正規化されたデータベース スキーマを Azure SQL Database から Azure Cosmos DB 非正規コンテナーに移行する
このガイドでは、Azure SQL Database の既存の正規化されたデータベース スキーマを取得し、それを Azure Cosmos DB 非正規化スキーマに変換して Azure Cosmos DB に読み込む方法について説明します。
SQL スキーマは、通常、3 番目の標準形式を使用してモデル化されます。その結果、データ整合性のレベルが高く重複するデータ値がより少ない正規化されたスキーマが得られます。 クエリでは、エンティティをテーブル間で結合して読み取りを行うことができます。 Azure Cosmos DB は、ドキュメント内でデータが自己完結する非正規化スキーマにより、コレクションまたはコンテナー内でトランザクションとクエリを超高速に実行できるよう最適化されています。
Azure Data Factory を使用すれば、エンティティ リレーションシップとして主キーと外部キーを含む、Azure SQL Database の 2 つの正規化されたテーブルからの読み取りを、マッピング データ フローを使用して実行するパイプラインを作成できます。 ADF では、データ フロー Spark エンジンを使用してこれらのテーブルが 1 つのストリームに結合され、結合した行が配列に収集されてから、新しい Azure Cosmos DB コンテナーへの挿入に合わせてクレンジングされたドキュメントが個別に生成されます。
このガイドでは、標準的 SQL Server の AdventureWorks サンプル データベースの SalesOrderHeader テーブルと SalesOrderDetail テーブルを使用する、"orders" という名前の新しいコンテナーをその場で構築します。 これらのテーブルは、SalesOrderID によって結合された販売トランザクションを表します。 一意の各詳細レコードには、それぞれ SalesOrderDetailID という独自の主キーがあります。 ヘッダーと詳細の間のリレーションシップは 1:M です。 ADF 内の SalesOrderID に参加して、それぞれの関連する詳細レコードを "detail" という配列にロールします。
このガイドの代表的な SQL クエリは次のとおりです。
SELECT
o.SalesOrderID,
o.OrderDate,
o.Status,
o.ShipDate,
o.SalesOrderNumber,
o.ShipMethod,
o.SubTotal,
(select SalesOrderDetailID, UnitPrice, OrderQty from SalesLT.SalesOrderDetail od where od.SalesOrderID = o.SalesOrderID for json auto) as OrderDetails
FROM SalesLT.SalesOrderHeader o;
結果として得られた Azure Cosmos DB コンテナーでは、内部クエリが 1 つのドキュメントに埋め込まれ、次のようになります。

パイプラインを作成する
[+ 新しいパイプライン] を選択して新しいパイプラインを作成します。
データ フロー アクティビティを追加する
データ フロー アクティビティで、 [New mapping data flow](新しいマッピング データ フロー) を選択します。
次のデータ フロー グラフを作成します
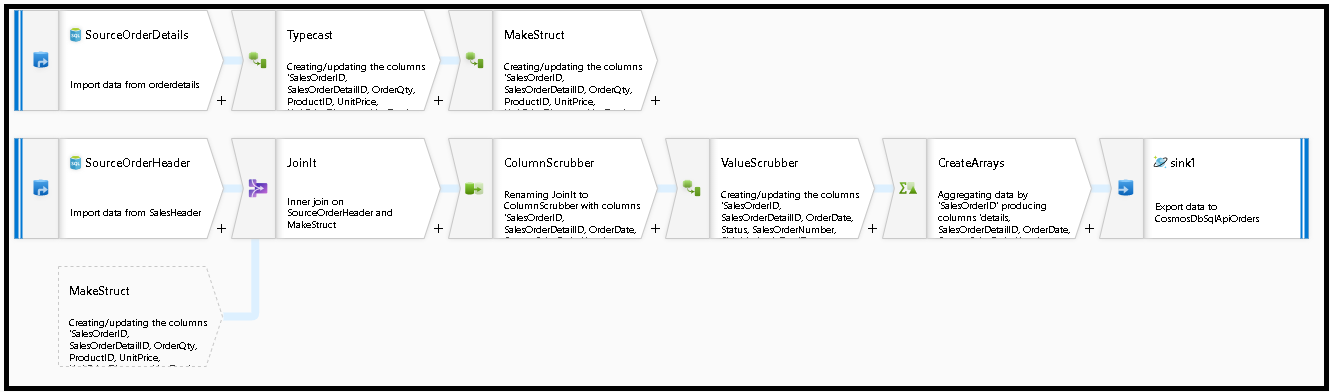
"SourceOrderDetails" 用のソースを定義します。 データセットの場合は、
SalesOrderDetailテーブルを指す新しい Azure SQL Database データセットを作成します。"SourceOrderHeader" 用のソースを定義します。 データセットの場合は、
SalesOrderHeaderテーブルを指す新しい Azure SQL Database データセットを作成します。上部のソースで、"SourceOrderDetails" の後に派生列変換を追加します。 この新しい変換 "TypeCast" と名付けます。
UnitPrice列を丸めて、Azure Cosmos DB の Double データ型にキャストする必要があります。 数式をtoDouble(round(UnitPrice,2))に設定します。別の派生列を追加し、"MakeStruct" 名付けます。 ここでは、details テーブルからの値を保持するための階層構造体を作成します。 details とヘッダーとの関係は
M:1であることを思い出してください。 新しい構造体にorderdetailsstructという名前を付けて、この方法で階層を作成します。これにより、各サブ列は入力列名に設定されます。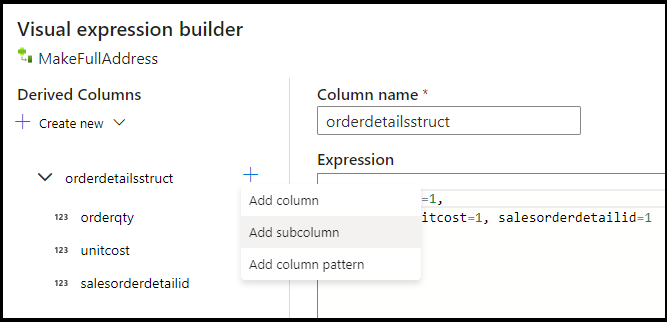
ここで、sales ヘッダー ソースに移りましょう。 結合変換を追加します。 右側の [MakeStruct] を選択します。 これを内部結合に設定されたままにして、結合条件の両側で
SalesOrderIDを選択します。追加した新しい結合の [データのプレビュー] タブをクリックして、この時点までの結果を確認できるようにします。 詳細行と結合されたすべてのヘッダー行が表示されます。 これは、
SalesOrderIDから結合が形成された結果です。 次に、共通行からの詳細を details 構造体に結合し、共通行を集計します。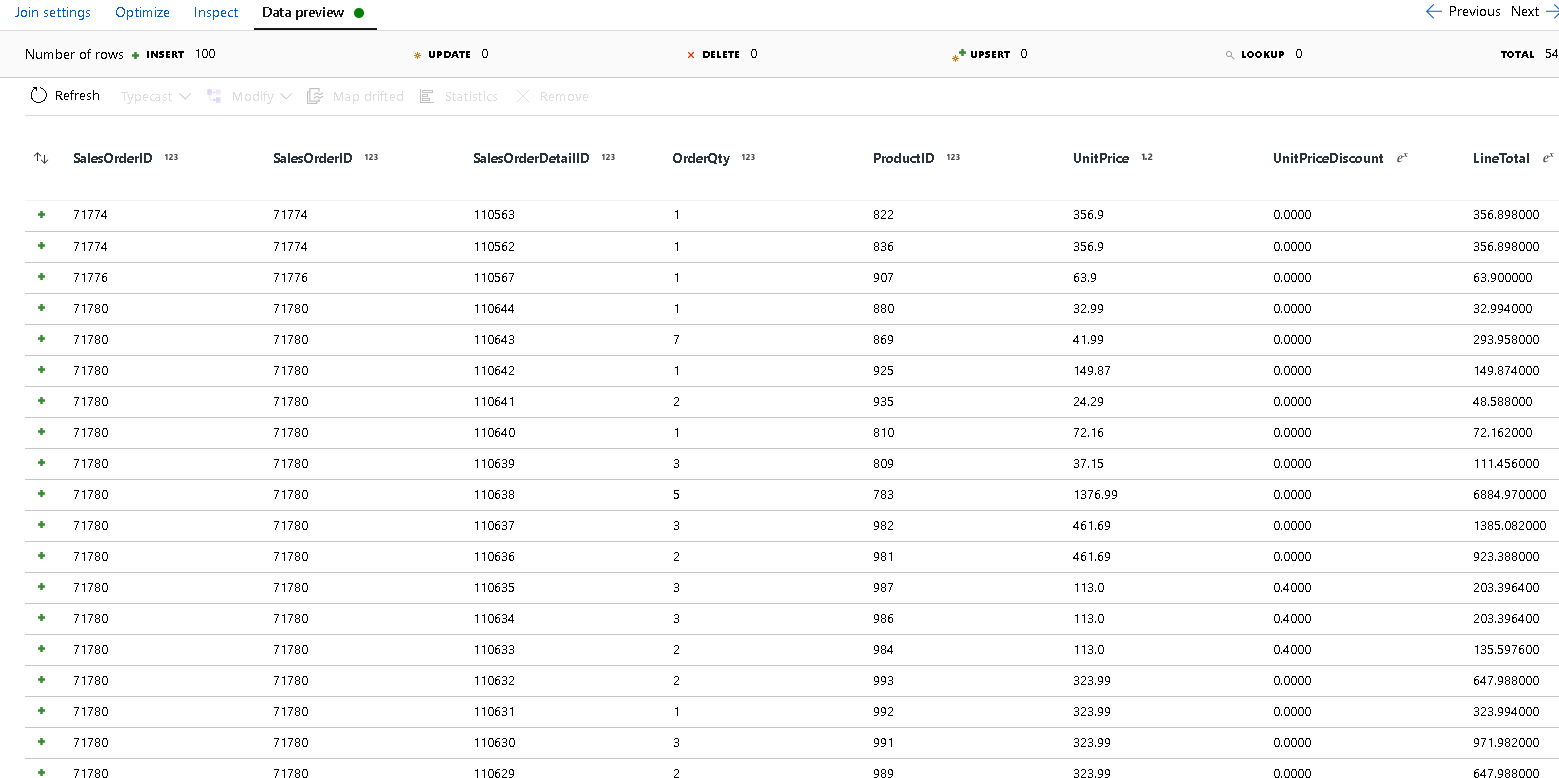
これらの行を非正規化する配列を作成するには、まず不要な列を削除し、データ値が Azure Cosmos DB のデータ型と一致することを確認する必要があります。
次に変換を選択を追加し、フィールド マッピングを次のように設定します。
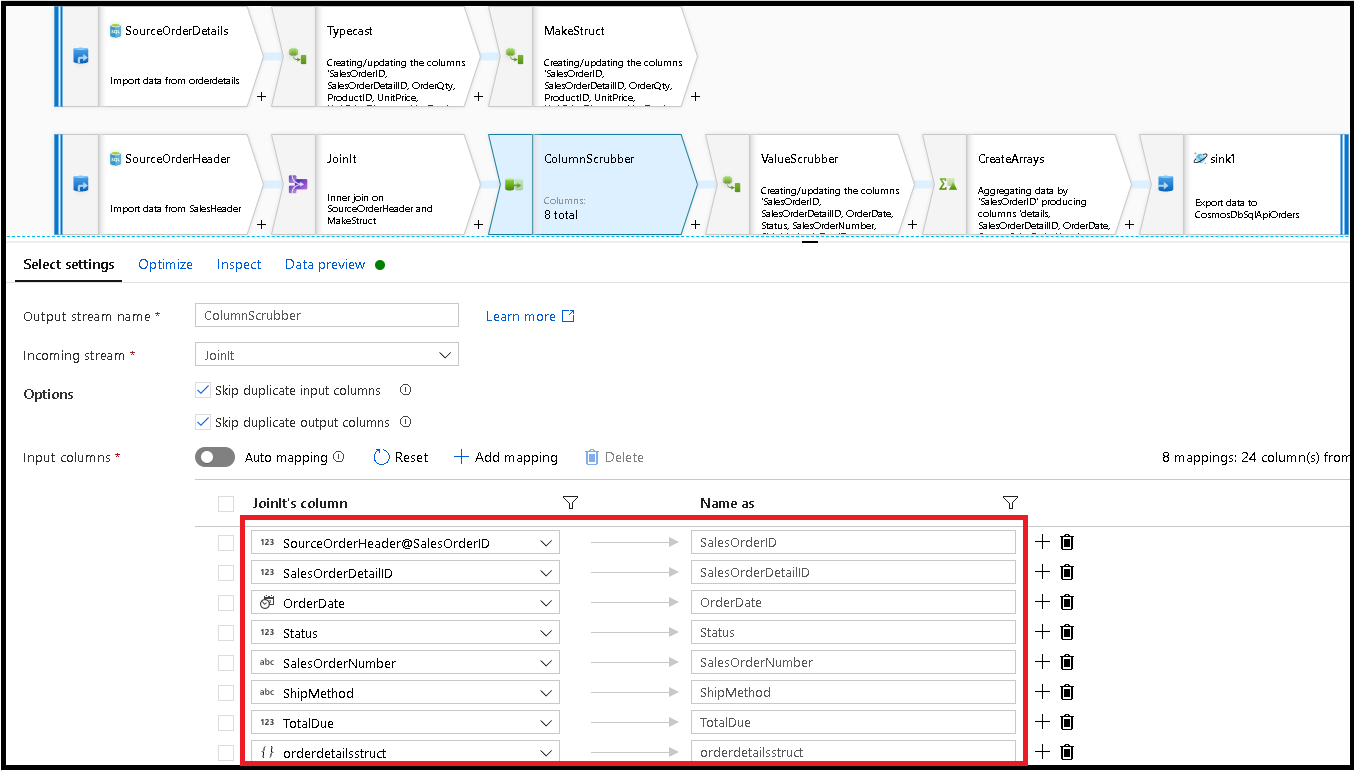
ここで、もう一度、通貨の列をキャストしてみましょう。今度は
TotalDueです。 上記の手順 7 で行ったように、式をtoDouble(round(TotalDue,2))に設定します。ここでは、共通キー
SalesOrderIDをグループ化することによって行を非正規化します。 集計変換を追加し、グループ化をSalesOrderIDに設定します。集計式に "details" という名前の新しい列を追加し、この式を使用して、前に作成した
orderdetailsstructという名前の構造体内の値を収集します:collect(orderdetailsstruct)集計式またはグループ化式の一部である列のみが、集計変換から出力されます。 そのため、sales ヘッダーからの列も含める必要があります。 これを行うには、それと同じ集計変換に列パターンを追加します。 このパターンでは、下に示した列 (OrderQty、UnitPrice、SalesOrderID) を除き、他のすべての列が出力に含められます。
instr(name,'OrderQty')==0&&instr(name,'UnitPrice')==0&&instr(name,'SalesOrderID')==0
同じ列名を維持し、集計に
first()関数を使用するように、他のプロパティでも "この" 構文 ($$) を使用します。 こうして、最初に見つかった一致する値を保持するよう ADF に指示します。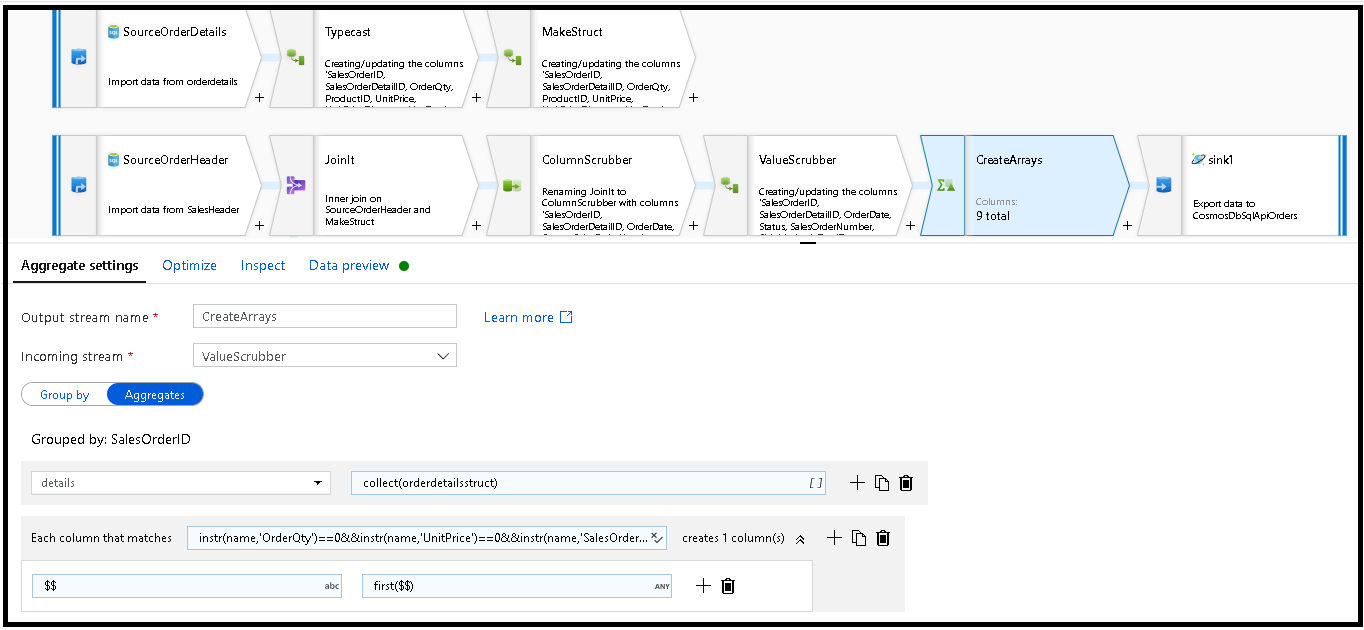
シンク変換を追加すれば、移行フローを完了する準備が整います。 データセットの横にある [新規] をクリックし、お使いの Azure Cosmos DB データベースを指す Azure Cosmos DB データセットを追加します。 コレクションの場合は、それに "orders" という名前を付けます。これは、その場で作成されるため、スキーマがなく、ドキュメントも作成されません。
[シンクの設定] で、[パーティション キー] を
/SalesOrderIDとし、コレクション アクションを "再作成" とします。 ご利用のマッピング タブが次のようになっていることを確認します。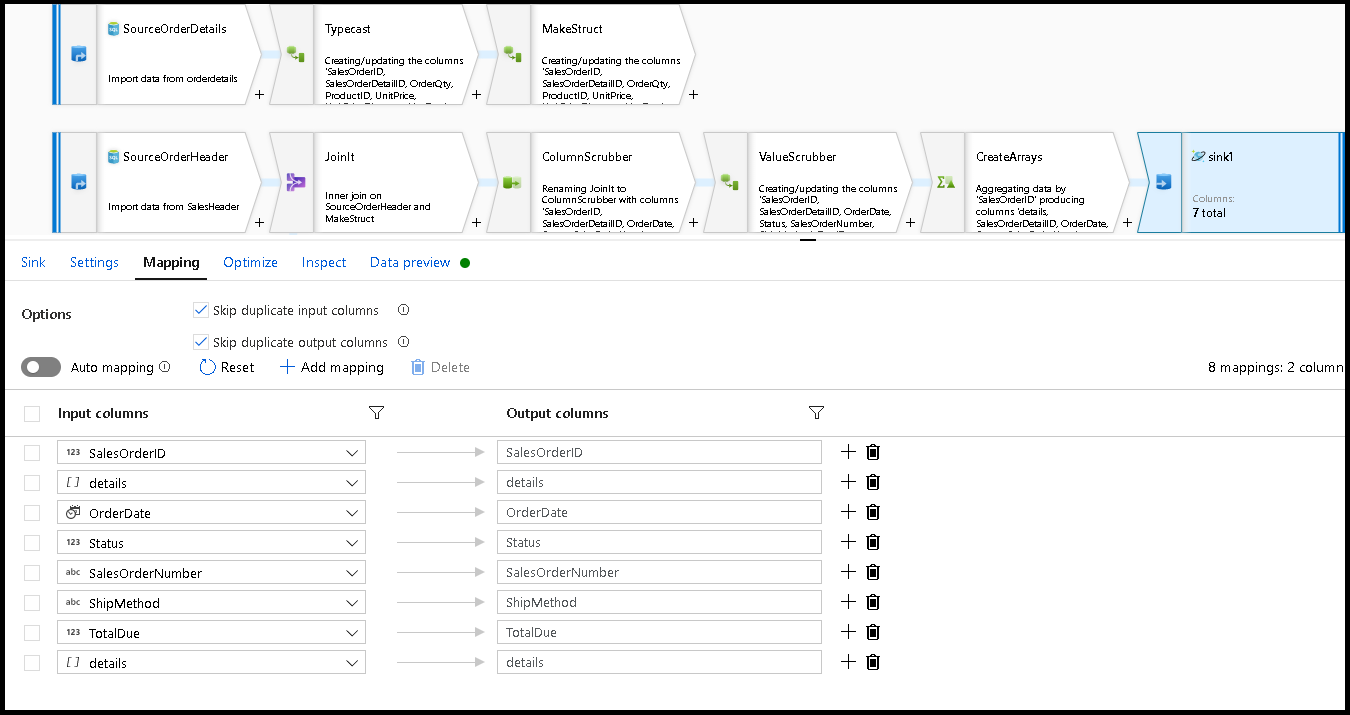
[データのプレビュー] をクリックして、これらの 32 行が新しいドキュメントとして新しいコンテナーに挿入されるように設定されていることを確認します。
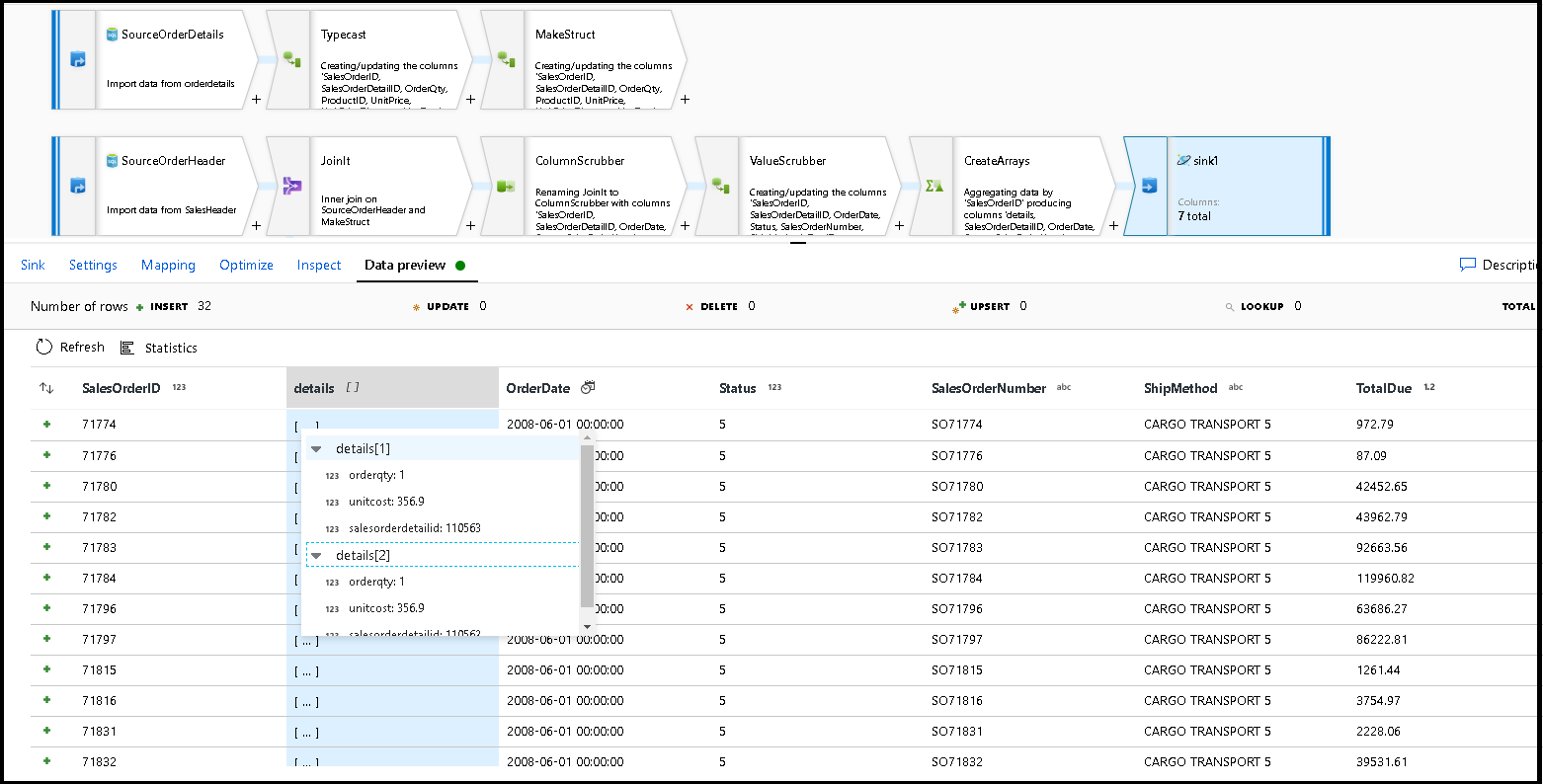
すべて問題がないようであれば、新しいパイプラインを作成し、このデータ フロー アクティビティをそのパイプラインに追加して実行する準備ができたことになります。 デバッグまたはトリガーされた実行から実行できます。 数分すると、お使いの Azure Cosmos DB データベース内に、"orders" という名前で、注文に関する新しい非正規化コンテナーが作成されているはずです。
関連するコンテンツ
- マッピング データ フローの変換を使用して、残りのデータ フロー ロジックを構築します。
- このチュートリアル用の完成したパイプライン テンプレートをダウンロードし、そのテンプレートをご自分のファクトリにインポートします。