Azure Cosmos DB for MongoDB でのインデックス作成を管理する
適用対象: ![]() MongoDB
MongoDB
Azure Cosmos DB for MongoDB では、Azure Cosmos DB のコア インデックス管理機能を利用します。 この記事では、Azure Cosmos DB for MongoDB を使用してインデックスを追加する方法を重点的に取り上げます。 インデックスは特殊なデータ構造で、データのクエリをおよそ 1 桁速くすることができます。
MongoDB サーバー バージョン 3.6 以降のインデックス作成
Azure Cosmos DB for MongoDB サーバー バージョン 3.6 以降では、_id フィールドとシャード キー (シャード コレクションのみ) のインデックスが自動的に作成されます。 この API では、シャード キーごとに _id フィールドの一意性が自動的に適用されます。
MongoDB 用 API は、既定ですべてのフィールドのインデックスが作成される Azure Cosmos DB for NoSQL とは動作が異なります。
インデックス作成ポリシーの編集
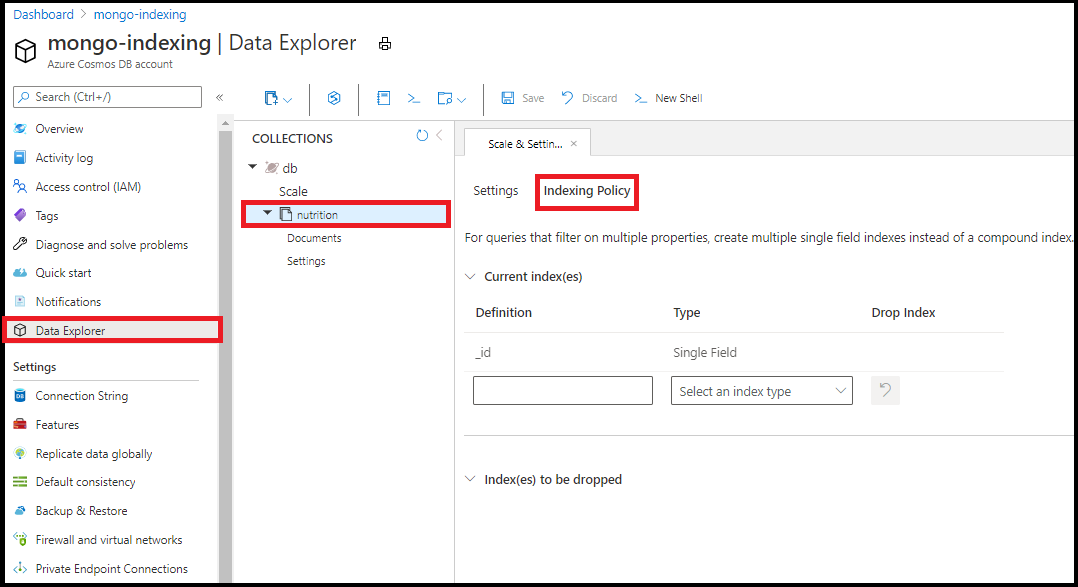
Azure portal 内のデータ エクスプローラーでインデックス作成ポリシーを編集することをお勧めします。 データ エクスプローラーのインデックス作成ポリシー エディターから、1 つフィールド インデックスとワイルドカード インデックスを追加できます。
Note
データ エクスプローラーのインデックス作成ポリシー エディターを使用して複合インデックスを作成することはできません。
インデックスの種類
単一フィールド
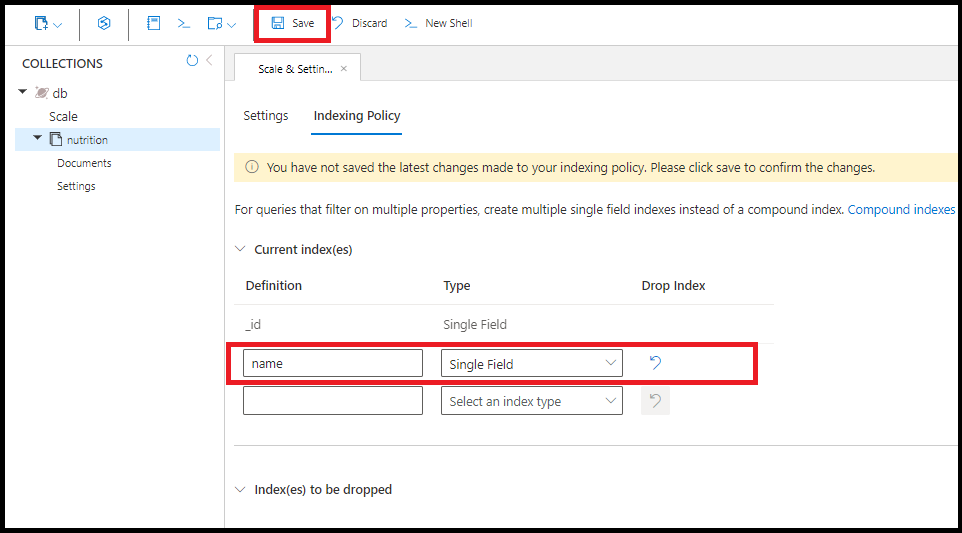
単一フィールドに対してインデックスを作成できます。 単一フィールドのインデックスの並べ替え順序は重要ではありません。 次のコマンドでは、フィールド name に対してインデックスが作成されます。
db.coll.createIndex({name:1})
Azure portal で name に対して同じ 1 つのフィールド インデックスを作成できます。
1 つのクエリで、使用可能な場合は複数の単一フィールドのインデックスが使用されます。 コレクションごとに最大 500 個の単一フィールド インデックスを作成できます。
複合インデックス (MongoDB サーバー バージョン 3.6 以降)
MongoDB 用 API では、クエリで一度に複数のフィールドの並べ替えを実行できる必要がある場合、複合インデックスが必須となります。 並べ替える必要がない、複数のフィルターを使用するクエリの場合は、複合インデックスではなく、複数の単一フィールド インデックスを作成して、インデックス作成コストを節約します。
複合インデックスまたは複合インデックス内のフィールドごとに単一フィールド インデックスを使用すると、クエリでのフィルター処理で同じパフォーマンスが得られます。
入れ子になったフィールドの複合インデックスは、配列の制限により、既定ではサポートされていません。 入れ子になったフィールドに配列が含まれていない場合、インデックスは意図したとおりに機能します。 入れ子になったフィールド (パス上の任意の場所) に配列が含まれている場合、その値はインデックスで無視されます。
たとえば、この場合、パスに配列がないため、people.dylan.age を含む複合インデックスが機能します。
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
この場合、パスに配列があるため、この同じ複合インデックスは機能しません。
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
ご自分のデータベース アカウントに対してこの機能を有効にするには、"EnableUniqueCompoundNestedDocs" 機能を有効にします。
注意
配列に複合インデックスを作成することはできません。
次のコマンドでは、フィールド name と age に対して複合インデックスを作成します。
db.coll.createIndex({name:1,age:1})
複合インデックスを使用すると、次の例に示すように、一度に複数のフィールドで効率的に並べ替えることができます。
db.coll.find().sort({name:1,age:1})
上記の複合インデックスを使用して、すべてのフィールドに対して逆の並べ替え順序でクエリを効率的に並べ替えることもできます。 次に例を示します。
db.coll.find().sort({name:-1,age:-1})
ただし、複合インデックス内のパスの順序は、クエリと完全に一致している必要があります。 追加の複合インデックスを必要とするクエリの例を次に示します。
db.coll.find().sort({age:1,name:1})
複数キー インデックス
Azure Cosmos DB では、配列に格納されているコンテンツにインデックスを作成するために、複数のキー インデックスが作成されます。 配列値を含むフィールドのインデックスを作成すると、Azure Cosmos DB によって配列内のすべての要素のインデックスが自動的に作成されます。
地理空間のインデックス
多くの地理空間演算子は、地理空間インデックスの恩恵を受けます。 現在、Azure Cosmos DB for MongoDB では、2dsphere インデックスがサポートされています。 API ではまだ 2d インデックスはサポートされていません。
location フィールドに対して地理空間インデックスを作成する例を以下に示します。
db.coll.createIndex({ location : "2dsphere" })
テキスト インデックス
Azure Cosmos DB for MongoDB では、現在、テキスト インデックスはサポートされていません。 文字列に対するテキスト検索クエリの場合は、Azure Cosmos DB との Azure AI Search の統合を使用する必要があります。
ワイルドカード インデックス
ワイルドカード インデックスを使用して、不明なフィールドに対するクエリをサポートできます。 たとえば、家族に関するデータを含むコレクションがあるとします。
このコレクションのサンプル ドキュメントの一部を次に示します。
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
もう 1 つの例を次に示します。今回は、children のプロパティのセットが少し異なります。
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
このコレクションでは、ドキュメントにはさまざまなプロパティが含まれる可能性があります。 children 配列内のすべてのデータのインデックスを作成する場合、次の 2 つのオプションがあります。個別のプロパティごとに個別のインデックスを作成するか、children 配列全体に対して 1 つのワイルドカード インデックスを作成します。
ワイルドカード インデックスの作成
次のコマンドでは、children 内のすべてのプロパティに対してワイルドカード インデックスが作成されます。
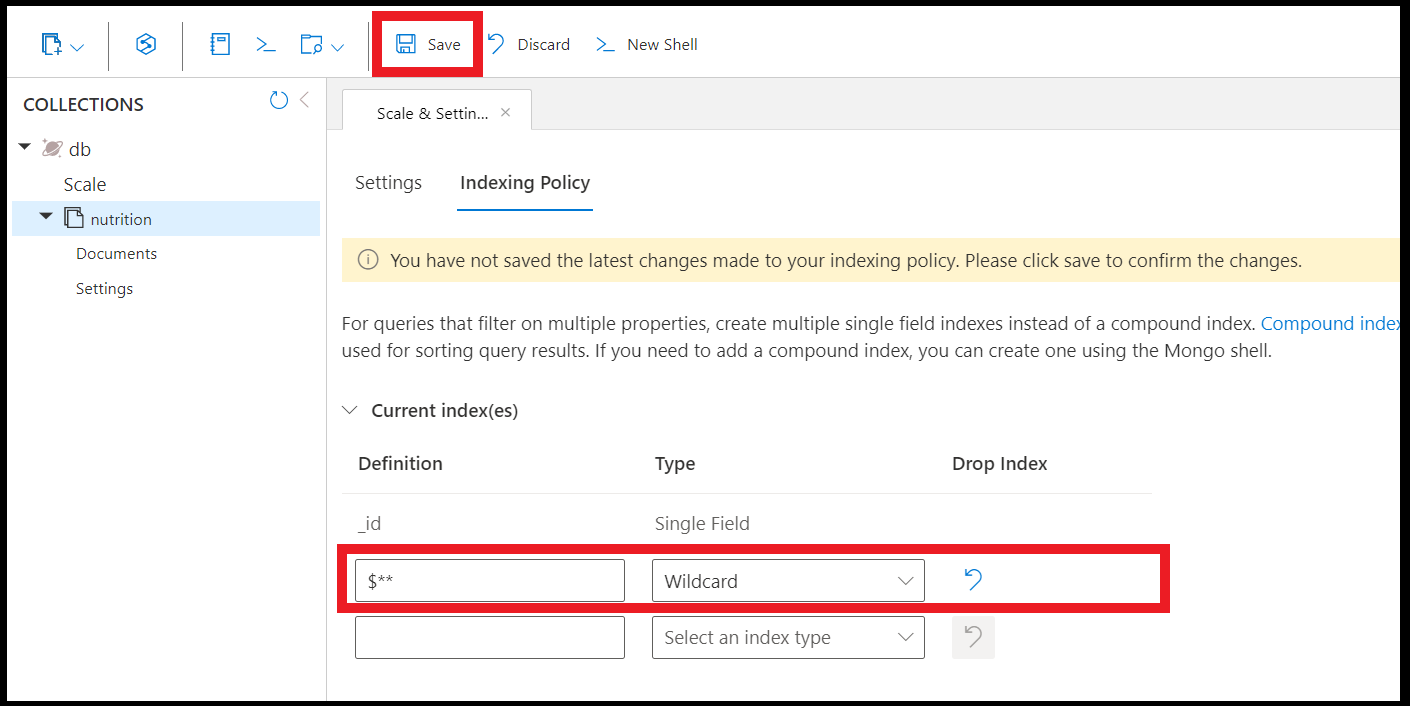
db.coll.createIndex({"children.$**" : 1})
MongoDB とは異なり、ワイルドカード インデックスはクエリ述語内の複数のフィールドをサポートできます。 プロパティごとに個別のインデックスを作成する代わりに 1 つのワイルドカード インデックスを使用しても、クエリのパフォーマンスに違いはありません。
ワイルドカード構文を使用して、次の種類のインデックスを作成できます。
- 単一フィールド
- GeoSpatial
すべてのプロパティのインデックス作成
すべてのフィールドに対するワイルドカード インデックスを作成する方法を次に示します。
db.coll.createIndex( { "$**" : 1 } )
Azure portal のデータ エクスプローラーを使用してワイルドカード インデックスを作成することもできます。
Note
開発を開始するだけの場合は、すべてのフィールドに対するワイルドカード インデックスから始めることを強くお勧め ます。 これにより、開発が簡素化され、クエリの最適化が容易になります。
多くのフィールドを持つドキュメントでは、書き込みと更新の要求ユニット (RU) 料金が高くなる場合があります。 そのため、書き込みが多いワークロードがある場合は、ワイルドカード インデックスを使用するのではなく、個別のインデックスを作成する方法を選択する必要があります。
注意
データが含まれている既存のコレクションに対する一意のインデックスのサポートは、プレビューで利用できます。 ご自分のデータベース アカウントに対してこの機能を有効にするには、'EnableUniqueIndexReIndex' 機能を有効にします。
制限事項
ワイルドカード インデックスでは、次のインデックスの種類やプロパティはいずれもサポートされません。
- 複合
- TTL
- 一意
MongoDB とは異なり、Azure Cosmos DB for MongoDB では、次の場合にワイルドカード インデックスを使用することはできません。
複数の特定のフィールドを含むワイルドカード インデックスの作成
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )複数の特定のフィールドを除外するワイルドカード インデックスの作成
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
代替手段として、複数のワイルドカード インデックスを作成することができます。
インデックスのプロパティ
次の操作は、ワイヤ プロトコル バージョン 4.0 に対応するアカウントと、以前のバージョンに対応するアカウントに共通です。 詳細については、サポートされているインデックスとインデックス付きプロパティを参照してください。
一意なインデックス
一意なインデックス は、複数のドキュメントのインデックス付きフィールドで、同じ値が確実に含まれないようにする場合に便利です。
次のコマンドでは、フィールド student_id に対して一意なインデックスを作成します。
globaldb:PRIMARY> db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
シャード コレクションの場合、一意なインデックスを作成するには、シャード (パーティション) キーを指定する必要があります。 つまり、シャード コレクション上の一意なすべてのインデックスは、いずれかのフィールドがシャード キーである複合インデックスとなります。 順序の最初のフィールドはシャード キーである必要があります。
以下のコマンドでは、フィールド student_id と university に対する一意なインデックスがあるシャード コレクションcoll (シャード キーは university) を作成します。
globaldb:PRIMARY> db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
globaldb:PRIMARY> db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
前の例では、"university":1 句を省略すると、次のメッセージを含むエラーが返されます。
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
制限事項
コレクションが空である間に、一意なインデックスを作成する必要があります。
入れ子になったフィールドの一意のインデックスは、配列の制限により、既定ではサポートされていません。 入れ子になったフィールドに配列が含まれていない場合、インデックスは意図したとおりに機能します。 入れ子になったフィールドに配列 (パス上の任意の場所) が含まれている場合、その値は一意のインデックスでは無視され、その値の一意性は保持されません。
たとえば、この場合、パスに配列がないため、people.tom.age の一意のインデックスは機能します。
{ "people": { "tom": { "age": "25" }, "mark": { "age": "30" } } }
ただし、パスに配列があるため、この場合は機能しません:
{ "people": { "tom": [ { "age": "25" } ], "mark": [ { "age": "30" } ] } }
ご自分のデータベース アカウントに対してこの機能を有効にするには、"EnableUniqueCompoundNestedDocs" 機能を有効にします。
TTL インデックス
特定のコレクションでドキュメントの有効期限を有効にするには、TTL (Time-to-Live) インデックスを作成する必要があります。 TTL インデックスは、expireAfterSeconds 値を持つ _ts フィールドのインデックスです。
例:
globaldb:PRIMARY> db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
上記のコマンドでは、過去 10 秒間、変更されなかったドキュメントが db.coll コレクションからすべて削除されます。
Note
_ts フィールドは Azure Cosmos DB に固有のものであり、MongoDB クライアントからアクセスすることはできません。 これは予約された (システム) プロパティであり、ドキュメントの最終変更日時のタイム スタンプが含まれます。
インデックスの進行状況を追跡する
Azure Cosmos DB for MongoDB のバージョン 3.6 以降では、データベース インスタンスでのインデックス作成の進行状況を追跡する currentOp() コマンドがサポートされます。 このコマンドでは、データベース インスタンスで進行中の操作に関する情報を含むドキュメントが返されます。 ネイティブ MongoDB で進行中のすべての操作を追跡するには、currentOp コマンドを使用します。 Azure Cosmos DB for MongoDB では、このコマンドでサポートされるのは、インデックス操作の追跡のみとなります。
以下に、currentOp コマンドを使用してインデックス作成の進行状況を追跡する方法を示す例をいくつか示します。
コレクションに対するインデックスの進行状況を取得します。
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})データベース内のすべてのコレクションに対するインデックスの進行状況を取得します。
db.currentOp({"command.$db": <databaseName>})Azure Cosmos DB アカウント内のすべてのデータベースとコレクションに対するインデックスの進行状況を取得します。
db.currentOp({"command.createIndexes": { $exists : true } })
インデックスの進行状況の出力例
インデックスの進行状況の詳細には、現在のインデックス操作の進行状況のパーセンテージが表示されます。 以下は、インデックスの進行状況のさまざまな段階での出力ドキュメントの形式を示す例です。
60% 完了した "foo" コレクションと "bar" データベースでのインデックス操作では、出力ドキュメントは次のようになります。
Inprog[0].progress.totalフィールドには、ターゲットの完了パーセンテージとして 100 が示されています。{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 60 %", "progress" : { "done" : 60, "total" : 100 }, …………..….. } ], "ok" : 1 }インデックス操作が "foo" コレクションと "bar" データベースで開始されたばかりの場合、出力ドキュメントの進行状況は、測定可能なレベルに到達するまで 0% と表示されることがあります。
{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 0 %", "progress" : { "done" : 0, "total" : 100 }, …………..….. } ], "ok" : 1 }進行中のインデックス操作が終了すると、出力ドキュメントには空の
inprog操作が表示されます。{ "inprog" : [], "ok" : 1 }
バックグラウンドでのインデックスの更新
background インデックス プロパティに指定された値に関係なく、インデックスの更新は常にバックグラウンドで実行されます。 インデックスの更新では他のデータベース操作よりも優先順位が低い要求ユニット (RU) が使用されるため、インデックスの変更によって書き込み、更新、削除のダウンタイムが発生することはありません。
新しいインデックスを追加するときに、読み取り可用性への影響はありません。 クエリでは、インデックス変換が完了するまで、新しいインデックスを使用しません。 インデックス変換中、クエリ エンジンでは引き続き既存のインデックスを使用します。そのため、インデックスの変更を開始する前と、インデックスの変換中とで、観察される読み取りパフォーマンスは同じです。 新しいインデックスを追加する場合、クエリ結果が不完全または不整合になるリスクもありません。
インデックスを削除し、削除されたインデックスに対してフィルターを使用するクエリをすぐに実行する場合、インデックス変換が完了するまで、クエリ結果の整合性や完全性は保証されません。 インデックスを削除し、新しく削除されたインデックスがクエリでフィルター処理された場合、クエリ エンジンによって結果の整合性または完全性は提供されません。 ほとんどの開発者は、インデックスを削除してからすぐにこれらのクエリを実行しようとはしないため、実際にこのような状況になることはほとんどありません。
Note
インデックスの進行状況を追跡することができます。
reIndex コマンド
reIndex コマンドによって、コレクションのすべてのインデックスが再作成されます。 まれに、コレクションでのクエリのパフォーマンスや他のインデックスの問題が、reIndex コマンドを実行することで解決される場合があります。 インデックスの作成に関する問題が発生している場合は、reIndex コマンドを使用してインデックスを再作成することをお勧めします。
reIndex コマンドは、次の構文を使用して実行できます。
db.runCommand({ reIndex: <collection> })
次の構文を使用すると、reIndex コマンドを実行することによりコレクションでのクエリのパフォーマンスが向上するかどうかを調べることができます。
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
サンプル出力:
{
"database" : "myDB",
"collection" : "myCollection",
"provisionedThroughput" : 400,
"indexes" : [
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
},
{
"v" : 1,
"key" : {
"b.$**" : 1
},
"name" : "b.$**_1",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
}
],
"ok" : 1
}
reIndex によってクエリのパフォーマンスが向上する場合は、requiresReIndex が true になります。 reIndex でクエリのパフォーマンスが向上しない場合、このプロパティは省略されます。
インデックス付きのコレクションを移行する
現在、一意なインデックスを作成できるのは、コレクションにドキュメントが含まれていない場合のみです。 広く使われている MongoDB 移行ツールでは、データのインポート後に一意なインデックスの作成が試行されます。 この問題を回避するために、移行ツールでの試行を許可するのではなく、対応するコレクションと一意なインデックスを手動で作成できます (コマンド ラインで --noIndexRestore フラグを使用することで、mongorestore に対してこの動作を実現できます)。
MongoDB バージョン 3.2 のインデックス作成
バージョン 3.2 の MongoDB ワイヤ プロトコルと互換性のある Azure Cosmos DB アカウントの場合、使用可能なインデックス作成機能と既定値は異なります。 アカウントのバージョンを確認し、バージョン 3.6 にアップグレードできます。
バージョン 3.2 をご利用の場合は、このセクションのバージョン 3.6 以降との主な違いの概要を参照してください。
既定のインデックスの削除 (バージョン 3.2)
バージョン 3.6 以降の Azure Cosmos DB for MongoDB とは異なり、バージョン 3.2 では既定ですべてのプロパティのインデックスが作成されます。 コレクション coll のこれらの既定のインデックスを削除する場合は、次のコマンドを使用できます。
> db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
既定のインデックスを削除した後、バージョン 3.6 以降の場合と同じようにインデックスをさらに追加することができます。
複合インデックス (バージョン 3.2)
複合インデックスは、ドキュメントの複数のフィールドに対する参照を保持します。 複合インデックスを作成する場合は、バージョン 3.6 または 4.0 にアップグレードします。
ワイルドカード インデックス (バージョン 3.2)
ワイルドカード インデックスを作成する場合は、バージョン 4.0 または 3.6 にアップグレードします。
次のステップ
- Azure Cosmos DB のインデックス作成
- Time to Live を使用して Azure Cosmos DB のデータの有効期限が自動的に切れるようにする
- パーティション分割とインデックス作成の関係の詳細については、Azure Cosmos DB コンテナーに対するクエリの実行方法に関する記事をご覧ください。
- Azure Cosmos DB への移行のための容量計画を実行しようとしていますか? 容量計画のために、既存のデータベース クラスターに関する情報を使用できます。
- 既存のデータベース クラスター内の仮想コアとサーバーの数のみがわかっている場合は、仮想コアまたは vCPU を使用した要求ユニットの見積もりに関するページを参照してください
- 現在のデータベース ワークロードに対する通常の要求レートがわかっている場合は、Azure Cosmos DB Capacity Planner を使用した要求ユニットの見積もりに関するページを参照してください