ローカルとゾーン冗長による可用性 - Azure SQL Managed Instance
適用対象: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
この記事では、ローカル冗長性による可用性とゾーン冗長による高可用性を実現する Azure SQL Managed Instance のアーキテクチャについて説明します。
重要
ゾーン冗長構成は、General Purpose サービス レベルではパブリック プレビュー段階にあり、Business Critical サービス レベルでは一般提供が開始されています。
概要
SQL Managed Instance は、適用可能なすべてのパッチが適用された Windows オペレーティング システム上の SQL Server データベース エンジンの最新の安定バージョンで実行されます。 SQL Managed Instance は、パッチの適用、バックアップ、Windows と SQL データベース エンジンのアップグレードなどの重要なサービス タスク、および基になるハードウェア、ソフトウェア、またはネットワークのエラーなどの計画外のイベントを、自動的に処理します。 アプリで再試行ロジックが使用されている場合、インスタンスのパッチ適用やフェールオーバーのときのダウンタイムによる大きな影響はありません。 SQL Managed Instance は、クリティカルな状況であっても迅速な復旧が可能であるため、データが常に使用可能であることが保証されます。 ほとんどのユーザーは、アップグレードが継続的に実行されていることに気付きません。
既定では、Azure SQL Managed Instance はローカル冗長性で可用性を実現し、次の期間中にインスタンスを使用できるようにします。
- 顧客が開始した管理操作で発生する短いダウンタイム
- サービス メンテナンス操作
- 次に関連する問題とデータセンターの障害:
- サービスを稼働するマシンが実行されているラック
- SQL データベース エンジンを実行する VM をホストする物理マシン
- SQL データベース エンジンを実行する仮想マシン
- SQL データベース エンジンに関するその他の問題
- その他の、発生する可能性がある計画外のローカル障害
デフォルトの可用性ソリューションは、コミットされたデータが障害によって失われないこと、メンテナンス操作がワークロードに影響を及ぼさないこと、インスタンスがソフトウェア アーキテクチャでの単一障害点にならないことを保証するように設計されています。
ただし、ゾーン全体の障害発生時にデータへの影響を最小限に抑えるために、ゾーン冗長を有効にすると、高可用性を実現できます。 ゾーン冗長がない場合、フェールオーバーは同じデータ センター内でローカルに実行されるため、障害が解決されるまでインスタンスが使用できなくなる可能性があります。フェールオーバー グループ、geo 冗長バックアップの geo リストアなどの、ディザスター リカバリー ソリューションを使用しなければ復元できません。 詳細については、「ビジネス継続性の概要」を確認してください。
高可用性により、次に関する影響からユーザーを保護することで、サービスの信頼性が向上します。
- データセンターを形成する可用性ゾーン
サービス レベルに基づいて、2 つの異なる可用性アーキテクチャ モデルがあります。
- リモート ストレージ モデルは、リモート ストレージの可用性と信頼性、および Azure Service Fabric によって管理されるコンピューティング クラスターの可用性に依存する、General Purpose および Next-gen General Purpose サービス レベルでのコンピューティングとストレージの分離に基づいています。 この可用性モデルでは、メンテナンス アクティビティ中に一定のパフォーマンスの低下を許容できる予算重視のビジネス アプリケーションを対象とします。
- ローカル ストレージ モデルは、ローカル ストレージを持つ Business Critical サービス レベルの可用性データベース エンジン ノードのクォーラムに依存するデータベース エンジン プロセスのクラスターに基づいています。 このローカル ストレージ モデルは、トランザクションレートが高く、高い IO パフォーマンスを必要とするミッション クリティカルなアプリケーションを対象とします。 高可用性アーキテクチャにより、メンテナンス アクティビティ中のワークロードへのパフォーマンスへの影響を最小限に抑えることができます。
さまざまなサービス レベルの特定の SLA について詳しくは、「Azure SQL Managed Instance のSLA」を確認してください。
ローカル冗長性による可用性
ローカル冗長可用性は、計算ノードとデータをプライマリ リージョンの 1 つのデータセンター内に格納することに基づいており、小規模なネットワークや停電などのローカル障害が発生した場合にデータが保護されます。 火災や洪水などの大規模な災害がリージョン内で発生した場合、計算ノードのストレージ アカウントやデータのすべてのレプリカが失われたり、回復不能になる可能性があります。 そのため、ローカル冗長可用性オプションを使用するときにデータをさらに保護するには、データベースのバックアップに回復性の高いストレージ オプションを使用することを検討してください。
汎用のサービス階層
General Purpose サービス レベルでは、リモート ストレージの可用性アーキテクチャが使われます。 次の図は、計算レイヤーとストレージ レイヤーが分離されている4 つの異なるノードを示しています。
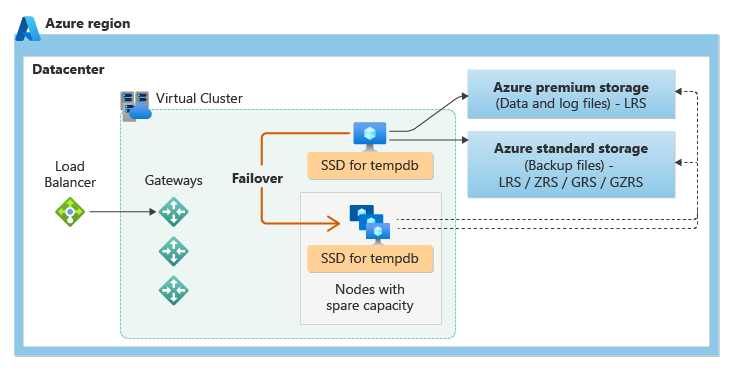
リモート ストレージの可用性モデルには、2 つのレイヤーが含まれます。
- ステートレス計算レイヤー。データベース エンジン プロセスが実行され、一時的なデータとキャッシュ データ (アタッチされた SSD 上の
tempdbとmodelデータベース、およびメモリ内のプラン キャッシュ、バッファー プール、列ストア プールなど) のみが含まれています。 このステートレス ノードは、データベース エンジンの初期化、ノードの正常性の制御、必要に応じた他のノードへのフェールオーバーの実行を行う Azure Service Fabric によって操作されます。 - ステートフル データ レイヤー。データベース ファイル (
.mdfおよび.ldf) は Azure Blob Storage に保存されています。 Azure Blob Storage には、データの可用性と冗長性の機能が組み込まれています。 ローカル冗長可用性は、データをローカル冗長ストレージ (LRS) に格納することに基づいています。これにより、プライマリ リージョンの 1 つのデータセンター内でデータが 3 回コピーされます。 データベース エンジン プロセスがクラッシュした場合でも、ログ ファイル内のすべてのレコードまたはデータ ファイル内のすべてのページが保持されることが保証されます。
データベース エンジンまたはオペレーティング システムがアップグレードされるとき、または障害が検出されたとき、Azure Service Fabric は常に、ステートレス データベース エンジン プロセスを十分な空き容量がある別のステートレス計算ノードに移動します。 Azure Blob Storage 内のデータは移動による影響を受けず、データとログ ファイルは、新しく初期化されたデータベース エンジン プロセスにアタッチされます。 このプロセスにより高い可用性が保証されますが、新しいデータベース エンジン プロセスはコールド キャッシュを使って起動されるため、負荷の高いワークロードでは移行の間にパフォーマンスが低下する可能性があります。
Next-gen General Purpose サービス レベル
Note
Next-gen General Purpose サービス レベルのアップグレードは現在プレビュー段階です。
次世代 General Purpose は、既存の General Purpose サービス レベルに対するアーキテクチャ アップグレードであり、アップグレードされたリモート ストレージ レイヤを使用して、ページ BLOB ではなくマネージド ディスクにインスタンス データを格納し、ローカルで維持します。
Business Critical サービス レベル
Business Critical サービス レベルではローカル ストレージ可用性モデルが使われ、コンピューティング リソース (データベース エンジン プロセス) とストレージ (ローカルにアタッチされた SSD) が 1 つのノードに統合されます。 高可用性は、コンピューティングとストレージの両方を追加のノードにレプリケートすることで実現されます。
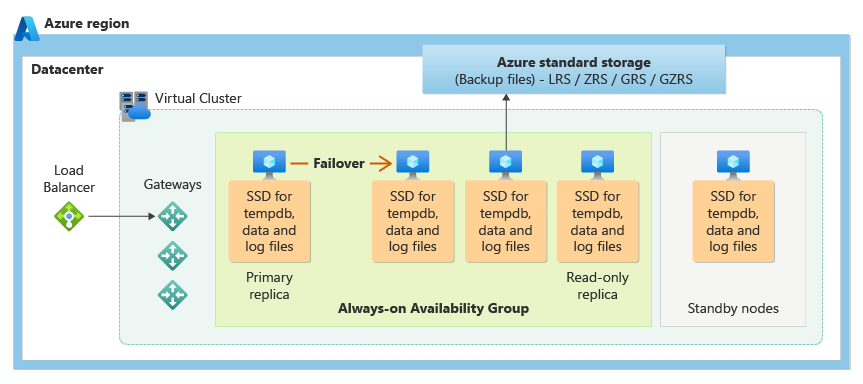
基になるデータベース ファイル (.mdf/.ldf) は、非常に低い待機時間の IO をワークロードに提供するために、アタッチされている SSD ストレージ上に配置されています。 高可用性は、SQL Server Always On 可用性グループと同様のテクノロジを使用して実装されます。 クラスターには、読み取り/書き込みの顧客ワークロードにアクセス可能な単一のプライマリ レプリカと、データのコピーを格納する最大 3 つのセカンダリ レプリカ (計算とストレージ) が含まれます。 プライマリ レプリカは、常に変更を順次セカンダリ レプリカにプッシュして、各トランザクションをコミットする前に、十分な数のセカンダリ レプリカにデータが保持されるようにします。 このプロセスにより、何らかの理由でプライマリ レプリカまたは読み取り可能なセカンダリ レプリカが利用不可になった場合に、フェールオーバー先となる完全に同期されたノードが常に利用可能であることが保証されます。 フェールオーバーは、Azure Service Fabric によって開始されます。 セカンダリ レプリカが新しいプライマリ レプリカになると、クォーラムを維持するのに十分な数のレプリカがクラスターに確実にあるよう、別のセカンダリ レプリカが作成されます。 フェールオーバーが完了すると、Azure SQL の接続は、新しいプライマリ レプリカ (または接続文字列に基づく読み取り可能なセカンダリ レプリカ)に自動的にリダイレクトされます。
その他の利点として、ローカル ストレージ可用性モデルは、読み取り専用の Azure SQL 接続をセカンダリ レプリカの 1 つにリダイレクトする機能を備えています。 この機能は、読み取りスケールアウトと呼ばれます。追加料金なしで 100% の追加のコンピューティング容量を提供し、分析ワークロードなどの読み取り専用の操作をプライマリ レプリカからオフロードします。
ゾーン冗長による高可用性
ゾーン冗長可用性は、プライマリ リージョンの 3 つの Azure 可用性ゾーンにレプリカを配置する方法に基づいています。 各可用性ゾーンは、独立した電源、冷却装置、ネットワークを備えた独立した物理的な場所です。
既定では、ローカル ストレージ可用性モデル用のノードのクラスターは、同じデータセンター内に作成されます。 Azure Availability Zones の導入により、SQL Managed Instance は、同じリージョン内の異なる可用性ゾーンに複数のレプリカを配置します。 単一障害点をなくすため、制御リングも複数のゾーンで複製されます。 その後コントロール プレーン トラフィックは、可用性ゾーン間にもデプロイされるロード バランサーにルーティングされます。 コントロール プレーンからロード バランサーへのトラフィック ルーティングは、Azure Traffic Manager (ATM) によって制御されます。
ゾーン冗長構成を使うことで、アプリケーション ロジックを変更しなくても、Business Critical インスタンスや General Purpose インスタンスに、データセンターの壊滅的な障害などの極めて大規模な障害に対する回復性を持たせることができます。 任意の既存の Business Critical インスタンスや General Purpose インスタンスを、ゾーン冗長構成に変換できます。
ゾーン冗長インスタンスでは、少し離れたところの異なるデータセンターにレプリカがあるため、ネットワーク待ち時間が長くなるとトランザクションのコミット時間が長くなり、一部の OLTP ワークロードのパフォーマンスに影響を及ぼす可能性があります。 いつでもゾーン冗長設定を無効にして単一ゾーン構成に戻ることができます。 このプロセスはオンライン操作であり、サービス レベルの通常の目標アップグレードと似ています。 プロセスの最後に、インスタンスは、ゾーン冗長リングから単一ゾーン リングに (またはその逆に) 移行されます。
SQL Managed Instance のゾーン冗長の使用を開始するには、「ゾーン冗長の構成」を確認してください。
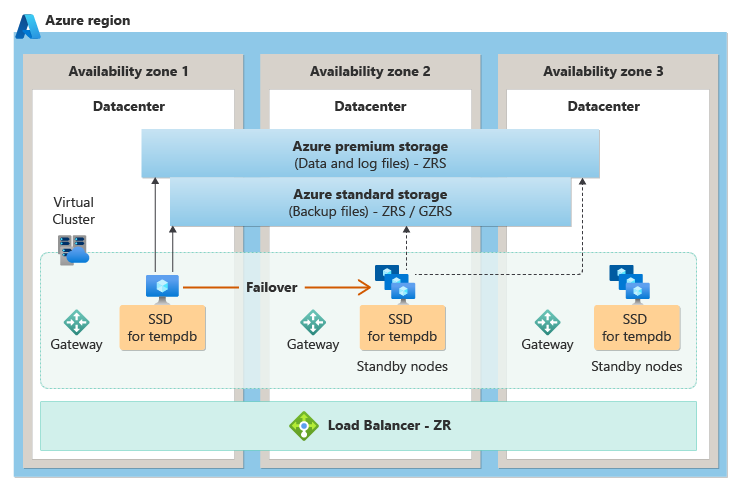
汎用のサービス階層
General Purpose サービス レベルでは、ステートレス コンピューティング ノードを異なる可用性ゾーンに配置することでゾーン冗長性が実現されます。また、現在アクティブな SQL データベース エンジン プロセスを含むノードにアタッチされているステートフル ゾーン冗長ストレージ (ZRS) に依存することになります。 障害が発生した場合、SQL データベース エンジン プロセスはステートレス ノードの 1 つでアクティブになり、ステートフル ストレージ内のデータにアクセスします。
次の図は、General Purpose サービス レベルのゾーン冗長アーキテクチャを示しています。
Note
ゾーン冗長は、General Purpose サービス レベルでは現在プレビュー段階です。
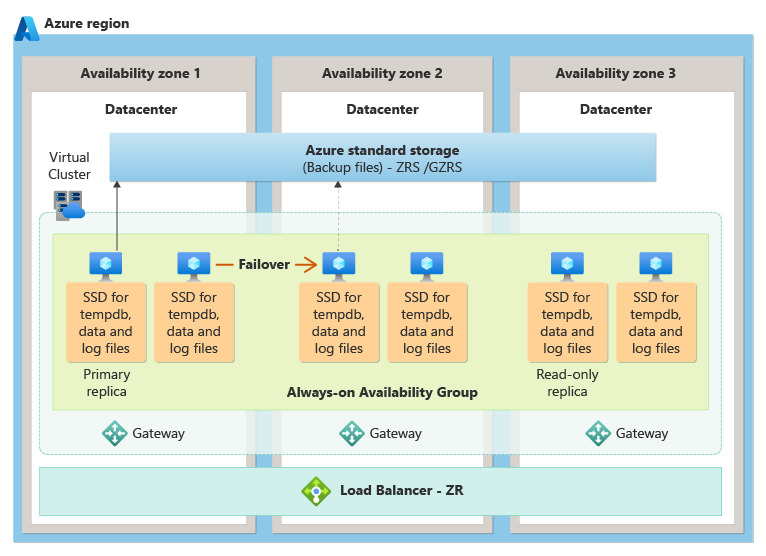
Business Critical サービス レベル
Business Critical サービス レベルでは、コンピューティング レプリカとストレージ レプリカを異なる可用性ゾーンに配置し、基になる Always On 可用性グループ テクノロジを使用して、プライマリ インスタンスから他の可用性ゾーンのスタンバイ レプリカへのデータ変更をレプリケートすることで、ゾーン冗長を実現します。 障害が発生した場合、スタンバイ レプリカの 1 つをプライマリにシームレスに移行する自動フェールオーバーが発生します。
次の図は、Business Critical サービス レベルのゾーン冗長アーキテクチャを示しています。
アプリケーションの障害回復性のテスト
可用性は、データベース アプリケーションに対して透過的に機能する、SQL Managed Instance プラットフォームの基礎となる部分です。 しかし、計画済みまたは計画外のイベント時に開始された自動フェールオーバー操作がアプリケーションに与える影響をテストしてから、運用環境にデプロイする必要があると Microsoft は認識しています。 特別な API を呼び出してマネージド インスタンスを再起動することで、フェールオーバーを手動でトリガーできます。 再起動は負荷のかかる操作であり、数が多いとプラットフォームに負荷をかける可能性があるため、各マネージド インスタンスに対しては、15 分ごとに 1 つのフェールオーバー呼び出しのみが許可されます。
実際のフェールオーバー中、SQL サービスが別のノードでプライマリになる間には、インスタンスへの接続は失敗します。 フェールオーバーをシミュレートするには、SQL プロセスを再起動するコマンドを呼び出して、フェールオーバーがあった状態を模倣するサービスの開始をシミュレートします。 ただし、シミュレートされたフェールオーバーと比較すると、実際のフェールオーバー期間では接続が長時間失敗する可能性があります。これは、実際のフェールオーバーでは、SQL プロセスがクラスター内の別の仮想マシン (ローカルまたはゾーン冗長が有効な場合は別のゾーン) のプライマリになり、シミュレートされたフェールオーバーでは既存の仮想マシンで SQL プロセスが再起動されるためです。
このセクションの手動フェールオーバー コマンドは、ローカル冗長構成とゾーン冗長構成の両方で同じように動作します。SQL プロセスはローカルでのみ再起動され、別のノードへのフェールオーバーは開始されません。 このローカル フェールオーバーは、フェールオーバー グループに対して発生するフェールオーバーとは異なります。
ローカル フェールオーバーは、PowerShell、REST API または Azure CLI を使用して開始できます。
| PowerShell | REST API | Azure CLI |
|---|---|---|
| Invoke-AzSqlInstanceFailover | SQL Managed Instance - フェールオーバー | Azure CLI から REST API 呼び出しを呼び出すために az sql mi failover が使用できます |
まとめ
Azure SQL Managed Instance では、Azure プラットフォームと緊密に統合される、組み込みの高可用性ソリューションが使われています。 障害の検出と復旧に Service Fabric を、データ保護に Azure BLOB ストレージを、フォールト トレランスを高めるために Availability Zones を活用しています。 また、Business Critical サービス レベル では、データベースのレプリケーションとフェールオーバーのために、SQL Managed Instance は SQL Server の Always On 可用性グループのテクノロジを利用しています。 これらのテクノロジを組み合わせることで、アプリケーションは混合ストレージ モデルを最大限に活用し、最も要求の厳しい SLA に対応できます。
次のステップ
- Azure SQL Managed Instance のゾーン冗長を有効にします。
- Azure 可用性ゾーンの詳細
- Service Fabric の詳細
- Azure Traffic Manager の詳細
- SQL Managed Instance で手動フェールオーバーを開始する方法の詳細
- 高可用性およびディザスター リカバリーのためのその他のオプションについては、ビジネス継続性に関するページを参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示