Azure Cosmos DB 分析ストアとは
適用対象: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Gremlin
Gremlin
重要
Microsoft Fabric での Azure Cosmos DB のミラーリングが、NoSql API で利用できるようになりました。 この機能により、Azure Synapse Link のすべての機能が提供され、分析パフォーマンスが向上し、データ資産と Fabric OneLake の統合および Delta Parquet 形式のデータへのアクセスができるようになります。 Azure Synapse Link を検討している場合は、ミラーリングを試して、組織への全体的な適合性を評価することをお勧めします。 Microsoft Fabric でのミラーリングを開始する。
Azure Synapse Link の使用を開始するには、「Azure Synapse Link の使用を開始する」を参照してください
Azure Cosmos DB の分析ストアは、トランザクション ワークロードに影響を与えることなく、Azure Cosmos DB 内の運用データに対する大規模な分析を可能にするための、完全に分離された列ストアです。
Azure Cosmos DB のトランザクション ストアはスキーマに依存せず、スキーマやインデックスを管理する必要なしに、アプリケーション上で反復処理を実行できます。 これに対し、Azure Cosmos DB の分析ストアは、分析クエリのパフォーマンスを最適化するためにスキーマ化されています。 この記事では、分析ストレージについて詳しく説明します。
運用データでの大規模な分析に関する課題
Azure Cosmos DB コンテナー内のマルチモデルの運用データは、インデックス付きの行ベースの "トランザクション ストア" に内部的に格納されます。 行ストアの形式は、ミリ秒単位の応答時間での高速なトランザクションの読み取りと書き込み、および操作クエリで実行できるように、設計されています。 ご利用のデータセットのサイズが大きくなると、この形式で格納されているデータに対する複雑な分析クエリでは、プロビジョニングされたスループットに関するコストが高くなる可能性があります。 プロビジョニングされたスループットが大量に消費されると、リアルタイムのアプリケーションやサービスによって使用されるトランザクション ワークロードのパフォーマンスに影響します。
従来は、大量のデータを分析するには、オペレーショナル データが Azure Cosmos DB のトランザクション ストアから抽出されて、別のデータ レイヤーに格納されます。 たとえば、データは適切な形式のデータ ウェアハウスやデータ レイクに格納されます。 その後、このデータは大規模な分析に使用され、Apache Spark クラスターなどのコンピューティング エンジンを使用して分析されます。 運用データから分析を分離すると、最新のデータを使用する必要があるアナリストにとって遅延が発生します。
また、オペレーショナル データの更新を処理する場合は、新しく取り込まれたオペレーショナル データだけを処理する場合と比較して、ETL パイプラインも複雑になります。
列指向の分析ストア
Azure Cosmos DB の分析ストアでは、従来の ETL パイプラインで発生する複雑さと待機時間の問題が対処されています。 Azure Cosmos DB の分析ストアでは、オペレーショナル データを別の列ストアに自動的に同期させることができます。 列ストアの形式は、最適化された方法で実行される大規模な分析クエリに適しているため、このようなクエリの待機時間が向上します。
Azure Synapse Link を使用すると、Azure Synapse Analytics から Azure Cosmos DB の分析ストアに直接リンクすることで、ETL なしの HTAP ソリューションを構築できます。 これにより、オペレーショナル データに対してほぼリアルタイムの大規模な分析を実行できます。
分析ストアの機能
Azure Cosmos DB コンテナーで分析ストアを有効にすると、コンテナー内のオペレーショナル データに基づいて、新しい列ストアが内部的に作成されます。 この列ストアは、そのコンテナーの行指向トランザクション ストアとは別に、Azure Cosmos DB によって完全に管理されているストレージ アカウント内の内部サブスクリプションに保持されます。 お客様は、ストレージ管理に時間を費やす必要はありません。 オペレーショナル データに対する挿入、更新、削除は、分析ストアに自動的に同期されます。 データを同期するために変更フィードや ETL は必要ありません。
オペレーショナル データに対する分析ワークロードでの列ストア
通常、分析ワークロードには、選択したフィールドの集計と順次スキャンが含まれます。 データ分析ストアは、列メジャー順に格納され、必要に応じて各フィールドの値を一緒にシリアル化できます。 この形式を使用すると、特定のフィールドのスキャンまたは統計計算に必要な IOPS が減少します。 大きなデータ セットに対するスキャンのクエリ応答時間が大幅に向上します。
たとえば、オペレーショナル テーブルが次のような形式になっているとします。
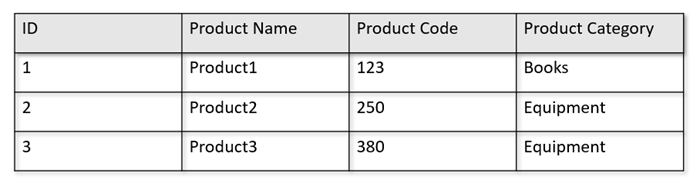
行ストアでは、上記のデータが、行ごとにシリアル化された形式で、ディスクに保持されます。 この形式を使用すると、トランザクションの読み取り、書き込み、操作クエリ ("製品 1 に関する情報の取得" など) を高速化できます。 ただし、データセットが大きくなるため、データに対して複雑な分析クエリを実行する場合は、コストが高くなる可能性があります。 たとえば、"異なる事業単位と月についての、'機材' というカテゴリに属する製品の売上動向" を取得するには、複雑なクエリを実行する必要があります。 このデータセットの大規模なスキャンでは、プロビジョニングされたスループットに関して高コストになる可能性があり、リアルタイムのアプリケーションやサービスに利用されるトランザクション ワークロードのパフォーマンスにも影響する場合があります。
列ストアである分析ストアは、類似したデータのフィールドがまとめてシリアル化され、ディスクの IOPS が減るため、そのようなクエリに適しています。
次の図では、Azure Cosmos DB でのトランザクション行ストアと分析列ストアの比較を示します。
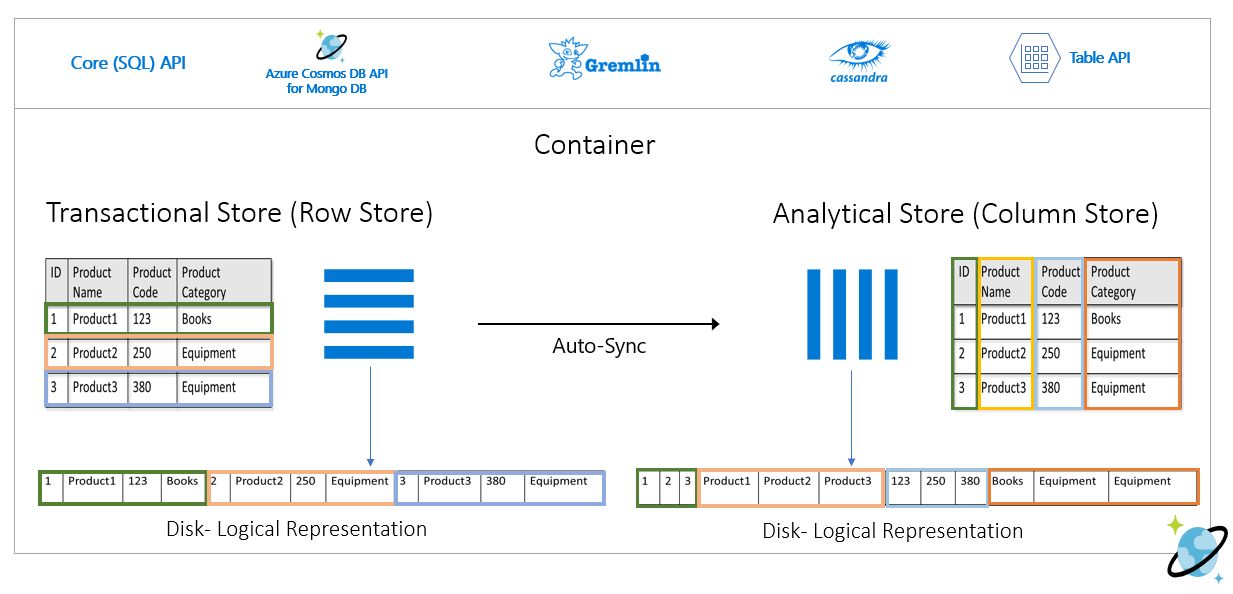
分析ワークロードの分離されたパフォーマンス
分析ストアはトランザクション ストアとは別のものであるため、分析クエリが原因でトランザクション ワークロードのパフォーマンスが影響を受けることはありません。 要求ユニット (RU) を分析ストアのために別に割り当てる必要はありません。
自動同期
自動同期とは、Azure Cosmos DB の完全に管理された機能のことであり、オペレーショナル データの挿入、更新、削除が、ほぼリアルタイムでトランザクション ストアから分析ストアに自動的に同期されます。 自動同期の待機時間は通常 2 分以内です。 コンテナーを多数備えた共有スループット データベースの場合は、個々のコンテナーの自動同期の待機時間が長くなり、最大で 5 分かかる可能性があります。
自動同期プロセスの各実行の終了時に、トランザクション データがすぐに Azure Synapse Analytics ランタイムで使用できるようになります。
Azure Synapse Analytics Spark プールは、自動的に更新される Spark テーブルを通じて、または常にデータの最後の状態を読み取る
spark.readコマンドを介して、最新の更新を含むすべてのデータを読み取ることができます。Azure Synapse Analytics SQL サーバーレス プールは、自動的に更新されるビューを通じてまたは常にデータの最新の状態を読み取る
OPENROWSETコマンドと一緒にSELECTを介して、最新の更新を含むすべてのデータを読み取ることができます。
Note
トランザクション データは、トランザクション TTL が 2 分より短い場合でも、分析ストアと同期されます。
Note
コンテナーを削除すると、分析ストアも削除されることにご注意ください。
スケーラビリティと弾力性
Azure Cosmos DB のトランザクション ストアは、行方向のパーティション分割を使用して、ダウンタイムなしでストレージとスループットを弾力的にスケーリングできます。 トランザクション ストアでの行方向のパーティション分割を使うと、自動同期のスケーラビリティと弾力性が提供され、データがほぼリアルタイムで分析ストアに同期されます。 データの同期は、トランザクション トラフィックのスループットが 1000 操作/秒または 100 万操作/秒のいずれであっても行われ、トランザクション ストアにプロビジョニングされたスループットには影響しません。
スキーマの更新を自動的に処理する
Azure Cosmos DB のトランザクション ストアはスキーマに依存せず、スキーマやインデックスを管理する必要なしに、アプリケーション上で反復処理を実行できます。 これに対し、Azure Cosmos DB の分析ストアは、分析クエリのパフォーマンスを最適化するためにスキーマ化されています。 Azure Cosmos DB では、自動同期機能により、トランザクション ストアからの最新の更新に対するスキーマの推論が管理されます。 また、入れ子になったデータ型の処理を含む、すぐに使用できる分析ストアのスキーマ表現も管理されます。
スキーマが進化し、新しいプロパティが時間と共に追加されると、分析ストアにより、トランザクション ストア内のすべての履歴スキーマに対して、統合されたスキーマが自動的に提供されます。
Note
分析ストアのコンテキストでは、次の構造がプロパティと見なされます。
- JSON の "要素" または "
:で区切られた文字列/値のペア"。 {と}で区切られた JSON オブジェクト。[と]で区切られた JSON 配列。
スキーマの制約
次の制約は、分析ストアでスキーマを自動的に推論して正しく表すことができるようにするときに、Azure Cosmos DB 内のオペレーショナル データに適用されます。
ドキュメント スキーマの各入れ子レベルでの最大プロパティ数は 1,000 個であり、入れ子の深さの最大値は 127 です。
- 分析ストアでは、最初の 1,000 個のプロパティのみが表示されます。
- 分析ストアでは、最初の 127 個の入れ子のレベルのみが表示されます。
- JSON ドキュメントの最初のレベルは、その
/ルート レベルです。 - ドキュメントの最初のレベルのプロパティは、列として表示されます。
サンプル シナリオ:
- ドキュメントの最初のレベルに 2,000 個のプロパティがある場合、同期プロセスで最初の 1,000 個が表示されます。
- ドキュメントに 5 つのレベルがあり、それぞれ 200 個のプロパティが含まれる場合は、同期プロセスですべてのプロパティが表示されます。
- ドキュメントに 10 のレベルがあり、それぞれ 400 個のプロパティが含まれる場合は、同期プロセスは 2 つの最初のレベルを完全に表示し、3 番目のレベルの半分のみを表示します。
以下の架空のドキュメントには、4 個のプロパティと 3 つのレベルが含まれています。
- レベルは
rootとmyArrayで、myArray内では入れ子構造になっています。 - プロパティは
id、myArray、myArray.nested1、myArray.nested2です。 - 分析ストア表現には、
idとmyArrayの 2 つの列があります。 Spark または T-SQL 関数を使用して、入れ子構造を列として公開することもできます。
- レベルは
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
JSON ドキュメント (および Azure Cosmos DB コレクション/コンテナー) では一意性の観点から大文字と小文字が区別されますが、分析ストアでは区別されません。
- 同じドキュメント内: 大文字と小文字の区別を比較する場合、同じレベルのプロパティ名は一意である必要があります。 たとえば、次の JSON ドキュメントでは、同じレベルで "Name" と "name" が使用されています。 これは有効な JSON ドキュメントですが、一意性制約を満たしていないため、分析ストアでは、完全に表示されません。 この例で "Name" と "name" は、大文字と小文字を区別せずに比べると同じになっています。 最初に出現する
"Name": "fred"のみが、分析ストアで表示されます。"name": "john"はまったく表示されません。
{"id": 1, "Name": "fred", "name": "john"}- 異なるドキュメント内: 同じレベルでプロパティと名前が同じでも、大文字と小文字が異なっていれば、最初に出現した名前の形式を使用して同じ列内に表示されます。 たとえば、次の JSON ドキュメントでは、
"Name"と"name"が同じレベルにあります。 最初のドキュメント形式は"Name"であるため、これが分析ストアでプロパティ名を表すために使用されます。 言い換えると、分析ストアの列名は"Name"になります。"fred"と"john"の両方が"Name"列に表示されます。
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}- 同じドキュメント内: 大文字と小文字の区別を比較する場合、同じレベルのプロパティ名は一意である必要があります。 たとえば、次の JSON ドキュメントでは、同じレベルで "Name" と "name" が使用されています。 これは有効な JSON ドキュメントですが、一意性制約を満たしていないため、分析ストアでは、完全に表示されません。 この例で "Name" と "name" は、大文字と小文字を区別せずに比べると同じになっています。 最初に出現する
コレクション内の最初のドキュメントによって、最初の分析ストア スキーマが定義されます。
- 最初のスキーマよりも多くのプロパティを持つドキュメントでは、分析ストアに新しい列が生成されます。
- 列を削除することはできません。
- コレクション内のすべてのドキュメントを削除しても、分析ストア スキーマはリセットされません。
- スキーマのバージョン管理はありません。 トランザクション ストアから推定された最新のバージョンが、分析ストアに表示されます。
現時点では、Azure Synapse Spark では、次に示す特殊文字が名前に含まれているプロパティを読み取ることはできません。 Azure Synapse SQL サーバーレスは影響を受けません。
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
Note
空白は、この制限に達すると返される Spark エラー メッセージにも表示されます。 ただし、空白に対して特別な処理を追加しました。詳しくは、以下の項目をご確認ください。
- 上に示した文字を使用するプロパティ名がある場合は、次のような選択肢があります。
- データ モデルを事前に変更して、これらの文字を回避します。
- 現在、スキーマのリセットはサポートされていないため、アプリケーションを変更して、類似した名前の冗長プロパティを追加することで、これらの文字を回避できます。
- 変更フィードを使用して、プロパティ名にこれらの文字を含まないコンテナーの具体化されたビューを作成します。
- Spark オプション
dropColumnを使用して、影響を受ける列を無視し、他のすべての列を DataFrame に読み込みます。 の構文は次のとおりです。
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Azure Synapse Spark では、名前に空白を含むプロパティがサポートされるようになりました。 そのためには、Spark オプション
allowWhiteSpaceInFieldNamesを使用して、影響を受ける列を DataFrame に読み込み、元の名前を保持する必要があります。 の構文は次のとおりです。
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
次の BSON データ型はサポートされておらず、分析ストアでは表されません。
- Decimal128
- Regular Expression
- DB Pointer
- JavaScript
- シンボル
- MinKey / MaxKey
ISO 8601 UTC 標準に準拠した DateTime 文字列を使用する場合、次の動作を期待できます。
- Azure Synapse の Spark プールは、これらの列を
stringとして表示します。 - Azure Synapse の SQL サーバーレス プールは、これらの列を
varchar(8000)として表示します。
- Azure Synapse の Spark プールは、これらの列を
UNIQUEIDENTIFIER (guid)の型のプロパティは、分析ストアではstringとして表され、正しく視覚化するには、SQL でVARCHARに、またはstringSpark で に変換する必要があります。Azure Synapse の SQL サーバーレス プールでは、最大 1,000 列の結果セットがサポートされており、入れ子になった列を公開する場合も、その制限までカウントされます。 トランザクション データのアーキテクチャとモデリングでは、この情報を考慮することをお勧めします。
1 つ以上のドキュメントでプロパティの名前を変更すると、それは新しい列と見なされます。 コレクション内のすべてのドキュメントで同じ名前変更を実行すると、すべてのデータが新しい列に移行され、古い列が
NULL値で表されます。
スキーマ表現
分析ストアには 2 つのスキーマ表現方法があり、データベース アカウント内のすべてのコンテナーに対して有効です。 これらには、クエリ エクスペリエンスの簡略さとポリモーフィック型スキーマの列形式の表現の利便性との間のトレードオフがあります。
- 適切に定義されたスキーマ表現。NoSQL および Gremlin 用 API アカウントの既定のオプションです。
- MongoDB 用 API アカウントの既定のオプションである、完全に忠実なスキーマ表現。
適切に定義されたスキーマ表現
適切に定義されたスキーマ表現は、スキーマに依存しないデータの単純な表形式表現をトランザクション ストアに作成します。 適切に定義されたスキーマ表現には、次の考慮事項があります。
- 最初のドキュメントで基本スキーマを定義し、プロパティはすべてのドキュメントで常に同じ型である必要があります。 例外は次の場合だけです。
- その他
NULLのデータ型に対して。 最初に出現する null 以外の型で、列のデータ型が定義されます。 null 以外の最初のデータ型に従っていないドキュメントは、分析ストアでは表されません。 floatからinteger。 すべてのドキュメントが分析ストアで表されます。integerからfloat。 すべてのドキュメントが分析ストアで表されます。 ただし、Azure Synapse SQL サーバーレス プールでこのデータを読み取るには、WITH 句を使用して列をvarcharに変換する必要があります。 この最初の変換の後で、再び数値に変換することができます。 次の例を確認してください。ここで、num の最初の値は整数で、2 番目の値は float でした。
- その他
SELECT CAST (num as float) as num
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
)
WITH (num varchar(100)) AS [IntToFloat]
基本スキーマのデータ型に従わないプロパティは、分析ストアでは表されません。 たとえば、次のドキュメントについて考えてみます。最初のものでは、分析ストアの基本スキーマが定義されています。
idが"2"である 2 番目のドキュメントは、プロパティ"code"が文字列であり、最初のドキュメントの"code"は数値であるため、2 番目には適切に定義されたスキーマはありません。 この場合、コンテナーの有効期間をとおして、分析ストアでは"code"のデータ型はintegerとして登録されます。 2 番目のドキュメントはそれでも分析ストアに含まれますが、その"code"プロパティは含まれません。{"id": "1", "code":123}{"id": "2", "code": "123"}
Note
上の条件は、 NULL プロパティには適用されません。 たとえば、{"a":123} and {"a":NULL} はやはり適切に定義されています。
Note
ドキュメント "1" の "code" をトランザクション ストア内の文字列に更新しても、上記の条件は変わりません。 分析ストアでは、スキーマのリセットは現在サポートされていないので、"code" は integer として保持されます。
- 配列型に含まれる繰り返される型は、1 つである必要があります。 たとえば、
{"a": ["str",12]}は、配列には整数型と文字列型が混在しているため、適切に定義されたスキーマではありません。
Note
Azure Cosmos DB 分析ストアが適切に定義されたスキーマ表現に準拠していて、上記の仕様を特定の項目が違反している場合、これらの項目は分析ストアには含まれません。
適切に定義されたスキーマのさまざまな型に関しては、異なる動作を想定しています。
- Azure Synapse の Spark プールは、これらの値を
undefinedとして表示します。 - Azure Synapse の SQL サーバーレス プールは、これらの値を
NULLとして表示します。
- Azure Synapse の Spark プールは、これらの値を
明示的な
NULL値に関しては、異なる動作を想定しています。- Azure Synapse の Spark プールは、これらの値を
0(ゼロ) として読み取り、列に null 以外の値が含まれるとすぐにundefinedとして読み取ります。 - Azure Synapse の SQL サーバーレス プールは、これらの値を
NULLとして読み取ります。
- Azure Synapse の Spark プールは、これらの値を
存在しない列に関しては、異なる動作を想定しています。
- Azure Synapse の Spark プールは、これらの列を
undefinedとして表示します。 - Azure Synapse の SQL サーバーレス プールは、これらの列を
NULLとして表示します。
- Azure Synapse の Spark プールは、これらの列を
表現上の課題を回避する方法
スキーマが正しくない古いドキュメントを使用して、コンテナーの分析ストアの基本スキーマが作成された可能性があります。 上記のすべてのルールに基づいて、Azure Synapse Link を使用して分析ストアに対してクエリを実行するときに、特定のプロパティに対して NULL を受け取る場合があります。 基本スキーマのリセットは現在サポートされていないため、問題のあるドキュメントを削除または更新しても役に立ちません。 次のような解決策が考えられます。
- データを新しいコンテナーに移行するには、すべてのドキュメントのスキーマが正しいことを確認します。
- 間違ったスキーマのプロパティを破棄し、すべてのドキュメント内の正しいスキーマを持つ新しいものを別の名前で追加します。 例: status プロパティが文字列である Orders コンテナーにドキュメントが数十億存在します。 ただし、そのコンテナー内の最初のドキュメントの状態は整数で定義されています。 そのため、1 つのドキュメントの状態が正しく表され、他のすべてのドキュメントが
NULLになります。 status2 プロパティをすべてのドキュメントに追加して、元のプロパティの代わりにそれを使用するようにします。
完全に忠実なスキーマ表現
完全に忠実なスキーマ表現は、スキーマに依存しないオペレーショナル データ内のさまざまなポリモーフィック型スキーマを処理するように設計されています。 このスキーマ表現では、適切に定義されたスキーマ制約 (つまり、混在したデータ型フィールドも、混在したデータ型配列も存在しない) に違反しても、分析ストアから項目が削除されることはありません。
これは、オペレーショナル データのリーフ プロパティを JSON key-value ペアとして分析ストアに変換することによって実現されます。ここで、データ型は key で、プロパティ コンテンツは value です。 この JSON オブジェクト表現により、あいまいさのないクエリが可能になり、各データ型を個別に分析できます。
つまり、完全に忠実なスキーマ表現では、各ドキュメントの各プロパティのデータ型ごとに、そのプロパティの JSON オブジェクトに key-value ペアが生成されます。 それぞれが最大 1,000 個のプロパティの 1 つとしてカウントされます。
たとえば、トランザクション ストアで次のサンプル ドキュメントを見てみましょう。
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
入れ子になったオブジェクト address は、ドキュメントのルート レベルのプロパティであり、列として表されます。 address オブジェクト内の各リーフ プロパティは、JSON オブジェクトとして表されます。{"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}
適切に定義されたスキーマ表現とは異なり、完全に忠実なメソッドを使用すると、データ型のバリエーションが許容されます。 上記の例のこのコレクションの次のドキュメントで、文字列として streetNo が使用される場合は、分析ストアでは "streetNo":{"string":15850} として表されます。 適切に定義されたスキーマ メソッドでは表現されません。
完全に忠実なスキーマのデータ型マップ
MongoDB のデータ型と分析ストアの表現方法を、完全な忠実度スキーマ表現でマップしたものだ。 次のマップは、NoSQL API アカウントでは有効ではありません。
| 元のデータ型 | サフィックス | 例 |
|---|---|---|
| Double | ".float64" | 24.99 |
| Array | ".array" | ["a", "b"] |
| Binary | ".binary" | 0 |
| Boolean | ".bool" | True |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NULL | ".NULL" | NULL |
| String | ".string" | "ABC" |
| Timestamp | ".timestamp" | Timestamp(0, 0) |
| ObjectId | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| ドキュメント | ".object" | {"a": "a"} |
明示的な
NULL値に関しては、異なる動作を想定しています。- Azure Synapse の Spark プールは、これらの値を
0(ゼロ) として読み取ります。 - Azure Synapse の SQL サーバーレス プールは、これらの値を
NULLとして読み取ります。
- Azure Synapse の Spark プールは、これらの値を
存在しない列に関しては、異なる動作を想定しています。
- Azure Synapse の Spark プールは、これらの列を
undefinedとして表示します。 - Azure Synapse の SQL サーバーレス プールは、これらの列を
NULLとして表示します。
- Azure Synapse の Spark プールは、これらの列を
timestamp値に関しては、異なる動作を想定しています:- Azure Synapse の Spark プールは、これらの値を
TimestampType、DateTypeまたはFloatとして読み取られます。 これは、範囲とタイムスタンプの生成方法によって異なります。 - Azure Synapse の SQL サーバーレス プールは、これらの値を
0001-01-01から9999-12-31の範囲のDATETIME2として読み取ります。 この範囲を超える値はサポートされていないため、クエリの実行エラーが発生します。 このような場合は、次のようにすることができます。- クエリから列を削除します。 表現を維持するには、サポートされている範囲内で、その列をミラーリングする新しいプロパティを作成できます。 また、クエリで使用します。
- RU コストなしで分析ストアからの変更データ キャプチャを使用して、サポートされているいずれかのシンク内でデータを変換して新しい形式に読み込みます。
- Azure Synapse の Spark プールは、これらの値を
Spark での完全に忠実なスキーマの使用
Spark では、DataFrame に読み込む際、各データ型は列として管理されます。 以下のドキュメントを含むコレクションを想定してみましょう。
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
最初のドキュメントでは、rating が数値、timestamp が utc 形式であるのに対し、2 番目のドキュメントでは rating と timestamp が文字列となっています。 このコレクションが一切のデータ変換なしで DataFrame に読み込まれたと仮定すると、df.printSchema() の出力は次のようになります。
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
適切に定義されたスキーマ表現では、2 番目のドキュメントの rating と timestamp はどちらも表現されません。 完全に忠実なスキーマでは、次の例を使用して、各データ型の各値に個別にアクセスできます。
次の例では、PySpark を使用して集計を実行できます。
df.groupBy(df.item.string).sum().show()
次の例では、PySQL を使用して別の集計を実行できます。
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
SQL での完全に忠実なスキーマの使用
上記の Spark の例と同じドキュメントで、次の構文例を使用できます。
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
cast、convert、またはその他の T-SQL 関数を使用して変換を実装し、データを操作できます。 また、ビューを使用して、複雑なデータ型構造を非表示にすることもできます。
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
MongoDB _id フィールドの操作
MongoDB _id フィールドは、MongoDB のすべてのコレクションの基本であり、もともとは 16 進数の表現を持っています。 上の表でわかるように、完全な忠実なスキーマはその特性を保持し、Azure Synapse Analytics での視覚化の課題を生み出します。 正しい視覚化を行うには、_id データ型を次のように変換する必要があります。
Spark での MongoDB _id フィールドの操作
下の例は、Spark 2.x および 3.x バージョンで動作します。
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
SQL での MongoDB _id フィールドの操作
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
HTAP) WITH (_id VARCHAR(1000)) as HTAP
MongoDB id フィールドの操作
MongoDB コンテナーの id プロパティは、"_id" プロパティの Base64 表現で自動的にオーバーライドされ、分析ストア内でも同様です。 "id" フィールドは、MongoDB アプリケーションによる内部使用を目的としています。 現時点で唯一の回避策は、"id" プロパティの名前を "id" 以外の名前に変更することです。
NoSQL または Gremlin 用 API アカウントの完全に忠実なスキーマ
Azure Cosmos DB アカウントで Synapse Link を初めて有効にするときにスキーマの種類を設定することによって、既定のオプションではなく、NoSQL 用 API アカウントの完全に忠実なスキーマを使用できます。 既定のスキーマ表現の種類を変更することに関する考慮事項を次に示します。
- 現在、Azure portal を使用して NoSQL API アカウントで Synapse Link を有効にすると、適切に定義されたスキーマとして有効になります。
- 現時点では、NoSQL または Gremlin API アカウントで完全に忠実なスキーマを使用する場合は、アカウント レベルで Synapse Link を有効にするのと同じ CLI または PowerShell コマンドのアカウント レベルで設定する必要があります。
- 現在、Azure Cosmos DB for MongoDB は、このスキーマ表現の変更の可能性と互換性がありません。 すべての MongoDB アカウントには、完全に忠実なスキーマ表現の種類があります。
- 上記の完全忠実度スキーマ データ型マップは、JSON データ型を使用する NoSQL API アカウントでは有効ではありません。 たとえば、
floatとintegerの値は分析ストアでnumとして表されます。 - スキーマ表現の種類を、適切に定義済みから完全に忠実に、あるいはその逆に再設定することはできません。
- 現在、分析ストア内のコンテナーのスキーマは、データベース アカウントで Synapse Link が有効になっていない場合でも、コンテナーの作成時に定義されます。
- アカウント レベルで完全に忠実なスキーマを設定して Synapse Link が有効になる前に作成されたコンテナーやグラフには、適切に定義されたスキーマが含まれます。
- アカウント レベルで完全に忠実なスキーマを設定して Synapse Link が有効になった後に作成されたコンテナーやグラフには、完全に忠実なスキーマが含まれます。
スキーマ表現の種類の決定は、Azure CLI または PowerShell を使用して、そのアカウントで Synapse Link を有効にするのと同時に行う必要があります。
Azure CLI を使用する場合:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Note
既存のアカウントの場合は、上のコマンドで create を update に置き換えます。
PowerShell を使用する場合:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Note
既存のアカウントの場合は、上のコマンドで New-AzCosmosDBAccount を Update-AzCosmosDBAccount に置き換えます。
分析の Time to Live (TTL)
分析 TTL (ATTL) は、データを分析ストアに保持する必要がある期間を示します (コンテナーの場合)
ATTL がNULL以外の値に設定され、0場合、分析ストアは有効になります。 有効にすると、操作データの挿入、更新、削除は、トランザクション TTL (TTTL) の構成に関係なく、トランザクション ストアから分析ストアに自動的に同期されます。 分析ストアでのこのトランザクション データの保持は、AnalyticalStoreTimeToLiveInSeconds プロパティによってコンテナー レベルで制御できます。
可能な ATTL 構成は次のとおりです。
値が
0に設定されている場合: 分析ストアは無効になり、トランザクション ストアから分析ストアにデータは複製されません。 コンテナー内の分析ストアを無効にするには、サポート ケースを開いてください。フィールドが省略さた場合、何も起こらず、前の値は保持されます。
値が
-1: に設定されている場合: トランザクション ストア内のデータの保持に関係なく、すべての履歴データが分析ストアに保持されます。 この設定は、オペレーショナル データが分析ストアに無期限に保持されることを示します存在し、値が何らかの正の値
nに設定されている場合: 項目は、トランザクション ストアでの最後に変更時刻からn秒後に、分析ストアでの期限が切れます。 この設定は、トランザクション ストアでのデータの保持に関係なく、分析ストアに一定期間だけオペレーショナル データを保持する場合に利用できます
考慮すべき点:
- 分析 ATTL の値を設定して分析ストアを有効にした後で、別の有効な値に更新できます。
- TTTL はコンテナー レベルまたは項目レベルで設定できますが、現時点では、分析 ATTL はコンテナー レベルでのみ設定できます。
- コンテナー レベルで ATTL >= TTTL を設定すると、分析ストアでのオペレーション データの長期保持を実現できます。
- ATTL = TTTL を同じに設定することにより、分析ストアでトランザクション ストアをミラー化することができます。
- ATTL よりも大きい TTTL がある場合、ある時点で分析ストアにのみ存在するデータがあります。 このデータは読み取り専用です。
- 現在、分析ストアからデータを削除することはありません。 ATTL を正の整数に設定した場合、データはクエリに含まれず、それに対して課金されません。 しかし、ATTL を
-1に戻すと、すべてのデータがもう一度表示され、すべてのデータ ボリュームに対する課金が開始されます。
コンテナーで分析ストアを有効にする方法:
Azure portal から、ATTL オプションをオンにすると、既定値の -1 に設定されます。 この値は、データ エクスプローラーのコンテナーの設定に移動することで、"n" 秒に変更できます。
Azure Management SDK、Azure Cosmos DB SDK、PowerShell、または Azure CLI から、これを -1 または "n" 秒に設定して、 ATTL オプションを有効にできます。
詳細については、コンテナーで分析 TTL を構成する方法に関するページを参照してください。
履歴データのコスト効率の高い分析
データの階層化とは、異なるシナリオ用に最適化されたストレージ インフラストラクチャ間にデータを分離することです。 これにより、エンドツーエンドのデータ スタックの全体的なパフォーマンスとコスト効果が向上します。 分析ストアにより、Azure Cosmos DB では、トランザクション ストアから分析ストアへの異なるデータ レイアウトでのデータの自動階層化がサポートされるようになりました。 ストレージ コストに関してトランザクション ストアより分析ストアの方が最適化されているため、より長い期間のオペレーショナル データを履歴分析用に保持することができます。
分析ストアを有効にした後は、トランザクション ワークロードのデータ保持ニーズに基づいて、一定期間後にトランザクション ストアからレコードが自動的に削除されるように、transactional TTL プロパティを構成できます。 同様に、analytical TTL を使用すると、トランザクション ストアからは独立して、分析ストアに保持されるデータのライフサイクルを管理できます。 分析ストアを有効にし、トランザクションおよび分析 TTL プロパティを構成することにより、2 つのストアのデータ保持期間をシームレスに階層化し、定義することができます。
Note
analytical TTL が transactional TTL 値より大きい値に設定されている場合、コンテナーには、分析ストアにのみ存在するデータが含まれます。 このデータは読み取り専用であり、現在、分析ストアのドキュメント レベル の TTL はサポートされていません。 将来のある時点でコンテナー データの更新または削除が必要になる場合は、transactional TTL より大きい analytical TTL の値を使用しないでください。 この機能は、今後更新や削除を必要としないデータに推奨されます。
Note
実際のシナリオで物理的な削除が必要ない場合は、論理的な削除または更新アプローチを採用できます。 分析ストアにのみ存在するが、論理的な削除/更新が必要な同じドキュメントの別のバージョンをトランザクション ストアに挿入します。 期限切れのドキュメントの削除または更新であることを示すフラグが付いている可能性があります。 同じドキュメントの両方のバージョンが分析ストアに共存し、アプリケーションでは最後のバージョンのみが考慮されます。
回復力
分析ストアは Azure Storage に依存し、物理的な障害に対して次の保護を提供します。
- 既定では、Azure Cosmos DB データベース アカウントは、ローカル冗長ストレージ (LRS) アカウントに分析ストアを割り当てます。 LRS では、オブジェクトに年間 99.999999999% (9 が 11 個) 以上の持続性が提供されます。
- データベース アカウントの geo リージョンがゾーン冗長用に構成されている場合は、ゾーン冗長ストレージ (ZRS) アカウントに割り当てられます。 Azure Cosmos DB データベース アカウントのリージョンで Availability Zones を有効にして、そのリージョンの分析データをゾーン冗長ストレージに保存する必要があります。 ZRS は、ストレージ リソースに年間 99.9999999999% (トゥエルブ ナイン) 以上の持続性を実現します。
Azure Storage の持続性の詳細については、このリンクを参照してください
バックアップ
分析ストアには物理的な障害に対する保護が組み込まれていますが、トランザクション ストアでの誤った削除や更新にはバックアップが必要な場合があります。 そのような場合は、コンテナーを復元し、復元されたコンテナーを使用して元のコンテナーのデータをバックフィルしたり、必要に応じて分析ストアを完全に再構築したりできます。
Note
現在、分析ストアはバックアップされていないため、復元できません。 それに依存してバックアップ ポリシーを計画することはできません。
Synapse Link と、結果として分析ストアでは、Azure Cosmos DB バックアップ モードとの互換性レベルが以下のように異なります。
- 定期的なバックアップ モードは Synapse Link と完全に互換性があり、これらの 2 つの機能は同じデータベース アカウントで使用できます。
- 継続的バックアップ モードを使用しているデータベース アカウント用の Synapse Link は GA です。
- Synapse Link が有効になっているアカウントでの継続的バックアップ モードはパブリック プレビュー段階です。 現時点では、Cosmos DB アカウント内のいずれかのコレクションで Synapse Link を無効にした場合、継続的バックアップに移行することはできません。
バックアップ ポリシー
2 つの可能なバックアップ ポリシーがあり、それらの使用方法を理解するには、Azure Cosmos DB バックアップに関する以下の詳細が非常に重要です:
- 元のコンテナーは、両方のバックアップ モードで分析ストアなしで復元されます。
- Azure Cosmos DB では、復元からのコンテナーの上書きはサポートされていません。
次に、分析ストアの観点からバックアップと復元を使用する方法を見てみましょう。
TTTL >= ATTL を使用したコンテナーの復元
transactional TTL が analytical TTL と等しいかそれより大きい場合、分析ストア内のすべてのデータは引き続きトランザクション ストアに存在します。 復元の場合は、次の 2 つの状況が考えられます。
- 復元されたコンテナーを元のコンテナーの代わりに使用する場合。 分析ストアを再構築するには、Synapse Link をアカウント レベルとコンテナー レベルで有効にします。
- 復元されたコンテナーをデータ ソースとして使用して、元のコンテナー内のデータをバックフィルまたは更新する場合。 この場合、分析ストアにはデータ操作が自動的に反映されます。
TTTL <= ATTL を使用したコンテナーの復元
transactional TTL が analytical TTL より小さい場合、一部のデータは分析ストアにのみ存在し、復元されたコンテナーには存在しません。 ここでも、次の 2 つの状況が考えられます。
- 復元されたコンテナーを元のコンテナーの代わりに使用する場合。 この場合、Synapse Link をコンテナー レベルで有効にすると、トランザクション ストアにあったデータのみが新しい分析ストアに含められます。 ただし、元のコンテナーが存在する限り、元のコンテナーの分析ストアはクエリで使用できます。 両方のクエリを実行するようにアプリケーションを変更することもできます。
- 復元されたコンテナーをデータ ソースとして使用して、元のコンテナー内のデータをバックフィルまたは更新するには、
- 分析ストアには、トランザクション ストア内のデータのデータ操作が自動的に反映されます。
transactional TTLのためトランザクション ストアから以前削除されたデータを再挿入した場合、このデータは分析ストア内に複製されます。
例:
- コンテナー
OnlineOrdersの TTTL は 1 か月に設定され、ATTL は 1 年に設定されています。 OnlineOrdersNewに復元し、それを再構築するために分析ストアを有効にすると、トランザクション ストアと分析ストアの両方に 1 か月のデータしか存在しません。- 元の
OnlineOrdersコンテナーは削除されす、その分析ストアは引き続き使用できます。 - 新しいデータは
OnlineOrdersNewにのみに取り込されます。 - 分析クエリは、元のデータが関連している間、分析ストアから UNION ALL を実行します。
元のコンテナーを削除しても、分析ストア データを失いたくない場合は、元のコンテナーの分析ストアを別の Azure データ サービスに保持できます。 Synapse Analytics には、異なる場所に格納データ間で結合を実行する機能があります。 例: Synapse Analytics クエリは、分析ストア データを Azure Blob Storage、Azure Data Lake Store などに格納されている外部テーブルと結合します。
分析ストア内のデータには、トランザクション ストアに存在するものとは異なるスキーマがあることに注意することが重要です。 RU コストをかけずに分析ストア データのスナップショットを生成し、任意の Azure Data Service にエクスポートすることはできますが、このスナップショットを使用したトランザクション ストアのフィードは保証できません。 このプロセスはサポートされていません。
グローバル配信
グローバルに分散された Azure Cosmos DB アカウントがある場合、コンテナーの分析ストアを有効にした後、そのアカウントのすべてのリージョンでそれを使用できるようになります。 オペレーショナル データに対する変更はすべて、すべてのリージョンにグローバルにレプリケートされます。 Azure Cosmos DB のデータの最も近いリージョン コピーに対して、分析クエリを効率的に実行できます。
パーティション分割
分析ストアのパーティション分割は、トランザクション ストアのパーティション分割にはまったく依存していません。 既定では、分析ストア内のデータはパーティション分割されません。 分析クエリに頻繁に使われるフィルターがある場合は、これらのフィールドに基づいてパーティション分割することで、クエリのパフォーマンスを向上させることができます。 詳細については、カスタム パーティション分割の概要およびカスタム パーティション分割を構成する方法に関する記事を参照してください。
セキュリティ
分析ストアでの認証は、特定のデータベースに対するトランザクション ストアと同じです。
プライベート エンドポイントを使用したネットワーク分離 - トランザクション ストアおよび分析ストア内のデータへのネットワーク アクセスを個別に制御できます。 ネットワークの分離は、Azure Synapse ワークスペースのマネージド仮想ネットワーク内で、ストアごとに別個のマネージド プライベート エンドポイントを使用して行われます。 詳細については、分析ストアのプライベート エンドポイントを構成する方法に関する記事を参照してください。
保存時のデータ暗号化 - 分析ストアの暗号化は既定で有効になっています。
カスタマー マネージド キーを使用したデータの暗号化 - 同じカスタマー マネージド キーを自動かつ透過的な方法で使用して、トランザクション ストアおよび分析ストア全体のデータをシームレスに暗号化できます。 Azure Synapse Link では、Azure Cosmos DB アカウントのマネージド ID を使用したカスタマー マネージド キーの構成のみがサポートされています。 アカウントで Azure Synapse Link を有効にする前に、Azure Key Vault のアクセス ポリシーでアカウントのマネージド ID を構成する必要があります。 詳細については、Azure Cosmos DB アカウントのマネージド ID を使用して、カスタマー マネージド キーを構成する方法に関する記事をご覧ください。
Note
データベース アカウントをファースト パーティからシステムまたはユーザー割り当て ID に変更し、データベース アカウントで Azure Synapse Link を有効にした場合は、データベース アカウントから Synapse Link を無効にできないため、ファースト パーティ ID に戻すことはできません。
複数の Azure Synapse Analytics ランタイムのサポート
分析ストアは、コンピューティング ランタイムに依存せずに、分析ワークロードに対してスケーラビリティ、弾力性、パフォーマンスを提供するように最適化されています。 ストレージ テクノロジは、手作業を必要とせずに分析ワークロードを最適化するように、自己管理されています。
Azure Cosmos DB 分析ストア内のデータは、Azure Synapse Analytics でサポートされているさまざまな分析ランタイムから同時に照会できます。 Azure Synapse Analytics では、Apache Spark とサーバーレス SQL プールが Azure Cosmos DB 分析ストアでサポートされています。
Note
Azure Synapse Analytics のランタイムを使用した分析ストアからの読み取りだけが可能です。 また、その逆も同様で、Azure Synapse Analytics ランタイムは分析ストアからの読み取りだけが可能です。 自動同期プロセスだけが分析ストア内のデータを変更できます。 組み込み Azure Cosmos DB OLTP SDK を使用して、Azure Synapse Analytics Spark プールで Azure Cosmos DB トランザクション ストアにデータを書き戻すことができます。
価格
分析ストアは、次の料金が課金される使用量ベースの価格モデルに従います。
ストレージ: 分析 TTL によって定義されている履歴データを含め、毎月分析ストアに保持されるデータの量。
分析の書き込み操作: トランザクション ストアから分析ストアへのオペレーショナル データの更新のフル マネージドの同期 (自動同期)
分析の読み取り操作: Azure Synapse Analytics Spark プールおよびサーバーレス SQL プールのランタイムから分析ストアに対して実行された読み取り操作。
分析ストアの価格は、トランザクション ストアの価格モデルとは別のものです。 分析ストアには、プロビジョニングされた RU の概念はありません。 分析ストアの価格モデルの詳細については、Azure Cosmos DB の価格のページを参照してください。
分析ストア内のデータにアクセスできるのは、Azure Synapse Link を使用した場合のみです。 これは、Azure Synapse Analytics ランタイムで、Azure Synapse Apache Spark プールと Azure Synapse サーバーレス SQL プールを使用して行われます。 分析ストアのデータへのアクセスの価格モデルの詳細については、Azure Synapse Analytics の価格のページを参照してください。
Azure Cosmos DB コンテナーで分析ストアを有効にするためのだいたいのコストの見積もりを入手するには、分析ストアの観点からは、Azure Cosmos DB 容量プランナーを使用して、分析ストレージと書き込み操作のコストを見積もることができます。
分析ストアの読み取り操作の見積もりは、分析ワークロードの機能であるため、Azure Cosmos DB のコスト計算ツールには含まれません。 しかし、大まかな見積もりとして、分析ストアの 1 TB のデータをスキャンすると、通常、13 万回の分析読み取り操作が行われ、結果のコストは $0.065 になります。 たとえば、Azure Synapseサーバーレス SQL プールを使用してこの 1 TB のスキャンを実行すると、Azure Synapse Analytics の価格のページに従って $5.00 のコストがかかります。 この 1 TB のスキャンの最終的な合計コストは $5.065 になります。
上記は、分析ストア内で 1 TB のデータをスキャンするための見積もりですが、フィルターを適用することで、スキャンされるデータの量が少なくなりため、従量課金モデルの場合は、これにより分析読み取り操作の正確な数が判断されます。 分析ワークロードに関する概念実証によって、分析読み取り操作のより詳細な予測が得られます。 この見積もりには、Azure Synapse Analytics のコストは含まれていません。
次のステップ
詳しく学習するために、次のドキュメントを参照してください。