正常性チェック
CycleCloud には、VM の正常性をチェックするための 2 つのメカニズムが用意されています。ノード正常性チェックは、プロビジョニング ステージ中にチェックを実行し、異常な VM が参加するのを防ぐ新しい機能です。一方、HealthCheck は、VM がクラスターにノードとして参加した後に定期的に実行します。
ノードの正常性チェック
Node Health Checks では、VM が CycleCloud クラスターへの参加を許可される前に、異常なハードウェアを検出できます。 この機能の現在のバージョンでは、/opt/azurehpc/test/azurehpc-health-checks/ の下にある公式の AzureHPC イメージに組み込まれている正常性チェックスクリプトが実行されます。 これらのスクリプトのソースは AzureHPC Node Health Checks リポジトリにありますが、クラスターのバージョンの AzureHPC イメージに組み込まれているバージョンは、リポジトリで使用できる最新のバージョンではない可能性があることに注意してください。
要件
現在のバージョンの Node Health Checks では、2023 年 11 月 7 日以降にリリースされた AzureHPC イメージ (azurehpc-health-checks バージョン v2.0.6 以降を含む) と、そこから派生したカスタム イメージのみがサポートされています。 Node Health Checks は現在、Windows ではサポートされていません。
Slurm クラスターのノード正常性チェックの有効化
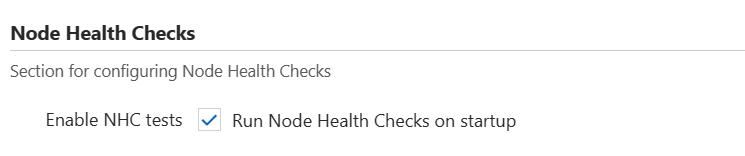
[Slurm クラスターの作成] フォームには、[ 詳細設定] タブにある [ノード正常性チェック] を有効にするチェック ボックスが用意されています。チェック ボックスをオンにすると、クラスターの HPC ノード配列でノード正常性チェックが有効になります。 他のノード配列 (または他のクラスターの種類) でノード正常性チェックを有効にする場合は、カスタム クラスター テンプレートを使用する必要があります。
ノード正常性チェックは、チェック ボックスをオフにするだけで、実行中のクラスターで無効にすることができます。 変更を有効にするためにノード配列をスケールダウンする必要はありません。
ノード正常性チェックの結果について
VM が正常性チェックに合格すると、ソフトウェア構成フェーズに進みます。
VM がいずれかの正常性チェックスクリプトに失敗した場合、エラー メッセージが CycleCloud に送信され、VM がクラスターに参加することが自動的に防止されます。
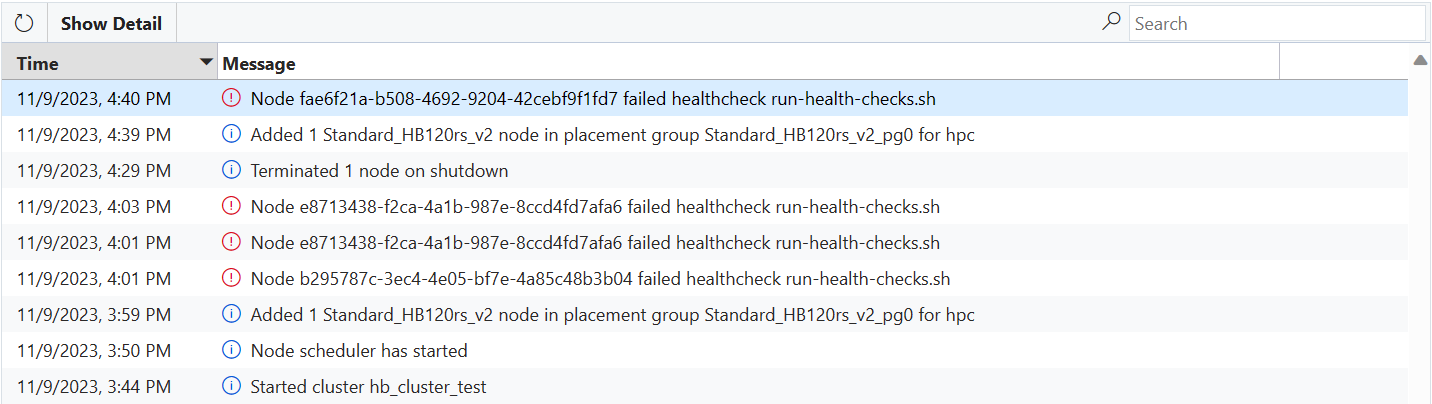
過剰プロビジョニングが有効になっている NodeArray (Slurm hpc Node Array など) で VM が起動された場合、VM は過剰プロビジョニングの一環として自動的に置き換えられます。 その場合、アクションは必要なく、正常な VM がクラスターに参加するように選択されます (ただし、1 つ以上の VM がチェックに失敗したことを示すエラー メッセージがクラスター ページに表示されます)。
VM が 1 つのノードに対して起動されている場合、過剰プロビジョニングが無効になっている Node Array (Slurmht Node Array など) や、過剰プロビジョニングでサポートされている VM よりも多くの VM が正常性チェックに失敗した場合、ノードは Failed 状態に移行し、割り当ては失敗します。 CycleCloud は問題を修正するために VM の再イメージ化を試みる場合がありますが、再イメージ化に失敗した場合は、ノードを終了して置き換える必要があります (手動で管理者または自動スケーラーによって自動的に)。
注意
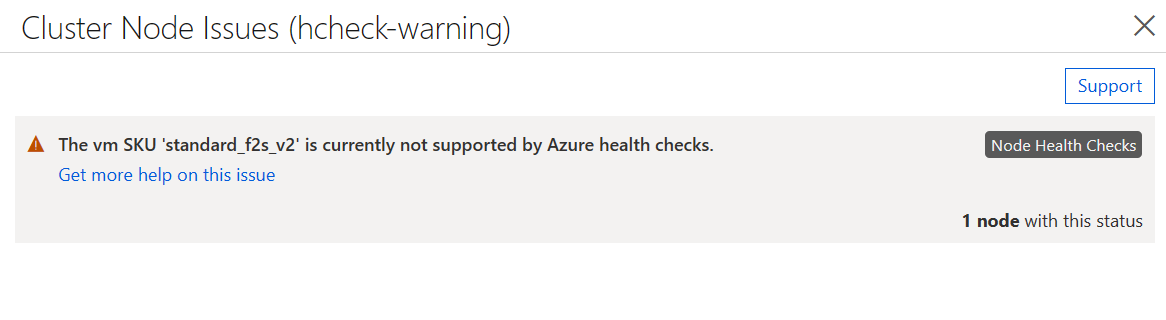
Node Health Checks を有効にしたが、VM イメージが上記の要件を満たしていない場合、すべての VM がクラスターへの参加を許可されますが、状態にはチェックがサポートされていないことを示す警告が含まれます。
属性リファレンス
| 属性 | Type | 定義 |
|---|---|---|
| EnableNodeHealthChecks | ブール値 | (省略可能)このノードまたはノード配列のオンブート ノード正常性チェックを有効にする |
HealthCheck
Azure CycleCloud には、HealthCheck と呼ばれる異常な状態の仮想マシン (VM) を終了するためのメカニズムが用意されています。 システム定義スクリプトとユーザー定義スクリプト (Python と Bash) の両方が定期的に実行され (Windows では 5 分、Linux では 10 分)、VM の全体的な正常性が判断されます。 HealthCheck を使用すると、管理者は、手動で監視および修復することなく、VM を終了する条件を定義できます。
HealthCheck スクリプトに組み込まれている
CycleCloud 対応 VM には、2 つの既定の HealthCheck スクリプトが付属しています。
-
converge_timeout スクリプトは、起動から 4 時間以内にソフトウェア構成が完了していないインスタンスを終了します。 このタイムアウト期間は、設定 (秒単位で定義) で制御
cyclecloud.keepalive.timeoutできます。 - scheduled_shutdown スクリプトは、unix タイムスタンプ秒のシャットダウン時間と説明付きのオプションの 2 行目を示す 1 行を含む、$JETPACK_HOME/run/scheduled_shutdown内の maker ファイルを検索します。 現在の時刻がファイル内の最も古いタイムスタンプより後の場合、VM は異常と見なされます。
しくみ
HealthCheck スクリプトは 、$JETPACK_HOME/config/healthcheck.d ディレクトリにあります。 Linux では Python スクリプトと Bash スクリプトの両方がサポートされていますが、Windows では Python スクリプトのみがサポートされています。 スクリプトは、VM の正常性を決定する必要があります。 VM が異常であることが判明した場合、スクリプトは の状態 254で終了する必要があります。これは、VM が異常であり、終了する必要があることを CycleCloud に示します。
HealthCheck を実行している VM にログオンしている場合は、 jetpack keepalive コマンドを実行することで、VM がシャットダウンされないようにすることができます。 Linux インスタンスでは、時間枠を時間単位で指定することも forever 、Windows forever 上で指定することもできます。
注意
VM が異常であると判断されると、HealthCheck エージェントは CycleCloud に VM の終了を要求します。コマンドを使用して shutdown VM がローカルでシャットダウンされることはありません。 VM が CycleCloud と通信できない場合、Vm は、CycleCloud に到達できる時間まで異常な状態でも稼働します。
例
簡単な例として、Linux VM が 24 時間以上アクティブでないことを確認する HealthCheck スクリプトを記述します。 このスクリプトを使用して、低優先度の削除をシミュレートして、削除された VM に対するワークフローの反応をテストできます。 このスクリプトは、/opt/cycle/jetpack/config/healthcheck.d/healthcheck_example.sh に配置されます
#!/bin/bash
# Get the uptime of the system (in seconds) and check to see if it is
# greater than 86,400 (24 hours in seconds). If it is, exit 254 to
# signal that the VM is unhealthy.
if (( $(cat /proc/uptime | awk '{print ($1 > 86400)}'))); then
exit 254
fi
注意
このスクリプトは、 CycleCloud プロジェクト を使用するか、 カスタム イメージの作成時に直接追加することで、VM に配置できます。