Azure Databricks による変換
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
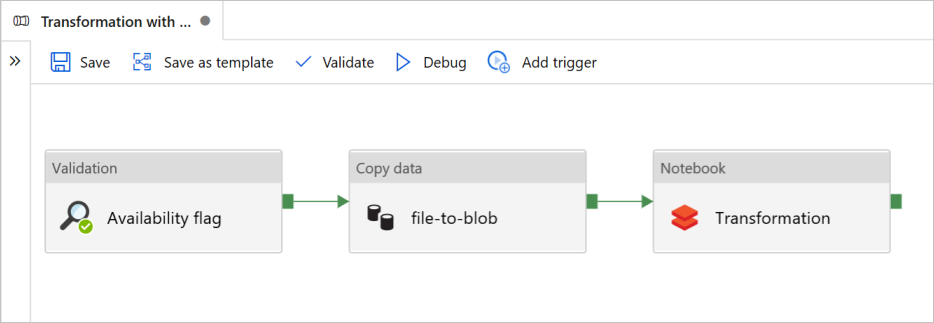
このチュートリアルでは、Azure Data Factory の検証、データ コピー、およびノートブック アクティビティが含まれる、エンド ツー エンドのパイプラインを作成します。
検証は、コピーおよび分析ジョブをトリガーする前に、ソース データセットがダウンストリームで使用できる状態にします。
データ コピーは、ソース データセットを Azure Databricks Notebook に DBFS としてマウントされているシンク ストレージにコピーします。 このようにして、データセットを Spark で直接使用することができます。
ノートブックによって、データセットを変換する Databricks Notebook がトリガーされます。 また、処理されたフォルダーまたは Azure Synapse Analytics にデータセットが追加されます。
わかりやすくするために、このチュートリアルのテンプレートではスケジュールされたトリガーを作成しません。 必要に応じて、1 つを追加できます。
前提条件
シンクとして使用するための
sinkdataという名前のコンテナーを持つ Azure Blob ストレージ アカウント。ストレージ アカウント名、コンテナー名、アクセス キーをメモしておきます。 これらの値は、後でテンプレートの中で必要になります。
Azure Databricks ワークスペース。
変換するノートブックをインポートする
変換ノートブックを Databricks ワークスペースにインポートするには、次のようにします。
Azure Databricks ワークスペースにサインインし、 [インポート] を選択します。
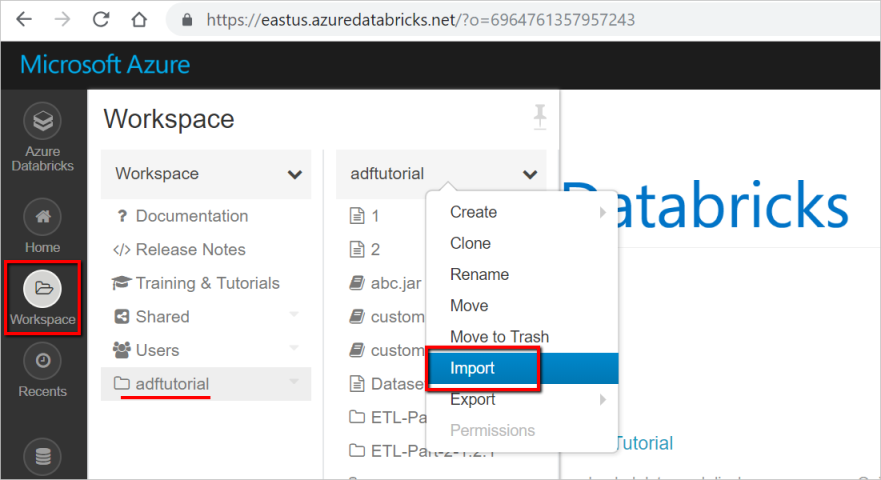 ワークスペース パスは、表示されているものとは異なる場合がありますが、後で使用できるように注意してください。
ワークスペース パスは、表示されているものとは異なる場合がありますが、後で使用できるように注意してください。インポート元:URL を選択します。 テキスト ボックスに、「
https://adflabstaging1.blob.core.windows.net/share/Transformations.html」と入力します。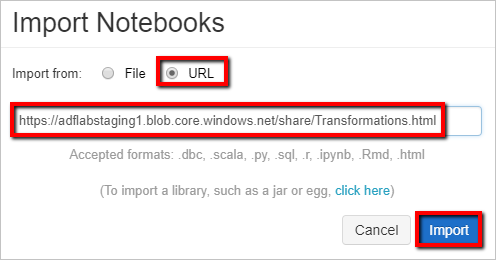
それでは、 [変換] ノートブックを実際のストレージ接続情報で更新しましょう。
インポートしたノートブックで、次のコード スニペットに示すようにコマンド 5 にアクセスします。
<storage name>と<access key>を実際のストレージ接続情報に置き換えます。sinkdataコンテナーでストレージ アカウントを使用します。
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.Data Factory で Databricks にアクセスするための Databricks アクセス トークンを生成します。
- Databricks ワークスペースで、右上にあるユーザー プロファイル アイコンを選択します。
- [ユーザー設定] を選択します。
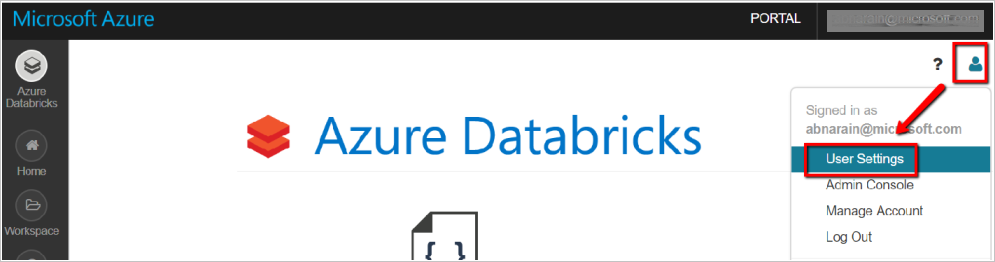
- [アクセス トークン] タブの [新しいトークンの生成] を選択します。
- [Generate] \(生成) を選択します。
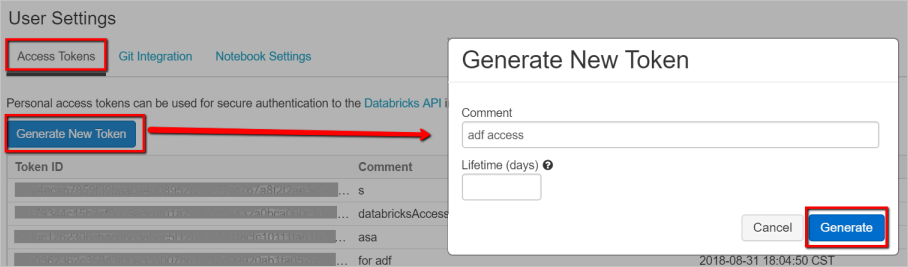
Databricks のリンクされたサービスの作成に後で使用するためにアクセス トークンを保存します。 アクセス トークンは、
dapi32db32cbb4w6eee18b7d87e45exxxxxxのようになります。
このテンプレートの使用方法
Azure Databricks による変換テンプレートに移動し、次の接続用の新しいリンクされたサービスを作成します。
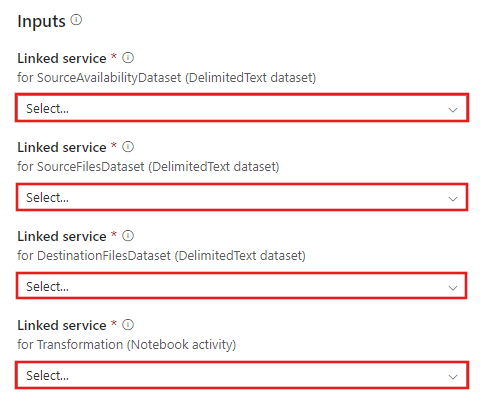
ソース BLOB 接続 - ソース データにアクセスするため。
この演習では、ソース ファイルが格納されているパブリック BLOB ストレージを使用できます。 構成については、次のスクリーンショットを参照してください。 次の [SAS URL] を使用して、ソース ストレージに接続します (読み取り専用アクセス)。
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D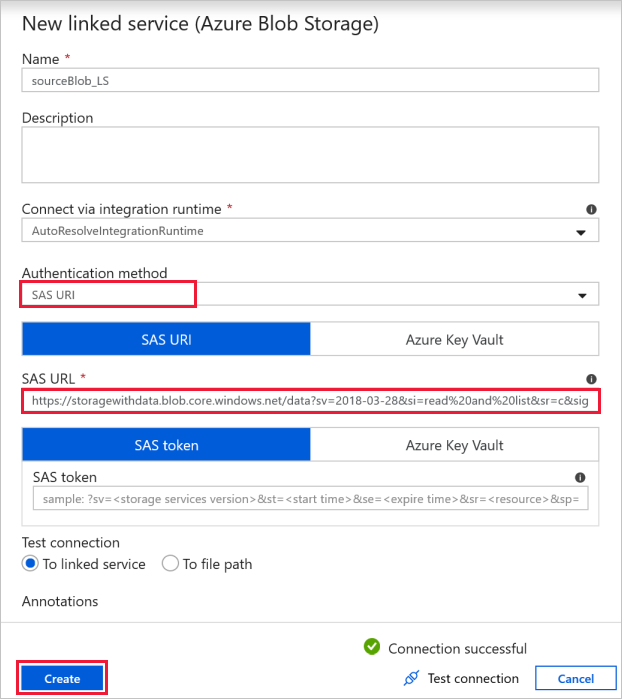
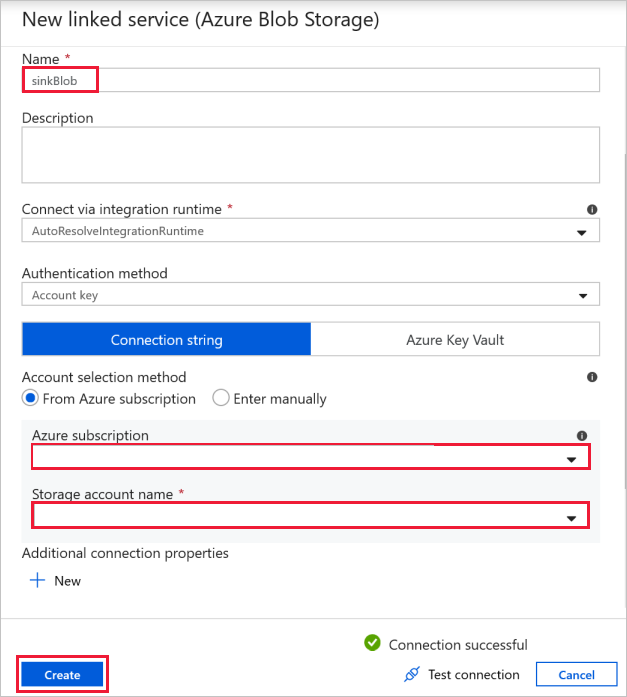
コピー先 BLOB 接続 – コピーしたデータの保管先。
[New Linked Service](新しいリンクされたサービス) ウィンドウで、シンク ストレージ BLOB を選択します。
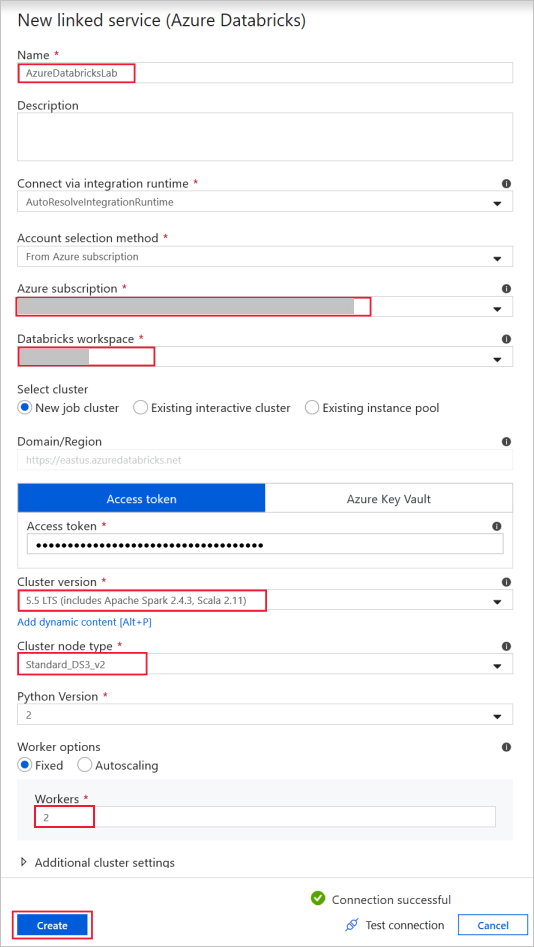
Azure Databricks - Databricks クラスターに接続する。
前に生成したアクセス キーを使用して、Databricks にリンクされたサービスを作成します。 ある場合は、対話型クラスターを選択することもできます。 この例では、 [New job cluster](新しいジョブ クラスター) オプションを使用します。
[このテンプレートを使用] を選択します。 作成されたパイプラインが表示されます。
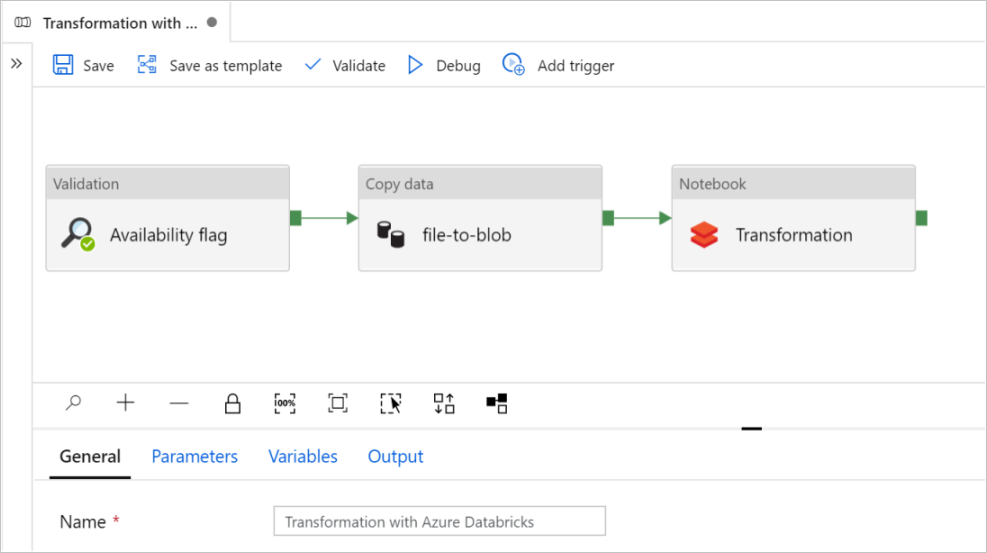
パイプラインの概要と構成
新しいパイプラインのほとんどの設定は、既定値で自動的に構成されています。 パイプラインの構成を確認し、必要に応じて変更します。
[検証] アクティビティの [Availability flag](可用性フラグ) で、ソース データセットの値が、先ほど作成した
SourceAvailabilityDatasetに設定されていることを確認します。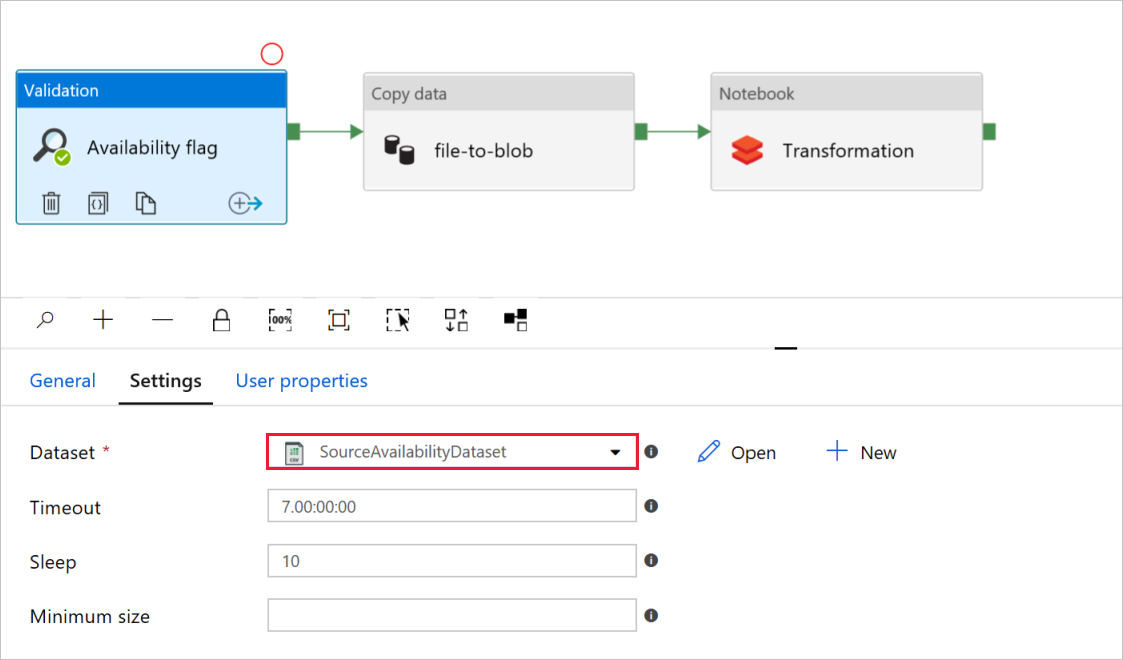
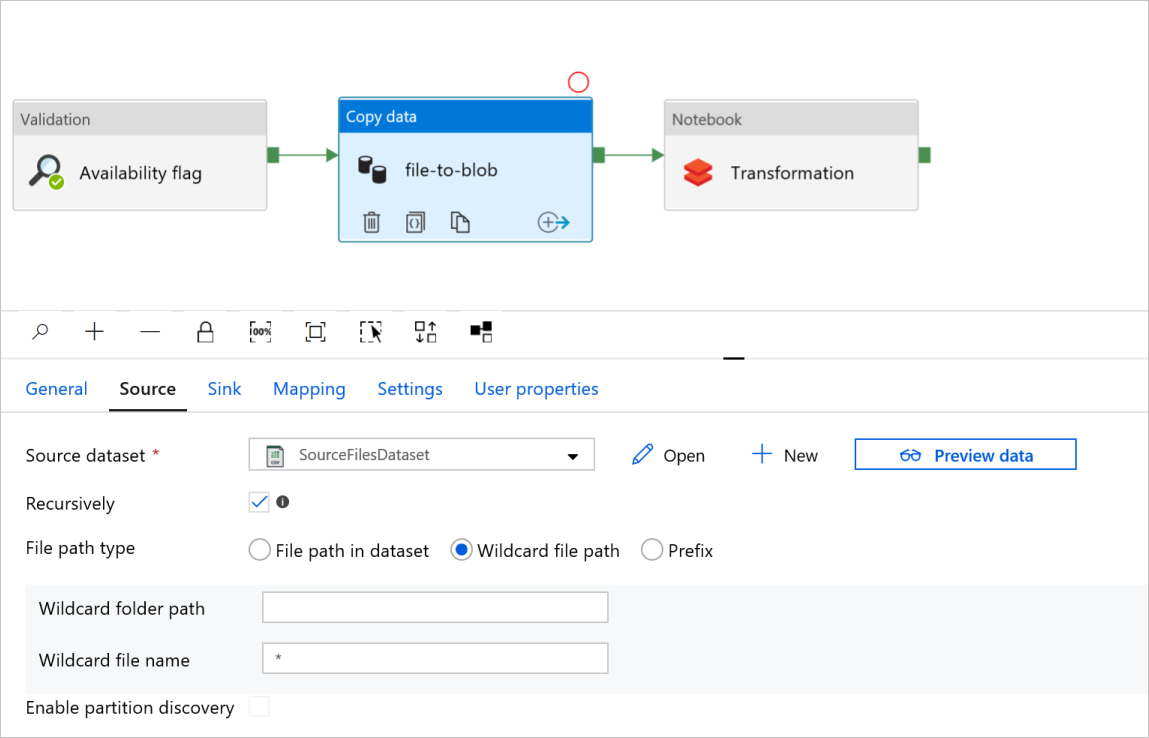
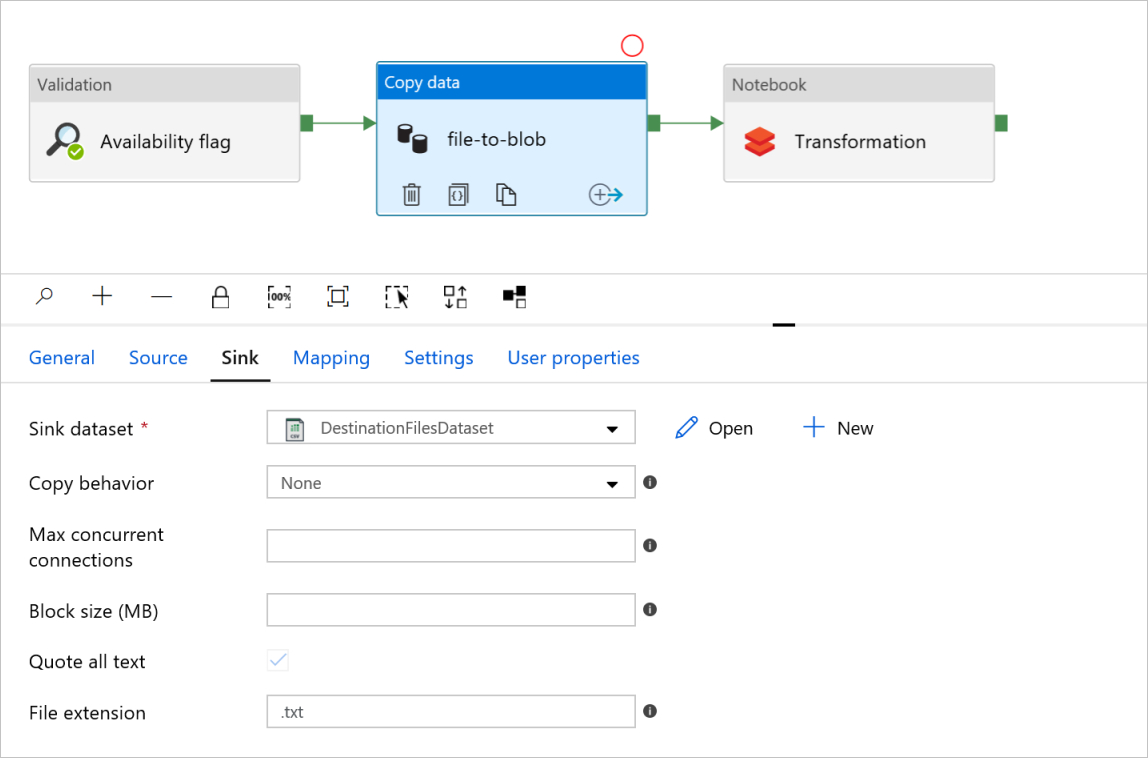
データ コピー アクティビティの [file-to-blob] で、 [ソース] タブと [シンク] タブを確認します。 必要に応じて設定を変更します。
[ソース] タブ
[シンク] タブ
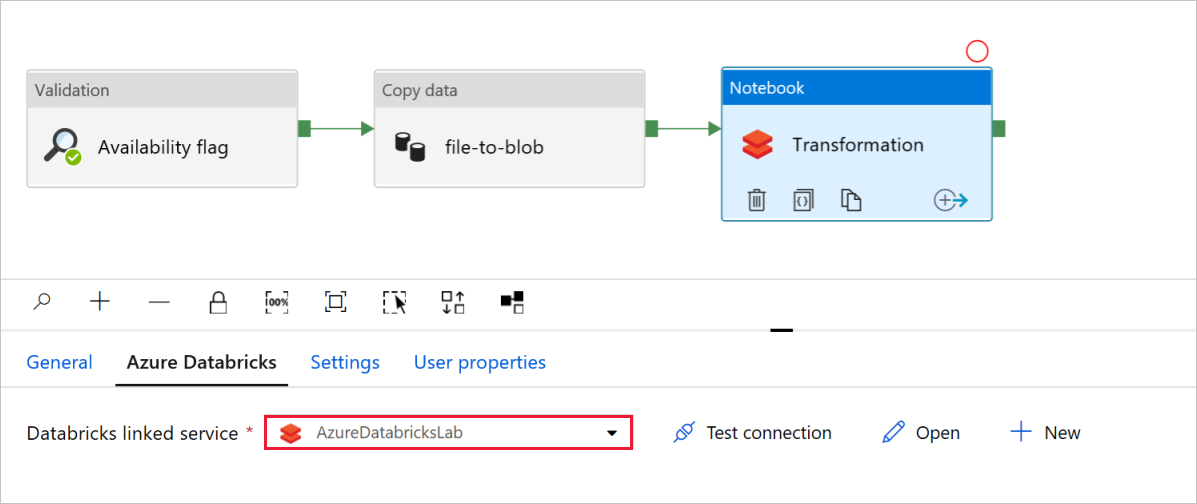
ノートブック アクティビティの変換で、必要に応じてパスと設定を確認し、更新します。
[Databricks リンク サービス] には、次に示すように、前の手順の値が事前に設定されます。
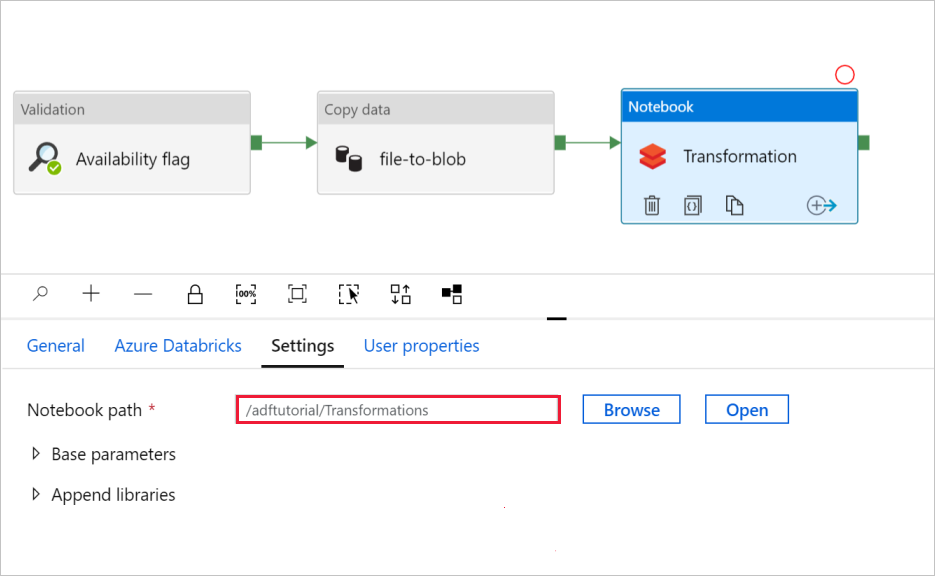
ノートブック設定を確認するには、次のようにします。
[設定] タブを選択します。ノートブック パスについては、既定のパスが正しいことを確認します。 正しいノートブック パスを参照して、選択する必要がある場合があります。
[基本パラメーター] セレクターを展開し、パラメーターが次のスクリーンショットに示されている内容と一致していることを確認します。 これらのパラメーターは Data Factory から Databricks Notebook に渡されます。
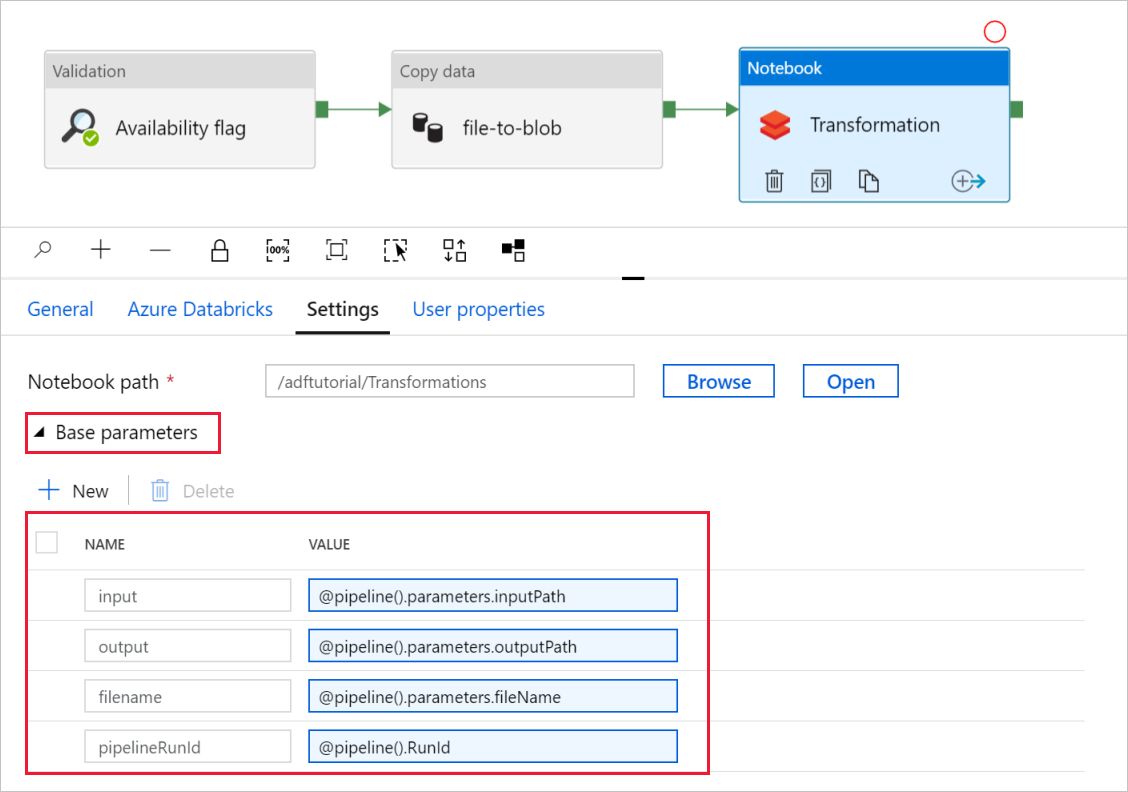
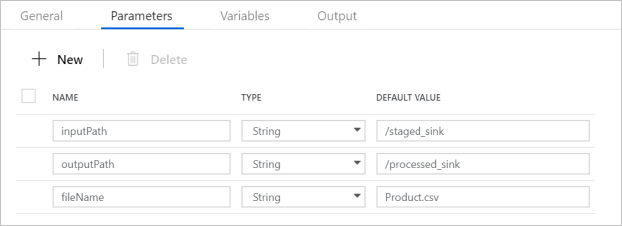
パイプラインのパラメーターが、次のスクリーンショットに示されている内容と一致していることを確認します。
データセットに接続します。
Note
以下のデータ セットでは、ファイルのパスはテンプレートで自動的に指定されています。 変更が必要な場合は、接続エラーが発生した場合に備えて、container と directory の両方のパスを指定してください。
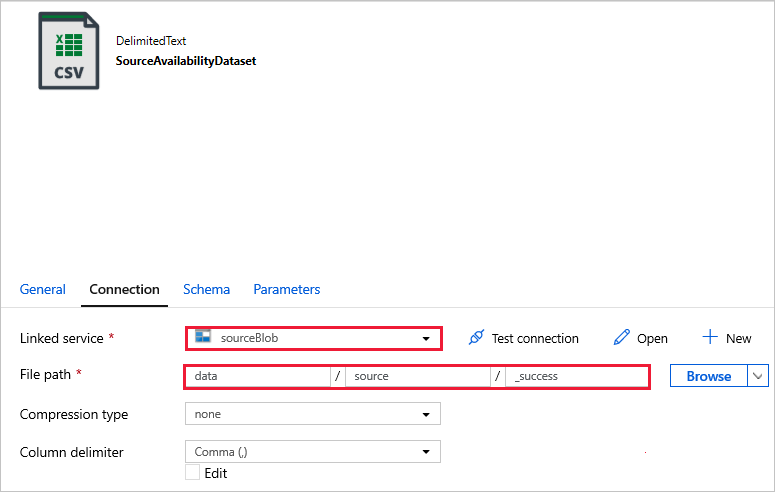
SourceAvailabilityDataset - ソース データが使用可能であることを確認します。
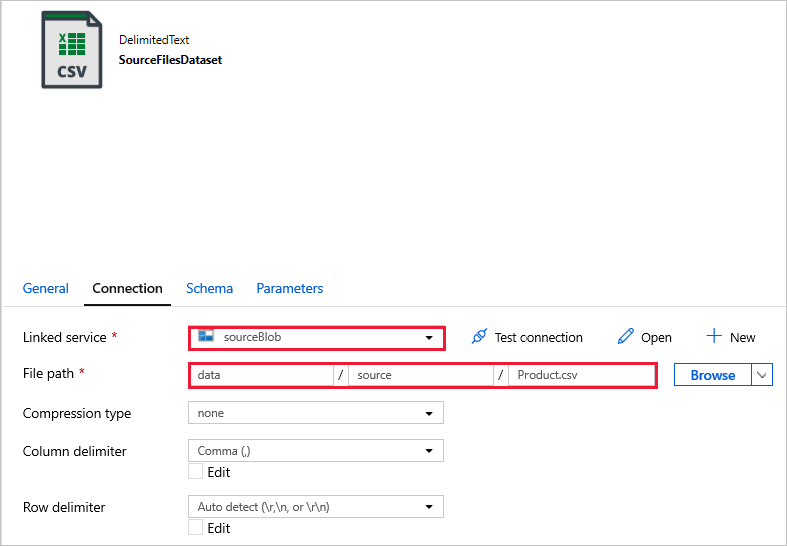
SourceFilesDataset - ソース データにアクセスします。
DestinationFilesDataset - シンクのターゲットの場所にデータをコピーします。 次の値を使用します。
リンクされたサービス -
sinkBlob_LS前のステップで作成済み。ファイル パス -
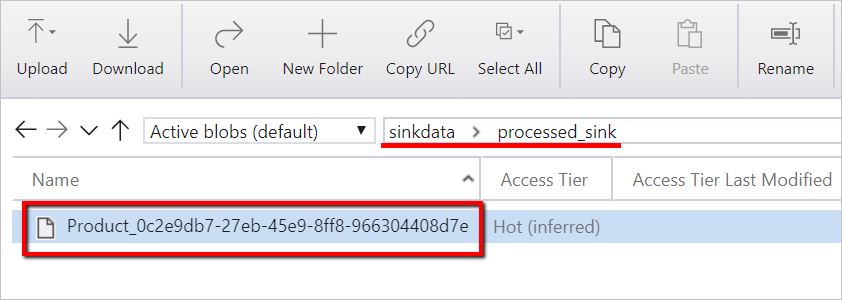
sinkdata/staged_sink。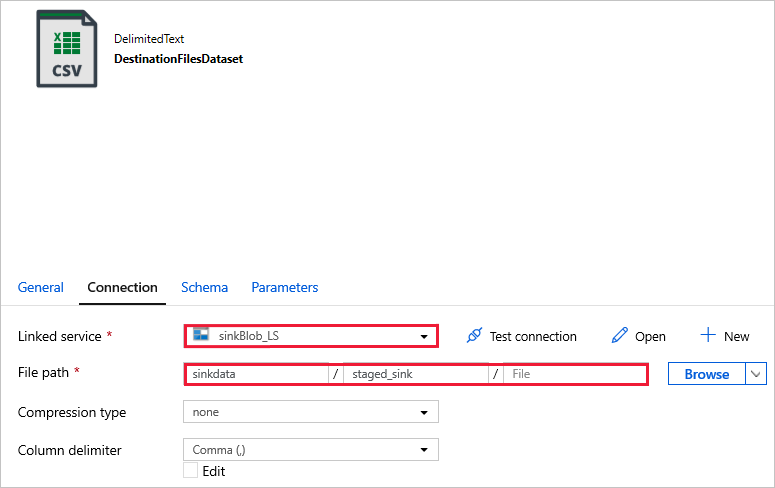
[デバッグ] を選択してパイプラインを実行します。 より詳細な Spark のログについては、Databricks のログへのリンクを検索できます。
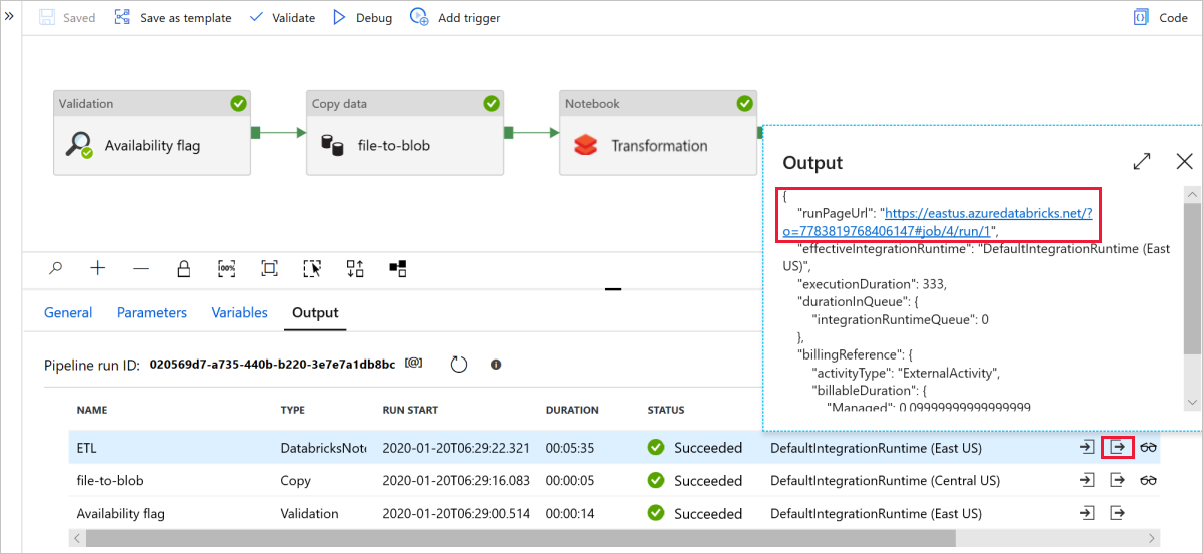
Azure Storage Explorer を使用してデータ ファイルを確認することもできます。
Note
Data Factory のパイプラインの実行と関連付けるため、この例では Data Factory からのパイプライン実行 ID を出力フォルダーに追加しています。 これにより、実行ごとに生成されたファイルを追跡することができます。