Azure Cosmos DB でプロビジョニング済みのスループット コストを最適化する
適用対象: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Azure Cosmos DB では、プロビジョニング済みスループット モデルにより、あらゆる規模で予測可能なパフォーマンスを提供します。 スループットを事前に予約またはプロビジョニングすると、パフォーマンスでの "迷惑な隣人効果" を排除できます。 必要なスループットの量を正確に指定すると、Azure Cosmos DB で SLA によって裏付けられた構成済みのスループットが保証されます。
最小スループットの 400 RU/秒から始めて、毎秒数千万要求あるいはそれ以上までスケールアップできます。 Azure Cosmos DB コンテナーまたはデータベースに対して発行する各要求 (読み取り要求、書き込み要求、クエリ要求、ストアド プロシージャなど) には対応するコストがあり、プロビジョニング済みスループットから差し引かれます。 400 RU/秒をプロビジョニングしてコストが 40 RU のクエリを発行する場合、そのようなクエリを 1 秒間に 10 回発行できます。 それを超えるすべての要求はレート制限を受け、要求を再試行する必要があります。 クライアント ドライバーを使っている場合、それらは自動再試行ロジックをサポートします。
スループットはデータベースまたはコンテナーに対してプロビジョニングでき、各戦略はシナリオに応じてコスト削減に役立ちます。
異なるレベルでスループットをプロビジョニングすることにより最適化する
データベースでスループットをプロビジョニングした場合は、そのデータベース内のすべてのコンテナー (コレクション/テーブル/グラフなど) が負荷に基づいてスループットを共有できます。 データベース レベルで予約されたスループットは、特定のコンテナーのセットでのワークロードに応じて不均一に共有されます。
コンテナーでスループットをプロビジョニングした場合は、そのコンテナーに対して SLA で裏付けられたスループットが保証されます。 コンテナーのすべての論理パーティションに負荷を均等に分散させるには、論理パーティション キーの選択が非常に重要です。 詳しくは、パーティション分割および水平スケーリングに関する記事をご覧ください。
プロビジョニング済みスループットの戦略の決定に関するガイドラインを次に示します。
次の場合は、(コンテナーのセットを含む) Azure Cosmos DB データベースでのスループットのプロビジョニングを検討します
数十個の Azure Cosmos DB コンテナーがあり、それらの一部または全部の間でスループットを共有したい場合。
IaaS でホストされた VM またはオンプレミスで実行するように設計されているシングル テナントのデータベース (NoSQL やリレーショナル データベースなど) から、Azure Cosmos DB に移行している場合。 また、多くのコレクション、テーブル、グラフがあり、データ モデルをまったく変更したくない場合。 オンプレミスのデータベースから移行するときにデータ モデルを更新しないと、Azure Cosmos DB によって提供されるベネフィットの一部を犠牲にしなければならない場合があることに注意してください。 常にデータ モデルに再アクセスして、パフォーマンスを最大限に活用し、コストも最適化することをお勧めします。
データベース レベルでスループットをプールすることより、ワークロードの予期しない急増に対処する場合。
コンテナーごとに個別に特定のスループットを設定するのではなく、データベース内の一連のコンテナー全体の集計スループットを取得することが大事な場合。
次の場合は、個々のコンテナーでスループットをプロビジョニングすることを検討します
Azure Cosmos DB コンテナーの数が少ない場合。 Azure Cosmos DB はスキーマに依存しないため、スキーマが異なるアイテムを 1 つのコンテナーに格納でき、お客様はエンティティごとに複数の種類のコンテナーを作成する必要はありません。 たとえば 10 から 20 個の個別のコンテナーを 1 つのコンテナーにグループ化することに意味があるかどうかを、常に検討できます。 コンテナーは最小 400 RU なので、10 ~ 20 個のコンテナーすべてを 1 つにプールすると、コスト効率がよくなる可能性があります。
特定のコンテナーでスループットを制御し、SLA によって裏付けられている保証されたスループットを取得したい場合。
上記の 2 つの戦略のハイブリッドを検討します
前に説明したように、Azure Cosmos DB では上記の 2 つの戦略を混在させることができるので、Azure Cosmos DB データベース内の一部のコンテナーについてはデータベースのプロビジョニング済みスループットを共有し、同時に、同じデータベース内の他のコンテナーでは専用のプロビジョニング済みスループット量を利用することができます。
上記の戦略を適用してハイブリッド構成を実現し、データベース レベルのプロビジョニング済みスループットと、コンテナー専用のスループットを併用できます。
次の表に示すように、API の選択に応じて、異なる細かさでスループットをプロビジョニングできます。
| API | 共有スループットの場合の構成対象 | 専用スループットの場合の構成対象 |
|---|---|---|
| NoSQL 用 API | データベース | コンテナー |
| Azure Cosmos DB の MongoDB 用 API | データベース | コレクション |
| Cassandra 用 API | キースペース | テーブル |
| Gremlin 用 API | データベース アカウント | グラフ |
| Table 用 API | データベース アカウント | テーブル |
異なるレベルでスループットをプロビジョニングすることにより、ワークロードの特性に基づいてコストを最適化できます。 前に説明したように、プログラムを使用していつでも、個々のコンテナーについて、またはコンテナーのセットで集合的に、プロビジョニング済みスループットを増やしたり減らしたりできます。 ワークロードの変化に応じてスループットを弾力的にスケーリングすることで、支払いは構成したスループットに対するものだけで済みます。 コンテナーまたはコンテナーのセットが複数のリージョンに分散されている場合、そのコンテナーまたはコンテナーのセットで構成するスループットがすべてのリージョンで使用可能になることが保証されます。
要求のレート制限で最適化する
待ち時間が重要ではないワークロードの場合は、プロビジョニングするスループットを少なくし、実際のスループットがプロビジョニング済みスループットを超えたときはアプリケーションでレート制限を処理することができます。 サーバーはいち早く RequestRateTooLarge (HTTP 状態コード 429) で要求を終了させ、要求を再試行するまでにユーザーが待機しなければならない時間 (ミリ秒) を示す x-ms-retry-after-ms ヘッダーを返します。
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK での再試行ロジック
ネイティブ SDK (.NET/.NET Core、Java、Node.js、Python) ではこの応答が暗黙的にキャッチされて、サーバーが指定した retry-after ヘッダーを優先して要求が再試行されます。 アカウントに複数のクライアントが同時アクセスしている状況でなければ、次回の再試行は成功します。
累積的に動作する複数のクライアントがあり、要求レートを常に超えている場合は、現在 9 に設定されている既定の再試行回数では十分ではない可能性があります。 このような場合、クライアントではアプリケーションに対して状態コード 429 の RequestRateTooLargeException がスローされます。 既定の再試行回数は、ConnectionPolicy インスタンスで RetryOptions を設定することで変更できます。 既定では、要求レートを超えて要求が続行されている場合に、30 秒の累積待機時間を過ぎると、状態コード 429 を含む RequestRateTooLargeException が返されます。 これは、現在の再試行回数が最大再試行回数 (既定値の 9 またはユーザー定義の値) より少ない場合でも発生します。
MaxRetryAttemptsOnThrottledRequests が 3 に設定されます。そのため、ここでは、コンテナーに予約されているスループットを超過し、要求操作がレート制限される場合、その要求操作は 3 回まで再試行し、成功しなければアプリケーションに例外をスローします。 MaxRetryWaitTimeInSeconds が 60 に設定されています。そのため、ここでは、最初の要求後、累積再試行時間 (秒) が 60 秒を超過すると、例外がスローされます。
ConnectionPolicy connectionPolicy = new ConnectionPolicy();
connectionPolicy.RetryOptions.MaxRetryAttemptsOnThrottledRequests = 3;
connectionPolicy.RetryOptions.MaxRetryWaitTimeInSeconds = 60;
パーティション分割戦略とプロビジョニング済みスループット コスト
Azure Cosmos DB でのコストを最適化するには、適切なパーティション分割戦略が重要です。 パーティションの不均衡がないことを確認します。これはストレージのメトリックで公開されます。 パーティションに対してスループットの不均衡がないことを確認します。これは、スループットのメトリックで公開されます。 特定のパーティション キーに対する偏りがないことを確認します。 ストレージでの主要なキーはメトリックを通じて公開されますが、キーはアプリケーションのアクセス パターンに依存します。 適切な論理パーティション キーについて考慮するのが最善です。 適切なパーティション キーは、次のような特性を持つことが期待されます。
すべてのパーティションと時間で均等にワークロードが分散されるパーティション キーを選択します。 つまり、一部のキーにデータの多くが集中し、他のキーにはデータがほとんど、またはまったくないということがあってはなりません。
アクセス パターンが論理パーティション間で均等に分散されるパーティション キーを選択します。 ワークロードをすべてのキーの間である程度一定にします。 つまり、ワークロードの大部分が少数の特定のキーに集中してはなりません。
値の範囲が広いパーティション キーを選択します。
基本的な考え方は、コンテナー内のデータとアクティビティを一連の論理パーティションに分散し、データ ストレージとスループットのリソースを論理パーティション間に分散できるようにすることです。 パーティション キーの候補には、クエリでフィルターとして頻繁に出現するプロパティが含まれる場合があります。 フィルターの述語にパーティション キーを含めることで、クエリ呼び出しを効率的にルーティングできます。 このようなパーティション分割戦略を使うと、プロビジョニング済みスループットの最適化がずっと容易になります。
スループットが高いほどアイテムが小さくなるように設計する
特定の操作の要求の使用量または要求処理コストは、アイテムのサイズに直接関係します。 大きいアイテムの操作には小さいアイテムの操作よりコストがかかります。
データ アクセス パターン
データへのアクセス頻度に基づいて論理カテゴリにデータを論理的に分割するのは、常によい方法です。 それをホット データ、ミディアム データ、コールド データに分類することによって、消費されるストレージと必要なスループットを細かく調整できます。 アクセスの頻度に応じて、データを異なるコンテナー (たとえば、テーブル、グラフ、コレクション) に配置し、それらのプロビジョニング済みスループットを微調整して、データのそのセグメントのニーズに対応できます。
さらに、Azure Cosmos DB を使っていて、特定のデータ値で検索を行わないこと、またはそれにほとんどアクセスしないことがわかっている場合は、これらの属性の圧縮された値を格納する必要があります。 このようにすると、ストレージ領域、インデックス領域、プロビジョニング済みスループットが節約されて、コストを削減できます。
インデックス作成ポリシーを変更することで最適化する
Azure Cosmos DB では既定で、すべてのレコードのすべてのプロパティに自動的にインデックスが付けられます。 これは、開発を容易にし、さまざまな種類のアドホック クエリで優れたパフォーマンスを確保するために行われます。 何千ものプロパティを含む大きいレコードがある場合、すべてのプロパティにインデックスを付けるためにスループットのコストを払うのは無益なことがあります。そのようなプロパティの 10 個とか 20 個に対してしかクエリを行わない場合は特にそうです。 特定のワークロードについての理解が深まったら、インデックス ポリシーを調整することをお勧めします。 Azure Cosmos DB でのインデックス作成ポリシーについて詳しくは、こちらをご覧ください。
プロビジョニング済みスループットと消費済みスループットを監視する
プロビジョニングされた要求ユニットの総数、レート制限された要求の数、消費された RU の数を、Azure portal で監視できます。 詳しくは、「Azure Cosmos DB メトリックの分析」をご覧ください。 次の図では使用量メトリックの例を示します。
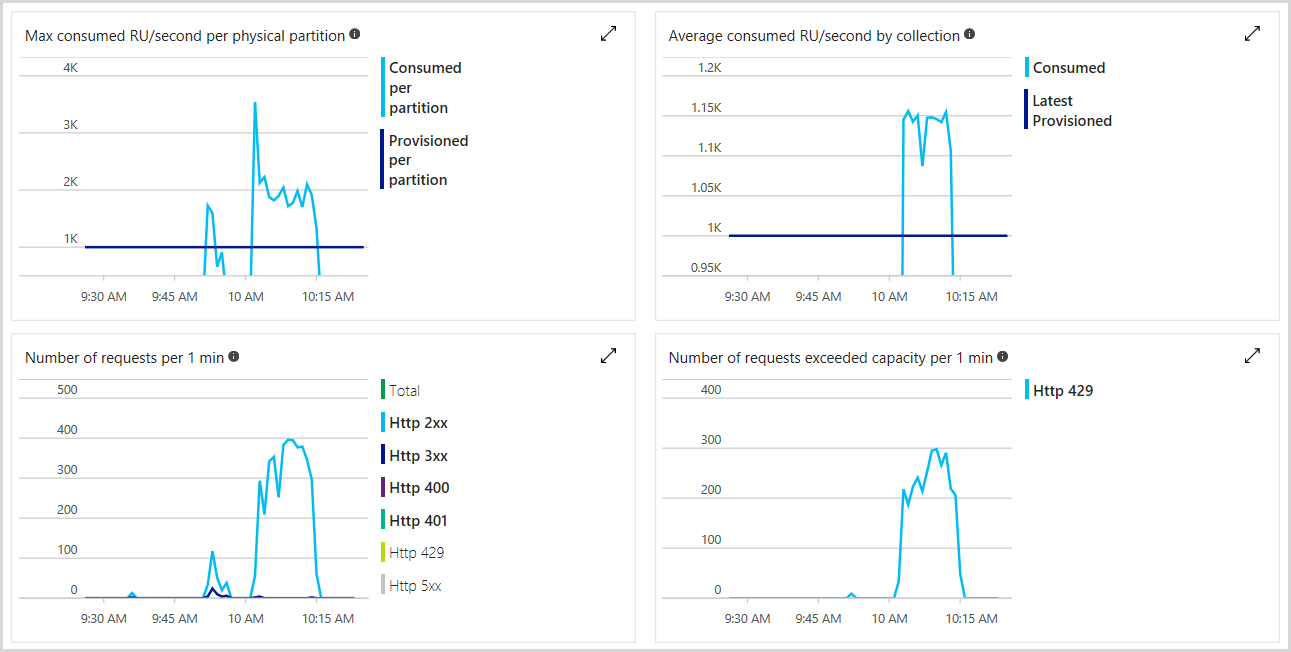
レート制限された要求の数が特定のしきい値を超えたかどうかを確認するアラートを設定することもできます。 アラートについて詳しくは、Azure Monitor のアラートに関する記事をご覧ください。
弾力的にオンデマンドでスループットをスケーリングする
プロビジョニングされたスループットに対して課金されるので、プロビジョニング済みスループットをニーズと一致させることが、未使用のスループットに課金されるのを防ぐのに役立ちます。 必要に応じていつでも、プロビジョニング済みスループットをスケールアップまたはスケールダウンできます。 スループットのニーズを正確に予測できる場合は、Azure Functions とタイマー トリガーを使用し、スケジュールに従ってスループットを増減することができます。
RU の消費量と、レート制限された要求の割合を監視すると、日または週を通してプロビジョニング済みスループットを一定に保つ必要がないことがわかる場合があります。 夜間や週末は、受け取るトラフィックが減ることがあります。 Azure portal または Azure Cosmos DB のネイティブ SDK や REST API を使用すると、いつでもプロビジョニング済みスループットをスケーリングできます。 Azure Cosmos DB の REST API では、コンテナーのパフォーマンス レベルをプログラムで更新するためのエンドポイントが提供されており、時間帯や曜日に応じてコードから簡単にスループットを調整できます。 操作はダウンタイムなしで実行され、通常は 1 分未満で有効になります。
スループットのスケーリングが必要になる場合の 1 つは、Azure Cosmos DB にデータを取り込むときです (たとえば、データ移行中)。 移行が完了したら、プロビジョニング済みスループットをスケールダウンして、ソリューションの安定した状態を処理できます。
課金の最小単位が 1 時間であることを思い出してください。そのため、1 時間に複数回プロビジョニング済みスループットを変更した場合、コストの節約にはなりません。
新しいワークロードに必要なスループットを判断する
新しいワークロードのプロビジョニング済みスループットを決定するには、次の手順を使用できます。
最初に容量計画ツールを使用して大まかに評価し、Azure portal で Azure Cosmos DB Explorer を使用して見積もりを調整します。
予想より高いスループットでコンテナーを作成し、必要に応じてスケールダウンすることをお勧めします。
いずれかの Azure Cosmos DB ネイティブ SDK を使用して、要求がレート制限を受けたときに自動再試行されるようにすることをお勧めします。 サポートされていないプラットフォームで作業していて、Azure Cosmos DB の REST API を使用する場合は、
x-ms-retry-after-msヘッダーを使用して独自の再試行ポリシーを実装します。アプリケーションのコードで、すべての再試行が失敗した場合が適切にサポートされていることを確認します。
レート制限に対する通知を受け取るように、Azure portal からのアラートを構成することができます。 過去 15 分間にレート制限された要求が 10 件のような控え目な制限から始めて、実際の消費量を把握したら、さらに積極的な制限に切り替えることができます。 ときどきレート制限が発生しても問題ありません。それは設定した制限が動作していて、意図したとおりになっていることを示します。
日または週の間にスループットのプロビジョニングを動的に調整する必要があるかどうかを検討できるよう、監視を使用してトラフィックのパターンを把握します。
プロビジョニング済みスループットと消費済みスループットの比率を定期的に監視し、必要な数より多くのコンテナーおよびデータベースをプロビジョニングしていないことを確認します。 スループットを少しだけオーバー プロビジョニングすることは、適切な安全性チェックです。
プロビジョニング済みスループットの最適化に関するベスト プラクティス
以下の手順は、Azure Cosmos DB を使用するときにソリューションのスケーラビリティとコスト効率を高くするのに役立ちます。
コンテナーやデータベースに大幅にオーバー プロビジョニングされたスループットがある場合は、プロビジョニングされた RU と消費された RU を確認して、ワークロードを微調整する必要があります。
アプリケーションに必要な予約済みスループットの量を推定するには、典型的な操作の実行に関連する要求ユニット (RU) の料金を記録し、アプリケーションが使用する代表的な Azure Cosmos DB コンテナーまたはデータベースに基づいて、1 秒ごとに実行される操作数を推定します。 さらに、通常のクエリとそれらの使用量も忘れずに測定し、考慮に入れます。 プログラムまたはポータルでクエリの RU コストを見積もる方法については、クエリのコストの最適化に関する記事をご覧ください。
操作とその RU コストを取得するもう 1 つの方法は、Azure Monitor ログを有効にすることで、操作/継続時間と要求の料金の明細が提供されます。 Azure Cosmos DB では、すべての操作に対して要求の料金が提供されるので、すべての操作の料金を応答から保存して、分析に使用できます。
プロビジョニング済みスループットを弾力的にスケールアップおよびスケールダウンして、ワークロードのニーズに対応できます。
必要に応じて Azure Cosmos DB アカウントに関連付けられているリージョンを追加および削除し、コストを管理できます。
コンテナーの論理パーティション間にデータとワークロードが均等に分散されていることを確認します。 パーティション間の分散が均等でない場合、スループットのプロビジョニング量が必要な値より高くなる可能性があります。 不均衡な分散があることを特定した場合は、パーティション間に均等にワークロードを再分配するか、またはデータを再パーティション分割することをお勧めします。
多くのコンテナーがあり、それらのコンテナーで SLA が必要ない場合は、コンテナー単位のスループット SLA が適用されないデータベースに基づくプランを使用できます。 データベース レベルのスループット オファーに移行する Azure Cosmos DB コンテナーを特定した後、変更フィード ベースのソリューションを使用してそれらを移行する必要があります。
開発/テストのシナリオには、"Azure Cosmos DB Free レベル" (1 年間無料)、Azure Cosmos DB を試す (最大 3 リージョン)、またはダウンロード可能な Azure Cosmos DB Emulator を使用することを検討します。 テストや開発にこれらのオプションを使用すると、コストを大幅に削減できます。
バッチ サイズの拡大、複数リージョンへの読み取りの負荷分散、データの重複除去など、該当する場合は、ワークロード固有のコスト最適化をさらに実行できます。
Azure Cosmos DB の予約容量を利用すると、3 年間最大 65% という大幅な割引を受けることができます。 Azure Cosmos DB の予約容量モデルは、一定期間に必要な要求ユニットに対する前払いのコミットメントです。 割引は、要求ユニットの使用期間が長いほど、割引額が大きくなるように、階層化されています。 これらの割引は、すぐに適用されます。 プロビジョニングされた値を超えて使用された RU は、予約容量ではないコストに基づいて課金されます。 詳細については、Azure Cosmos DB の予約容量に関する記事を参照してください。 プロビジョニング済みスループットのコストをさらに下げるには、予約容量の購入を検討してください。
次のステップ
次は、先に進み、以下の各記事で Azure Cosmos DB でのコストの最適化の詳細について学習することができます。
- Azure Cosmos DB への移行のための容量計画を実行しようとしていますか? 容量計画のために、既存のデータベース クラスターに関する情報を使用できます。
- 既存のデータベース クラスター内の仮想コアとサーバーの数のみがわかっている場合は、仮想コア数または仮想 CPU 数を使用した要求ユニットの見積もりに関するページを参照してください
- 現在のデータベース ワークロードに対する通常の要求レートがわかっている場合は、Azure Cosmos DB Capacity Planner を使用した要求ユニットの見積もりに関するページを参照してください
- 開発とテストのための最適化の詳細について学習します
- Azure Cosmos DB の課金内容の確認の詳細について学習します
- ストレージ コストの最適化の詳細について学習します
- 読み取りと書き込みのコストの最適化の詳細について学習します
- クエリ コストの最適化の詳細について学習します
- 複数リージョンの Azure Cosmos DB アカウントのコストの最適化の詳細について学習します