AI/ML ドメイン駆動型の特徴エンジニアリング用のデータ メッシュを運用化する
データ メッシュは、一元化されたデータ レイクまたはデータ ウェアハウスから、分析データのドメイン駆動型の分散化に組織が移行するのに役立ちます。これは、4 つの原則 (ドメイン所有権、製品としてのデータ、セルフサービス データ プラットフォーム、フェデレーション計算ガバナンス) によって明確に示されます。 データ メッシュは、分散データ所有権の利点と、組織のビジネスおよび価値実現までの時間短縮を促進するデータ品質およびガバナンスの向上をもたらします。
データ メッシュの実装
一般的なデータ メッシュの実装には、データ パイプラインを構築するデータ エンジニアがいるドメイン チームが含まれます。 チームは、データ レイク、データ ウェアハウス、データ レイクハウスなどの運用および分析データ ストアを維持します。 パイプラインは、他のドメイン チームやデータ サイエンス チームが使用するデータ製品としてリリースされます。 他のチームは、次の図に示すように、中央データ ガバナンス プラットフォームを利用してデータ製品を使用します。
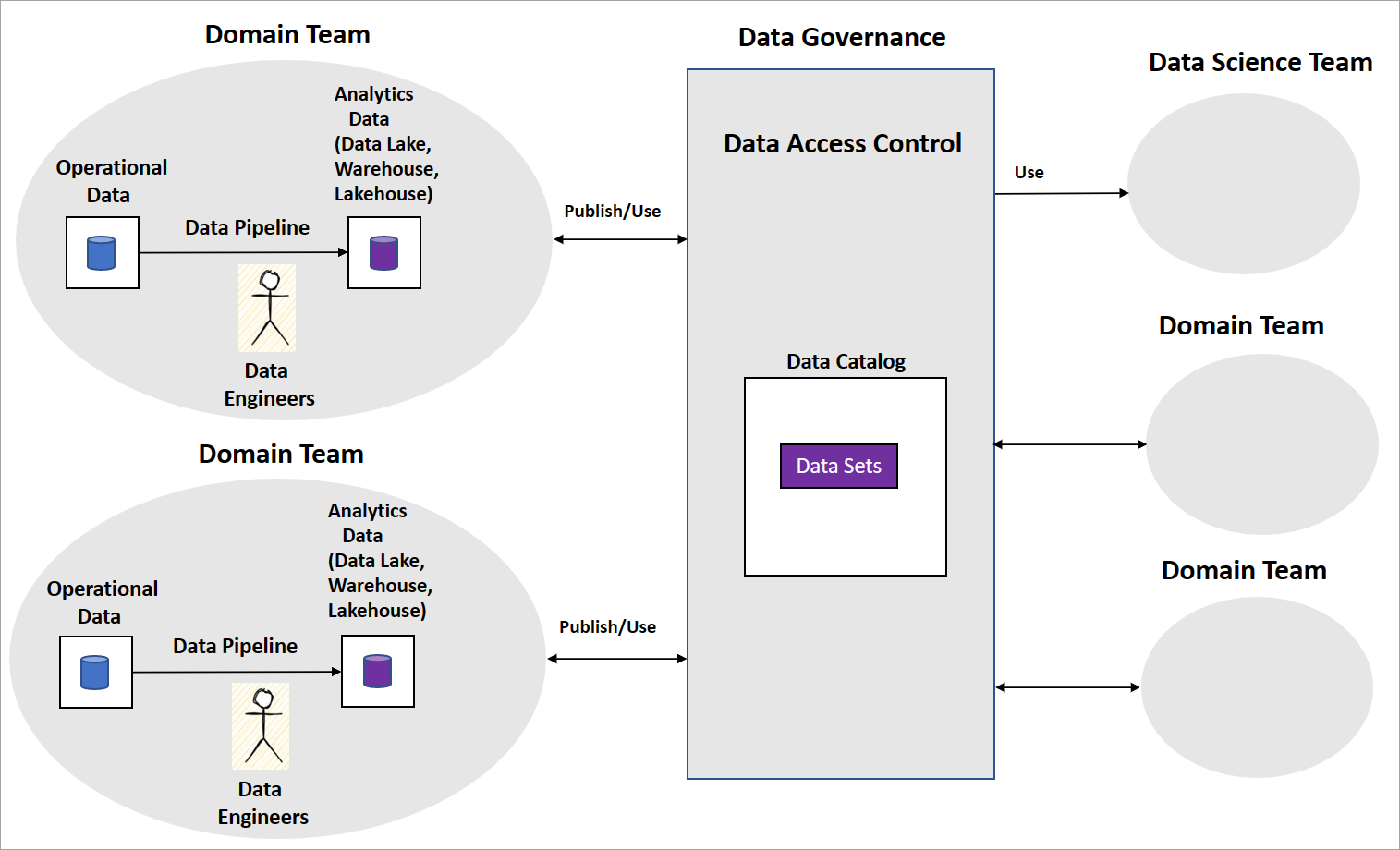
データ メッシュでは、データ製品がビジネス インテリジェンスのために変換および集計されたデータ セットを処理する方法については明確です。 一方で、AI/ML モデルを構築するために組織が取るべきアプローチについては明確ではありません。 また、データ サイエンス チームを構築する方法、AI/ML モデル ガバナンス、およびドメイン チーム間で AI/ML モデルまたは特徴を共有する方法に関するガイダンスもありません。
次のセクションでは、データ メッシュ内で AI/ML 機能を開発するために組織で使用できるいくつかの戦略について説明します。 また、ドメイン駆動型特徴エンジニアリングまたは特徴メッシュに関する戦略について提案します。
データ メッシュの AI/ML 戦略
一般的な戦略の 1 つは、組織がデータ コンシューマーとしてデータ サイエンス チームを採用することです。 これらのチームは、ユース ケースに従って、データ メッシュ内のさまざまなドメイン データ製品を利用します。 データ探索と特徴エンジニアリングを実行して、AI/ML モデルを開発および構築します。 場合によっては、ドメイン チームは、データや他のチームのデータ製品を使用して新しい特徴を拡張および派生させることで、独自の AI/ML モデルも開発します。
特徴エンジニアリングはモデル構築の中核であり、複雑になりがちで、ドメインの専門知識が求められます。 データ サイエンス チームがさまざまなデータ製品を分析する必要があるため、上記の戦略には時間がかかる場合があります。 高品質の特徴を構築するためのドメインに関する専門知識がない場合もあります。 ドメインの専門知識が不足すると、ドメイン チーム間で特徴エンジニアリングの作業が重複する恐れがあります。 また、チーム間の特徴セットに一貫性がなくなるため、AI/ML モデルの再現性などの問題も発生します。 データ サイエンスまたはドメイン チームは、新しいバージョンのデータ製品がリリースされると、継続的に特徴を更新する必要があります。
もう 1 つの戦略は、ドメイン チームが Open Neural Network Exchange (ONNX) のような形式で AI/ML モデルをリリースすることですが、その結果はブラック ボックスであり、ドメイン間で AI/モデルまたは特徴を組み合わせるのは困難です。
課題に対処するために、ドメインおよびデータ サイエンスのチーム全体で AI/ML モデル構築を分散化する方法はありますか? 提案されたドメイン駆動型の特徴エンジニアリングまたは特徴メッシュ戦略が 1 つの選択肢です。
ドメイン駆動型の特徴エンジニアリングまたは特徴メッシュ
ドメイン駆動型の特徴エンジニアリングまたは特徴メッシュ戦略では、データ メッシュ設定において AI/ML モデル構築に対する分散型アプローチが提供されます。 次の図では、この戦略と、それによってデータ メッシュの 4 つの主要な原則にどのように対処するかを示しています。
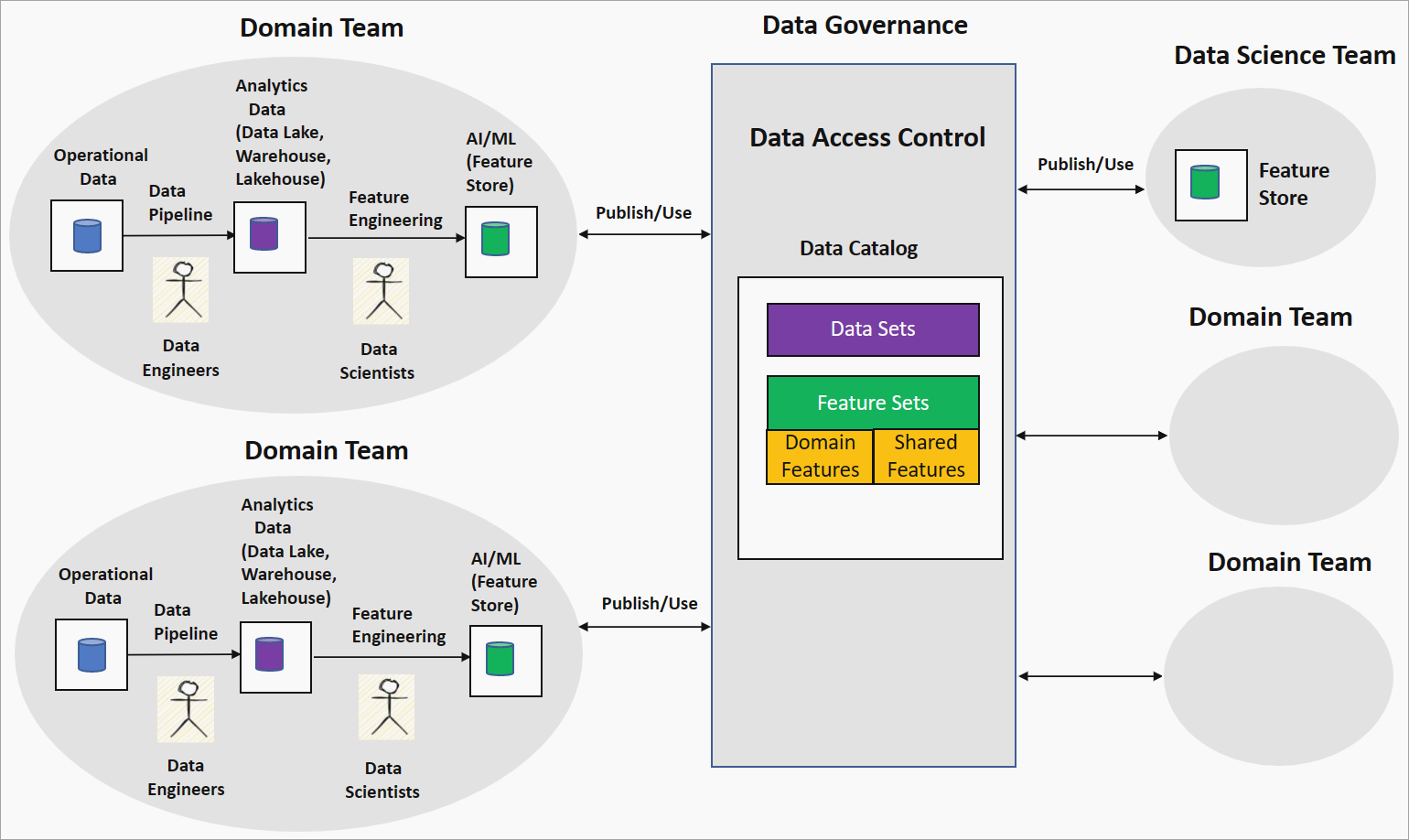
ドメイン チームによるドメイン所有権の特徴エンジニアリング
この戦略では、組織はドメイン チームのデータ サイエンティストとデータ エンジニアをペアにして、クリーンで変換されたデータ (データ レイクなど) でデータ探索を実行します。 エンジニアリングでは、特徴ストアに格納される特徴が生成されます。 特徴ストアは、トレーニングと推論のための特徴を提供し、特徴のバージョン、メタデータ、統計を追跡するのに役立つデータ リポジトリです。 この機能により、ドメイン チームのデータ サイエンティストはドメイン エキスパートと緊密に連携し、ドメイン内のデータ変更に応じて特徴を最新の状態に保つことができます。
製品としてのデータ: 特徴セット
ドメイン チームによって生成された特徴は、ドメインまたはローカルの特徴と呼ばれ、データ ガバナンス プラットフォームのデータ カタログに特徴セットとして発行されます。 これらの特徴セットは、データ サイエンス チームや他のドメイン チームが AI/ML モデルを構築するために使用できます。 AI/ML モデルの開発中、データ サイエンスまたはドメイン チームは、ドメインの特徴を組み合わせて、共有またはグローバルの特徴と呼ばれる新しい特徴を生成できます。 これらの共有された特徴は、使用するために特徴セット カタログに発行されます。
セルフサービス データ プラットフォームとフェデレーション計算ガバナンス: 特徴の標準化と品質
この戦略により、特徴エンジニアリング パイプラインごとに異なるテクノロジ スタックが採用され、ドメイン チーム間で一貫性のない特徴定義が採用される場合があります。 セルフサービス データ プラットフォームの原則により、ドメイン チームは共通のインフラストラクチャとツールを使用して、特徴エンジニアリング パイプラインを構築し、アクセス制御を適用します。 フェデレーション計算ガバナンスの原則により、グローバルな標準化と特徴品質のチェックを通じて、特徴セットの相互運用性が保証されます。
ドメイン駆動型の特徴エンジニアリングまたは特徴メッシュ戦略を使用すると、組織が AI/ML モデルを開発する時間を短縮するのに役立つ分散型 AI/ML モデル構築アプローチが提供されます。 この戦略は、ドメイン チーム間で特徴の一貫性を維持するのに役立ちます。 これにより、作業の重複が回避され、より正確な AI/ML モデルの高品質な特徴が得られ、ビジネスの価値が向上します。
Azure でのデータ メッシュの実装
この記事では、データ メッシュでの AI/ML の運用に関する概念について説明しますが、これらの戦略を構築するためのツールやアーキテクチャについては説明しません。 Azure には、Azure Databricks 特徴ストアや LinkedIn の Feathr などの特徴ストア オファリングがあります。 Microsoft Purview カスタム コネクタを開発して、特徴ストアを管理および統制できます。