカよりも高くなる可能性があります。 チェーン geo レプリケーション トポロジの設定は、プログラムによってのみサポートされており、Azure portal からはサポートされていません。
エラスティック プール内のデータベースの geo レプリケーション
セカンダリ データベースは、Single Database またはエラスティック プールのデータベースにできます。 Geo セカンダリ データベースごとにエラスティック プールの選択は独立しており、トポロジ内の他のレプリカ (プライマリまたはセカンダリ) の構成には依存しません。 各エラスティック プールは、1 つの論理サーバー内に含まれます。 論理サーバー上のデータベース名は一意である必要があるため、同じプライマリの複数の geo セカンダリがエラスティック プールを共有できません。
ユーザー制御の geo フェールオーバーとフェールバック
初期シード処理が完了した geo セカンダリは、アプリケーションまたはユーザーがいつでもプライマリ ロールに明示的に切り替え (フェールオーバー) できます。 プライマリにアクセスできない停止中には、強制フェールオーバーのみを使用することができ、ジオセカンダリを直ちに新しいプライマリに昇格させます。 停止が軽減された場合、システムは自動的に復旧されたプライマリを geo セカンダリにし、新しいプライマリで最新の状態に戻します。 geo レプリケーションの非同期の性質上、これらのトランザクションが geo セカンダリにレプリケートされる前にプライマリが失敗した場合、計画外の 地域フェールオーバー中に最近のトランザクションが失われる可能性があります。 複数の geo セカンダリを持つプライマリがフェールオーバーすると、システムは自動的にレプリケーション関係を再構成して、いかなるユーザー介入も必要とすることなく、残りの geo セカンダリを新しく昇格されたプライマリにリンクします。 geo フェールオーバーの原因となった障害が軽減された後、プライマリを元のリージョンに復帰させることが望ましい場合があります。 そのためには、手動フェールオーバーを実行してください。
スタンバイ レプリカ
セカンダリ レプリカがディザスター リカバリー (DR) にのみ使用され、読み取りまたは書き込みのワークロードがない場合は、レプリカをスタンバイとして指定してライセンス コストを節約できます。
Geo フェールオーバーの準備
geo フェールオーバー後にアプリケーションが新しいプライマリにすぐアクセスできることが確実になるよう、セカンダリ サーバーの認証とネットワークが正しく構成されていることを確認してください。 詳細については、「Azure SQL Database のセキュリティを geo リストアやフェールオーバー用に構成し、管理する」を参照してください。 また、セカンダリデータベースのバックアップ保持ポリシーがプライマリのバックアップ保持ポリシーと一致していることを確認します。 この設定はデータベースの一部ではなく、プライマリからはレプリケートされません。 既定では、geo セカンダリは 7 日間の既定の PITR 保持期間で構成されます。 詳細については、「Azure SQL データベースの自動バックアップ」を参照してください。
重要
ご使用のデータベースがフェールオーバー グループのメンバーである場合、geo レプリケーション フェールオーバー コマンドを使用してそのフェールオーバーを開始することはできません。 グループのフェールオーバー コマンドを使用してください。 個々のデータベースをフェールオーバーする必要がある場合、最初にそれをフェールオーバー グループから削除する必要があります。 詳細については、フェールオーバー グループに関する記事をご覧ください。
Geo セカンダリの構成
プライマリと geo セカンダリの両方が同じサービス レベルを持つ必要があります。 また、geoセカンダリは、プライマリと同じバックアップストレージの冗長性、コンピューティングレベル (プロビジョニング済みまたはサーバーレス) 、コンピューティングサイズ (DTUまたは仮想コア) で設定することを強くお勧めします。 プライマリで書き込みワークロードの負荷が高くなっている場合、コンピューティング サイズがより小さな geo セカンダリは維持できない可能性があります。 これにより、geo セカンダリでレプリケーションが発生し、最終的に geo セカンダリが利用できなくなる可能性があります。 このようなリスクを軽減するために、アクティブ geo レプリケーションは、必要に応じてプライマリのトランザクション ログ速度を減少 (スロットル) してセカンダリが追い付けるようにします。
バランスがとれていない geo セカンダリ構成の他の影響として、フェールオーバーの後、新しいプライマリのコンピューティング容量の不足のためにアプリケーションのパフォーマンスが低下する可能性があることが挙げられます。 その場合は、データベースが十分なリソースを確保するために拡張する必要があります。これには膨大な時間がかかる可能性があり、スケールアップ プロセスの最後には高可用性フェールオーバーが必要となり、アプリケーションのワークロードが中断される可能性があります。
別の設定でgeo-secondaryを作成する場合は、プライマリのログIOレートを長期的に監視する必要があります。 これにより、レプリケーションの負荷を維持するために必要な geo セカンダリの最小コンピューティングサイズを見積もることができます。 たとえば、プライマリ データベースが P6 (1000 DTU) で、ログ IO が 50% で維持されている場合、geo セカンダリは P4 (500 DTU) 以上である必要があります。 履歴ログ IO データを取得するには、sys.resource_stats ビューを使用します。 短期間の急増を詳細に反映した最新のログ IO データを取得するには、sys.dm_db_resource_stats ビューを使用します。
ヒント
トランザクション ログの IO 調整が発生する可能性があります。
- geo セカンダリのコンピューティング サイズがプライマリよりも小さい場合。 sys.dm_exec_requests と sys.dm_os_wait_stats のデータベース ビューで HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO の待機タイプを探します。
- コンピューティング サイズとは関係しない理由。 さまざまな種類のログ IO スロットリングの待機の種類などの詳細については、「トランザクション ログ速度ガバナンス」を参照してください。
既定では、geo セカンダリのバックアップ ストレージの冗長性は、プライマリ データベースのものと同じです。 別のバックアップ ストレージの冗長性を使用して geo セカンダリを構成することもできます。 バックアップは、常にプライマリ データベースで実行されます。 セカンダリが異なるバックアップ ストレージの冗長性で構成されている場合、geo セカンダリがプライマリに昇格されたときの geo フェールオーバー後に、新しいプライマリ (前のセカンダリ) で選択されたストレージの種類に従って (RA-GRS, ZRS, LRS)、バックアップが保存され、課金されます。
スタンバイ レプリカを使用してコストを節約する
セカンダリ レプリカがディザスター リカバリー (DR) にのみ使用され、読み取りまたは書き込みワークロードがない場合は、新しいアクティブ geo レプリケーションリレーションシップを構成するときにデータベースをスタンバイに指定することで、ライセンス コストを節約できます。
詳細については、ライセンスフリー スタンバイ レプリカに関する説明を参照してください。
サブスクリプション間 geo レプリケーション
両方のサブスクリプションが同じ Microsoft Entra テナントにある限り、Azure Portal を使用してサブスクリプション間でアクティブ geo レプリケーションを設定できます。
- 別の Microsoft Entra テナントにあるプライマリのサブスクリプションとは異なるサブスクリプションで geo セカンダリ レプリカを作成するには、SQL 認証 と T-SQL を使用します。 論理サーバーが別の Azure テナントにある場合、サブスクリプション間 geo レプリケーションの Microsoft Entra 認証 はサポートされません。
- セットアップと geo フェールオーバーを含むサブスクリプション間 geo レプリケーション操作は、データベース作成または更新 REST API を使用するときもサポートされます。
プライマリまたはセカンダリの論理サーバー上のいずれかで Microsoft Entra ID 専用の認証が有効になり、Microsoft Entra ID ユーザーを使用して作成を試みた場合、同じまたは別の Microsoft Entra テナントの論理サーバーでサブスクリプション間 geo セカンダリの作成はサポートされません。
方法と段階に分けた手順については、「チュートリアル: アクティブ geo レプリケーションとフェールオーバーの構成 (Azure SQL データベース)」を参照してください。
プライベート エンドポイント
T-SQL を使用した geo セカンダリの追加は、プライベート エンドポイント経由でプライマリ サーバーに接続するときはサポートされません。
- プライベート エンドポイントが構成されているが、パブリック ネットワーク アクセスが許可される場合、パブリック IP アドレスからプライマリ サーバーに接続するときに geo セカンダリの追加がサポートされます。
- geo セカンダリを追加すると、パブリック ネットワーク アクセスを拒否できます。
資格情報とファイアウォール規則の同期を保つ
データベースへの接続にパブリックネットワークアクセスを使用する場合は、geo レプリケートされたデータベースに対してデータベースレベルの IP ファイアウォール規則を使用することをお勧めします。 これらのルールはデータベースと共にレプリケートされます。これにより、すべての geo セカンダリがプライマリと同じ IP ファイアウォールルールを持つようになります。 このアプローチにより、プライマリとセカンダリ データベースをホストするサーバー上で、顧客がファイアウォール規則を手動で構成、管理する必要性がなくなります。 同様に、データアクセスに包含データベースユーザーを使用すると、プライマリデータベースとセカンダリデータベースの両方に同じ認証資格情報が常に割り当てられます。 これにより、geo フェールオーバー後に、認証資格情報の不一致による中断は発生しません。 包含ユーザーではなくログインとユーザーを使用している場合は、追加の手順を実行して、セカンダリ データベースに同じログインが存在することを確認する必要があります。 構成の詳細については、「Azure SQL Database のセキュリティを geo リストアやフェールオーバー用に構成し、管理する」を参照してください。
プライマリデータベースのスケーリング
Geo セカンダリを切断せずに、プライマリデータベースを (同じサービスレベル内の) 別のコンピューティングサイズにスケールアップまたはスケールダウンすることができます。 スケールアップするときは、まず geo セカンダリをスケールアップしてから、プライマリをスケールアップすることをお勧めします。 スケールダウンする場合は、順序を逆にします。最初にプライマリをスケールダウンし、次にセカンダリをスケールダウンします。
フェールオーバー グループの詳細については、「フェールオーバー グループでレプリカのスケーリング」を確認してください。
重要なデータが失われないようにする
ワイドエリアネットワークの待機時間が長いため、geo レプリケーションは非同期レプリケーションメカニズムを使用します。 非同期レプリケーションを使用すると、プライマリに障害が発生した場合にデータ損失が回避される可能性があります。 重要なトランザクションをデータ損失から保護するために、アプリケーション開発者はトランザクションをコミットした直後に sp_wait_for_database_copy_sync ストアドプロシージャを呼び出すことができます。 sp_wait_for_database_copy_sync を呼び出すと、最後にコミットされたトランザクションが転送され、セカンダリデータベースのトランザクションログに書き込まれるまで、呼び出し元のスレッドがブロックされます。 ただし、転送されたトランザクションがセカンダリで再生 (再実行) されるのを待つことはありません。 sp_wait_for_database_copy_sync は、特定の geo レプリケーションリンクにスコープが設定されています。 プライマリ データベースへの接続権限を持つユーザーが、このプロシージャを呼び出すことができます。
Note
sp_wait_for_database_copy_sync は、特定のトランザクションの geo フェールオーバー後のデータ損失を防ぎますが、読み取りアクセスの完全同期は保証しません。 プロシージャ呼び出しによって発生する遅延は sp_wait_for_database_copy_sync 大きくなる可能性があり、呼び出し時のプライマリでまだ転送されていないトランザクションログのサイズによって異なります。
geo レプリケーションのラグの監視
RPO に関する遅延を監視するには、プライマリ データベースの sys.dm_geo_replication_link_status の replication_lag_sec 列を使用します。 プライマリでコミットされたトランザクション間の遅延が秒単位で表示され、セカンダリのトランザクションログに書き込まれます。 たとえば、ラグが 1 秒の場合は、プライマリが停止によって影響を受け、geo フェールオーバーが開始されると、最後の 1 秒間にコミットされたトランザクションは失われます。
セカンダリに書き込み済みのプライマリ データベースに対する変更に関する遅延を測定するには、geo セカンダリの last_commit 時間をプライマリの同じ値と比較します。
ヒント
プライマリの replication_lag_sec が NULL になっていることがありますが、これは、現時点でプライマリと geo セカンダリとの間の遅延時間が不明であることを意味します。 これは、プロセスが再起動した後に発生する一時的な状態であることがほとんどです。 replication_lag_sec から長時間にわたって NULL が返される場合は、アラートを送ることを検討してください。 接続エラーが原因で、geo セカンダリがプライマリと通信できないことを示す場合があります。
Geo セカンダリとプライマリ間の last_commit 時間に大きな差が生じる可能性のある状況は他にもあります。 例えば、長時間変更がなかったプライマリでコミットが行われた場合、差異は非常に大きくなりますが、すぐにゼロに戻ります。 この2つの値の差が長時間続く場合は、アラートを送信することを検討してください。
アクティブ geo レプリケーションのプログラムでの管理
アクティブ geo レプリケーションは、T-SQL、Azure PowerShell、REST API を使用してプログラムで管理することもできます。 次の表では、使用できるコマンド セットについて説明します。 アクティブ geo レプリケーションには、管理のための Azure Resource Manager API 一式 (Azure SQL Database REST API、Azure PowerShell コマンドレットなど) が含まれています。 こうした API は、Azure ロールベースのアクセス制御 (Azure RBAC) をサポートします。 アクセス ロールの実装方法の詳細については、Azure のロール ベースのアクセス制御 (Azure RBAC) に関するページをご覧ください。
重要
これらの T-SQL コマンドは、アクティブ geo レプリケーションにのみ適用され、フェールオーバー グループには適用されません。
| command | 説明 |
|---|---|
| ALTER DATABASE | ADD SECONDARY ON SERVER 引数を使用して、既存のデータベースのセカンダリ データベースを作成し、データ レプリケーションを開始します。 |
| ALTER DATABASE | FAILOVER または FORCE_FAILOVER_ALLOW_DATA_LOSS を使用して、セカンダリ データベースをプライマリに切り替え、フェールオーバーを開始します |
| ALTER DATABASE | REMOVE SECONDARY ON SERVER を使用して、SQL Database と指定されたセカンダリ データベース間でのデータ レプリケーションを終了します。 |
| sys.geo_replication_links | サーバー上の各データベースの、既存のレプリケーション リンクの情報をすべて返します。 |
| sys.dm_geo_replication_link_status | 最新のレプリケーション時刻、最後のレプリケーションの遅延、および指定されたデータベースのレプリケーション リンクに関する他の情報を取得します。 |
| sys.dm_operation_status | レプリケーション リンクの変更を含むすべてのデータベース操作の状態が表示されます。 |
| sys.sp_wait_for_database_copy_sync | コミットされたすべてのトランザクションが、geo セカンダリのトランザクションログに書き込まれるまで待機します。 |
関連するコンテンツ
アクティブ geo レプリケーションの構成
その他のビジネス継続性コンテンツ