マッピング データ フローでの参照変換
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
データ フローは、Azure Data Factory および Azure Synapse Pipelines の両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、概要の記事「マッピング データ フローを使用してデータを変換する」を参照してください。
参照変換を使用して、データ フロー ストリーム内の別のソースからデータを参照します。 参照変換では、一致したデータの列がソース データに追加されます。
参照変換は、左外部結合と似ています。 プライマリ ストリームのすべての行が出力ストリームに存在し、それに参照ストリームからの列が追加されます。
構成
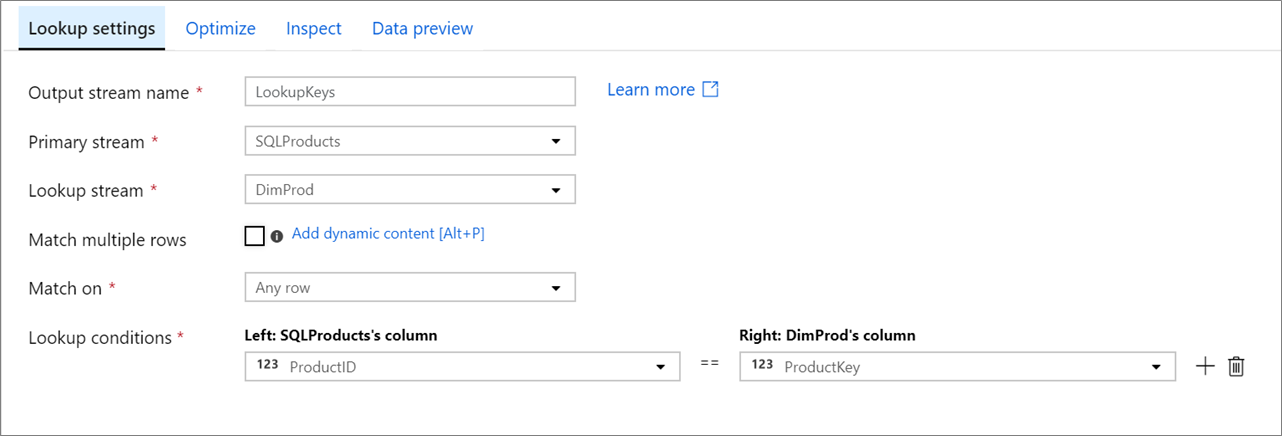
[Primary stream](プライマリ ストリーム): データの受信ストリーム。 このストリームは、結合の左側に相当します。
[Lookup stream](参照ストリーム): プライマリ ストリームに追加されるデータ。 どのデータが追加されるかは、参照条件によって決まります。 このストリームは、結合の右側に相当します。
[Match multiple rows](複数の行の一致): 有効にすると、プライマリ ストリームに複数の一致がある行で、複数の行が返されます。 それ以外の場合は、[Match on](一致対象) 条件に基づいて 1 行だけが返されます。
[一致対象]: [複数の行の一致] が選択されていない場合にのみ表示されます。 任意の行、最初の一致、または最後の一致のいずれと一致するかを選択します。 実行が最も速いので、任意の行をお勧めします。 最初の行または最後の行を選択する場合は、並べ替え条件を指定する必要があります。
[Lookup conditions](参照条件): 一致対象の列を選択します。 等値条件が満たされた場合、行は一致と見なされます。 データ フロー式言語を使用して値を抽出するには、ポイントして [Computed column](計算列) を選択します。
両方のストリームのすべての列が、出力データに含まれます。 重複する列または不要な列を削除するには、参照変換の後に選択変換を追加します。 シンク変換で列を削除したり、名前を変更したりすることもできます。
非等結合
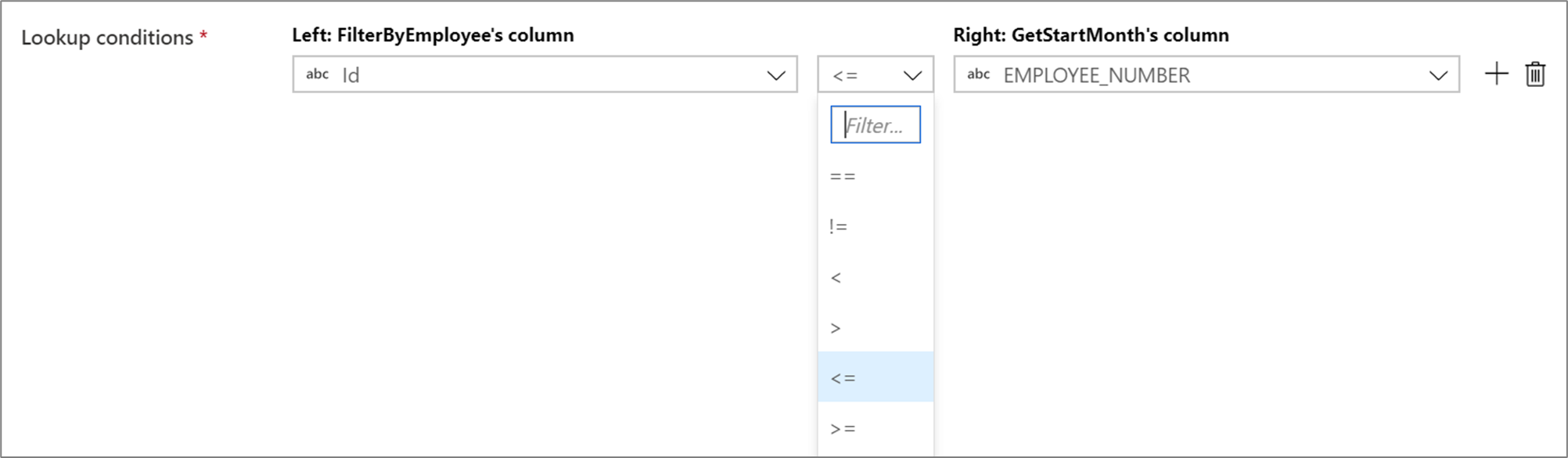
参照条件で等しくない (!=) またはより大きい (>) などの条件演算子を使用するには、2 つの列の間の演算子ドロップダウンを変更します。 非等結合では、 [最適化] タブで [固定] ブロードキャストを使用して、2 つのストリームのうち少なくとも 1 つをブロードキャストする必要があります。
一致した行の分析
参照変換の後で、isMatch() 関数を使用して、参照が個々の行と一致したかどうかを確認できます。
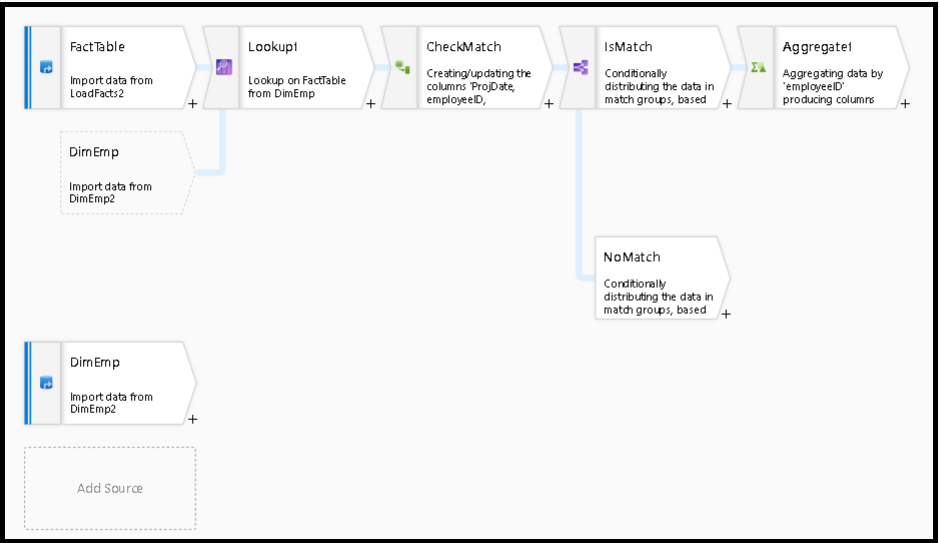
このパターンの例は、条件分割変換を使用して isMatch() 関数で分割する場合です。 上記の例では、一致する行が上のストリームを進み、一致しない行は NoMatch ストリームを進みます。
参照条件のテスト
デバッグ モードでデータ プレビューを使用して参照変換のテストを行う場合は、小さな既知のデータ セットを使用してください。 大きなデータセットから行をサンプリングすると、テストでどの行とキーが読み取られるのかを予測できなくなります。 結果が確定的なものとならず、結合条件で一致するものが返されなくなる可能性があります。
ブロードキャストの最適化
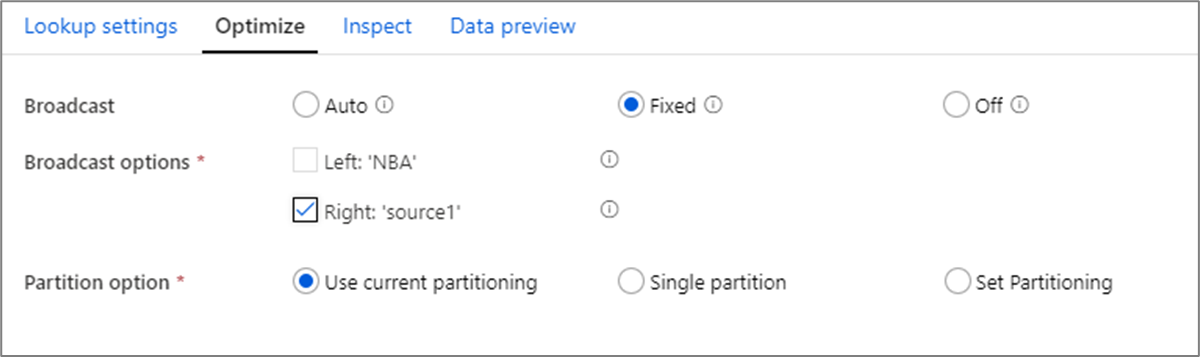
結合変換、参照変換、および存在変換では、一方または両方のデータ ストリームがワーカー ノードのメモリに収まる場合、ブロードキャストを有効にすることでパフォーマンスを最適化できます。 既定では、ある一方をブロードキャストするかどうかは、Spark エンジンによって自動的に決定されます。 ブロードキャストする側を手動で選択するには [Fixed](固定) を選択します。
Off オプションを使用してブロードキャストを無効にすることは、タイムアウト エラーが発生していない限り推薦されません。
キャッシュされた参照
同じソースに対して複数の小さい参照を実行する場合、キャッシュされたシンクと参照は、参照変換よりも適切なユース ケースである可能性があります。 キャッシュ シンクがより適切な一般的な例としては、データ ストアで最大値を検索することや、エラー コードをエラー メッセージ データベースと照合することが挙げられます。 詳細については、キャッシュ シンク と キャッシュされた参照に関するページをご覧ください。
データ フローのスクリプト
構文
<leftStream>, <rightStream>
lookup(
<lookupConditionExpression>,
multiple: { true | false },
pickup: { 'first' | 'last' | 'any' }, ## Only required if false is selected for multiple
{ desc | asc }( <sortColumn>, { true | false }), ## Only required if 'first' or 'last' is selected. true/false determines whether to put nulls first
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <lookupTransformationName>
例
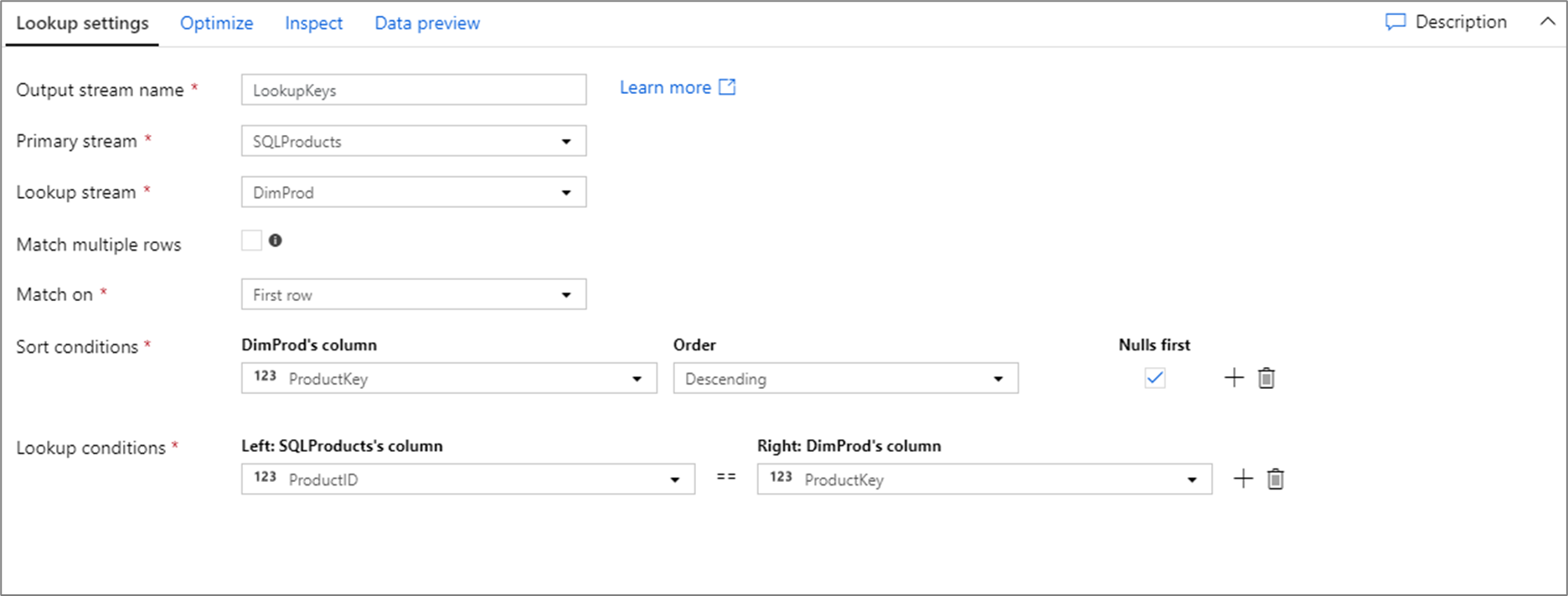
次のコード スニペットには、上記の参照構成に対するデータ フロー スクリプトが含まれています。
SQLProducts, DimProd lookup(ProductID == ProductKey,
multiple: false,
pickup: 'first',
asc(ProductKey, true),
broadcast: 'auto')~> LookupKeys