組織規模での Azure Machine Learning の予算、コスト、クォータを管理する
多くのワークロード、多くのチーム、およびユーザーを含む組織規模で、Azure Machine Learning から発生するコンピューティング コストを管理する場合、多くの管理と最適化の課題を解決する必要があります。
この記事では、Azure Machine Learning でのコストの最適化、予算の管理、クォータの共有を行うベスト プラクティスを説明します。 これは、Microsoft 内部で機械学習チームを運営し、お客様と提携した経験と教訓を反映しています。 学習内容は次のとおりです。
ワークロードの要件を満たすためにコンピューティングを最適化する
新しい機械学習プロジェクトを開始するときに、コンピューティング要件の全体像を得るために探索的な作業が必要になる場合があります。 このセクションでは、トレーニング、推論、または作業に使用するワークステーションとして、適切な仮想マシン (VM) SKU の選択を決定する方法に関する推奨事項を示します。
トレーニングのコンピューティング サイズを決定する
トレーニング ワークロードのハードウェア要件は、プロジェクトによって異なる場合があります。 これらの要件を満たすために、Azure Machine Learning コンピューティングではさまざまな種類の VM が提供されます。
- 汎用: CPU とメモリの比率のバランスが取れている。
- メモリ最適化: CPU に対してメモリの比率が高い。
- コンピューティング最適化: メモリに対して CPU の比率が高い。
- ハイ パフォーマンス コンピューティング: 実環境のさまざまな HPC ワークロードに対して、最高レベルのパフォーマンス、スケーラビリティ、コスト効率を実現する。
- GPU を使用するインスタンス: 負荷の高いグラフィックスのレンダリングやビデオ編集、ディープ ラーニングを使用したモデル トレーニングと推論 (ND) に特化した仮想マシン。
コンピューティング要件がまだわかっていない場合があります。 このシナリオでは、次のいずれかのコスト効率の高い既定のオプションから開始することをお勧めします。 これらのオプションは、軽量テスト用とトレーニング ワークロード用です。
| Type | [仮想マシンのサイズ] | 仕様 |
|---|---|---|
| CPU | Standard_DS3_v2 | 4 コア、14 ギガバイト (GB) RAM、28 GB ストレージ |
| GPU | Standard_NC6 | 6 コア、56 ギガバイト (GB) RAM、380 GB ストレージ、NVIDIA Tesla K80 GPU |
シナリオに最適な VM サイズを取得するためには、試行錯誤が必要な場合があります。 考慮する側面がいくつかあります。
- CPU が必要な場合:
- 大規模なデータセットでトレーニングする場合は、メモリ最適化 VM を使用します。
- リアルタイムの推論や待機時間の影響を受けるその他のタスクを実行する場合は、コンピューティング最適化 VM を使用します。
- トレーニング時間を短縮するために、より多くのコアと RAM を備えた VM を使用します。
- GPU が必要な場合は、VM の選択に関する情報について「GPU 最適化 VM サイズ」を参照してください。
- 分散トレーニングを行う場合は、複数の GPU を持つ VM サイズを使用します。
- 複数のノードで分散トレーニングを行う場合は、NVLink 接続を持つ GPU を使用します。
ワークロードに最適な VM の種類と SKU を選択する一方で、CPU と GPU のパフォーマンスと価格のトレードオフとして、同等の VM SKU を評価します。 コスト管理の観点から見ると、複数の SKU でのジョブの実行で十分な場合があります。
NC ファミリ、特に NC_Promo SKU などの特定の GPU は、待機時間が短く、複数のコンピューティング ワークロードを並列で管理する機能など、他の GPU と同様の機能を備えています。 他のいくつかの GPU と比較して、割引価格で利用できます。 ワークロードに対して VM SKU を思慮深く選択すると、最終的にコストが大幅に節約される可能性があります。
使用率の重要性に関する注意事項として、より多くの GPU にサインアップしても、必ずしも高速な結果で実行されるとは限りません。 代わりに、GPU が完全に使用できているか確認してください。 たとえば、NVIDIA CUDA の必要性を二重に確認します。 高パフォーマンスの GPU 実行に必要な場合があるかもしれませんが、自身のジョブでは依存する必要がない可能性があります。
推論のコンピューティング サイズを決定する
推論シナリオのコンピューティング要件は、トレーニング シナリオとは異なります。 シナリオでオフライン推論がバッチで要求されるか、オンライン推論がリアルタイムで要求されるかによって、使用可能なオプションは異なります。
リアルタイム推論のシナリオでは、次の提案を検討してください。
- Azure Machine Learning でモデルのプロファイリング機能を使用して、Web サービスとしてモデルをデプロイするときにモデルに割り当てる必要がある CPU とメモリの量を決定します。
- リアルタイム推論を実行するが、高可用性が必要ない場合は、Azure Container Instances にデプロイします (SKU を選択しない)。
- リアルタイム推論を実行し、高可用性が必要な場合は、Azure Kubernetes Service にデプロイします。
- 従来の機械学習モデルを使用し、受信が毎秒 10 クエリ未満の場合は、CPU SKU から始めます。 F シリーズ SKU は、多くの場合、うまく機能します。
- ディープ ラーニング モデルを使用し、受信が毎秒 10 クエリを超える場合は、Triton を備えた NVIDIA GPU SKU (NCasT4_v3 がうまく動作する場合が多い) を試してください。
バッチ推論のシナリオでは、次の提案を検討してください。
- バッチ推論で Azure Machine Learning パイプラインを使用する場合は、「トレーニングのコンピューティング サイズを決定する」のガイダンスに従って、初期 VM サイズを選択します。
- 水平方向にスケーリングして、コストとパフォーマンスを最適化します。 コストとパフォーマンスを最適化する主な方法の 1 つは、ワークロードの Azure Machine Learning で並列実行ステップを使用してワークロードを並列化しすることです。 このパイプライン ステップでは、多数の小さなノードを使用してタスクを並列実行でき、水平方向にスケーリングできます。 ただし、並列化にはオーバーヘッドがあります。 ワークロードと、実現できる並列処理の程度によっては、並列化がオプションになる場合と使用できない場合があります。
コンピューティング インスタンスのサイズを決定する
対話型開発の場合 Azure Machine Learning のコンピューティング インスタンスをお勧めします。 コンピューティング インスタンス (CI) オファリングでは、1 人のユーザーにバインドされ、クラウド ワークステーションとして使用できる単一ノード コンピューティングが提供されます。
一部の組織では、ローカル ワークステーションでの実稼働データの使用を禁止したり、ワークステーション環境に制限を適用したり、企業 IT 環境でのパッケージと依存関係のインストールを制限したりしています。 コンピューティング インスタンスは、制限を克服するためのワークステーションとして使用できます。 これは、実稼働データ アクセスを備えるセキュリティで保護された環境を提供し、データ サイエンス用の一般的なパッケージとツールがプレインストールされているイメージで実行されます。
コンピューティング インスタンスが実行されている場合、ユーザーは VM コンピューティング、Standard Load Balancer (lb またはアウトバウンド規則、処理済みデータを含む)、OS ディスク (Premium SSD マネージド P10 ディスク)、一時ディスク (一時ディスクの種類は選択した VM サイズによって異なります)、およびパブリック IP アドレスに対して請求されます。 コストを節約するために、ユーザーは次の点を考慮することをお勧めします。
- コンピューティング インスタンスが使用されていない場合は、起動および停止します。
- コンピューティング インスタンスでデータのサンプルに対して作業し、コンピューティング クラスターにスケールアウトして、データの完全なセットに対して作業します
- 開発中またはテスト中、またはジョブをフルスケールで送信するときに共有コンピューティング容量に切り替える場合は、コンピューティング インスタンスのローカル コンピューティング ターゲット モードで実験ジョブを送信します。 たとえば、多くのエポック、データの完全なセット、ハイパーパラメーター検索などです。
コンピューティング インスタンスを停止すると、VM コンピューティング時間、一時ディスク、および Standard Load Balancer データ処理コストの課金が停止されます。 コンピューティング インスタンスが停止した場合でも、ユーザーは引き続き OS ディスクと Standard Load Balancer に含まれる lb またはアウトバウンド規則に対して支払いを行うことに注意してください。 OS ディスクに保存されたデータは、停止と再起動によって保持されます。
コンピューティング使用率を監視して選択した VM サイズを調整する
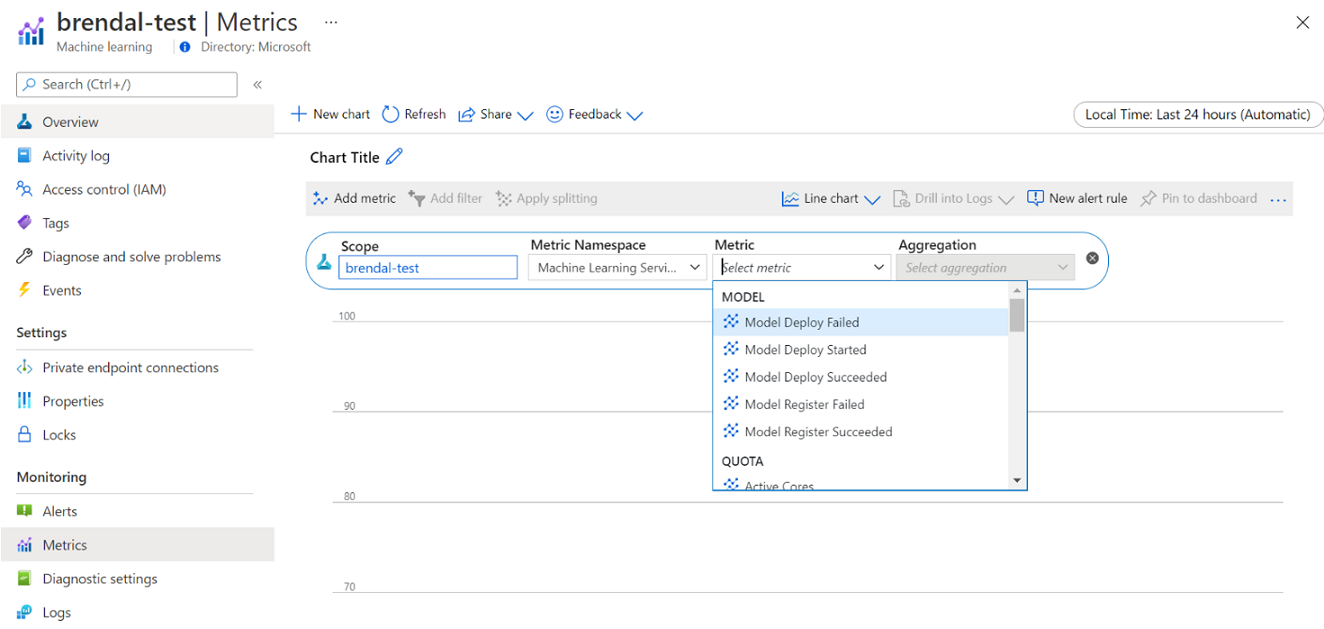
Azure Machine Learning のコンピューティングの使用状況と使用率に関する情報は、Azure Monitor を使用して表示できます。 モデル デプロイと登録、アクティブおよびアイドル ノードなどのクォータの詳細、キャンセルまたは完了した実行などの実行の詳細、GPU と CPU 使用率のコンピューティング使用率の詳細を表示できます。
監視の詳細からの分析情報に基づいて、チーム全体のリソース使用量をよりよく計画または調整できます。 たとえば、過去 1 週間に多数のアイドル 状態のノードがある場合は、対応するワークスペース所有者と協力して、この追加コストを防ぐためにコンピューティング クラスター構成を更新できます。 使用率パターンの分析の利点は、コストの予測と予算の改善に役立ちます。
これらのメトリックには、Azure portal から直接アクセスできます。 Azure Machine Learning ワークスペースに移動し、左側のパネルの [監視] セクションで [メトリック] を選択します。 次に、メトリック、集計、期間など、表示する対象の詳細を選択できます。 詳細については、「Azure Machine Learning の監視」ドキュメントページを参照してください。
開発中にローカル、単一ノード、マルチノードのクラウド コンピューティングを切り替える
機械学習ライフサイクル全体で、さまざまなコンピューティング要件とツール要件があります。 これらの要件を満たすために、必要に応じて任意のワークステーション構成から SDK および CLI インターフェイスを使用して、Azure Machine Learning を関連付けることができます。
コストを削減し、生産性をさらに高くするには、次のことをお勧めします。
- Git を使用して実験コード ベースをローカルに複製し、Azure Machine Learning SDK または CLI を使用してクラウド コンピューティングにジョブを送信します。
- データセットが大きい場合は、クラウド ストレージ上の完全なデータセットを維持しながら、ローカル ワークステーションでデータのサンプルを管理することを検討してください。
- 実験コード ベースをパラメーター化して、さまざまな数のエポックまたは異なるサイズのデータセットでジョブを実行するように構成できるようにします。
- データセットのフォルダー パスをハード コーディングしないでください。 これにより、異なるデータセットで同じコード ベースを簡単に再利用できます。また、ローカルとクラウドの実行コンテキストで再利用できます。
- 実験ジョブは、開発またはテスト中にローカル コンピューティング ターゲット モードでブートストラップします。または、ジョブをフルスケールで送信するときに共有コンピューティング クラスター容量に切り替えたときにもブートストラップします。
- データセットが大きい場合は、ローカルまたはコンピューティング インスタンス ワークステーション上のデータのサンプルを操作し、Azure Machine Learning でクラウド コンピューティングに拡張して、完全なデータセットを処理します。
- ジョブの実行に時間がかかる場合は、水平方向にスケールアウトできるように、分散トレーニングのコード ベースを最適化することを検討してください。
- ノードの弾力性のための分散トレーニング ワークロードを設計し、単一ノードとマルチ ノードのコンピューティングを柔軟に使用できるようにし、割り込まれるコンピューティングの使用を容易にします。
Azure Machine Learning パイプラインを使用したコンピューティングの種類の結合
機械学習ワークフローを調整する際には、複数の手順を含むパイプラインを定義できます。 パイプラインの各手順は、独自のコンピューティングの種類で実行できます。 これにより、機械学習のライフサイクル全体にわたってさまざまなコンピューティング要件を満たすために、パフォーマンスとコストを最適化することができます。
チームの予算を最適に使用する
予算割り当ての決定は個々のチームの制御範囲外になる場合がありますが、通常、チームは割り当てられた予算を最適なニーズに使用することができます。 チームは、ジョブの優先順位とパフォーマンスおよびコストのトレードオフを賢く実施することで、より高いクラスター使用率を実現し、全体的なコストを削減し、同じ予算からより多くのコンピューティング時間を使用することができます。 これにより、チームの生産性が向上する可能性があります。
共有コンピューティング リソースのコストを最適化する
共有コンピューティング リソースのコストを最適化するための鍵は、最大限使用されるようにすることです。 共有リソースのコストを最適化するためのヒントを次に示します。
- コンピューティング インスタンスを使用する場合は、実行するコードがあるときにのみオンにします。 使用されていないときはシャットダウンします。
- コンピューティング クラスターを使用する場合は、最小ノード数を 0 に設定し、最大ノード数を予算の制約に基づいて算出される数値に設定します。 Azure 料金計算ツールを使用して、選択した VM SKU の 1 つの VM ノードをフルに使用した場合のコストを計算します。 自動スケールを使用していない場合は、すべてのコンピューティング ノードがスケールダウンされます。 予算があるノードの数までしかスケールアップされません。 自動スケールを構成して、すべてのコンピューティング ノードをスケールダウンすることができます。
- モデルのトレーニング時に CPU 使用率や GPU 使用率などのリソース使用率を監視します。 リソースが完全に使用されていない場合は、リソースをより効率的に使用するようにコードを変更するか、小規模または安価な VM サイズにスケールダウンします。
- クラスターのスケーリング操作によるコンピューティングの非効率性を避けるため、チームの共有コンピューティング リソースを作成できるかどうかを評価します。
- 使用状況メトリックに基づいて計算クラスターの自動スケール タイムアウト ポリシーを最適化します。
- ワークスペース クォータは、個々のワークスペースからアクセスできるコンピューティング リソースの量を制御するために使用します。
複数の VM SKU 用のクラスターを作成して、スケジュールの優先順位を導入する
クォータと予算の制約の下では、チームは、重要なジョブが適時に実行されるようにし、最適な方法で予算が使用されるように、タイムリーなジョブの実行とコストのトレードオフを実行する必要があります。
最適なコンピューティング使用率をサポートするため、チームが 低優先度と専用 VM 優先度を備えたさまざまなサイズのクラスターを作成することをお勧めします。 低優先度のコンピューティングでは、Azure の余剰容量が使用されるため、割引料金が発生します。 欠点は、優先順位の高い要求が来たとき、いつでもこれらのマシンに割り込みが生じる可能性があります。
さまざまなサイズと優先度のクラスターを使用して、スケジュールの優先度の概念を導入することができます。 たとえば、実験的なジョブと実稼働ジョブが同じ NC GPU クォータに対して競合する場合、実稼働ジョブは実験用のジョブに優先して実行されるように設定されている可能性があります。 その場合、専用のコンピューティング クラスターで実稼働ジョブを実行し、低優先度のコンピューティング クラスターで実験用のジョブを実行します。 クォータが足りない場合、実稼働ジョブが優先され、試験的なジョブが割り込まれます。
VM の優先度の次に、さまざまな VM SKU でジョブを実行することを検討します。 P40 GPU を使用する VM インスタンスでは、V100 GPU よりもジョブの実行時間が長くなることがあります。 ただし、V100 VM インスタンスが占有されているか、クォータが完全に使用されている可能性があるため、P40 での完了までの時間の方が、ジョブのスループットの観点から高速になる可能性があります。 また、コスト管理の観点から、低パフォーマンスで低コストの VM インスタンスで、優先度の低いジョブを実行することも検討してください。
トレーニングが収束しないときに実行を早期終了する
モデルをそのベースラインに対して継続的に改善するために、それぞれ構成を若干変えて、さまざまな実験を実行することがあります。 1 回の実行では、入力データセットを微調整するかもしれません。 別の実行では、ハイパー パラメーターを変更するかもしれません。 すべての変更が、他の変更と同じように有効であるとは限りません。 変更してもモデルトレーニングの品質に対して意図した影響がなかったことを早期に検出できます。 トレーニングが収束していないかどうかを検出するには、実行中のトレーニングの進行状況を監視します。 たとえば、各トレーニング エポックの後にパフォーマンス メトリックをログに記録します。 ジョブを早期に終了して別の評価を行えるよう、リソースと予算を解放することを検討します。
予算、コスト、およびクォータを計画、管理、および共有する
機械学習のユースケースやチームの数が増えるにつれて、効率的な操作を実現するために、IT および財務部門の運用の成熟度の向上と、個々の機械学習チーム間の調整が必要になります。 企業規模の容量とクォータの管理は、コンピューティング リソースの不足を解決し、管理オーバーヘッドを克服するために重要になります。
このセクションでは、エンタープライズ規模での予算、コスト、およびクォータの計画、管理、および共有に関するベストプラクティスについて説明します。 Microsoft 内部で、機械学習のために多くの GPU トレーニング リソースを管理していることから得た学びに基づいています。
Azure Machine Learning を使用したリソースの消費量について
コンピューティング ニーズを計画する際の管理者として最も大きな課題の 1 つは、ベースライン予測として過去の情報がない状態で開始することです。 実務的には、ほとんどのプロジェクトは最初のステップとして小規模な予算から開始されます。
予算がどうなるかを把握するには、Azure Machine Learning コストの発生元を把握しておくことが重要です。
- Azure Machine Learning では、使用されるコンピューティング インフラストラクチャの料金のみが課金対象となり、コンピューティング コストに対する追加料金はかかりません。
- Azure Machine Learning ワークスペースが作成されると、他にもいくつかのリソースが作成され、Azure Machine Learning が有効になります (Key Vault、Application Insights、Azure Storage、Azure Container Registry)。 これらのリソースは Azure Machine Learning で使用され、これらのリソースに対して課金されます。
- トレーニング クラスター、コンピューティング インスタンス、マネージド推論エンドポイントなど、マネージド コンピューティングに関連するコストがあります。 これらの管理されたコンピューティング リソースを使用する場合、ストレージに関して、仮想マシン、仮想ネットワーク、ロード バランサー、帯域幅などのインフラストラクチャ コストを考慮する必要があります。
タグを使用して支出パターンを追跡し、より適切なレポートを実現する
管理者は、Azure Machine Learning のさまざまなリソースのコストを追跡できるようにしたいと思うことがよくあります。 タグ付けは、この問題に対する自然な解決策であり、Azure や他の多くのクラウド サービス プロバイダーによって使用される一般的なアプローチと一致します。 タグのサポートにより、コンピューティング レベルでコストの明細を確認できるようになったため、より詳細なビューにアクセスして、コストの監視、レポートの改善、透明性の向上を支援できます。
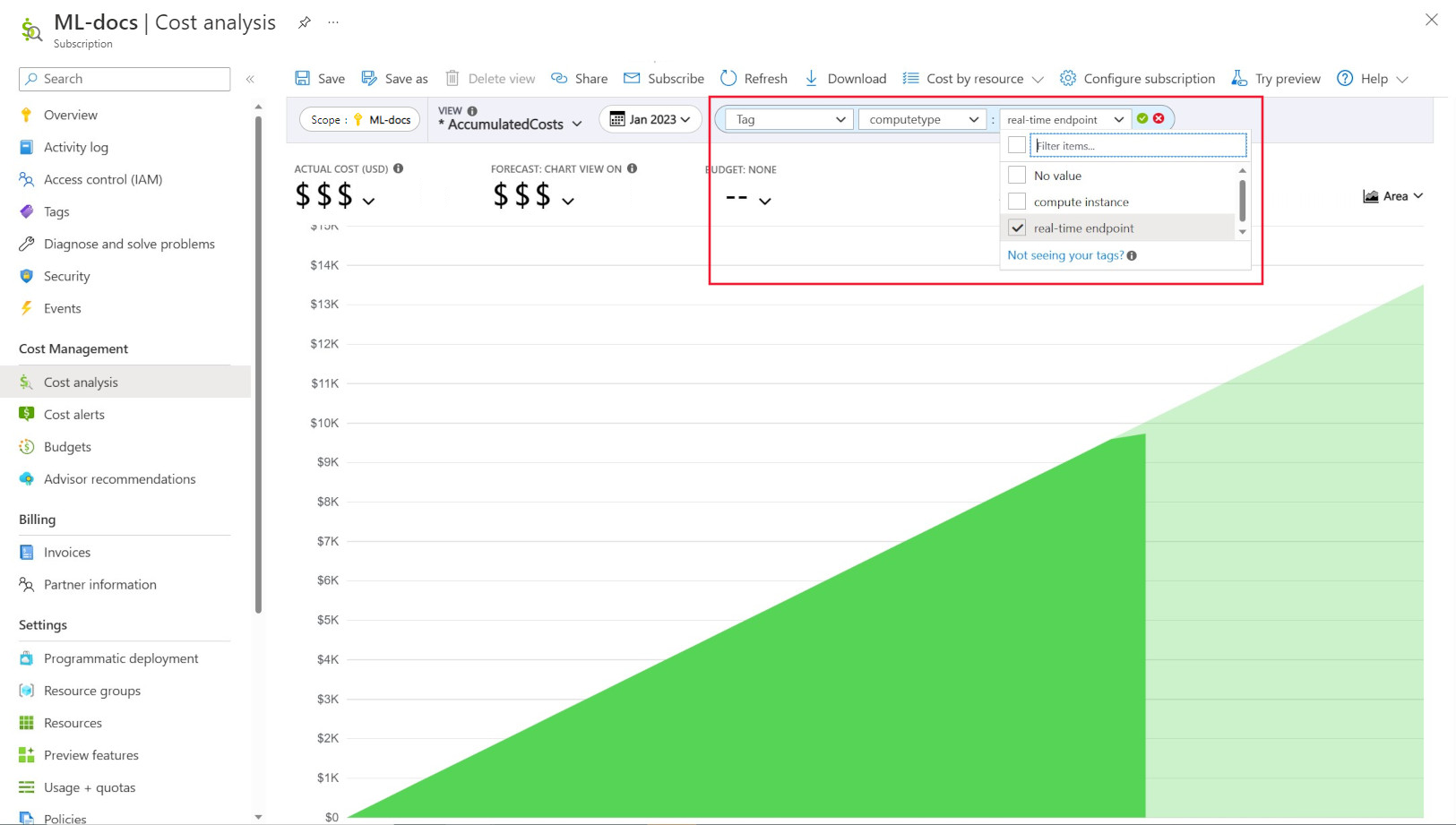
タグ付けを使うと、ワークスペースとコンピューティングに (Azure Resource Manager テンプレートと Azure Machine Learning スタジオから) カスタマイズされたタグを配置し、これらのタグに基づいて Microsoft Cost Management でこれらのリソースをさらにフィルター処理し、支出パターンを観察できます。 この機能は、内部のチャージバックのシナリオに使うと最適です。 さらに、タグは、プロジェクト、チーム、特定の請求コードなど、コンピューティングに関連付けられているメタデータや詳細をキャプチャするのに役立ちます。 これにより、タグ付けは、さまざまなリソースにかかっている金額を計算するのに非常に役立ちます。そのため、チームやプロジェクト全体のコストと支出パターンに関するより深い洞察を得ることができます。
また、コンピューティングにはシステム挿入タグも配置されており、それを使うと、[コスト分析] ページで "コンピューティングの種類" タグによりフィルター処理を行って、総支出のコンピューティングごとの内訳を確認し、コストの大部分に関係している可能性があるコンピューティング リソースのカテゴリを判断できます。 これは、トレーニングと推論を比較したコスト パターンの理解を深めるのに特に便利です。
ポリシーによるコンピューティング使用状況の制御と制限
多くのワークロードを含む Azure 環境を管理する場合、リソースの消費の全体像を維持することが困難な場合があります。 Azure Policy は、Azure 環境全体で特定の使用パターンを制限することで、リソースの消費量を制御し、管理するのに役立ちます。
具体的には Azure Machine Learning で、特定の VM SKU の使用のみを許可するようにポリシーを設定することをお勧めします。 ポリシーを使用すると、高価な VM の選択を防止し、制御することができます。 ポリシーを使用して、優先順位の低い VM SKU の使用を強制することもできます。
ビジネスの優先度に基づいてクォータを割り当てて管理する
Azure では、サブスクリプションおよび Azure Machine Learning ワークスペース レベルに対するクォータ割り当ての制限を設定することができます。 Azure のロールベースのアクセス制御 (RBAC) を使用してクォータを管理できるユーザーを制限すると、リソースの使用率とコストの予測可能性を確保するのに役立ちます。
GPU クォータの可用性は、サブスクリプション全体では十分ではない可能性があります。 ワークロード全体で高いクォータ使用率を確保するために、クォータが最適に使用されているか、ワークロード全体に割り当てられているかどうかを監視することをお勧めします。
Microsoft では、ビジネスの優先度に対するキャパシティ ニーズを評価することによって、GPU クォータが最適に使用され、機械学習チーム間で割り当てられるかどうかを定期的に決定しています。
容量を事前にコミットする
次の年または今後数年間に使用されるコンピューティングの量を十分に見積もることができる場合は、Azure Reserved VM Instances を割引料金で購入できます。 1 年間または 3 年間の購入期間があります。 Azure Reserved VM Instances は割引されるため、従量課金制の料金と比較して大幅なコスト削減ができる可能性があります。
Azure Machine Learning では、予約済みコンピューティング インスタンスがサポートされています。 割引は Azure Machine Learning マネージド コンピューティングに自動的に適用されます。
データ保有期間を管理する
機械学習パイプラインを実行するたび、データのキャッシュと再利用のために各パイプライン ステップで中間データセットを生成できます。 これらの機械学習パイプラインの出力としてのデータの増加は、機械学習の実験を多く実行している組織にとって、問題点になる可能性があります。
一般に、データ サイエンティストは、生成される中間データセットのクリーンアップに時間を費やすことはありません。 時間の経過と共に、生成されるデータの量が加算されていきます。 Azure Storage には、データ ライフサイクルの管理を強化する機能が用意されています。 Azure Blob Storage ライフサイクル管理を使用すると、使用されていないデータをよりコールドなストレージ層に移動する、コストを節約するための一般的なポリシーを設定できます。
インフラストラクチャ コストの最適化に関する考慮事項
ネットワーク
Azure ネットワーク コストは、Azure データ センターからの送信帯域幅から発生します。 Azure データセンターへの受信データはすべて無料です。 ネットワーク コストを削減する鍵は、可能な限りすべてのリソースを同じデータセンター リージョンにデプロイすることです。 Azure Machine Learning ワークスペースとコンピューティングをデータがあるリージョンにデプロイできる場合は、コストを削減し、パフォーマンスを向上させることができます。
ハイブリッド クラウド環境を使用するには、オンプレミス ネットワークと Azure ネットワークの間にプライベート接続を使用した方が良い場合があります。 ExpressRoute ではこれを行えますが、ExpressRoute の高コストを考慮すると、ハイブリッド クラウドのセットアップから移行し、すべてのリソースを Azure クラウドに移動する方がコスト効率が高い場合があります。
Azure Container Registry
Azure Container Registry の場合、コストの最適化の決定要因は次のとおりです。
- コンテナー レジストリから Azure Machine Learning への Docker イメージのダウンロードに必要なスループット
- Azure Private Link などのエンタープライズ セキュリティ機能の要件
高スループットまたはエンタープライズ セキュリティが必要な実稼働シナリオでは、Azure Container Registry の Premium SKU の使用をお勧めします。
スループットとセキュリティがそれほど重要ではない Dev/Test シナリオの場合は、Standard SKU または Premium SKU をお勧めします。
Azure Machine Learning には、Azure Container Registry の Basic SKU はお勧めしません。 スループットが低く、含まれるストレージが少ないので、Azure Machine Learning の比較的大きなサイズ (1 GB 以上) の Docker イメージによって、すぐに超過する可能性があります。
Azure リージョンを選択するときに、コンピューティングの種類の可用性を検討する
コンピューティングのリージョンを選択する場合は、コンピューティング クォータの可用性に関する情報を念頭に置きます。 米国東部、米国西部、西ヨーロッパなどの一般的で大規模なリージョンでは、容量制限が厳しい他のリージョンと比較して、既定のクォータ値が高く、ほとんどの CPU と GPU の可用性が向上する傾向があります。
詳細情報
クラウド導入フレームワークを使用して、事業単位、環境、またはプロジェクト全体のコストを追跡する
次のステップ
Azure Machine Learning 環境を整理および設定する方法の詳細については、「Azure Machine Learning 環境の整理とセットアップ」を参照してください。
Azure Machine Learning を使用した機械学習 DevOps のベストプラクティスに関する詳細については、「機械学習の DevOps ガイド」を参照してください。