Azure Databricks で Python アクティビティを実行してデータを変換する
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューションである Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
パイプラインの Azure Databricks Python アクティビティは、Azure Databricks クラスターで Python ファイルを実行します。 この記事は、データ変換とサポートされる変換アクティビティの概要を説明する、 データ変換アクティビティ に関する記事に基づいています。 Azure Databricks は、Apache Spark を実行するための管理されたプラットフォームです。
この機能の概要とデモンストレーションについては、以下の 11 分間の動画を視聴してください。
UI で Azure Databricks の Python アクティビティをパイプラインに追加する
Azure Databricks の Python アクティビティをパイプラインで使用するには、以下の手順を実行します。
パイプラインの [アクティビティ] ペイン内で Python を検索し、Python アクティビティをパイプライン キャンバスにドラッグします。
まだ選択されていない場合は、キャンバスで新しい Python アクティビティを選択します。
[Azure Databricks] タブを選択し、Python アクティビティを実行する、新しい Azure Databricks のリンクされたサービスを選択または作成します。
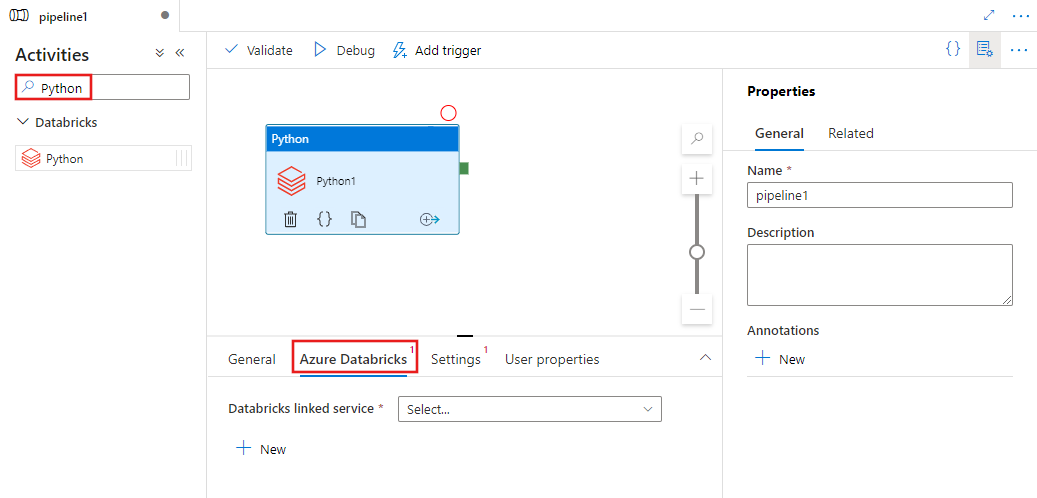
[設定] タブを選択し、Azure Databricks 内で、実行する Python ファイルのパス、渡すオプションのパラメータ、ジョブを実行するためにクラスターにインストールする追加のライブラリを指定します。
![Python アクティビティの [設定] タブの UI を示しています。](media/transform-data-databricks-python/python-settings.png)
Databricks Python アクティビティの定義
Databricks Python アクティビティのサンプルの JSON 定義を次に示します。
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksSparkPython",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"pythonFile": "dbfs:/docs/pi.py",
"parameters": [
"10"
],
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
}
]
}
}
}
Databricks Python アクティビティのプロパティ
次の表で、JSON 定義で使用される JSON プロパティについて説明します。
| プロパティ | 説明 | 必須 |
|---|---|---|
| name | パイプラインのアクティビティの名前。 | はい |
| description | アクティビティの動作を説明するテキスト。 | いいえ |
| type | Databricks Python アクティビティでは、アクティビティの種類は DatabricksSparkPython です。 | はい |
| linkedServiceName | Python アクティビティが実行されている Databricks リンク サービスの名前です。 このリンクされたサービスの詳細については、計算のリンクされたサービスに関する記事をご覧ください。 | はい |
| pythonFile | 実行される Python ファイルの URI。 DBFS パスのみがサポートされています。 | はい |
| parameters | Python ファイルに渡されるコマンド ライン パラメーター。 文字列の配列です。 | いいえ |
| libraries | ジョブを実行するクラスターにインストールされるライブラリのリスト。 <文字列, オブジェクト> の配列を指定できます。 | いいえ |
databricks アクティビティでサポートされるライブラリ
前述の Databricks アクティビティ定義では、jar、egg、maven、pypi、cran というライブラリの種類を指定しています。
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
ライブラリの種類の詳細については、Databricks のドキュメントを参照してください。
Databricks でライブラリをアップロードする方法
ワークスペース UI を使用できます。
UI を使用して追加されたライブラリの dbfs パスを取得するには、Databricks CLI を使用します。
UI を使用する場合、通常、Jar ライブラリは dbfs:/FileStore/jars に保存されます。 CLI databricks fs ls dbfs:/FileStore/job-jars を使用してすべてを一覧表示することができます
または、Databricks CLI を使用できます。
Databricks CLI を使用したライブラリのコピーに関するページの手順を行います
Databricks CLI を使用します (インストール手順)。
たとえば、JAR を dbfs にコピーする場合:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar