Azure Data Factory を使用して Hive からデータをコピーおよび変換する
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
この記事では、Azure Data Factory または Synapse Analytics パイプラインでコピー アクティビティを使用して、Hive からデータをコピーする方法について説明します。 この記事は、コピー アクティビティの概要を示しているコピー アクティビティの概要に関する記事に基づいています。
サポートされる機能
この Hive コネクタでは、次の機能がサポートされます。
| サポートされる機能 | IR |
|---|---|
| Copy アクティビティ (ソース/-) | ① ② |
| マッピング データ フロー (ソース/-) | ① |
| Lookup アクティビティ | ① ② |
① Azure 統合ランタイム ② セルフホステッド統合ランタイム
コピー アクティビティによってソースまたはシンクとしてサポートされているデータ ストアの一覧については、サポートされているデータ ストアに関する記事の表をご覧ください。
このサービスでは接続を有効にする組み込みのドライバーが提供されるので、このコネクタを使用してドライバーを手動でインストールする必要はありません。
コネクタは、この記事の Windows バージョンをサポートしています。
前提条件
データ ストアがオンプレ ミスネットワーク、Azure 仮想ネットワーク、または Amazon Virtual Private Cloud 内にある場合は、それに接続するようセルフホステッド統合ランタイムを構成する必要があります。
データ ストアがマネージド クラウド データ サービスである場合は、Azure Integration Runtime を使用できます。 ファイアウォール規則で承認されている IP にアクセスが制限されている場合は、Azure Integration Runtime の IP を許可リストに追加できます。
また、Azure Data Factory のマネージド仮想ネットワーク統合ランタイム機能を使用すれば、セルフホステッド統合ランタイムをインストールして構成しなくても、オンプレミス ネットワークにアクセスすることができます。
Data Factory によってサポートされるネットワーク セキュリティ メカニズムやオプションの詳細については、「データ アクセス戦略」を参照してください。
作業の開始
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用します。
UI を使用して Hive へのリンク サービスを作成する
次の手順を使用して、Azure portal UI で Hive へのリンク サービスを作成します。
Azure Data Factory または Synapse ワークスペースの [管理] タブに移動し、[リンクされたサービス] を選択して、[新規] をクリックします。
Hive を検索して、Hive コネクタを選択します。
サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
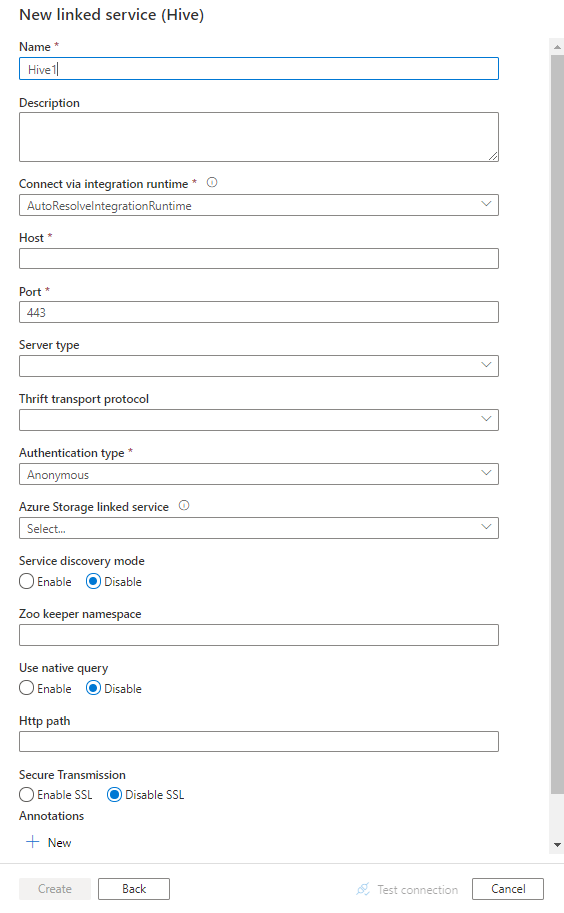
コネクタの構成の詳細
次のセクションでは、Hive コネクタに固有の Data Factory エンティティの定義に使用されるプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
Hive のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは、次のように設定する必要があります:Hive | はい |
| host | Hive サーバーの IP アドレスまたはホスト名。複数のホストは ';' で区切ります (serviceDiscoveryMode が有効な場合のみ)。 | はい |
| port | Hive サーバーがクライアント接続のリッスンに使用する TCP ポート。 Azure HDInsight に接続する場合は、port で 443 を指定します。 | はい |
| serverType | Hive サーバーの種類。 使用できる値は、以下のとおりです。HiveServer1、HiveServer2、HiveThriftServer。 |
いいえ |
| thriftTransportProtocol | Thrift レイヤーで使用するトランスポート プロトコル。 使用できる値は、以下のとおりです。Binary、SASL、HTTP。 |
いいえ |
| authenticationType | Hive サーバーへのアクセスに使用する認証方法。 使用できる値は、以下のとおりです。Anonymous、Username、UsernameAndPassword、WindowsAzureHDInsightService。 Kerberos 認証は現在サポートされていません。 |
はい |
| serviceDiscoveryMode | ZooKeeper サービスの使用を指定する場合は true、そうでない場合は false。 | いいえ |
| zooKeeperNameSpace | Hive サーバーの 2 ノードが追加される ZooKeeper 上の名前空間。 | いいえ |
| useNativeQuery | ドライバーがネイティブの HiveQL クエリを使用するか、または HiveQL の同等の形式に変換するかを指定します。 | いいえ |
| username | Hive サーバーへのアクセスに使用するユーザー名。 | いいえ |
| password | ユーザーに対応するパスワード。 このフィールドを SecureString とマークして安全に保存するか、Azure Key Vault に保存されているシークレットを参照します。 | いいえ |
| httpPath | Hive サーバーに対応する部分的な URL。 | いいえ |
| enableSsl | サーバーへの接続が TLS を使用して暗号化されるかどうかを指定します。 既定値は false です。 | いいえ |
| trustedCertPath | TLS 経由で接続するときにサーバーを検証するための信頼された CA 証明書を含む .pem ファイルの完全なパス。 このプロパティは、セルフホステッド IR 上で TLS を使用している場合にのみ設定できます。 既定値は、IR でインストールされる cacerts.pem ファイルです。 | いいえ |
| useSystemTrustStore | システムの信頼ストアと指定した PEM ファイルのどちらの CA 証明書を使用するかを指定します。 既定値は false です。 | いいえ |
| allowHostNameCNMismatch | TLS 経由で接続するときに、CA が発行した TLS/SSL 証明書名がサーバーのホスト名と一致する必要があるかどうかを指定します。 既定値は false です。 | いいえ |
| allowSelfSignedServerCert | サーバーからの自己署名証明書を許可するかどうかを指定します。 既定値は false です。 | いいえ |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 詳細については、「前提条件」セクションを参照してください。 指定されていない場合は、既定の Azure 統合ランタイムが使用されます。 | いいえ |
| storageReference | マッピング データ フローでデータをステージングするために使用されるストレージ アカウントのリンクされたサービスへの参照。 これは、マッピング データ フローで Hive のリンクされたサービスを使用する場合にのみ必要です | いいえ |
例:
{
"name": "HiveLinkedService",
"properties": {
"type": "Hive",
"typeProperties": {
"host" : "<cluster>.azurehdinsight.net",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
データセットのプロパティ
データセットを定義するために使用できるセクションとプロパティの完全な一覧については、データセットに関する記事をご覧ください。 このセクションでは、Hive データセットでサポートされるプロパティの一覧を示します。
Hive からデータをコピーするには、データセットの type プロパティを HiveObject に設定します。 次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセットの type プロパティは、次のように設定する必要があります:HiveObject | はい |
| schema | スキーマの名前。 | いいえ (アクティビティ ソースの "query" が指定されている場合) |
| table | テーブルの名前。 | いいえ (アクティビティ ソースの "query" が指定されている場合) |
| tableName | スキーマ部分を含むテーブルの名前。 このプロパティは下位互換性のためにサポートされています。 新しいワークロードでは、schema と table を使用します。 |
いいえ (アクティビティ ソースの "query" が指定されている場合) |
例
{
"name": "HiveDataset",
"properties": {
"type": "HiveObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Hive linked service name>",
"type": "LinkedServiceReference"
}
}
}
コピー アクティビティのプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関する記事を参照してください。 このセクションでは、Hive ソースでサポートされるプロパティの一覧を示します。
ソースとしての HiveSource
Hive からデータをコピーするは、コピー アクティビティのソースの種類を HiveSource に設定します。 コピー アクティビティの source セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティは、次のように設定する必要があります:HiveSource | はい |
| query | カスタム SQL クエリを使用してデータを読み取ります。 (例: "SELECT * FROM MyTable")。 |
いいえ (データセットの "tableName" が指定されている場合) |
例:
"activities":[
{
"name": "CopyFromHive",
"type": "Copy",
"inputs": [
{
"referenceName": "<Hive input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "HiveSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Mapping Data Flow のプロパティ
Hive コネクタは、マッピング データ フローでインライン データセットのソースとしてサポートされています。 クエリを使用するか、HDInsight の Hive テーブルから直接読み取ります。 Hive データは、データ フローの一部として変換される前に、ストレージ アカウントで Parquet ファイルとしてステージングされます。
ソース プロパティ
次の表に、Hive ソースでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [ソース オプション] タブで編集できます。
| 名前 | 説明 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| ストア | ストアは hive である必要があります |
はい | hive |
store |
| フォーマット | テーブルまたはクエリから読み取るかを指定します | はい | table または query |
format |
| スキーマ名 | テーブルから読み取る場合、ソース テーブルのスキーマ | はい (フォーマットが table の場合) |
String | schemaName |
| テーブル名 | テーブルから読み取る場合、テーブル名 | はい (フォーマットが table の場合) |
String | tableName |
| クエリ | フォーマットが query の場合、Hive のリンクされたサービスに対するソース クエリ |
はい (フォーマットが query の場合) |
String | query |
| ステージング済み | Hive テーブルは常にステージングされます。 | はい | true |
staged |
| ストレージ コンテナー | Hive から読み取る前、または Hive に書き込む前にデータをステージングするために使用されるストレージ コンテナー。 Hive クラスターは、このコンテナーへのアクセス権を持っている必要があります。 | はい | String | storageContainer |
| ステージング データベース | リンクされたサービスで指定されたユーザー アカウントがアクセスできるスキーマ/データベース。 ステージング中に外部テーブルを作成するために使用され、その後削除します | no | true または false |
stagingDatabaseName |
| 事前 SQL スクリプト | データを読み取る前に Hive テーブルで実行する SQL コード | no | String | preSQLs |
ソースの例
以下に Hive ソース構成の例を示します。
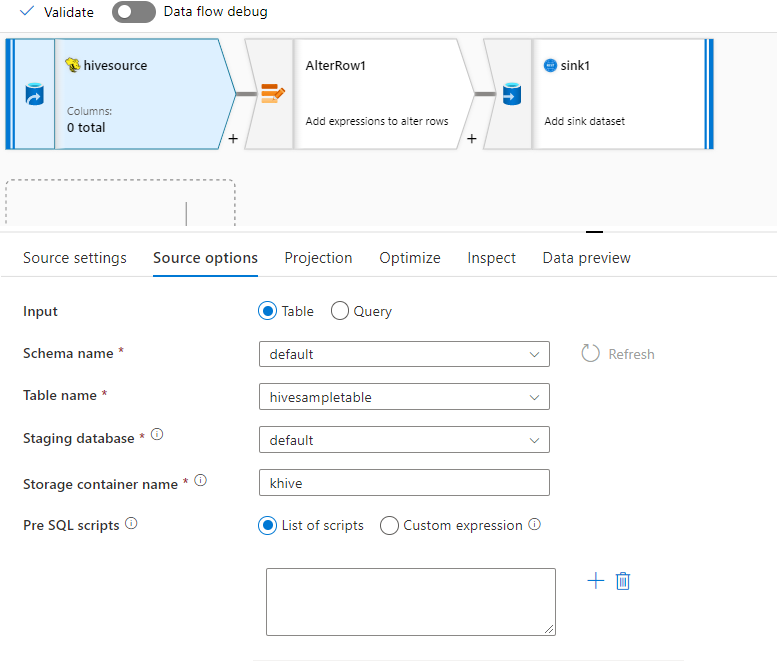
これらの設定は、次のデータ フロー スクリプトに変換されます。
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
format: 'table',
store: 'hive',
schemaName: 'default',
tableName: 'hivesampletable',
staged: true,
storageContainer: 'khive',
storageFolderPath: '',
stagingDatabaseName: 'default') ~> hivesource
既知の制限事項
- 配列、マップ、構造体、和集合などの複合型の読み取りはサポートされていません。
- Hive コネクタがサポートしているのは、バージョン 4.0 以上 (Apache Hive 3.1.0) の Azure HDInsight の Hive テーブルのみです
- 既定では、Hive ドライバーはシンクで "tableName.columnName" を提供します。 列名にテーブル名を表示しない場合は、これを修正する 2 とおりの方法があります。 a. Hive サーバー側で "hive.resultset.use.unique.column.names" の設定を確認し、false に設定します。 b. 列マッピングを使用して列の名前を変更します。
Lookup アクティビティのプロパティ
プロパティの詳細については、Lookup アクティビティに関するページを参照してください。
関連するコンテンツ
Copy アクティビティでソースおよびシンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するセクションを参照してください。