Azure VM 上の SAP HANA データベースの復元
この記事では、Azure Virtual Machines (VM) で実行されていて、Azure Backup サービスによって Recovery Services コンテナーにバックアップされた SAP HANA データベースを復元する方法について説明します。 復元データを使用して、開発/テスト シナリオ用にコピーを作成することや、以前の状態に戻すことができます。
Azure Backup では、SAP HANA システム レプリケーション (HSR) インスタンスのバックアップと復元がサポートされるようになりました。
Note
- HSR を使用した HANA データベースの復元プロセスは、HSR を使用しない HANA データベースの復元プロセスと同じです。 SAP アドバイザリに従い、HSR モードを使用してデータベースを "スタンドアロン" データベースとして復元できます。 ターゲット システムで HSR モードが有効になっている場合、最初にこのモードを無効にし、その後データベースを復元します。 ただし、ファイルとして復元する場合は、HSR モードを無効にする (HSR を中断する) 必要はありません。
- 現在、元の場所への回復 (OLR) は HSR ではサポートされていません。 代わりに、[場所の指定] 復元を選択し、"ホスト" として一覧からソース VM を選択します。
- HSR インスタンスへの復元はサポートされていません。 ただし、HANA インスタンスのみへの復元はサポートされています。
サポートされている構成とシナリオについて詳しくは、「SAP HANA バックアップのサポート マトリックス」を参照してください。
特定の時点 (ポイントインタイム) または復旧ポイントに復元する
Azure Backup は、Azure VM で実行されている SAP HANA データベースを復元します。 次のことが可能です。
ログ バックアップを使用して、特定の日付または時刻 (秒) の状態に復元する。 Azure Backup は、選択された時刻に基づいて、復元のために必要になる適切な完全バックアップ、差分バックアップ、および一連のログ バックアップを自動的に判別します。
特定の完全バックアップまたは差分バックアップに復元することで、特定の復旧ポイントに復元する。
前提条件
データベースの復元を開始する前に、次のことに注意してください。
データベースの復元先にできるのは、同じリージョン内の SAP HANA インスタンスのみです。
ターゲット インスタンスは、ソースと同じコンテナーに登録されている必要があります。 SAP HANA データベースのバックアップについて詳細を確認してください。
Azure Backup は、同じ VM 上にある 2 つの異なる SAP HANA インスタンスを識別できません。 そのため、同じ VM 上の一方のインスタンスから他方のインスタンスにデータを復元することはできません。
ターゲットの SAP HANA インスタンスが復元の準備ができているか確認するには、そのインスタンスのバックアップの準備状態を確認します。
Azure portal で [バックアップ センター] に移動し、[バックアップ] を選択します。
[開始: バックアップの構成] ペインの [データソースの種類] で [Azure VM の SAP HANA] を選択し、SAP HANA インスタンスの登録先のコンテナーを選択し、[続行] を選択します。
![データソースの種類として [Azure VM の SAP HANA] を選択する場所を示すスクリーンショット。](media/sap-hana-db-restore/hana-select-vault.png)
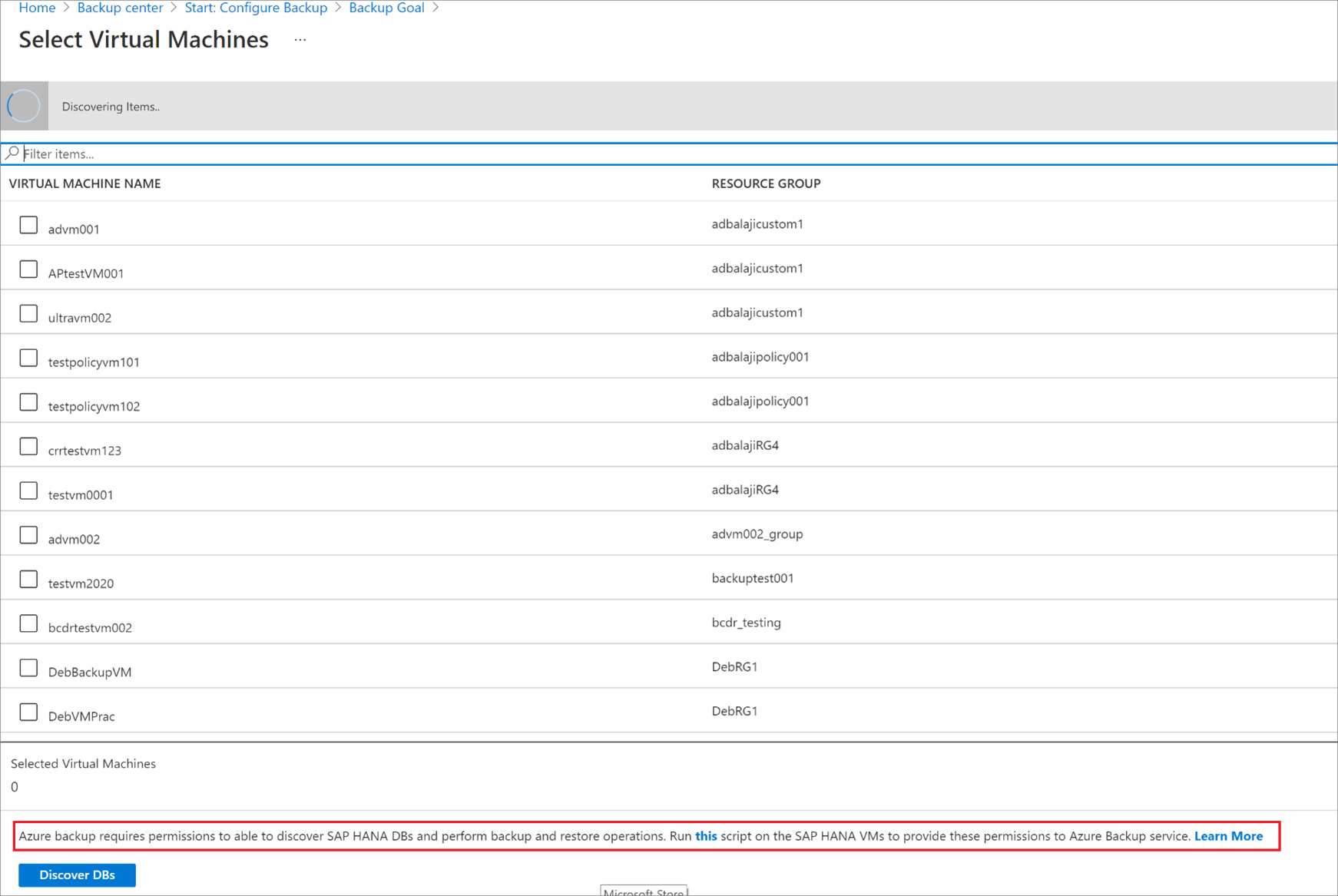
[VM 内のデータベースを検出] で [詳細の表示] を選択します。
ターゲット VM の [バックアップの準備] を確認します。
SAP HANA がサポートする復元の種類について詳しくは、「SAP HANA ノート 1642148」に関するページを参照してください。


データベースを復元する
データベースを復元するには、次のアクセス許可が必要です。
- バックアップ オペレーター: 復元を実行するコンテナーでのアクセス許可を提供します。
- 共同作成者 (書き込み): バックアップされたソース VM へのアクセス権を提供します。
- 共同作成者 (書き込み): ターゲット VM へのアクセス権を提供します。
- 同じ VM に復元する場合は、これがソース VM になります。
- 別の場所に復元する場合は、これが新しいターゲット VM になります。
Azure portal で [バックアップ センター] に移動し、[復元] を選択します。
データソースの種類として [Azure VM の SAP HANA] を選択し、復元するデータベースを選択し、[続行] を選択します。
[復元の構成] で、データの復元先または復元方法を指定します。
- 別の場所:別の場所にデータベースを復元し、元のソース データベースを保持します。
- DB の上書き:元のソースと同じ SAP HANA インスタンスにデータを復元します。 このオプションでは、元のデータベースが上書きされます。

注意
復元中 (仮想 IP/ロード バランサー フロントエンド IP シナリオにのみ適用されます)、HSR モードをスタンドアロンとして変更した後にターゲット ノードにバックアップを復元しようとするか、SAP によって推奨されるように、復元前に HSR を中断する場合は、Load Balancer がターゲット ノードを指していることを確認します。
シナリオ例:
- 事前登録スクリプトで "hdbuserstore set SYSTEMKEY localhost" を使用している場合、復元中に問題は発生しません。
- 事前登録スクリプトに *hdbuserstore が
SYSTEMKEY <load balancer host/ip>を設定していて、バックアップをターゲット ノードに復元しようとする場合は、ロード バランサーが復元する必要があるターゲット ノードを指していることを確認します。
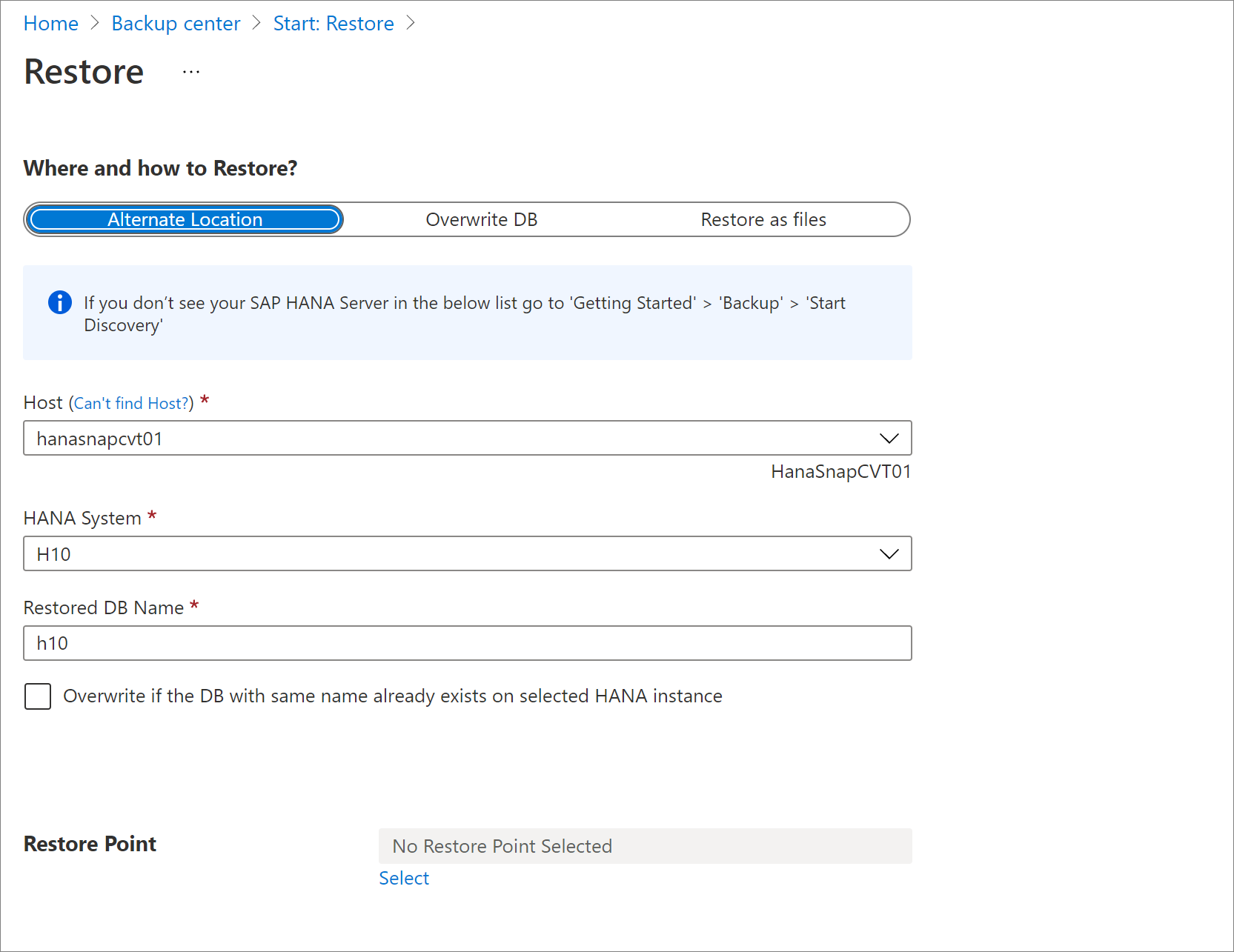
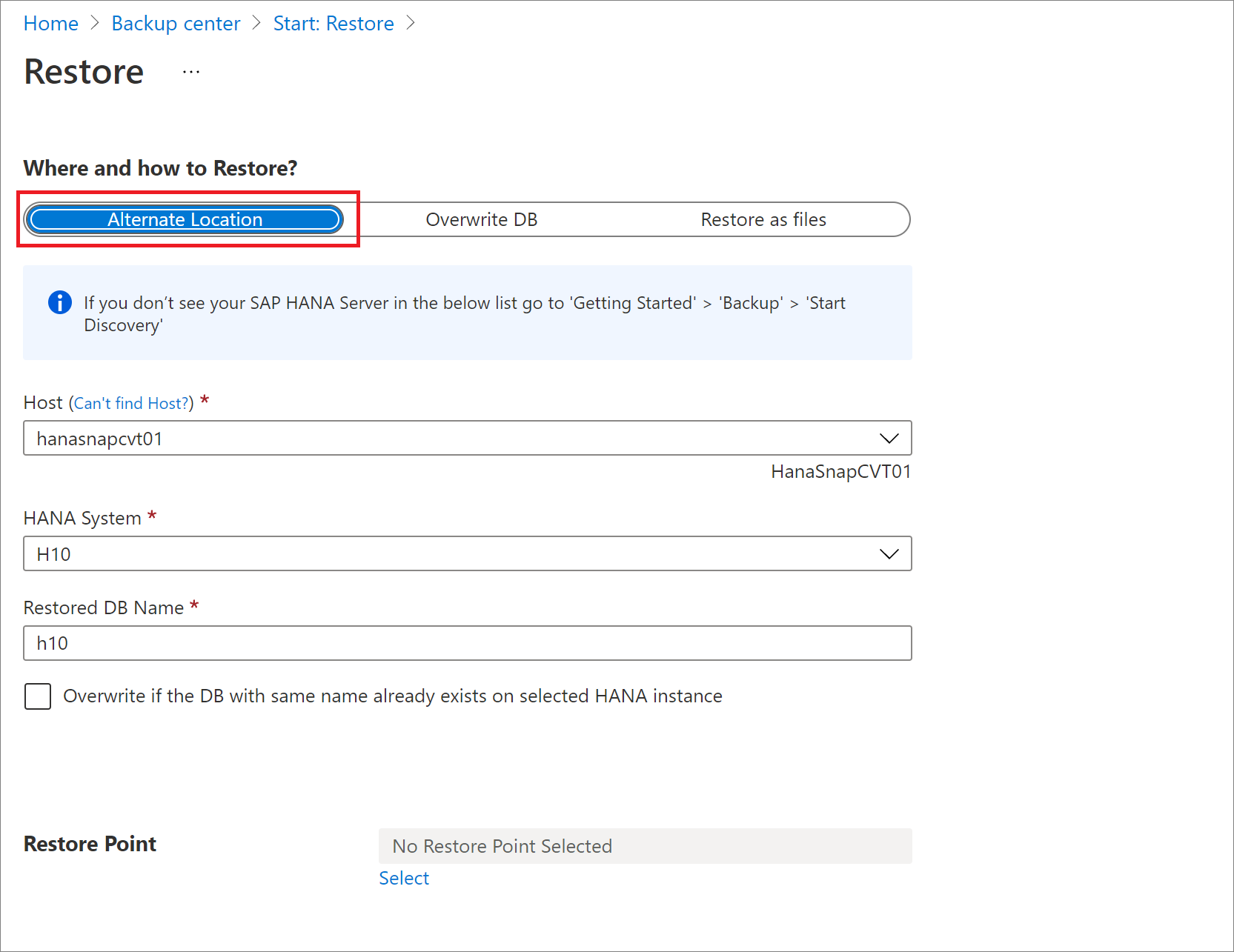
別の場所に復元する
[復元] ペインの [復元する場所と方法] で、[場所の指定] を選択します。
データベースを復元する先の SAP HANA のホスト名とインスタンス名を選択します。
ターゲット SAP HANA インスタンスを復元する準備ができているかどうかを、そのバックアップの準備状態を確認することで確認します。 詳細については、「前提条件」を参照してください。
[復元される DB 名] ボックスに、ターゲット データベースの名前を入力します。
Note
SDC (Single Database Container) の復元では、確認事項に従う必要があります。
該当する場合は、[Overwrite if the DB with the same name already exists on selected HANA instance] (選択した HANA インスタンスに同じ名前の DB が既に存在する場合は上書きする) チェックボックスを選択します。
[復元ポイントの選択] で、特定の時点に復元する[ログ (特定の時点)] を選択します。 または、[完全および差分] を選択して、特定の復旧ポイントに復元します。
ファイルとして復元
Note
[ファイルとして復元する] は、共通インターネット ファイル システム (CIFS) 共有では機能しませんが、ネットワーク ファイル システム (NFS) では機能します。
バックアップ データをデータベースとしてではなくファイルとして復元するには、[ファイルとして復元する] を選択します。 ファイルが指定されたパスにダンプされた後、それらのファイルを任意の SAP HANA マシン (それらのファイルをデータベースとして復元したい場所) に移動できます。 これらのファイルは任意のマシンに移動できるため、サブスクリプションやリージョンをまたいでデータを復元できます。
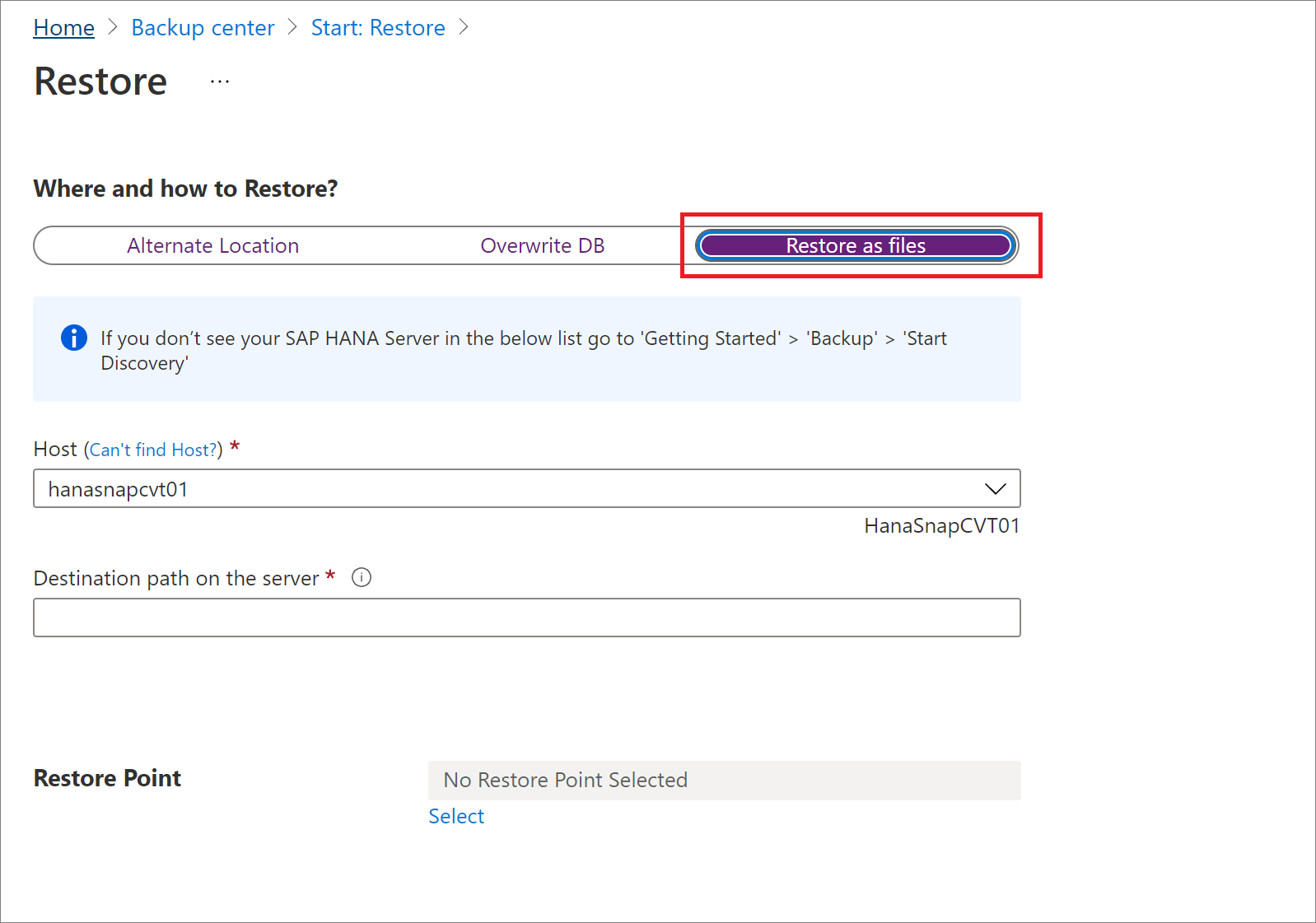
[復元] ペインの [復元する場所と方法] で、[ファイルとして復元する] を選択します。
バックアップ ファイルを復元する先のホストまたは HANA サーバーの名前を選択します。
[サーバー上の宛先パス] ボックスに、前の手順で選択したサーバー上のフォルダー パスを入力します。 これは、必要なすべてのバックアップ ファイルをサービスがダンプする場所です。
ダンプされるファイルは次のとおりです。
- データベース バックアップ ファイル
- (関連するバックアップ ファイルごとの) JSON メタデータ ファイル
通常、ネットワーク共有パスや、宛先パスとして指定されているマウントされた Azure ファイル共有のパスを使うと、同じネットワーク内の他のマシンや、それらにマウントされている同じ Azure ファイル共有でこれらのファイルに簡単にアクセスできます。
Note
ターゲットとなる登録済み VM にマウントされている Azure ファイル共有でデータベース バックアップ ファイルを復元するには、その共有に対する読み取り/書き込みアクセス許可がルート アカウントにあることを確認します。
すべてのバックアップ ファイルとフォルダーを復元する先の復元ポイントを選択します。
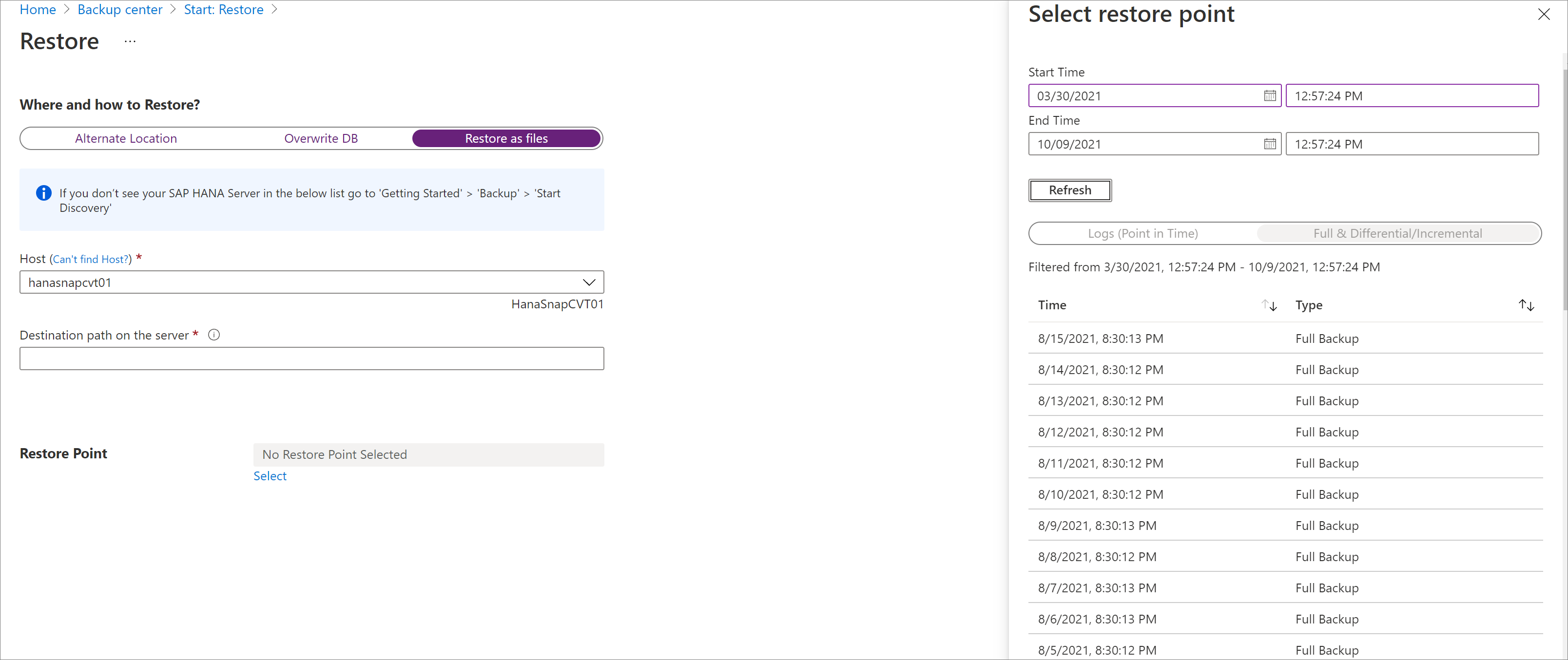
選択した復元ポイントに関連付けられているすべてのバックアップ ファイルが、この宛先パスにダンプされます。
選択した復元ポイントの種類 ([特定の時点] または [完全および差分]) に基づいて、宛先パスに 1 つ以上のフォルダーが作成されるのを確認します。 フォルダーの 1 つである Data_<復元の日時> には、完全バックアップが格納され、別のフォルダーである Log には、ログ バックアップとその他のバックアップ (差分、増分など) が格納されます。
Note
[特定の時点に復元] を選択した場合、ターゲット VM にダンプされたログ ファイルに、復元のために選択した特定の時点を超えるログが含まれる場合があります。 Azure Backup でこれが行なわれることにより、選択した特定の時点に一貫して正常に復元するために、すべての HANA サービスのログ バックアップを使用できるようになります。
復元されたファイルを SAP HANA サーバー (復元されたファイルをデータベースとして復元したい場所) に移動し、次の操作を行ないます。
a. 次のコマンドを実行して、バックアップ ファイルが格納されているフォルダーまたはディレクトリのアクセス許可を設定します。
chown -R <SID>adm:sapsys <directory>b.
<SID>admとして、次の一連のコマンドを実行します。su: <sid>admc. 復元用のカタログ ファイルを生成します。 完全バックアップの JSON メタデータ ファイルから BackupId を抽出します。これは、後ほど復元操作で使用します。 完全バックアップとログ バックアップがそれぞれ異なるフォルダーにあることを確認し (ログ バックアップは、完全バックアップ復旧の場合には存在しません)、これらのフォルダー内の JSON メタデータ ファイルを削除します。 次を実行します。
hdbbackupdiag --generate --dataDir <DataFileDir> --logDirs <LogFilesDir> -d <PathToPlaceCatalogFile><DataFileDir>: 完全バックアップが格納されるフォルダー。<LogFilesDir>: ログ バックアップ、差分バックアップ、増分バックアップが格納されるフォルダー。 完全バックアップ復元の場合、ログ フォルダーは作成されないため、空のディレクトリを追加します。<PathToPlaceCatalogFile>: 生成されたカタログ ファイルを配置する必要があるフォルダー。
d. HANA Studio を介して新しく生成されたカタログ ファイルを使用して復元するか、この新しく生成されたカタログを使用して SAP HANA HDBSQL ツールで復元クエリを実行できます。 HDBSQL クエリの一覧を次に示します。
HDBSQL プロンプトを開くには、次のコマンドを実行します。
hdbsql -U AZUREWLBACKUPHANAUSER -d systemDB特定の時点まで復元するには:
復元されたデータベースを新しく作成する場合は、HDBSQL コマンドを実行して新しいデータベース
<DatabaseName>を作成し、その後、ALTER SYSTEM STOP DATABASE <db> IMMEDIATEコマンドを使用してこの復元用のデータベースを停止します。 ただし、既存のデータベースのみを復元する場合は、HDBSQL コマンドを実行してそのデータベースを停止します。そして、次のコマンドを実行してデータベースを復元します。
RECOVER DATABASE FOR <db> UNTIL TIMESTAMP <t1> USING CATALOG PATH <path> USING LOG PATH <path> USING DATA PATH <path> USING BACKUP_ID <bkId> CHECK ACCESS USING FILE<DatabaseName>: 復元する新しいデータベースまたは既存のデータベースの名前。<Timestamp>- 特定の時点に復元する場合の正確なタイムスタンプ。<DatabaseName@HostName>: バックアップを復元に使用するデータベースの名前と、このデータベースが存在するホストまたは SAP HANA サーバーの名前。USING SOURCE <DatabaseName@HostName>オプションでは、データ バックアップ (復元に使用) が、ターゲットの SAP HANA マシンとは異なる SID または名前を持つデータベースであることが指定されます。 バックアップが作成されたのと同じ HANA サーバーで復元を実行する場合には、これを指定する必要はありません。<PathToGeneratedCatalogInStep3>: "手順 c." で生成されたカタログ ファイルへのパス。<DataFileDir>: 完全バックアップが格納されるフォルダー。<LogFilesDir>: ログ バックアップ、差分バックアップ、増分バックアップ (存在する場合) が格納されるフォルダー。<BackupIdFromJsonFile>: "手順 c" で抽出された BackupId。
特定の完全または差分バックアップに復元するには、次のようにします。
復元されたデータベースを新しく作成する場合は、HDBSQL コマンドを実行して新しいデータベース
<DatabaseName>を作成し、その後、ALTER SYSTEM STOP DATABASE <db> IMMEDIATEコマンドを使用してこの復元用のデータベースを停止します。 ただし、既存のデータベースのみを復元する場合は、HDBSQL コマンドを実行してそのデータベースを停止します。RECOVER DATA FOR <DatabaseName> USING BACKUP_ID <BackupIdFromJsonFile> USING SOURCE '<DatabaseName@HostName>' USING CATALOG PATH ('<PathToGeneratedCatalogInStep3>') USING DATA PATH ('<DataFileDir>') CLEAR LOG<DatabaseName>: 復元する新しいデータベースまたは既存のデータベースの名前。<Timestamp>- 特定の時点に復元する場合の正確なタイムスタンプ。<DatabaseName@HostName>: バックアップを復元に使用するデータベースの名前と、このデータベースが存在するホストまたは SAP HANA サーバーの名前。USING SOURCE <DatabaseName@HostName>オプションでは、データ バックアップ (復元に使用) が、ターゲットの SAP HANA マシンとは異なる SID または名前を持つデータベースであることが指定されます。 バックアップが作成されたのと同じ HANA サーバーで復元を実行する場合には、これを指定する必要はありません。<PathToGeneratedCatalogInStep3>: "手順 c." で生成されたカタログ ファイルへのパス。<DataFileDir>: 完全バックアップが格納されるフォルダー。<LogFilesDir>: ログ バックアップ、差分バックアップ、増分バックアップ (存在する場合) が格納されるフォルダー。<BackupIdFromJsonFile>: "手順 c" で抽出された BackupId。
バックアップ ID を使用して復元するには:
RECOVER DATA FOR <db> USING BACKUP_ID <bkId> USING CATALOG PATH <path> USING LOG PATH <path> USING DATA PATH <path> CHECK ACCESS USING FILE例 :
同じサーバーでの SAP HANA システムの復元:
RECOVER DATABASE FOR SYSTEM UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILE同じサーバーでの SAP HANA テナントの復元:
RECOVER DATABASE FOR DHI UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILE別のサーバーでの SAP HANA システムの復元:
RECOVER DATABASE FOR SYSTEM UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING SOURCE <sourceSID> USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILE別のサーバーでの SAP HANA テナントの復元:
RECOVER DATABASE FOR DHI UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING SOURCE <sourceSID> USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILE

ファイルとしての部分復元
Azure Backup サービスは、"ファイルとして復元" 中、ダウンロードする一連のファイルを決定します。 ただし、コンテンツ全体をもう一度ダウンロードしたくないシナリオがあります。
たとえば、週次完全バックアップ、日次差分バックアップ、ログ バックアップというバックアップ ポリシーがあり、特定の差分のファイルは既にダウンロードしているとします。 これが適切な復旧ポイントではないことが分かり、翌日の差分をダウンロードすることに決定しました。 最初の完全バックアップは既にあるため、ここで必要なのは差分ファイルのみです。 Azure Backup が提供する "ファイルとしての部分復元" 機能を使用することで、ダウンロード チェーンから完全バックアップを除外し、差分バックアップのみをダウンロードできます。
バックアップ ファイルの種類の除外
ExtensionSettingOverrides.json は JSON (JavaScript Object Notation) ファイルであり、SQL 用の Azure Backup サービスの複数の設定のオーバーライドが含まれています。 "ファイルとしての部分復元" 操作では、新しい JSON フィールドである RecoveryPointsToBeExcludedForRestoreAsFiles を追加する必要があります。 このフィールドには、次の "ファイルとして復元" 操作でどの種類の復旧ポイントを除外するかを示す文字列値を入力します。
ファイルをダウンロードするターゲット マシンで、opt/msawb/bin フォルダーに移動します。
ExtensionSettingOverrides.JSON という名前の新しい JSON ファイルを作成します (このファイルがまだ存在しない場合)。
次の JSON キーと値のペアを追加します。
{ "RecoveryPointsToBeExcludedForRestoreAsFiles": "ExcludeFull" }ファイルのアクセス許可と所有権を次のように変更します。
chmod 750 ExtensionSettingsOverrides.json chown root:msawb ExtensionSettingsOverrides.jsonサービスを再起動する必要はありません。 Azure Backup サービスは、このファイルの記述に従って、バックアップの種類を復元チェーンから除外しようとします。
RecoveryPointsToBeExcludedForRestoreAsFiles には、復元時に除外する復旧ポイントを示す特定の値のみ指定できます。 SAP HANA の場合、これらの値は次のとおりです。
ExcludeFull復元ポイント チェーンに、差分、増分、ログなどの他の種類のバックアップが存在する場合、それらのバックアップがダウンロードされます。ExcludeFullAndDifferential復元ポイント チェーンに、増分、ログなどの他の種類のバックアップが存在する場合、それらのバックアップがダウンロードされます。ExcludeFullAndIncremental復元ポイント チェーンに、差分、ログなどの他の種類のバックアップが存在する場合、それらのバックアップがダウンロードされます。ExcludeFullAndDifferentialAndIncremental復元ポイント チェーンに、ログなどの他の種類のバックアップが存在する場合、それらのバックアップがダウンロードされます。
特定の時点に復元する
復元の種類として [ログ (特定の時点)] を選択した場合は、次の操作を行います。
ログ グラフから復旧ポイントを選択し、[OK] を選択して復元ポイントを選択します。
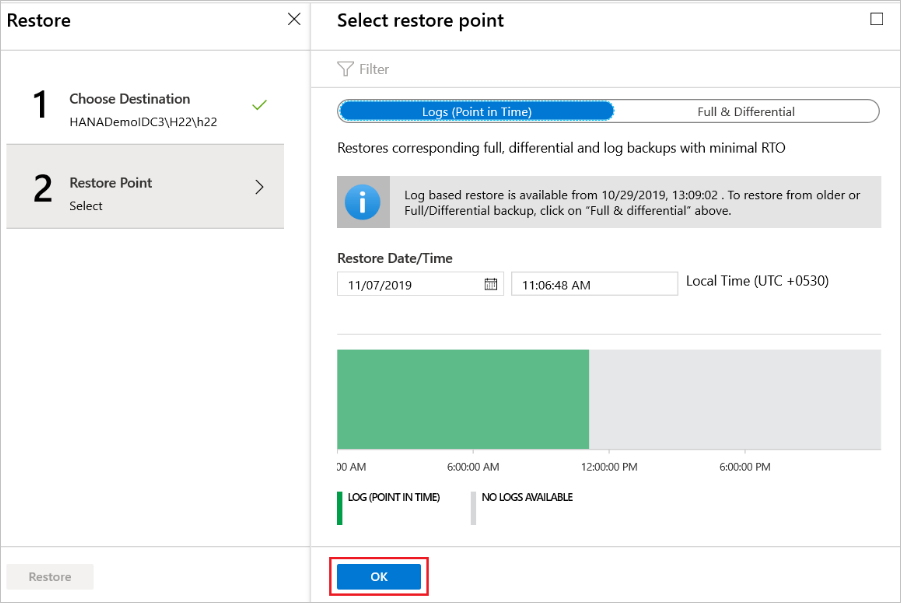
[復元] メニューで、 [復元] を選択して復元ジョブを開始します。
![[復元] メニューと [復元] ボタンを示すスクリーンショット。](media/sap-hana-db-restore/restore-restore.png)
[通知] 領域で復元の進行状況を追跡します。またはデータベース メニューの [Restore jobs](復元ジョブ) を選択して復元の進行状況を追跡します。

特定の復旧ポイントに復元する
復元の種類として [完全および差分] を選択した場合は、次の操作を行います。
一覧から復旧ポイントを選択し、[OK] を選択して復元ポイントを選択します。
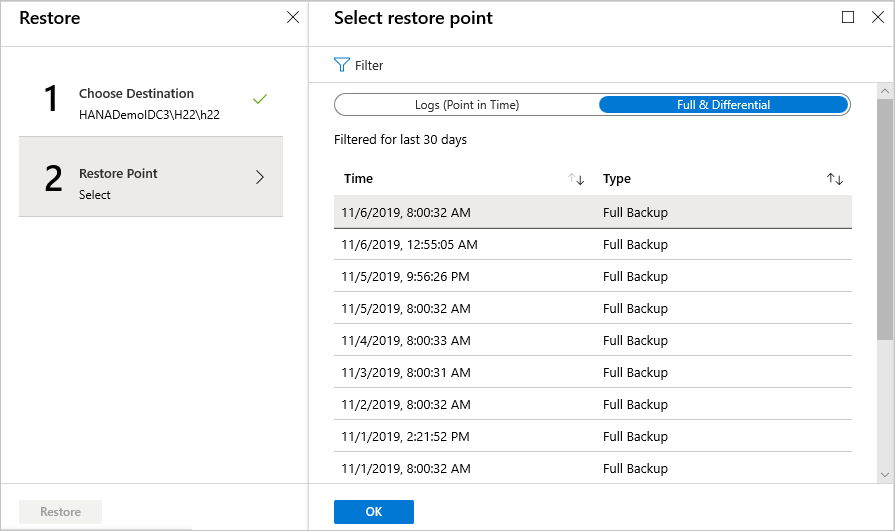
[復元] メニューで、 [復元] を選択して復元ジョブを開始します。
![特定の復元ポイントを選択するための [復元] メニューを示すスクリーンショット。](media/sap-hana-db-restore/restore-specific.png)
[通知] 領域で復元の進行状況を追跡します。またはデータベース メニューの [Restore jobs](復元ジョブ) を選択して復元の進行状況を追跡します。

Note
Multiple Database Container (MDC) の復元では、システム データベースがターゲット インスタンスに復元された後、事前登録スクリプトを再実行する必要があります。 その後、後続のテナント データベースの復元が成功します。 詳しくは、複数のコンテナー データベースの復元のトラブルシューティングに関するページを参照してください。
リージョンをまたがる復元
復元オプションの 1 つである、リージョンをまたがる復元 (CRR) を使用すると、セカンダリ リージョン (Azure のペアになっているリージョン) 内の Azure VM でホストされている SAP HANA データベースを復元できます。
この機能の使用を開始するには、「リージョンをまたがる復元の設定」を参照してください。
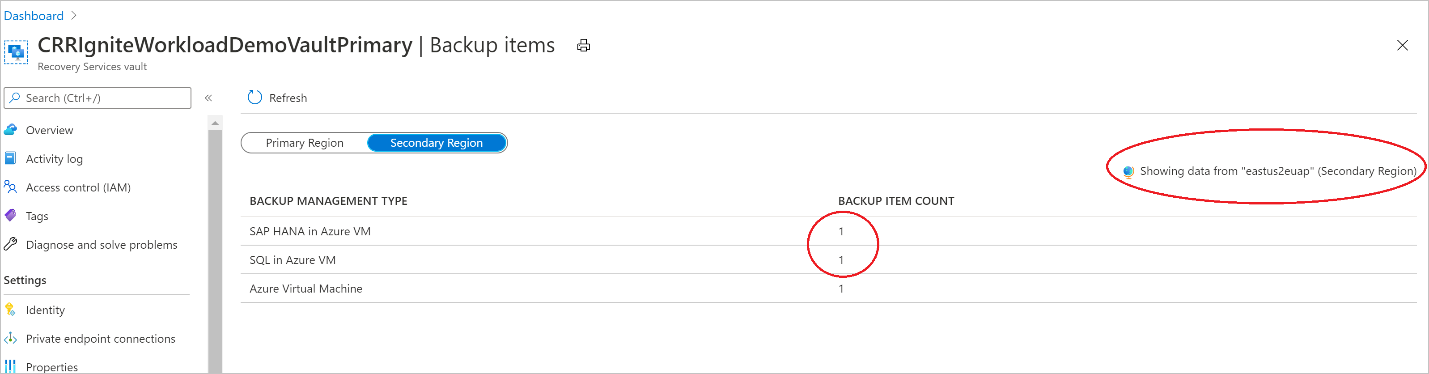
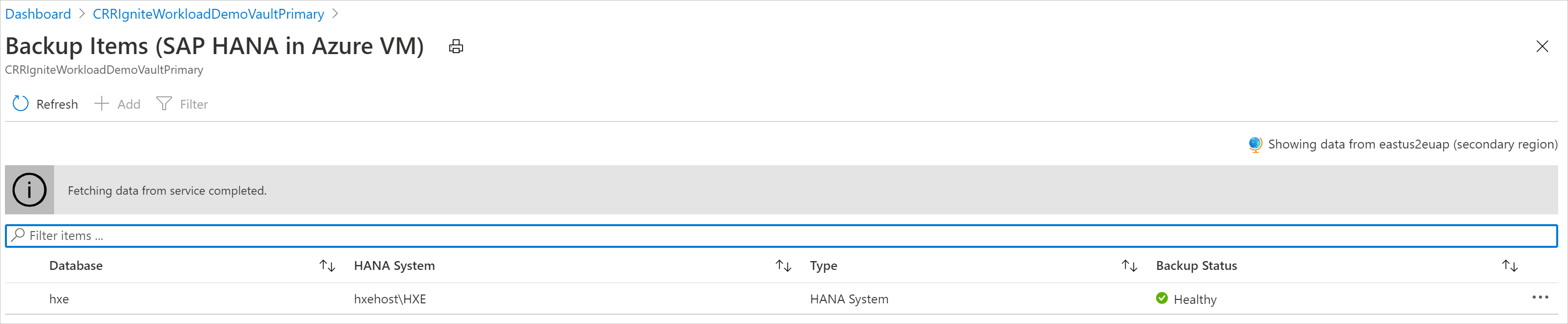
セカンダリ リージョン内のバックアップ項目を確認する
CRR が有効になっている場合は、セカンダリ リージョンのバックアップ項目を表示できます。
- Azure portal で、[Recovery Services コンテナー] に移動し、[バックアップ項目] を選択します。
- セカンダリ リージョンの項目を表示するには、 [セカンダリ リージョン] を選択します。
Note
CRR 機能をサポートするバックアップ管理の種類のみが一覧に表示されます。 現時点では、セカンダリ リージョン データをセカンダリ リージョンに復元することのみが許可されています。
セカンダリ リージョンに復元する
セカンダリ リージョンに復元するユーザー エクスペリエンスは、プライマリ リージョンに復元するユーザー エクスペリエンスに似ています。 [復元の構成] ペインで詳細を構成するとき、セカンダリ リージョンのパラメーターのみを指定するように求められます。 コンテナーがセカンダリ リージョンに存在する必要があり、また SAP HANA サーバーをセカンダリ リージョン内のコンテナーに登録する必要があります。
![[復元する場所と方法] ペインを示すスクリーンショット。](media/sap-hana-db-restore/restore-secondary-region.png)
Note
- 復元がトリガーされた後、データ転送フェーズでは、復元ジョブを取り消すことができません。
- リージョンをまたがる復元操作を実行するために必要なロールとアクセス レベルは、サブスクリプションのバックアップ オペレーター ロールと、ソースおよびターゲットの仮想マシンの共同作成者 (書き込み) アクセス権です。 バックアップ ジョブを表示する場合、バックアップ閲覧者がサブスクリプションで必要となる最低限のアクセス許可です。
- セカンダリ リージョンで使用できるバックアップ データの目標復旧時点 (RPO) は 12 時間です。 このため、CRR をオンにすると、セカンダリ リージョンの RPO は "12 時間 + ログ頻度期間" (15 分以上に設定できます) になります。
リージョンをまたがる復元の最小ロール要件について学習します。
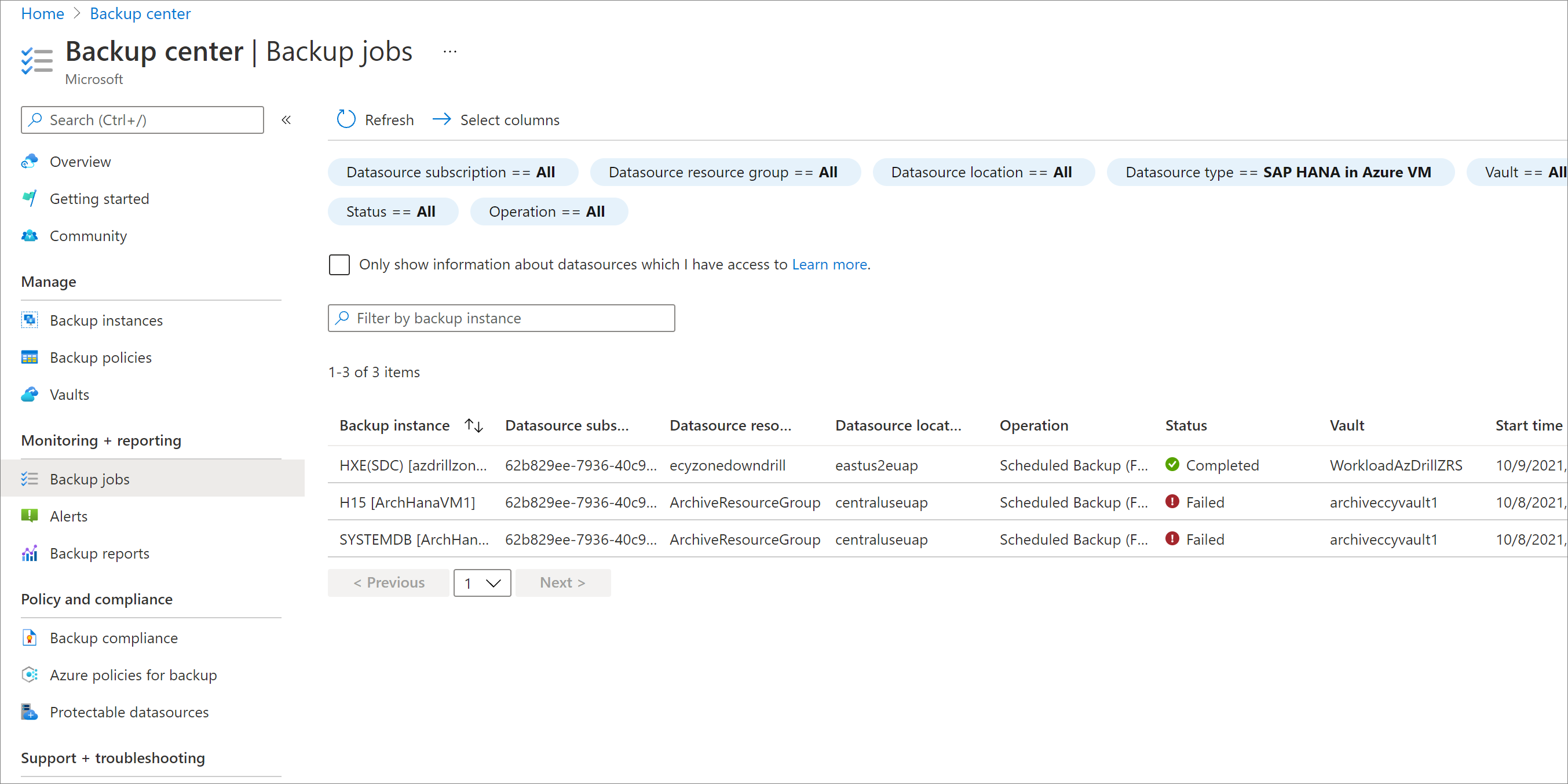
セカンダリ リージョンの復元ジョブを監視する
Azure portal で [バックアップ センター] に移動し、[バックアップ ジョブ] を選択します。
セカンダリ リージョンのジョブを表示するために、CrossRegionRestore の操作をフィルター処理します。

サブスクリプション間の復元
Azure Backup では、復元ポイントから (次の Azure RBAC 要件に従って) 任意のサブスクリプションに SAP HANA データベースを復元できるようになりました。 既定では、Azure Backup は、復元ポイントが使用可能な同じサブスクリプションに復元します。
サブスクリプション間の復元 (CSR) を使用すると、復元アクセス許可が使用可能な場合は、任意のサブスクリプションとテナントの下の任意のコンテナーに柔軟に復元できます。 既定では、CSR はすべての Recovery Services コンテナー (既存のコンテナーと新しく作成されたコンテナー) で有効になっています。
注意
- Recovery Services コンテナーからサブスクリプション間の復元をトリガーできます。
- CSR はストリーミング/Backint ベースのバックアップでのみサポートされ、スナップショット ベースのバックアップではサポートされていません。
- CSR を使用したリージョン間復元 (CRR) はサポートされていません。
プライベート エンドポイントが有効なコンテナーへのサブスクリプション間の復元
プライベート エンドポイントが有効なコンテナーへのサブスクリプション間の復元を行うには:
- "ソース Recovery Services コンテナー" で、[ネットワーク] タブに移動します。
- [プライベート アクセス] セクションに移動して、プライベート エンドポイントを作成します。
- 復元先のコンテナーの "サブスクリプション" を選びます。
- [仮想ネットワーク] セクションで、サブスクリプション全体を復元するターゲット VM の [VNet] を選びます。
- プライベート エンドポイントを作成して、復元プロセスをトリガーします。
Azure RBAC の要件
| 演算の種類 | バックアップ オペレーター | Recovery Services コンテナー | 代替オペレーター |
|---|---|---|---|
| データベースを復元する、またはファイルとして復元する | Virtual Machine Contributor |
バックアップされたソース VM | 組み込みロールではなく、次のアクセス許可を持つカスタム ロールを検討できます。 - Microsoft.Compute/virtualMachines/write - Microsoft.Compute/virtualMachines/read |
Virtual Machine Contributor |
データベースが復元される、またはファイルが作成されるターゲット VM。 | 組み込みロールではなく、次のアクセス許可を持つカスタム ロールを検討できます。 - Microsoft.Compute/virtualMachines/write - Microsoft.Compute/virtualMachines/read |
|
Backup Operator |
ターゲット Recovery Services コンテナー |
既定では、Recovery Services コンテナーでは CSR が有効になっています。 Recovery Services コンテナーの復元設定を更新するには、[プロパティ]>[サブスクリプション間の復元] に移動し、必要な変更を行います。
![HANA データベースに対する Recovery Services コンテナーの [サブスクリプション間の復元] 設定を変更する方法を示すスクリーンショット。](media/sap-hana-db-restore/cross-subscription-restore-settings-for-database.png#lightbox)
Azure CLI を使用したサブスクリプション間の復元
az backup vault create
コンテナーの作成と更新中にコンテナーの CSR 状態を設定できるようにするパラメータ cross-subscription-restore-state を追加します。
az backup recoveryconfig show
SQL または HANA データソースのサブスクリプション間復元をトリガーするときに、ターゲット サブスクリプションを入力として指定できるようにするパラメータ --target-subscription-id を追加します。
例:
az backup vault create -g {rg_name} -n {vault_name} -l {location} --cross-subscription-restore-state Disable
az backup recoveryconfig show --restore-mode alternateworkloadrestore --backup-management-type azureworkload -r {rp} --target-container-name {target_container} --target-item-name {target_item} --target-resource-group {target_rg} --target-server-name {target_server} --target-server-type SQLInstance --target-subscription-id {target_subscription} --target-vault-name {target_vault} --workload-type SQLDataBase --ids {source_item_id}