Azure SQL Managed Instance でデータベースのファイル領域を管理する
適用対象: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
この記事では、Azure SQL Managed Instance のデータベース内のファイルを監視および管理する方法について説明します。 データベース ファイルサイズの監視、トランザクション ログの圧縮、トランザクション ログ ファイルの拡張、およびトランザクション ログ ファイルの書き込み制御方法を確認します。
この記事は、Azure SQL Managed Instance には適用されません。 よく似ていますが、SQL Server でのトランザクション ログ ファイルのサイズの管理については、「トランザクション ログ ファイルのサイズの管理」を参照してください。
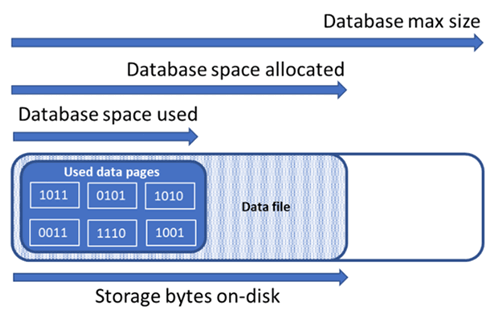
データベースの記憶域スペースの種類を理解する
データベースのファイル領域を管理するには、以下に示す記憶域スペースの量について理解することが重要です。
| データベースの量 | 定義 | 説明 |
|---|---|---|
| 使用済みのデータ領域 | データベース データを格納するために使用された領域の量。 | 一般的に、使用済みの領域は挿入 (削除) で増加 (減少) します。 操作に関連するデータの量とパターン、および断片化によっては、挿入または削除時に使用される領域が変わらない場合があります。 たとえば、各データ ページから 1 行を削除しても、使用される領域が減らない場合があります。 |
| 割り当て済みのデータ領域 | データベース データの格納に使用できるフォーマット済みファイル領域の量。 | 割り当て済みの領域の量は自動的に増えますが、削除後に自動的に減ることはありません。 このような動作で領域を再フォーマットする必要がないため、以降の挿入はより高速になります。 |
| 割り当て済みで未使用のデータ領域 | 割り当て済みのデータ領域と使用済みのデータ領域の差。 | この量は、データベースのデータ ファイルを縮小して再利用できる空き領域の上限を表します。 |
| データの最大サイズ | データベース データの格納に使用できる領域の最大量。 | データの最大サイズを超えて割り当て済みのデータ領域を拡大することはできません。 |
次の図は、データベースの異なる種類の記憶域スペース間の関係を示しています。
ファイル領域の情報について単一データベースのクエリを実行する
sys.database_files に次のクエリを使用して、割り当て済みデータベース ファイル領域と未使用の割り当て済み領域を返します。 クエリ結果の単位は MB です。
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
ログ領域の使用量の監視
sys.dm_db_log_space_usage を利用し、ログ領域の使用量を監視します。 この DMV は、現在使用されているログ領域の量に関する情報を返し、いつトランザクション ログを切り捨てる必要があるかを示します。
ログ ファイルの現在のサイズ、最大サイズ、およびファイルの自動拡張オプションについては、sys.database_files にある、そのログ ファイルに関する size、max_size、growth の各列も使用できます。
Azure Resource Manager ベースのメトリック API に表示される記憶領域メトリックは、使用されるデータ ページのサイズのみを測定します。 例については、PowerShell get-metrics に関する記事を参照してください。
ログ ファイルのサイズを圧縮する
未使用の領域を削除して物理ログ ファイルの物理サイズを減らすには、ログ ファイルを圧縮する必要があります。 圧縮では、トランザクション ログ ファイルに未使用の領域が含まれている場合にのみ誤差が生じます。 未処理のトランザクションが原因でログ ファイルがいっぱいになっている場合は、トランザクション ログの切り捨てを妨げている原因を調査してください。
注意事項
圧縮操作は、通常のメンテナンス操作と見なすことはできません。 通常の定期的なビジネス操作のために増加するデータ ファイルとログ ファイルには、圧縮操作は必要ではありません。 縮小コマンドは、実行中のデータベース パフォーマンスに影響を及ぼすため、可能であれば、使用率が低い期間中に実行してください。 通常のアプリケーション ワークロードによってファイルが同じ割り当て済みサイズまで再度増える場合は、データ ファイルを圧縮することはお勧めしません。
データベース ファイルの圧縮によってパフォーマンスが悪影響を受けるおそれがあることに注意してください。「圧縮後のインデックスのメンテナンス」を参照してください。 まれに、圧縮操作が自動データベース バックアップの影響を受ける場合があります。 必要に応じて、圧縮操作を再試行してください。
トランザクション ログを圧縮する前に、ログの切り捨てが遅れる原因となる要因に留意してください。 ログの圧縮後、ストレージ領域が再び必要になると、トランザクション ログが再び増え、その分のパフォーマンスのオーバーヘッドが発生します。 詳細については、「推奨事項」を参照してください。
ログ ファイルの圧縮を実行できるのは、データベースがオンラインで、1 つ以上の仮想ログ ファイル (VLF) が解放されている間だけです。 場合によっては、次のログの切り詰める後までにログを圧縮できない可能性があります。
実行期間の長いトランザクションなどの要因があると、長期間にわたってVLF がアクティブなままになったり、ログの圧縮が制限されたり、ログがまったく圧縮できなかったりすることがあります。 詳細については、「ログの切り捨てが遅れる原因となる要因」を参照してください。
ログ ファイルを圧縮すると、論理ログのどの部分も保持しない 1 つまたは複数の VLF (つまり、非アクティブな VLF) が削除されます。 トランザクション ログ ファイルを圧縮すると、ログ ファイルが目的のサイズにできるだけ近いサイズに縮小されるように、非アクティブな VLF がログ ファイルの末尾から削除されます。
圧縮操作の詳細については、以下を参照してください。
データベース ファイルを圧縮せずにログ ファイルを圧縮する
ログ ファイルの圧縮イベントを監視する
ログ領域の監視
sys.database_files (Transact-SQL) (ログ ファイルの
size、max_size、growth列を参照してください。)
圧縮後のインデックスのメンテナンス
データ ファイルに対する圧縮操作が完了すると、インデックスが断片化される可能性があります。 これにより、大規模なスキャンを使用したクエリなど、特定のワークロードではパフォーマンス最適化の有効性が低下します。 圧縮操作の完了後にパフォーマンスが低下する場合は、インデックスを再構築するためのインデックスのメンテナンスを検討してください。 インデックスの再構築にはデータベースの空き領域が必要であるため、割り当てられた領域が増えて、圧縮の効果を弱める可能性があることを覚えておいてください。
インデックスのメンテナンスの詳細については、「クエリのパフォーマンスを向上させてリソースの消費を削減するためにインデックスのメンテナンスを最適化する」を参照してください。
インデックス ページの密度を評価する
データ ファイルを切り詰めても割り当てられた領域が十分に減らなかった場合、データベースのデータ ファイルを圧縮し、それらのファイルから未使用の領域を再利用することをお勧めします。 ただし、省略可能ですがお勧めの手順として、最初にデータベース内のインデックスの平均ページ密度を判別する必要があります。 同じ量のデータの場合、ページの密度が高い場合は、ページの移動が少なくなるので圧縮の完了がより速くなります。 一部のインデックスでページの密度が低い場合は、データ ファイルを圧縮する前に、これらのインデックスのメンテナンスを実行してページ密度を増やすことを検討してください。 これにより、圧縮で割り当て済みのストレージ領域のより大幅な削減を実現できます。
データベース内のすべてのインデックスのページ密度を判別するには、次のクエリを使用します。 ページ密度は avg_page_space_used_in_percent 列で報告されます。
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
ページ密度が 60 から 70% 未満のページ数が多いインデックスがある場合は、データ ファイルを圧縮する前に、これらのインデックスを再構築または再編成することを検討してください。
Note
大規模なデータベースでは、ページ密度を判別するクエリが完了するまで、長時間 (数時間) かかる場合があります。 さらに、大規模なインデックスを再構築または再編成するには、かなりの時間とリソース使用量も必要です。 ページ密度を増やすことに追加の時間をかけることと、圧縮期間を短縮して高い省スペースを実現することとの間には、トレードオフがあります。
ページ密度が低いインデックスが複数ある場合、複数のデータベース セッションで並行して再構築し、プロセスを高速化できる場合があります。 ただし、これを実行することでデータベース リソースの制限に近づかないようにし、アプリケーション ワークロードに十分なリソース ヘッドルームを残してください。 Azure portal 内で、またはsys.dm_db_resource_stats ビューを使用して、リソース使用量 (CPU、データ IO、ログ IO) を監視し、これらの各ディメンションのリソース使用率が 100% を大幅に下回ったままの場合にのみ、追加の並列再構築を開始します。 CPU、データ IO、ログ IO の使用率が 100% の場合、データベースをスケール アップし、CPU コアを増やして IO スループットを向上させることができます。これでプロセスを高速に完了するために並行して再構築を追加できます。
インデックス再構築コマンドのサンプル
ALTER INDEX ステートメントを使用して、インデックスを再構築してページ密度を高めるためのサンプル コマンドを次に示します。
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
このコマンドによって、オンラインの再開可能なインデックスの再構築が開始されます。 これで、再構築の進行中に同時実行ワークロードでテーブルの使用を続行でき、何らかの理由で中断された場合に再構築を再開できます。 ただし、この種類の再構築は、テーブルへのアクセスをブロックするオフラインの再構築よりも低速です。 再構築中に他のワークロードからテーブルにアクセスする必要がない場合は、ONLINE および RESUMABLE オプションを OFF に設定し、WAIT_AT_LOW_PRIORITY 句を削除します。
インデックスのメンテナンスの詳細について学習するには、「クエリのパフォーマンスを向上させてリソースの消費を削減するためにインデックスのメンテナンスを最適化する」を参照してください。
複数のデータ ファイルを圧縮する
前に説明したように、データ移動での圧縮は長期のプロセスです。 データベースに複数のデータ ファイルがある場合は、複数のデータ ファイルを並行して圧縮することで、プロセスを高速化できます。 これを行うには、複数のデータベース セッションを開き、各セッションで異なる file_id 値とともに DBCC SHRINKFILE を使用します。 上記のインデックスの再構築と同様に、新しいそれぞれの並列圧縮コマンドを開始する前に、十分なリソース ヘッドルーム (CPU、データ IO、ログ IO) を確保してください。
次のサンプル コマンドでは、file_id が 4 のデータ ファイルを圧縮し、ファイル内でページを移動して、割り当てサイズを 52,000 MB に減らします。
DBCC SHRINKFILE (4, 52000);
ファイルの割り当て済み領域を最小限まで減らしたい場合は、ターゲット サイズを指定せずにステートメントを実行します。
DBCC SHRINKFILE (4);
ワークロードが圧縮と同時に実行されている場合、圧縮が完了してファイルが切り詰める前に、圧縮によって解放された記憶領域の使用を開始する可能性があります。 この場合、圧縮しても、指定したターゲットに割り当てられた領域を減らすことはできません。
これを回避するには、各ファイルを小さなステップに分割して圧縮します。 つまり、DBCC SHRINKFILE コマンドでは、ファイルに現在割り当てられている領域よりも少し小さいターゲットを設定します。 たとえば、file_id が 4 のファイルに割り当てられた領域が 200,000 MB の場合に、100,000 MB に圧縮するには、最初にターゲットを 170,000 MB に設定できます。
DBCC SHRINKFILE (4, 170000);
このコマンドが完了すると、ファイルが切り詰められ、割り当てられたサイズが 170,000 MB に減ります。 その後、ファイルが目的のサイズに圧縮されるまで、最初にターゲットを 140,000 MB に設定し、次に 110,000 MB などに設定して、このコマンドを繰り返すことができます。 コマンドが完了したがファイルが切り詰められていない場合は、30,000 MB ではなく 15,000 MB など、より小さなステップを使用します。
同時に実行されているすべての圧縮セッションの圧縮の進行状況を監視するには、次のクエリを使用できます。
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Note
圧縮がまだ進行中でも、圧縮の進行状況は非線形になり、percent_complete 列の値は長時間で実質的に変更されない状態が維持される可能性があります。
すべてのデータ ファイルの圧縮が完了したら、領域の使用状況クエリを使用して、割り当てられたストレージ サイズの削減結果を確認します。 使用済みの領域と割り当て済みの領域の間にまだ大きな差がある場合は、インデックスを再構築できます。 これで割り当てられた領域がさらに一時的に増加する可能性があります。ただし、インデックスの再構築後にデータ ファイルを再び圧縮すると、割り当てられた領域が大幅に減る結果になります。
ログ ファイルを拡張する
Azure SQL Managed Instance で、既存のログ ファイルを拡張してログ ファイルに領域を追加します (ディスク領域が許可されている場合)。 データベースへのログ ファイルの追加はサポートされていません。 ログ領域が不足し、さらにログ ファイルが保存されているボリュームでディスク容量が不足しない限り、トランザクション ログ ファイルは 1 つで十分です。
ログ ファイルを大きくするには、ALTER DATABASE ステートメントの MODIFY FILE 句を使用します。SIZE および MAXSIZE 構文を指定します。 詳細については、「ALTER DATABASE (Transact-SQL) の File および Filegroup オプション」を参照してください。
詳細については、「推奨事項」を参照してください。
トランザクション ログ ファイルのサイズ拡大の管理
トランザクション ログ ファイルのサイズ拡大を管理するには、ALTER DATABASE (Transact-SQL) の File および Filegroup オプション ステートメントを使用します。 次の点に注意してください。
- 現在のサイズを KB、MB、GB、TB 単位で変更するには、
SIZEオプションを使用します。 - 拡張増分値で変更するには、
FILEGROWTHオプションを使用します。 0 は、自動拡張がオフで、領域を追加できないことを示します。 - ログ ファイルの最大サイズを KB、MB、GB、TB 単位で制御するか、拡張値を UNLIMITED に設定するには、
MAXSIZEオプションを使用します。
推奨事項
トランザクション ログ ファイルを使用して作業するときの一般的な推奨事項を次に示します。
トランザクション ログの自動拡張 (autogrow) の増分は
FILEGROWTHオプションで設定されますが、トランザクションの作業負荷に対して常に余裕を持たせられるよう、十分な量にする必要があります。 ログ ファイルの拡張増分値は、拡張を頻繁に行わなくても済むように十分な大きさにする必要があります。 トランザクション ログのサイズは、次の時間のログ量を監視することで正しく判断できます。- 完全バックアップに必要な時間。完全バックアップが終わるまでログはバックアップされないためです。
- 最も大規模なインデックス保守管理に必要な時間。
- データベースで最も大規模な一括処理を実行するときに必要な時間。
FILEGROWTHオプションを利用してデータ ファイルとログ ファイルに 自動拡張 を設定する場合、割合は常に増加する量であるため、拡張率をより適切に制御できるように、percentageではなくsizeに設定することをお勧めします。- Azure SQL Managed Instance において、即時のファイル初期化は、最大 64 MB (メガバイト)のトランザクション ログ拡張イベントに役立ちます。 新しいデータベースの既定の自動拡張サイズの拡張は 64 MB です。 64 MB を超えるトランザクション ログ ファイルの自動拡張イベントについては、ファイルの瞬時初期化の恩恵を得ることができません。
- ベスト プラクティスとしては、トランザクション ログに対して
FILEGROWTHオプションの値を 1,024 MB 以上に設定しないでください。
自動拡張の増分が少ないと、小さな VLF が過度に生成され、パフォーマンスが低下する可能性があります。 指定されたインスタンスにおいて、すべてのデータベースの現在のトランザクション ログ サイズに最適な VLF 配布と必要なサイズを得るために必要な増分を決定するには、SQL Tiger チームが提供する VLF の分析と修正のためのスクリプトを参照してください。
自動拡張が大きくインクリメントされると、次の 2 つの問題が発生する可能性があります。
- 自動拡張が大きくインクリメントされると、新しい領域が割り当てられている間にデータベースが一時停止し、クエリのタイムアウトが発生する可能性があります。
- 自動拡張が大きくインクリメントされると、大きな VLF が生成される回数が極めて少なく、やはりパフォーマンスに影響が出る可能性があります。 指定されたインスタンスにおいて、すべてのデータベースの現在のトランザクション ログ サイズに最適な VLF 配布と必要なサイズを得るために必要な増分を決定するには、SQL Tiger チームが提供する VLF の分析と修正のためのスクリプトを参照してください。
自動拡張を有効にしても、増加が遅く、クエリのニーズを満たせなければ、トランザクション ログがいっぱいになったというメッセージが表示されます。 増分変更の詳細については、「ALTER DATABASE (Transact-SQL) の File および Filegroup オプション」を参照してください
ログ ファイルは自動的に圧縮するように設定できます。 ただし、これは推奨されません。auto_shrink データベース プロパティは既定で FALSE に設定されています。 auto_shrink を TRUE に設定すると、ファイル領域の 25% を超える領域が未使用の場合にのみ、自動圧縮によってファイルのサイズが縮小されます。
- ファイルは、ファイル領域の 25% のみが未使用領域になるサイズ、またはファイルの元のサイズの、どちらか大きい方のサイズまで圧縮されます。
- auto_shrink プロパティの設定変更については、「データベースのプロパティの表示または変更」と「ALTER DATABASE の SET オプション (Transact-SQL)」を参照してください。