マッピング データ フローのデバッグ モード
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
概要
Azure Data Factory および Synapse Analytics のマッピング データ フローのデバッグ モードを使用すると、データ フローの構築およびデバッグ時にデータ シェイプの変換を対話的に監視できます。 デバッグ セッションは、Data Flow のデザイン セッションと、データ フローのパイプライン デバッグ実行中に使用できます。 デバッグ モードを有効にするには、データ フロー アクティビティがある状態で、データ フロー キャンバスまたはパイプライン キャンバスの上部のバーにある [Data Flow のデバッグ] ボタンを使用します。
![[デバッグ] スライダーの場所を示すスクリーンショット 1](media/data-flow/debug-button.png)
![[デバッグ] スライダー の場所を示すスクリーンショット 2](media/data-flow/debug-button-4.png)
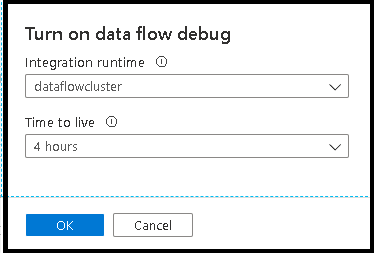
スライダーを有効にすると、使用する統合ランタイム構成を選択するように求めるメッセージが表示されます。 AutoResolveIntegrationRuntime を選択した場合は、既定の 60 分の Time to Live が設定された一般的なコンピューティングの 8 個のコアを持つクラスターがスピンアップされます。 セッションのタイムアウトまでのアイドル時間を増やす場合は、より高い TTL 設定を選択できます。 データ フロー統合ランタイムの詳細については、「Integration Runtime のパフォーマンス」を参照してください。
デバッグ モードが有効なときは、アクティブな Spark クラスターを使用して対話的にデータ フローを構築します。 デバッグを無効にすると、セッションは終了します。 デバッグ セッションを有効にしている間に Data Factory によって発生する 1 時間あたりの料金を把握しておく必要があります。
ほとんどの場合は、デバッグ モードでデータ フローを構築し、ビジネス ロジックを検証してデータ変換を確認してから、作業内容を公開することをお勧めします。 パイプライン パネルの [デバッグ] ボタンを使用して、パイプライン内部のデータ フローをテストします。
注意
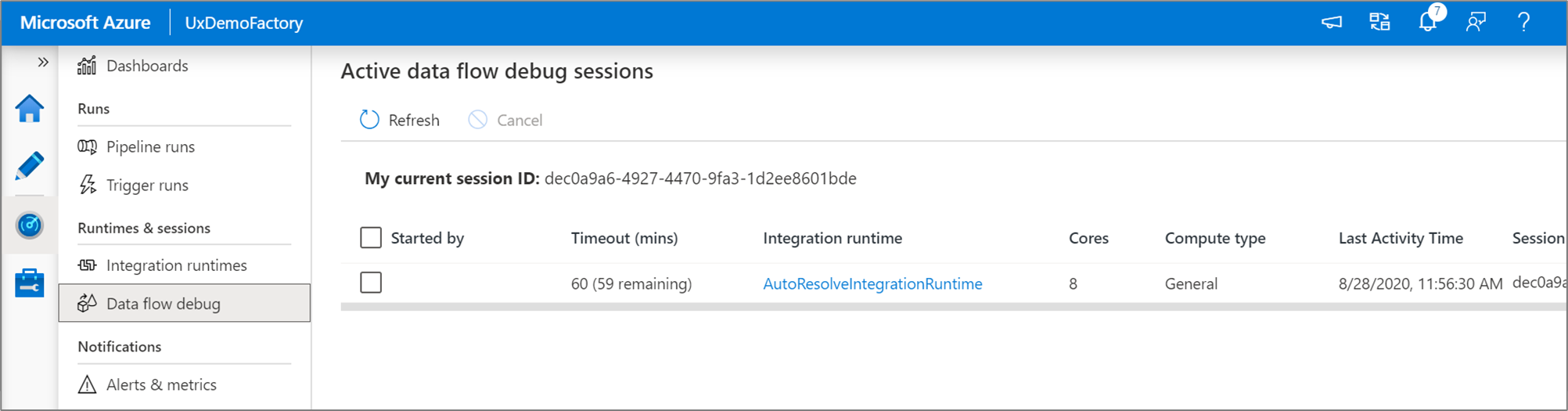
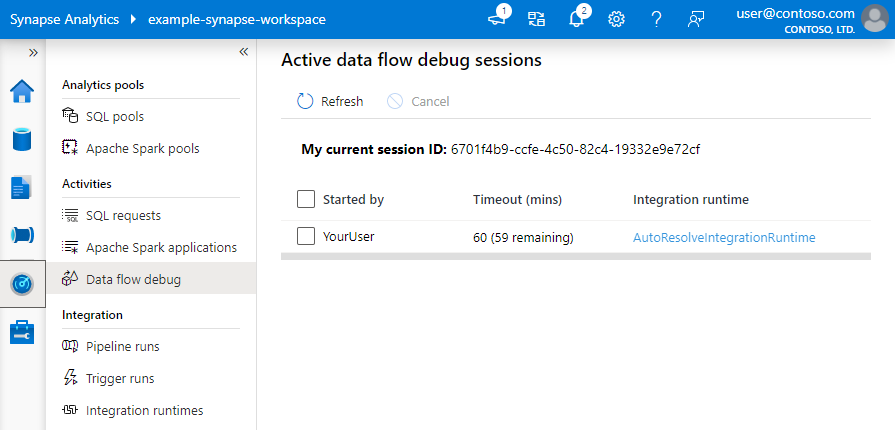
ユーザーがブラウザー UI から開始するすべてのデバッグ セッションは、独自の Spark クラスターを使用する新しいセッションです。 前の図に示されているデバッグ セッションの監視ビューを使用して、デバッグ セッションを表示および管理できます。 TTL 時間を含め、各デバッグ セッションの実行時間に対し、時間単位で課金されます。
このビデオ クリップでは、データ フロー デバッグ モードに関するヒント、テクニック、および推奨される方法について説明します。
クラスターの状態
クラスターのデバッグの準備が整うと、デザイン サーフェスの上部にあるクラスター状態インジケーターが緑色に変わります。 クラスターが既に実行されている場合、緑色のインジケーターはほぼ瞬時に表示されます。 デバッグ モードに入ったときにクラスターがまだ実行されていなかった場合、Spark クラスターではコールド ブートが実行されます。 インジケーターは、対話型デバッグのための環境の準備が整うまでスピンします。
デバッグが終了したら、[デバッグ] スイッチをオフにして、Spark クラスターを終了できるようにし、デバッグ アクティビティについて課金されないようにします。
デバッグの設定
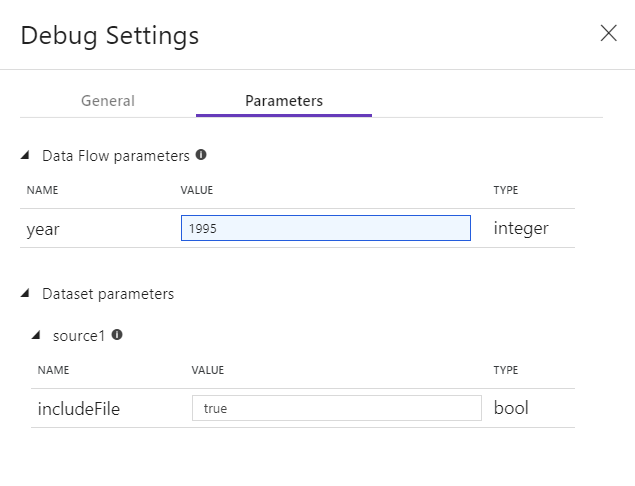
デバッグ モードを有効にすると、データ フローでデータをプレビューする方法を編集できます。 デバッグ設定は、Data Flow のキャンバス ツール バーにある [Debug Settings] (デバッグ設定) をクリックすることで編集できます。 ここで、各ソース変換に使用する行制限やファイル ソースを選択できます。 この設定の行制限の対象となるのは、現在のデバッグ セッションのみです。 Azure Synapse Analytics ソースに使用するステージング リンク サービスを選択することもできます。
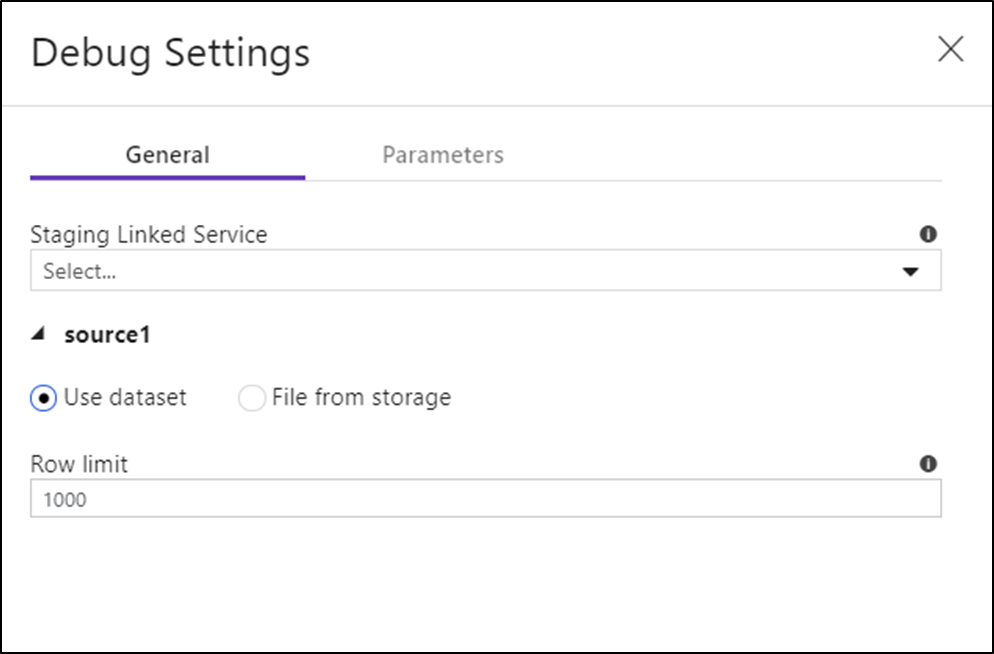
データフローまたは参照されているデータセットにパラメーターがある場合は、[パラメーター] タブを選択して、デバッグ中に使用する値を指定できます。
ここでサンプリング設定を使用して、データのサンプル ファイルまたはサンプル テーブルを参照します。これにより、ソース データセットを変更する必要がなくなります。 ここでサンプル ファイルまたはテーブルを使用することで、データのサブセットに対してテストを行うときに、データ フロー内で同じロジックやプロパティの設定を維持することができます。
データ フローでデバッグ モードに使用される既定の IR は、4 コアの単一ドライバー ノードを持つ小さな 4 コアのシングル ワーカー ノードです。 これは、データ フロー ロジックをテストするときの小さなデータ サンプルで問題なく動作します。 データ プレビューの間にデバッグ設定で行の制限を拡張する場合、またはパイプライン デバッグの間にソースでサンプリングされる行数に高い値を設定する場合は、新しい Azure Integration Runtime でさらに大きいコンピューティング環境を設定することを検討できます。 その後、より大きなコンピューティング環境を使用してデバッグ セッションを再開できます。
データのプレビュー
デバッグが有効な場合、下部のパネルに [データのプレビュー] タブが表示されます。 デバッグが有効ではない場合、Data Flow では、各変換に含まれる、または含まれない現在のメタデータのみが [検査] タブに表示されます。データのプレビューでは、デバッグ設定で制限として設定した行数のみのクエリが実行されます。 [更新する] を選択して、現在の変換に基づいてデータ プレビューを更新します。 ソース データが変更された場合は、[更新] > [ソースから再フェッチ] を選択します。
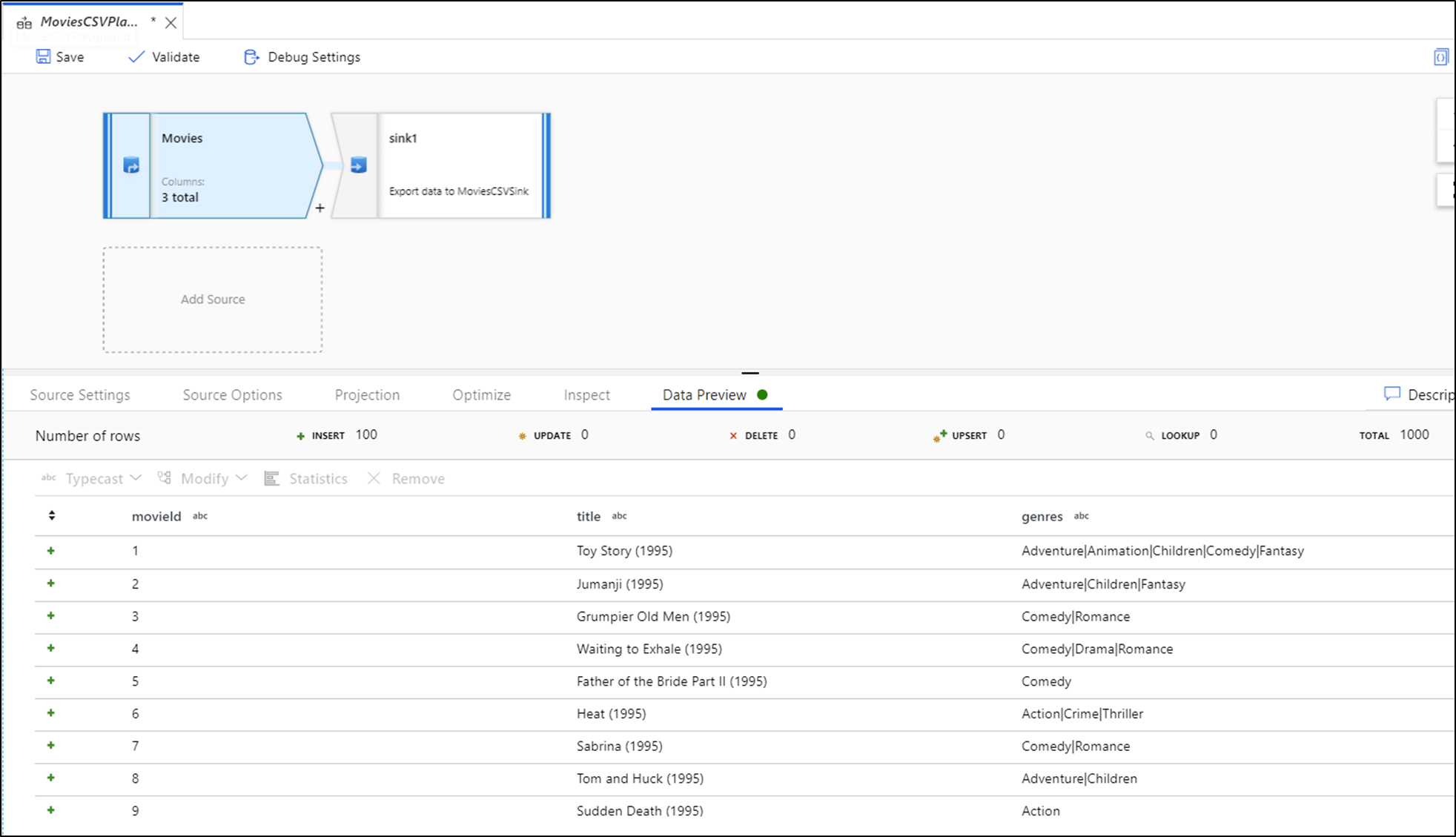
データ プレビューで列を並べ替え、ドラッグ アンド ドロップを使用して列を再配置することができます。 さらに、データ プレビュー パネルの上部にエクスポート ボタンがあり、プレビュー データを CSV ファイルにエクスポートしてオフライン データの探索に使用できます。 この機能を使用すると、最大 1,000 行のプレビュー データをエクスポートできます。
注意
ファイル ソースでは、読み取られる行ではなく、表示される行のみを制限します。 データセットが非常に大規模な場合は、そのファイルのごく一部を取得して、ご自身のテストに使用することをお勧めします。 [Debug Settings](デバッグ設定) では、ファイル データセットの種類のソースごとに一時ファイルを選択できます。
デバッグ モードで Data Flow を実行している場合、データはシンク変換に書き込まれません。 デバッグ セッションは、変換のテスト ハーネスとして機能することを目的としています。 シンクはデバッグ中には必要ではなく、データ フローでは無視されます。 シンクへのデータの書き込みをテストする場合は、パイプラインから Data Flow を実行し、パイプラインからデバッグの実行を使用します。
データ プレビューは、Spark メモリ内のデータ フレームからの、行制限とデータ サンプリングを使用して変換されたデータのスナップショットです。 そのため、このシナリオでは、シンク ドライバーは使用またはテストされません。
Note
データのプレビューでは、ブラウザーのロケール設定に従って時間が表示されます。
結合条件のテスト
Join、Exists、または Lookup の変換を単体テストする場合、ご自身のテストには必ず小規模な既知のデータを使用するようにしてください。 前述の [デバッグ設定] オプションを使用すると、ご自身のテストで使用する一時ファイルを設定できます。 これは、大規模なデータセットから行を制限したり、サンプリングしたりするときに、どの行およびどのキーがテストのフローに読み込まれるかを予測できないために必要です。 結果は非決定論的であり、ご自身の結合条件が失敗する可能性があります。
クイック アクション
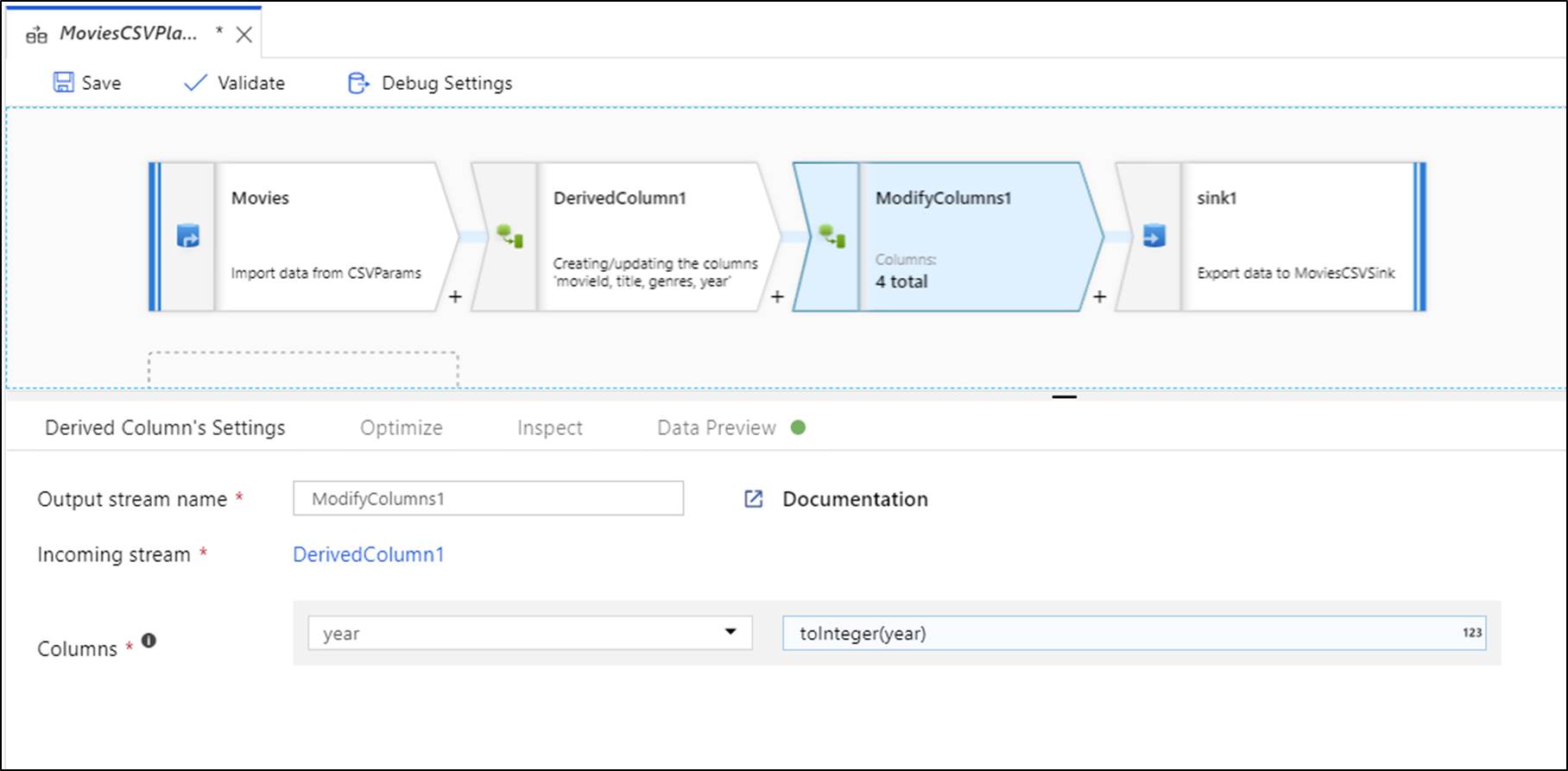
データのプレビューが表示されたら、クイック変換を生成して、列に対する型キャスト、削除、または変更を行うことができます。 列見出しを選択した後、[データのプレビュー] ツールバーからいずれかのオプションを選択します。
![スクリーンショットには、次のオプションが含まれる [データのプレビュー] ツールバーが示されています:[型キャスト]、[変更]、[統計]、および [削除]。](media/data-flow/quick-actions1.png)
[変更] を選択すると、データのプレビューがすぐに更新されます。 新しい変換を生成するには、右上隅にある [確認] を選択します。
![スクリーンショットには [確認] ボタンが示されています。](media/data-flow/quick-actions2.png)
[型キャスト] と [変更] では派生列変換が生成され、[削除] では選択変換が生成されます。
注意
データフローを編集する場合は、クイック変換を追加する前にデータのプレビューを再フェッチする必要があります。
データ プロファイル
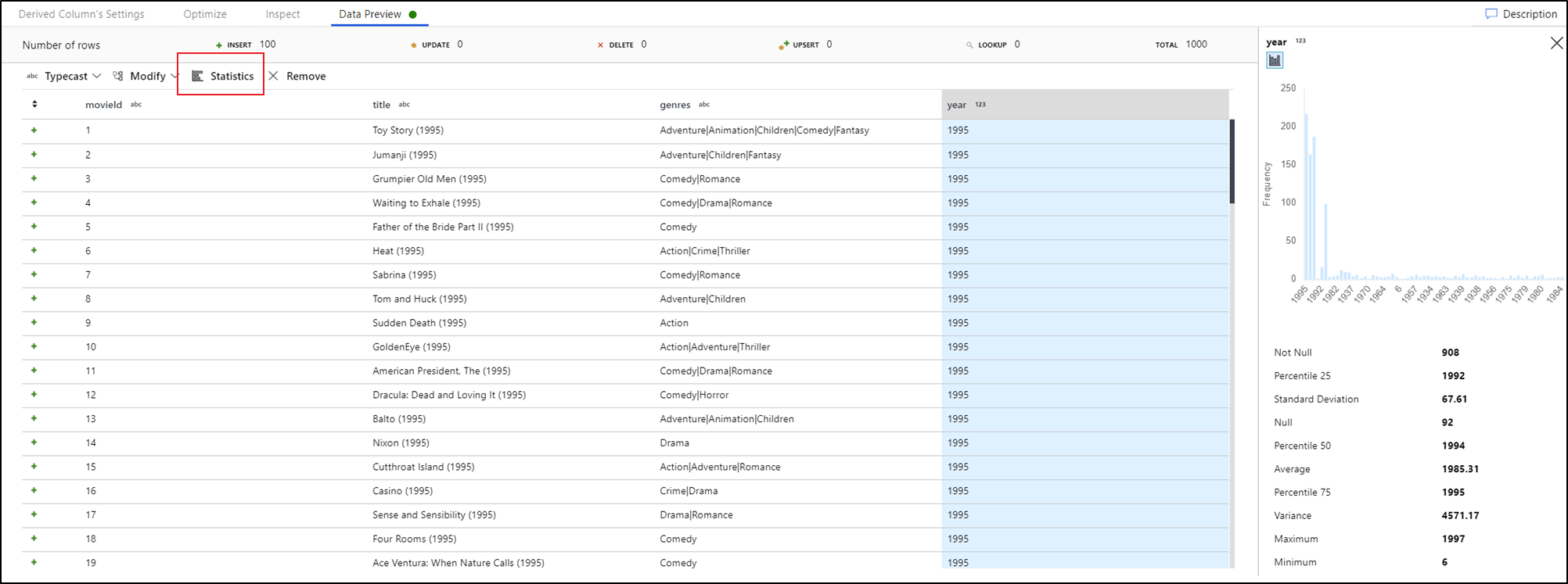
[データのプレビュー] タブで列を選択し、[データのプレビュー] ツール バーで [統計] をクリックすると、データ グリッドの右端にグラフがポップアップ表示され、各フィールドに関する詳細な統計情報が示されます。 このサービスでは、表示するグラフの種類のデータ サンプリングに基づいて判断が下されます。 カーディナリティが高いフィールドの既定は NULL/NOT NULL グラフです。一方、カーディナリティが低いカテゴリ データや数値データでは、データ値の頻度を示す棒グラフが表示されます。 また、文字列フィールドの最大/長さ、数値フィールドの最小/最大値、標準偏差、百分位、カウント、および平均も表示されます。
関連するコンテンツ
- データ フローの構築とデバッグが完了したら、パイプラインからデータ フローを実行します。
- データ フローでパイプラインをテストする場合は、パイプラインのデバッグ実行の実行オプションを使用します。